شكك أندريه كارباثي، أحد الخبراء في مجال الذكاء الاصطناعي، مؤخرًا في التعلم المعزز القائم على ردود الفعل البشرية (RLHF)، معتقدًا أنه ليس الطريقة الوحيدة لتحقيق ذكاء اصطناعي حقيقي على المستوى البشري، الأمر الذي أثار قلقًا واسع النطاق ومناقشات ساخنة في الصناعة. . وهو يعتقد أن RLHF هو إجراء مؤقت أكثر من كونه حلًا نهائيًا، واتخذ AlphaGo كمثال لمقارنة الاختلافات في حل المشكلات بين التعلم المعزز الحقيقي وRLHF. لا شك أن آراء كارباثي توفر منظورًا جديدًا لاتجاهات أبحاث الذكاء الاصطناعي الحالية وتجلب أيضًا تحديات جديدة لتطوير الذكاء الاصطناعي في المستقبل.
في الآونة الأخيرة، طرح أندريه كارباثي، وهو باحث معروف في صناعة الذكاء الاصطناعي، وجهة نظر مثيرة للجدل، فهو يعتقد أن التعلم المعزز الذي يحظى بتقدير واسع النطاق حاليًا والذي يعتمد على تقنية ردود الفعل البشرية (RLHF) قد لا يكون هو السبيل الوحيد لتحقيق ذلك قدرات حقيقية على حل المشكلات على المستوى البشري. مما لا شك فيه أن هذا البيان ألقى قنبلة ثقيلة على المجال الحالي لأبحاث الذكاء الاصطناعي.
كان يُنظر إلى RLHF ذات يوم على أنها عامل رئيسي في نجاح نماذج اللغة واسعة النطاق (LLM) مثل ChatGPT، وتم الترحيب بها باعتبارها السلاح السري الذي يمنح الذكاء الاصطناعي الفهم والطاعة وقدرات التفاعل الطبيعي. في عملية تدريب الذكاء الاصطناعي التقليدية، عادةً ما يتم استخدام RLHF كحلقة وصل أخيرة بعد التدريب المسبق والضبط الدقيق تحت الإشراف (SFT). ومع ذلك، قارن كارباثي RLHF باختناق وتدبير مؤقت، معتقدًا أنه بعيد عن الحل النهائي لتطور الذكاء الاصطناعي.
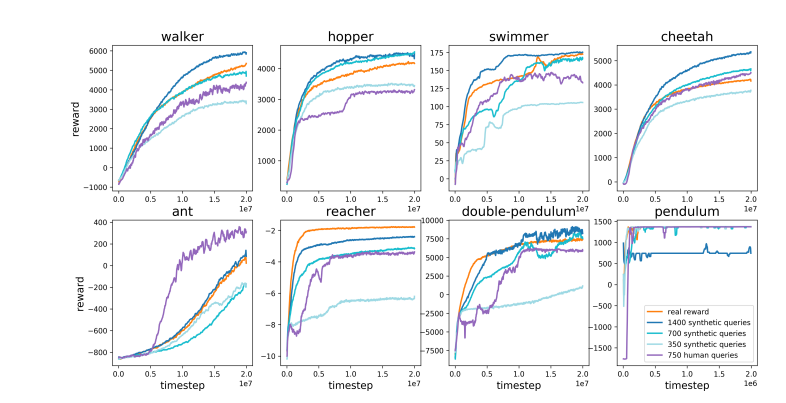
قام كارباثي بمقارنة RLHF بذكاء مع AlphaGo من DeepMind. استخدم AlphaGo ما يسميه تقنية RL الحقيقية (التعلم المعزز)، ومن خلال اللعب المستمر ضد نفسه وزيادة معدل فوزه إلى الحد الأقصى، فقد تجاوز في النهاية أفضل لاعبي الشطرنج من البشر دون تدخل بشري. يحقق هذا النهج مستويات أداء خارقة من خلال تحسين الشبكات العصبية للتعلم مباشرة من نتائج اللعبة.
في المقابل، يعتقد كارباثي أن RLHF يتعلق بتقليد التفضيلات البشرية أكثر من حل المشكلات فعليًا. لقد تخيل أنه إذا اعتمد AlphaGo طريقة RLHF، فسيحتاج المقيِّمون البشريون إلى مقارنة عدد كبير من حالات اللعبة واختيار التفضيلات. وقد تتطلب هذه العملية ما يصل إلى 100000 مقارنة لتدريب نموذج مكافأة يحاكي فحص الغلاف الجوي البشري. ومع ذلك، فإن مثل هذه الأحكام المبنية على الغلاف الجوي يمكن أن تؤدي إلى نتائج مضللة في لعبة صارمة مثل Go.
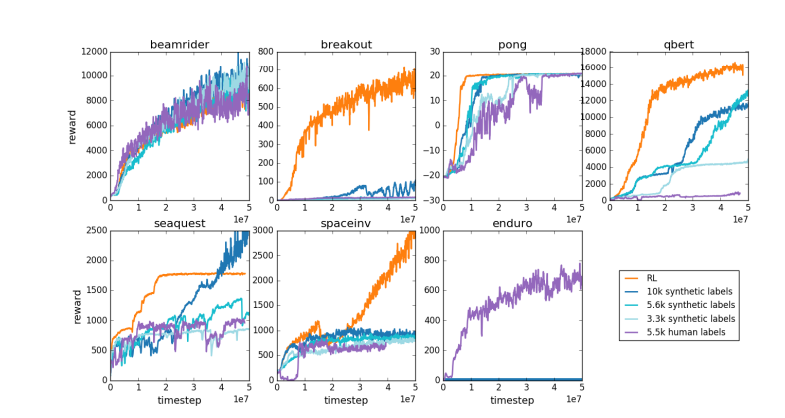
لنفس السبب، يعمل نموذج مكافأة LLM الحالي بشكل مشابه، فهو يميل إلى تصنيف الإجابات العالية التي يبدو أن المقيمين البشريين يفضلونها إحصائيًا. يعد هذا وكيلًا يلبي التفضيلات البشرية السطحية أكثر من كونه انعكاسًا لقدرة حقيقية على حل المشكلات. والأمر الأكثر إثارة للقلق هو أن النماذج قد تتعلم بسرعة كيفية استغلال وظيفة المكافأة هذه بدلاً من تحسين قدراتها فعليًا.
يشير كارباثي إلى أنه على الرغم من أن التعلم المعزز يؤدي أداءً جيدًا في البيئات المغلقة مثل Go، إلا أن التعلم المعزز الحقيقي يظل بعيد المنال بالنسبة لمهام اللغة المفتوحة. ويرجع ذلك أساسًا إلى صعوبة تحديد أهداف واضحة وآليات المكافأة في المهام المفتوحة. كيف يتم منح مكافآت موضوعية لمهام مثل تلخيص مقال، أو الإجابة على سؤال غامض حول تثبيت النقطة، أو إلقاء نكتة، أو إعادة كتابة كود Java في بايثون؟ يطرح كارباثي هذا السؤال الثاقب، والذهاب في هذا الاتجاه ليس مبدأً مستحيلاً، لكن الأمر ليس سهلاً أيضًا، ويتطلب بعض التفكير الإبداعي.

ومع ذلك، يعتقد كارباثي أنه إذا كان من الممكن حل هذه المشكلة الصعبة، فإن النماذج اللغوية لديها القدرة على مطابقة أو حتى تجاوز القدرات البشرية على حل المشكلات. ويتزامن هذا الرأي مع ورقة بحثية حديثة نشرها موقع Google DeepMind، أشارت إلى أن الانفتاح هو أساس الذكاء العام الاصطناعي (AGI).
باعتباره واحدًا من العديد من كبار خبراء الذكاء الاصطناعي الذين تركوا OpenAI هذا العام، يعمل كارباثي حاليًا على إنشاء شركته الناشئة التعليمية الخاصة بالذكاء الاصطناعي. ولا شك أن تصريحاته ضخت بعدًا جديدًا للتفكير في مجال أبحاث الذكاء الاصطناعي وقدمت رؤى قيمة حول الاتجاه المستقبلي لتطوير الذكاء الاصطناعي.
أثارت آراء كارباثي نقاشًا واسع النطاق في الصناعة. يعتقد المؤيدون أنه يكشف عن قضية رئيسية في أبحاث الذكاء الاصطناعي الحالية، وهي كيفية جعل الذكاء الاصطناعي قادرًا حقًا على حل المشكلات المعقدة بدلاً من مجرد تقليد السلوك البشري. يشعر المعارضون بالقلق من أن التخلي المبكر عن RLHF قد يؤدي إلى انحراف في اتجاه تطوير الذكاء الاصطناعي.
عنوان الورقة: https://arxiv.org/pdf/1706.03741
أثارت آراء كارباثي مناقشات متعمقة حول اتجاه التطوير المستقبلي للذكاء الاصطناعي، وقد دفعت شكوكه حول RLHF الباحثين إلى إعادة النظر في أساليب تدريب الذكاء الاصطناعي الحالية واستكشاف مسارات أكثر فعالية، بهدف نهائي هو تحقيق ذكاء اصطناعي حقيقي.