قام مجتمع ModelScope بإصدار نسخة مطورة مفتوحة المصدر من نموذج توليد الفيديو Sora المحلي مفتوح المصدر CogVideoX - CogVideoX-5B، وهو نموذج لإنشاء نص إلى فيديو يعتمد على نموذج DiT واسع النطاق. بالمقارنة مع CogVideoX-2B السابق، قام النموذج الجديد بتحسين جودة الفيديو والمؤثرات المرئية بشكل ملحوظ. يستخدم CogVideoX-5B جهاز التشفير التلقائي السببي ثلاثي الأبعاد (VAE السببي ثلاثي الأبعاد) وتقنية المحولات المتخصصة، ويستخدم 3D-RoPE كتشفير الموضع وآلية الاهتمام الكامل ثلاثية الأبعاد لنمذجة المفاصل المكانية والزمانية ، جودة أعلى، المزيد من مقاطع الفيديو المميزة بالحركة.
بالمقارنة مع CogVideoX-2B السابق، قام النموذج الجديد بتحسين الجودة والتأثيرات المرئية لإنشاء الفيديو بشكل ملحوظ.
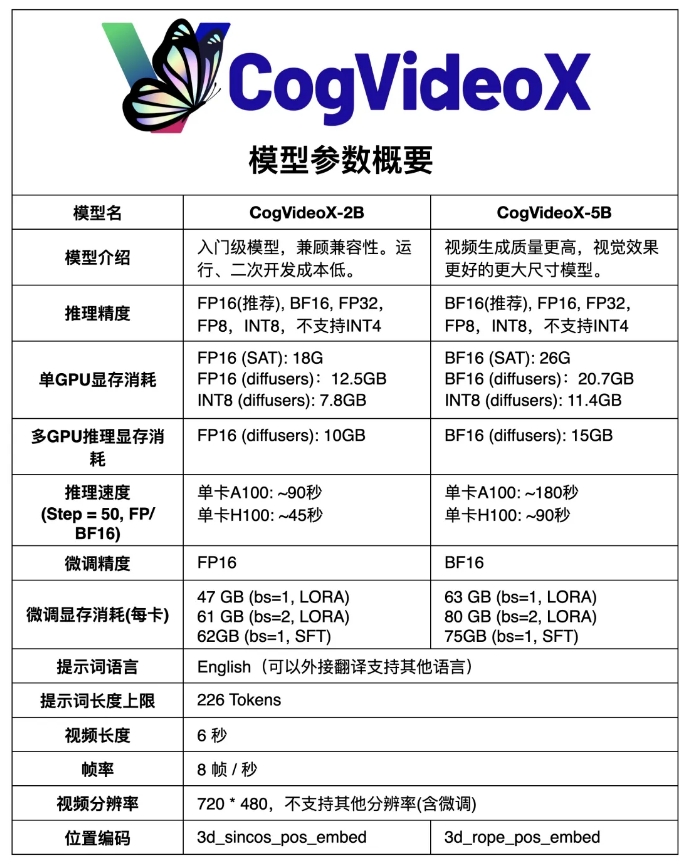
يعتمد CogVideoX-5B على نموذج DiT (محول الانتشار) واسع النطاق، المصمم خصيصًا لمهام إنشاء تحويل النص إلى فيديو. يعتمد النموذج على التشفير التلقائي السببي ثلاثي الأبعاد (VAE السببي ثلاثي الأبعاد) وتقنية المحولات المتخصصة، ويجمع بين تضمينات النص والفيديو، ويستخدم 3D-RoPE كترميز للموضع، ويستخدم آلية الاهتمام الكامل ثلاثية الأبعاد لنمذجة المفاصل المكانية والزمانية.
بالإضافة إلى ذلك، يعتمد النموذج تقنية تدريب تقدمية وهو قادر على إنشاء مقاطع فيديو متماسكة وطويلة الأمد وعالية الجودة مع ميزات حركة مهمة.
رابط النموذج:
https://modelscope.cn/models/ZhipuAI/CogVideoX-5b
جلب المصدر المفتوح لـ CogVideoX-5B اختراقات تكنولوجية جديدة وفرص تطوير إلى مجال إنشاء فيديو الذكاء الاصطناعي المحلي، كما قدم أدوات وموارد قوية للباحثين والمطورين. ومن المعتقد أن المزيد من التطبيقات المبتكرة المعتمدة على CogVideoX-5B ستظهر في المستقبل، مما يعزز التقدم المستمر في تكنولوجيا إنشاء الفيديو بالذكاء الاصطناعي. كما أن سهولة الوصول إلى النموذج تقلل أيضًا من عتبة البحث والتطبيق، مما يعزز نشر التكنولوجيا وتطبيقها على نطاق أوسع.