في مجال الذكاء الاصطناعي المزدهر، أصبحت أساليب الحصول على البيانات هي محور التركيز بشكل متزايد. يستكشف هذا المقال الجدل الناجم عن سلوك استخراج البيانات على نطاق واسع لفريق كلود التابع لشركة الذكاء الاصطناعي Anthropic. قام برنامج الزاحف ClaudeBot التابع لفريق كلود بالزحف إلى كمية كبيرة من البيانات من مواقع ويب متعددة دون ترخيص، الأمر الذي لم ينتهك لوائح موقع الويب فحسب، بل تسبب أيضًا في استهلاك ضخم لموارد الخادم، مما أثار انتقادات وقلقًا واسع النطاق. يسلط هذا الحادث الضوء على التناقض بين تطوير الذكاء الاصطناعي وحماية حقوق الطبع والنشر للبيانات، مما دفع الصناعة إلى إعادة التفكير في الأخلاقيات والمعايير القانونية للحصول على البيانات.
كان سبب الحادث هو أن زاحف فريق كلود زار خادم الشركة مليون مرة خلال 24 ساعة، وقام بالزحف إلى محتوى موقع الويب مجانًا. لم يتجاهل هذا السلوك بشكل صارخ إعلان حظر الزحف الخاص بموقع الويب فحسب، بل احتل أيضًا قدرًا كبيرًا من موارد الخادم بالقوة.
وعلى الرغم من بذل قصارى جهدها للدفاع عن نفسها، إلا أن الشركة الضحية فشلت في النهاية في منع فريق كلود من جمع البيانات. لجأ قادة الشركة بغضب إلى وسائل التواصل الاجتماعي لإدانة تصرفات فريق كلود. كما أعرب العديد من مستخدمي الإنترنت عن استيائهم، حتى أن البعض اقترح استخدام كلمة "سرقة" لوصف هذا السلوك.
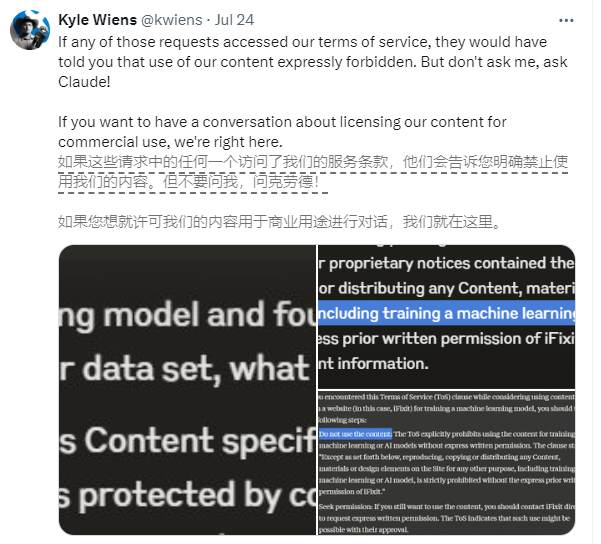
الشركة المعنية هي iFixit، وهو موقع أمريكي للتجارة الإلكترونية والإرشادات. يقدم iFixit ملايين الصفحات من أدلة الإصلاح المجانية عبر الإنترنت والتي تغطي الأجهزة الإلكترونية والأدوات الاستهلاكية. ومع ذلك، اكتشف iFixit أن برنامج الزاحف الخاص بكلود ClaudeBot بدأ عددًا كبيرًا من الطلبات في فترة زمنية قصيرة، حيث تمكن من الوصول إلى 10 تيرابايت من الملفات في يوم واحد، وإجمالي 73 تيرابايت في شهر مايو بأكمله.
قال الرئيس التنفيذي لشركة iFixit، كايل وينز، إن ClaudeBot سرق جميع بياناته دون إذن واحتل موارد الخادم. على الرغم من أن iFixit ينص صراحةً على موقعه على الويب على أن تجريف البيانات غير المصرح به محظور، يبدو أن فريق كلود يغض الطرف عن ذلك.
سلوك فريق كلود ليس فريدًا. في أبريل من هذا العام، عانى منتدى Linux Mint أيضًا من الزيارات المتكررة بواسطة ClaudeBot، مما تسبب في عمل المنتدى ببطء أو حتى تعطله. بالإضافة إلى ذلك، أشارت بعض الأصوات إلى أنه بالإضافة إلى Claude وGPT الخاص بـ OpenAI، هناك العديد من شركات الذكاء الاصطناعي الأخرى التي تتجاهل أيضًا إعدادات ملف robots.txt الخاصة بالموقع وتستولي على البيانات بالقوة.
في مواجهة هذا الموقف، تم اقتراح أن يضيف مالكو مواقع الويب محتوى مزيفًا يحتوي على معلومات يمكن تتبعها أو فريدة من نوعها إلى الصفحة لاكتشاف ما إذا كانت البيانات قد تم استخلاصها بشكل غير قانوني. لقد اتخذت iFixit هذه الخطوة بالفعل واكتشفت أن بياناتها قد تم حذفها ليس فقط بواسطة Claude، ولكن أيضًا بواسطة OpenAI.
أثار الحادث نقاشًا واسع النطاق حول ممارسات استخراج البيانات التي تتبعها شركات الذكاء الاصطناعي. من ناحية، يتطلب تطوير الذكاء الاصطناعي كمية كبيرة من البيانات لدعمه؛ ومن ناحية أخرى، يجب أن يحترم جمع البيانات أيضًا حقوق ولوائح مالك موقع الويب. إن كيفية إيجاد التوازن بين تعزيز التقدم التكنولوجي وحماية حقوق الطبع والنشر هو سؤال تحتاج الصناعة بأكملها إلى التفكير فيه.
لقد دقت حادثة الاستيلاء على البيانات التي تعرض لها فريق كلود ناقوس الخطر، مذكّرة شركات الذكاء الاصطناعي بأنه أثناء متابعة التقدم التكنولوجي، يجب عليها احترام حقوق الملكية الفكرية، والامتثال للقوانين واللوائح، واستكشاف الطرق المتوافقة للحصول على البيانات. وبهذه الطريقة فقط يمكننا ضمان التطور الصحي لتكنولوجيا الذكاء الاصطناعي وتجنب الإضرار بسمعة الصناعة وثقة الجمهور بسبب السلوك غير اللائق.