لقد أظهرت لنا تجربة Meta في تدريب نموذج اللغة Llama 3.1 واسع النطاق تحديات وفرصًا غير مسبوقة في تطوير الذكاء الاصطناعي. شهدت المجموعة الضخمة المكونة من 16,384 وحدة معالجة رسوميات فشلًا متوسطًا كل 3 ساعات خلال فترة التدريب التي استمرت 54 يومًا، وهذا لم يسلط الضوء على النمو السريع لحجم نموذج الذكاء الاصطناعي فحسب، بل كشف أيضًا عن عنق الزجاجة الهائل في استقرار الحوسبة الفائقة. نظام. سوف تتعمق هذه المقالة في التحديات التي واجهتها Meta أثناء عملية التدريب على Llama 3.1، والاستراتيجيات التي اعتمدتها للتعامل مع هذه التحديات، وتحلل آثارها على صناعة الذكاء الاصطناعي بأكملها.
في عالم الذكاء الاصطناعي، كل اختراق يرافقه بيانات مذهلة. تخيل أن 16,384 وحدة معالجة رسوميات تعمل في نفس الوقت. هذا ليس مشهدًا من فيلم خيال علمي، ولكنه تصوير حقيقي لـ Meta عند تدريب أحدث طراز Llama3.1. لكن وراء هذا العيد التكنولوجي يكمن فشل يحدث في المتوسط كل 3 ساعات. ولا يوضح هذا الرقم المذهل سرعة تطور الذكاء الاصطناعي فحسب، بل يكشف أيضًا عن التحديات الهائلة التي تواجهها التكنولوجيا الحالية.
من 2028 وحدة معالجة رسوميات مستخدمة في Llama1 إلى 16384 وحدة معالجة رسومية مستخدمة في Llama3.1، لا يمثل هذا النمو السريع تغييرًا في الكمية فحسب، بل يمثل أيضًا تحديًا كبيرًا لاستقرار نظام الحوسبة الفائقة الحالي. تظهر بيانات بحث Meta أنه خلال دورة التدريب التي استمرت 54 يومًا لـ Llama3.1، حدث إجمالي 419 فشلًا غير متوقع في المكونات، نصفها تقريبًا كان مرتبطًا بوحدة معالجة الرسومات H100 وذاكرة HBM3 الخاصة بها. هذه البيانات تجعلنا نفكر: أثناء سعينا لتحقيق اختراقات في أداء الذكاء الاصطناعي، هل تحسنت موثوقية النظام أيضًا في وقت واحد؟
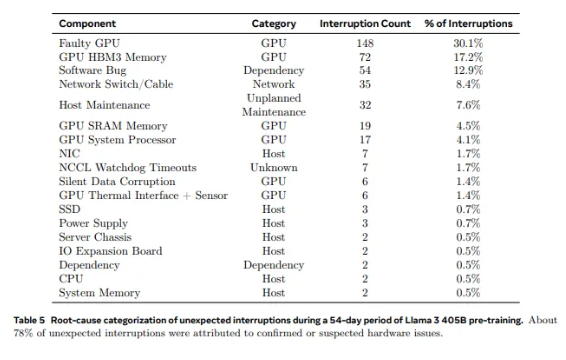
في الواقع، هناك حقيقة لا جدال فيها في مجال الحوسبة الفائقة: كلما زاد حجم النطاق، زادت صعوبة تجنب الفشل. تتكون مجموعة التدريب Meta's Llama 3.1 من عشرات الآلاف من المعالجات، ومئات الآلاف من الرقائق الأخرى، ومئات الأميال من الكابلات، وهو مستوى من التعقيد يمكن مقارنته بمستوى الشبكة العصبية لمدينة صغيرة. في مثل هذا العملاق، يبدو أن الأعطال أمر شائع.
في مواجهة الإخفاقات المتكررة، لم يكن فريق Meta عاجزًا. لقد تبنوا سلسلة من استراتيجيات التكيف: تقليل أوقات بدء العمل ونقاط التفتيش، وتطوير أدوات التشخيص الخاصة، والاستفادة من مسجل الطيران NCCL الخاص بشركة PyTorch، وما إلى ذلك. ولا تؤدي هذه التدابير إلى تحسين تحمل النظام للخطأ فحسب، بل تعمل أيضًا على تعزيز قدرات المعالجة الآلية. يشبه مهندسو Meta رجال الإطفاء المعاصرين، وهم على استعداد لإخماد أي حرائق قد تعطل عملية التدريب.
ومع ذلك، فإن التحديات لا تأتي فقط من الأجهزة نفسها. تجلب العوامل البيئية وتقلبات استهلاك الطاقة أيضًا تحديات غير متوقعة لمجموعات الحوسبة الفائقة. وجد فريق Meta أن التغيرات في درجات الحرارة ليلًا ونهارًا والتقلبات الجذرية في استهلاك طاقة وحدة معالجة الرسومات سيكون لها تأثير كبير على أداء التدريب. ويذكرنا هذا الاكتشاف بأنه بينما نسعى لتحقيق الاختراقات التكنولوجية، لا يمكننا أن نتجاهل أهمية إدارة البيئة وإدارة استهلاك الطاقة.
يمكن تسمية عملية تدريب Llama3.1 بالاختبار النهائي لاستقرار وموثوقية نظام الحوسبة الفائقة. توفر الاستراتيجيات التي اعتمدها فريق Meta للتعامل مع التحديات والأدوات الآلية التي تم تطويرها تجربة قيمة وإلهامًا لصناعة الذكاء الاصطناعي بأكملها. على الرغم من الصعوبات، لدينا سبب للاعتقاد أنه مع التقدم التكنولوجي المستمر، ستكون أنظمة الحوسبة الفائقة المستقبلية أكثر قوة واستقرارًا.
في عصر التطور السريع لتكنولوجيا الذكاء الاصطناعي، تعد محاولة ميتا بلا شك مغامرة شجاعة. إنه لا يدفع حدود أداء نماذج الذكاء الاصطناعي فحسب، بل يوضح لنا أيضًا التحديات الحقيقية التي نواجهها في السعي وراء الحدود. دعونا نتطلع إلى الإمكانيات اللامحدودة التي توفرها تكنولوجيا الذكاء الاصطناعي، وفي الوقت نفسه نشيد بالمهندسين الذين يعملون بلا كلل في طليعة التكنولوجيا. كل محاولة وكل فشل وكل اختراق يحققونه يمهد الطريق للتقدم التكنولوجي البشري.
مراجع:
https://www.tomshardware.com/tech-industry/artificial-intelligence/faulty-nvidia-h100-gpus-and-hbm3-memory-caused-half-of-the-failures-during-llama-3-training- فشل واحد كل ثلاث ساعات لـ metas-16384-gpu-training-cluster
لقد زودتنا الحالة التدريبية لـ Llama 3.1 بدروس قيمة وأشارت إلى اتجاه التطوير المستقبلي لأنظمة الحوسبة الفائقة: أثناء متابعة الأداء، يجب علينا أن نولي أهمية كبيرة لاستقرار النظام وموثوقيته، واستكشاف استراتيجيات التعامل مع حالات الفشل المختلفة بشكل فعال. وبهذه الطريقة فقط يمكننا ضمان التطوير المستمر والمستقر لتكنولوجيا الذكاء الاصطناعي وإفادة البشرية.