إن التقدم الذي أحرزته نماذج اللغات الكبيرة (LLMs) مثير للإعجاب، ولكنها تظهر عيوبًا غير متوقعة في بعض المشكلات البسيطة. أشار أندريه كارباثي بشدة إلى ظاهرة "الذكاء المتعرج"، أي أن LLM قادر على القيام بمهام معقدة، ولكنه كثيرًا ما يرتكب أخطاء في المشكلات البسيطة. وقد أدى هذا إلى تفكير متعمق حول العيوب الأساسية في LLM واتجاهات التحسين المستقبلية. ستشرح هذه المقالة هذا بالتفصيل وتستكشف كيفية الاستفادة بشكل أفضل من LLM وتجنب قيودها.
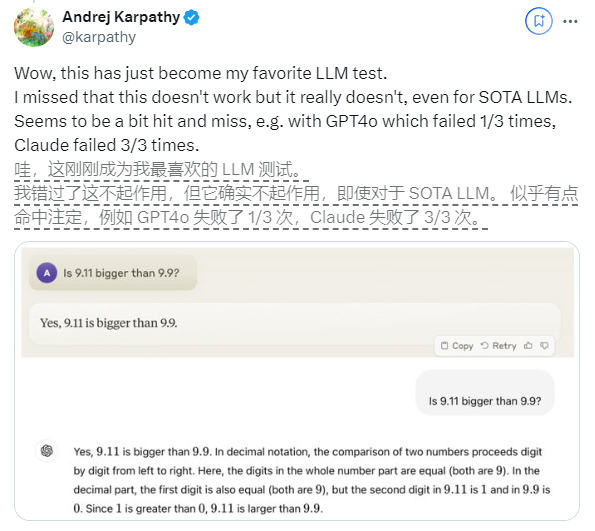
في الآونة الأخيرة، اجتذب سؤال يبدو بسيطًا: "هل 9.11 أكبر من 9.9؟"، اهتمامًا واسع النطاق في جميع أنحاء العالم. وقد ارتكبت جميع نماذج اللغات الكبيرة (LLM) تقريبًا أخطاء بشأن هذه المسألة. جذبت هذه الظاهرة انتباه أندريه كارباثي، الخبير في مجال الذكاء الاصطناعي. بدءًا من هذه المشكلة، ناقش بعمق العيوب الأساسية واتجاهات التحسين المستقبلية لتكنولوجيا النماذج الكبيرة الحالية.
يطلق كارباثي على هذه الظاهرة اسم "الذكاء الخشن" أو "الذكاء الخشن"، مشيرًا إلى أنه على الرغم من أن طلاب ماجستير العلوم المتطورين يمكنهم أداء مجموعة متنوعة من المهام المعقدة، مثل حل المشكلات الرياضية الصعبة، إلا أنهم يفشلون في بعض المهام التي تبدو بسيطة يؤدي أداءً سيئًا في حل المشكلات، وهذا الخلل في الذكاء يشبه شكل سن المنشار.
على سبيل المثال، وجد الباحث في OpenAI، نعوم براون، أن أداء LLM كان ضعيفًا في لعبة Tic-Tac-Toe، مع عدم قدرة النموذج على اتخاذ القرارات الصحيحة حتى عندما كان المستخدم على وشك الفوز. يعتقد كارباثي أن السبب في ذلك هو أن النموذج يتخذ قرارات "غير مبررة"، بينما يعتقد نعوم أن هذا قد يكون بسبب عدم وجود مناقشة ذات صلة للاستراتيجيات في بيانات التدريب.
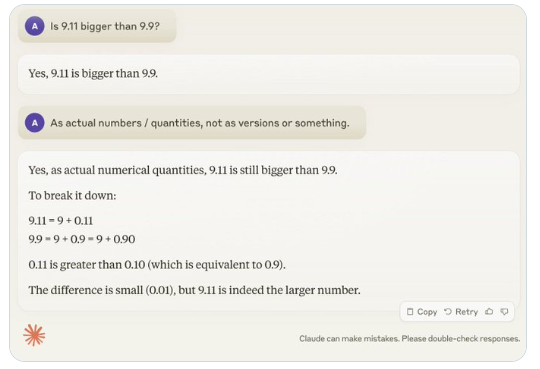
مثال آخر هو الخطأ الذي يحدثه LLM عند حساب الكميات الأبجدية الرقمية. حتى الإصدار الأخير من Llama 3.1 يقدم إجابات خاطئة على الأسئلة البسيطة. أوضح كارباثي أن هذا ينبع من افتقار LLM إلى "المعرفة الذاتية"، أي أن النموذج لا يمكنه التمييز بين ما يمكنه وما لا يمكنه فعله، مما يؤدي إلى أن يكون النموذج "واثقًا بثقة" عند مواجهة المهام.
لحل هذه المشكلة، ذكر كارباثي الحل المقترح في ورقة Llama3.1 التي نشرتها Meta. ويوصي البحث بتحقيق محاذاة النموذج في مرحلة ما بعد التدريب بحيث ينمي النموذج الوعي الذاتي ويعرف ما يعرفه ولا يمكن القضاء على مشكلة الوهم بمجرد إضافة المعرفة الواقعية. اقترح فريق اللاما طريقة تدريب تسمى "اكتشاف المعرفة"، والتي تشجع النموذج على الإجابة فقط على الأسئلة التي يفهمها ويرفض توليد إجابات غير مؤكدة.
ويعتقد كارباثي أنه على الرغم من وجود مشاكل مختلفة تتعلق بالقدرات الحالية للذكاء الاصطناعي، إلا أنها لا تشكل عيوبًا أساسية وهناك حلول ممكنة. واقترح أن فكرة تدريب الذكاء الاصطناعي الحالية هي فقط "تقليد العلامات البشرية وتوسيع النطاق". لمواصلة تحسين ذكاء الذكاء الاصطناعي، يجب القيام بالمزيد من العمل في جميع أنحاء حزمة التطوير بأكملها.
وإلى أن يتم حل المشكلة بالكامل، إذا كان سيتم استخدام LLMs في الإنتاج، فيجب أن يقتصروا على المهام التي يجيدونها، وأن يكونوا على دراية بـ "الحواف الخشنة"، وأن يبقيوا البشر مشاركين في جميع الأوقات. وبهذه الطريقة، يمكننا استغلال إمكانات الذكاء الاصطناعي بشكل أفضل مع تجنب المخاطر الناجمة عن قيوده.
وبشكل عام، يمثل "الذكاء المتعرج" الخاص بـ LLM تحديًا يواجه حاليًا مجال الذكاء الاصطناعي، ولكنه ليس مستعصيًا على الحل. من خلال تحسين أساليب التدريب، وتعزيز الوعي الذاتي بالنموذج، وتطبيقه بعناية على السيناريوهات الفعلية، يمكننا الاستفادة بشكل أفضل من مزايا LLM وتعزيز التطوير المستمر لتكنولوجيا الذكاء الاصطناعي.