NaturalSpeech2
v1.0
Vor kurzem gab Microsoft bekannt, dass es ein neues großes Modell auf den Markt bringen wird: NaturalSpeech2. Im Vergleich zu früheren großen Modellen ist die Sprachrekonstruktion von NaturalSpeech2 „genauer“, bleibt nicht beim Lesen hängen und kann Benutzern ein besseres Erlebnis bieten .
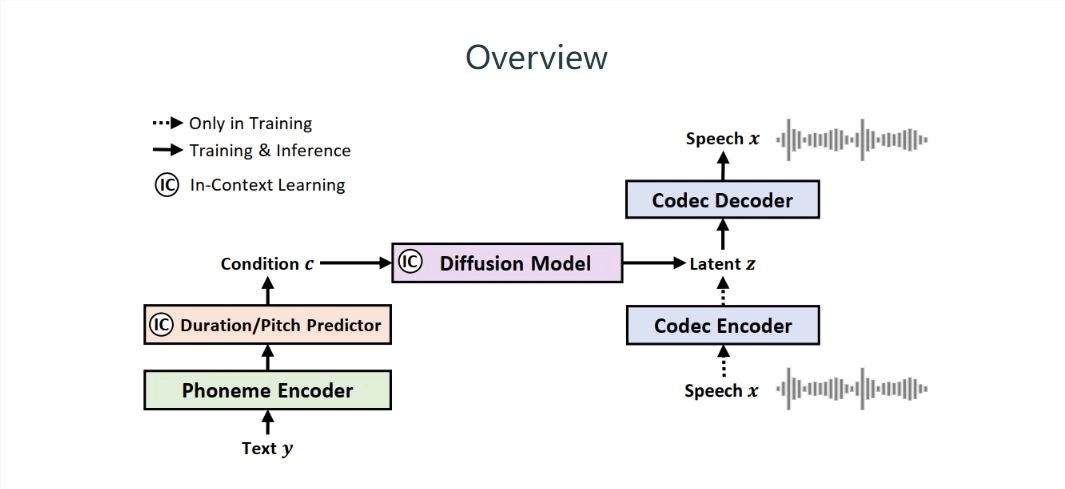
Microsoft hat kürzlich ein Sprachmodell namens NaturalSpeech2 auf den Markt gebracht, das ein „Potenzialdiffusions“-Design verwendet und hervorragende Ergebnisse auf der Ebene der Sprachsynthese ohne Stichproben erzielt. Microsoft behauptet, dass das Modell eine „kommerzielle“ Sprach-/Gesangslösung bietet Benutzern ein hochwertiges und vielfältiges Sprachsyntheseerlebnis.
Microsoft führte eine Reihe von Demonstrationen von NaturalSpeech2 durch und demonstrierte seine Fähigkeit, Sprache mit unterschiedlichen Sprecheridentitäten, Prosodie und Stilen (z. B. Gesang) in Situationen ohne Stichproben zu erzeugen.
Es wird berichtet, dass NaturalSpeech2 von Microsoft im Gegensatz zu herkömmlichen Speech-to-Text-Systemen (TTS) „kontinuierliche Vektoren“ anstelle von „diskreten Markierungen“ verwendet, um Sprache darzustellen, wodurch vollständigere Sprachsegmente generiert werden und kein „Stablesen“, das heißt „ „ohne Emotionen“ (Wort für Wort sprechen)“-Phänomen.
Experimentelle Ergebnisse zeigen, dass die von NaturalSpeech2 unter Zero-Sample-Bedingungen erzeugte Sprache nahezu mit der Prosodie von Sprachaufforderungen und echter Sprache übereinstimmt und die Natürlichkeit (gemessen durch CMOS) auf den LibriTTS- und VCTK-Testsätzen nicht von echter Sprache zu unterscheiden ist.
Das Papier zu diesem Projekt ist derzeit auf GitHub veröffentlicht
1. Großes Modell, offiziell von Microsoft eingeführt
2. Es wird den Spielern viele reichhaltige neue Interaktionen bringen.
3. Derzeit in intensiver Entwicklung, bitte bleiben Sie auf dem Laufenden.