لقد أحدث ظهور بنية المحولات ثورة في مجال معالجة اللغات الطبيعية، لكن تكلفتها الحسابية العالية أصبحت بمثابة عنق الزجاجة عند معالجة النصوص الطويلة. ردًا على هذه المشكلة، تقدم هذه المقالة طريقة جديدة تسمى Tree Attention، والتي تقلل بشكل فعال من التعقيد الحسابي للانتباه الذاتي لنموذج محول السياق الطويل من خلال تقليل الشجرة، وتستفيد بشكل كامل من قوة مجموعات GPU الحديثة وطوبولوجيا الشبكة يحسن بشكل كبير كفاءة الحوسبة.
في عصر الانفجار المعلوماتي هذا، يشبه الذكاء الاصطناعي النجوم الساطعة، التي تضيء سماء الحكمة البشرية ليلاً. من بين هذه النجوم، تعد بنية Transformer هي بلا شك الأكثر إبهارًا، حيث تمثل آلية الاهتمام الذاتي جوهرها، فهي تقود عصرًا جديدًا من معالجة اللغة الطبيعية. ومع ذلك، فحتى ألمع النجوم لها زوايا يصعب الوصول إليها. بالنسبة لنماذج المحولات ذات السياق الطويل، يصبح الاستهلاك العالي للموارد لحساب الاهتمام الذاتي مشكلة. تخيل أنك تحاول جعل الذكاء الاصطناعي يفهم مقالًا يبلغ طوله عشرات الآلاف من الكلمات، ويجب مقارنة كل كلمة بكل كلمة أخرى في المقالة، مما لا شك فيه أن حجم العمليات الحسابية ضخم.
ومن أجل حل هذه المشكلة، اقترحت مجموعة من العلماء من Zyphra وEleutherAI طريقة جديدة تسمى Tree Attention.
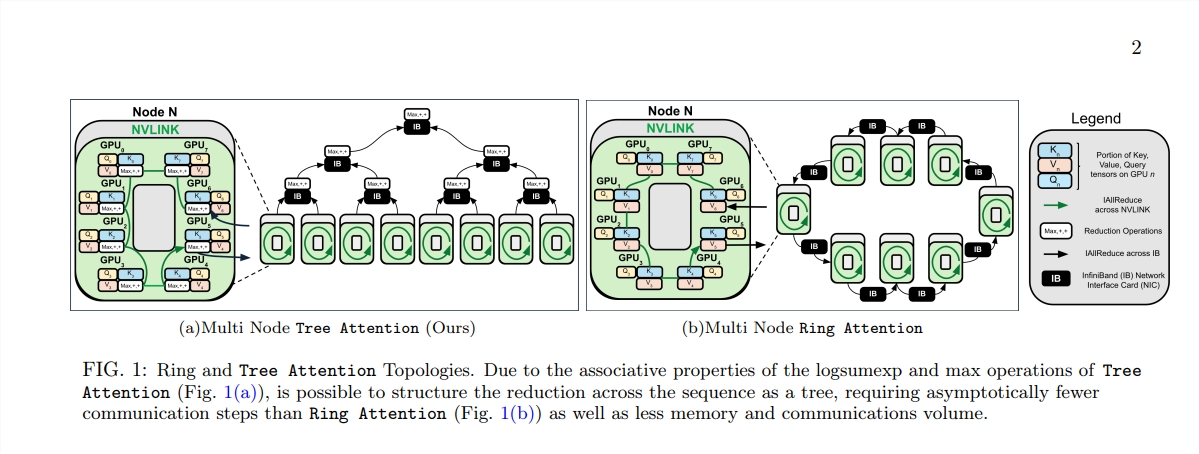
الاهتمام الذاتي، باعتباره جوهر نموذج المحولات، يزداد تعقيده الحسابي بشكل تربيعي مع زيادة طول التسلسل. يصبح هذا عائقًا لا يمكن التغلب عليه عند التعامل مع النصوص الطويلة، خاصة بالنسبة لنماذج اللغات الكبيرة (LLMs).
إن ميلاد Tree Attention يشبه زراعة الأشجار التي يمكنها إجراء عمليات حسابية فعالة في هذه الغابة الحسابية. فهو يقسم حساب الاهتمام الذاتي إلى مهام متعددة متوازية من خلال اختزال الشجرة، وكل مهمة تشبه ورقة على الشجرة، والتي تشكل معًا شجرة كاملة.
الأمر الأكثر إثارة للدهشة هو أن مقترحي شجرة الانتباه اشتقوا أيضًا وظيفة الطاقة للانتباه الذاتي، والتي لا توفر تفسيرًا بايزيًا للانتباه الذاتي فحسب، بل تربطه أيضًا بشكل وثيق بنماذج الطاقة مثل شبكة هوبفيلد.
تأخذ Tree Attention أيضًا في الاعتبار بشكل خاص طوبولوجيا الشبكة لمجموعات وحدات معالجة الرسومات الحديثة وتقلل من متطلبات الاتصال عبر العقد من خلال الاستخدام الذكي لاتصالات النطاق الترددي العالي داخل المجموعة، وبالتالي تحسين كفاءة الحوسبة.
ومن خلال سلسلة من التجارب، تحقق العلماء من أداء Tree Attention تحت أطوال تسلسلية مختلفة وعدد وحدات معالجة الرسومات. تظهر النتائج أن Tree Attention أسرع بما يصل إلى 8 مرات من أساليب Ring Attention الحالية عند فك التشفير على وحدات معالجة رسومات متعددة، مع تقليل حجم الاتصال بشكل كبير وذروة استخدام الذاكرة.
لا يوفر اقتراح Tree Attention حلاً فعالاً لحساب نماذج الانتباه طويلة السياق فحسب، بل يوفر لنا أيضًا منظورًا جديدًا لفهم الآلية الداخلية لنموذج المحولات. مع استمرار تقدم تكنولوجيا الذكاء الاصطناعي، لدينا سبب للاعتقاد بأن Tree Attention ستلعب دورًا مهمًا في أبحاث وتطبيقات الذكاء الاصطناعي المستقبلية.
عنوان الورقة: https://mp.weixin.qq.com/s/U9FaE6d-HJGsUs7u9EKKuQ
يوفر ظهور Tree Attention حلاً فعالاً ومبتكرًا لحل الاختناق الحسابي لمعالجة النصوص الطويلة، وله أهمية بعيدة المدى لفهم نموذج المحول وتطويره في المستقبل. لا تحقق هذه الطريقة تحسينات كبيرة في الأداء فحسب، بل الأهم من ذلك أنها توفر أفكارًا واتجاهات جديدة للبحث اللاحق، وهو أمر يستحق الدراسة والمناقشة المتعمقة.