أصدرت NVIDIA مؤخرًا سلسلة Minitron من نماذج اللغات الصغيرة، بما في ذلك إصدارات 4B و8B. تهدف هذه الخطوة إلى تقليل تكاليف التدريب والنشر لنماذج اللغات الكبيرة والسماح لمزيد من المطورين باستخدام هذه التكنولوجيا المتقدمة بسهولة. ومن خلال تقنيات "التقليم" و"التقطير المعرفي"، يعمل نموذج Minitron على تقليل حجم النموذج بشكل كبير مع الحفاظ على أداء يضاهي النماذج الكبيرة، بل ويتفوق على النماذج الأخرى المعروفة في بعض المؤشرات. وهذا له أهمية كبيرة لتعزيز تعميم تكنولوجيا الذكاء الاصطناعي.
في الآونة الأخيرة، قامت شركة NVIDIA بتحركات جديدة في مجال الذكاء الاصطناعي حيث أطلقت سلسلة Minitron من نماذج اللغات الصغيرة، بما في ذلك إصدارات 4B و8B. لا تعمل هذه النماذج على زيادة سرعة التدريب بمقدار 40 مرة فحسب، بل تسهل أيضًا على المطورين استخدامها لتطبيقات مختلفة، مثل الترجمة وتحليل المشاعر والذكاء الاصطناعي للمحادثة.
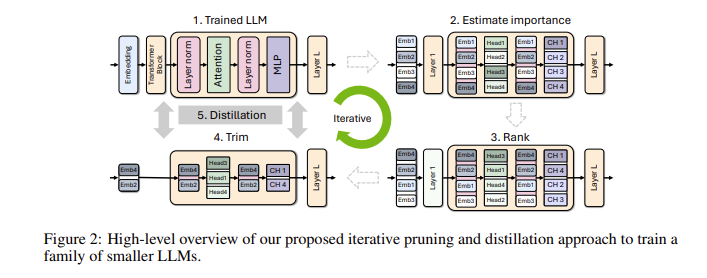
قد تتساءل، لماذا تعتبر نماذج اللغات الصغيرة مهمة جدًا؟ في الواقع، على الرغم من أن نماذج اللغات الكبيرة التقليدية تتمتع بأداء قوي، إلا أن تكاليف تدريبها ونشرها مرتفعة جدًا، وغالبًا ما تتطلب كمية كبيرة من موارد الحوسبة والبيانات. من أجل جعل هذه التقنيات المتقدمة في متناول عدد أكبر من الأشخاص، توصل فريق البحث في NVIDIA إلى طريقة رائعة: الجمع بين تقنيتين: "التقليم" و"التقطير المعرفي" لتقليل حجم النموذج بكفاءة.
على وجه التحديد، سيبدأ الباحثون أولاً من نموذج كبير موجود ثم يقومون بتهذيبه. يقومون بتقييم أهمية كل خلية عصبية أو طبقة أو رأس انتباه في النموذج وإزالة تلك الأقل أهمية. وبهذه الطريقة، يصبح النموذج أصغر بكثير، كما تنخفض الموارد والوقت اللازم للتدريب بشكل كبير. بعد ذلك، سيستخدمون أيضًا مجموعة بيانات صغيرة الحجم لإجراء تدريب على استخلاص المعرفة على النموذج المقطوع لاستعادة دقة النموذج. والمثير للدهشة أن هذه العملية لا توفر المال فحسب، بل تعمل أيضًا على تحسين أداء النموذج!
في الاختبار الفعلي، حقق فريق البحث في NVIDIA نتائج جيدة على عائلة نماذج Nemotron-4. لقد نجحوا في تقليل حجم النموذج بمقدار 2 إلى 4 مرات مع الحفاظ على أداء مماثل. والأمر الأكثر إثارة هو أن نموذج 8B يتفوق على النماذج الأخرى المعروفة مثل Mistral7B وLLaMa-38B في مؤشرات متعددة، ويتطلب بيانات تدريب أقل بمقدار 40 مرة أثناء عملية التدريب، مما يوفر 1.8 مرة في تكاليف الحوسبة. تخيل ماذا يعني هذا؟ يمكن لمزيد من المطورين تجربة قدرات الذكاء الاصطناعي القوية بموارد وتكاليف أقل!
تجعل NVIDIA نماذج Minitron المحسنة هذه مفتوحة المصدر على Huggingface ليستخدمها الجميع بحرية.
الدخول التجريبي: https://huggingface.co/collections/nvidia/minitron-669ac727dc9c86e6ab7f0f3e
أبرز النقاط:
** تحسين سرعة التدريب **: سرعة تدريب نموذج Minitron أسرع 40 مرة من النماذج التقليدية، مما يسمح للمطورين بتوفير الوقت والجهد.
**توفير التكلفة**: من خلال تقنية التقليم والتقطير المعرفي، يتم تقليل موارد الحوسبة وحجم البيانات المطلوبة للتدريب بشكل كبير.
** مشاركة مفتوحة المصدر **: أصبح نموذج Minitron مفتوح المصدر على Huggingface، بحيث يمكن لعدد أكبر من الأشخاص الوصول إليه واستخدامه بسهولة، مما يعزز تعميم تكنولوجيا الذكاء الاصطناعي.
يمثل المصدر المفتوح لنموذج Minitron طفرة مهمة في التطبيق العملي لنماذج اللغات الصغيرة، كما يشير إلى أن تكنولوجيا الذكاء الاصطناعي ستصبح أكثر شعبية وأسهل في الاستخدام، مما سيمكن المزيد من المطورين وسيناريوهات التطبيق. وفي المستقبل، يمكننا أن نتوقع المزيد من الابتكارات المماثلة لتعزيز التطوير المستمر لتكنولوجيا الذكاء الاصطناعي.