Das Repository von TrafficLLM , einem universellen LLM-Anpassungsframework zum Erlernen einer robusten Verkehrsdarstellung für alle Open-Source-LLM in realen Szenarien und zur Verbesserung der Generalisierung über verschiedene Verkehrsanalyseaufgaben hinweg.

Hinweis: Dieser Code basiert auf ChatGLM2 und Llama2. Vielen Dank an die Autoren.
[28.10.2024] Wir haben den Anpassungscode für die Verwendung von GLM4 aktualisiert, um TrafficLLM zu erstellen, das eine schnellere Abstimmungs- und Inferenzgeschwindigkeit als ChatGLM2 aufweist. Weitere Informationen finden Sie unter Adapt2GLM4.
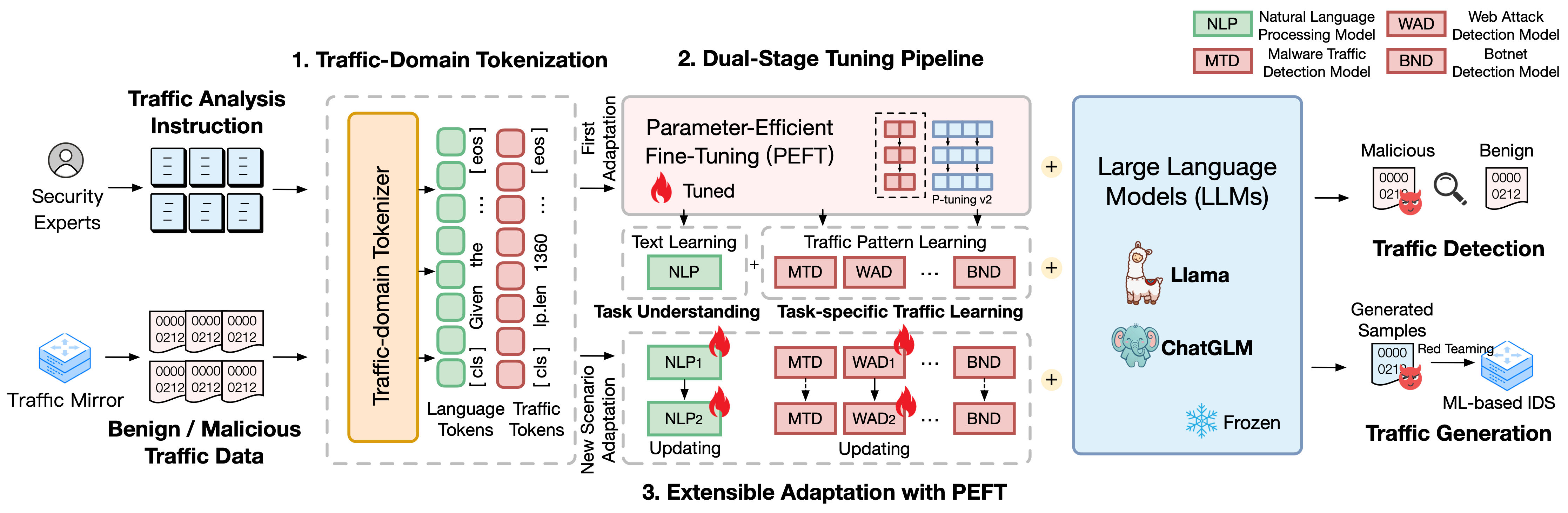
TrafficLLM basiert auf einem hochentwickelten Feinabstimmungs-Framework unter Verwendung natürlicher Sprache und Verkehrsdaten, das die folgenden Techniken vorschlägt, um den Nutzen großer Sprachmodelle bei der Netzwerkverkehrsanalyse zu verbessern.
Traffic-Domain-Tokenisierung. Um die Modalitätslücke zwischen natürlicher Sprache und heterogenen Verkehrsdaten zu schließen, führt TrafficLLM die Verkehrsdomänen-Tokenisierung ein, um die vielfältigen Eingaben von Verkehrserkennungs- und -generierungsaufgaben für die LLM-Anpassung zu verarbeiten. Dieser Mechanismus erweitert effektiv den nativen Tokenizer von LLM, indem er das Tokenisierungsmodell speziell auf große Traffic-Domain-Korpora trainiert.
Zweistufige Tuning-Pipeline. TrafficLLM verwendet eine zweistufige Tuning-Pipeline, um das robuste Repräsentationslernen von LLM über verschiedene Verkehrsdomänenaufgaben hinweg zu erreichen. Die Pipeline schult LLM darin, Anweisungen zu verstehen und aufgabenbezogene Verkehrsmuster in verschiedenen Phasen zu lernen, was auf dem Aufgabenverständnis und den Verkehrsbegründungsfähigkeiten von TrafficLLM für verschiedene Aufgaben zur Verkehrserkennung und -generierung aufbaut.
Erweiterbare Anpassung mit Parameter-effektiver Feinabstimmung (EA-PEFT). Um LLM für die Verallgemeinerung an neue Verkehrsumgebungen anzupassen, schlägt TrafficLLM eine erweiterbare Anpassung mit Parameter-effektiver Feinabstimmung (EA-PEFT) vor, um Modellparameter mit geringem Overhead zu aktualisieren. Die Technik teilt die Modellfunktionen in verschiedene PEFT-Modelle auf, was dazu beiträgt, die Kosten für dynamische Szenarien, die durch Änderungen des Verkehrsmusters entstehen, zu minimieren.
Wir haben die Trainingsdatensätze von TrafficLLM veröffentlicht, die über 0,4 Millionen Verkehrsdaten und 9.000 menschliche Anweisungen für die LLM-Anpassung an verschiedene Verkehrsanalyseaufgaben enthalten.
Instruction Datasets : Die Anweisungsdatensätze werden verwendet, um LLM dabei zu helfen, das Domänenwissen über Verkehrserkennungs- oder -generierungsaufgaben zu erlernen und zu verstehen, welche Aufgabe in verschiedenen Szenarien ausgeführt werden sollte.
Traffic Datasets : Die Verkehrsdatensätze enthalten die Verkehrsoptimierungsdaten, die wir aus den öffentlichen Verkehrsdatensätzen extrahiert haben, was LLM dabei hilft, das Verkehrsmuster in verschiedenen nachgelagerten Aufgaben zu lernen.
Um den Korpus natürlicher Sprache als menschliche Anweisungen in TrafficLLM aufzubauen, haben wir 9.209 aufgabenspezifische Anweisungen unter Aufsicht von Experten und KI-Assistenten gesammelt. Die Statistiken werden wie folgt angezeigt:
| Mainstream-Aufgaben | Nachgelagerte Aufgaben | Abkürzung. | #Probe |
|---|---|---|---|
| Verkehrserkennung | Erkennung von Malware-Verkehr | MTD | 1,0K |
| Botnet-Erkennung | BND | 1,1K | |
| Bösartige DoH-Erkennung | MDD | 0,6K | |
| Erkennung von Web-Angriffen | BÜNDEL | 0,6K | |
| APT-Angriffserkennung | AAD | 0,6K | |
| Verschlüsselte VPN-Erkennung | EVD | 1,2K | |
| Tor-Verhaltenserkennung | Noch offen | 0,6K | |
| Verschlüsselte App-Klassifizierung | EAC | 0,6K | |
| Website-Fingerprinting | WF | 0,6K | |
| Konzeptdrift | CD | 0,6K | |
| Traffic-Generierung | Generierung von Malware-Verkehr | MTG | 0,6K |
| Generierung von Botnet-Verkehr | BTG | 0,1K | |
| Verschlüsselte VPN-Generierung | EVG | 0,4K | |
| Verschlüsselte App-Generierung | EAG | 0,6K |
Um die Leistung von TrafficLLM in verschiedenen Netzwerkszenarien zu bewerten, haben wir über 0,4 Millionen Optimierungsdaten aus öffentlich verfügbaren Verkehrsdatensätzen extrahiert, um die Fähigkeit von TrafficLLM zu messen, bösartigen und harmlosen Datenverkehr zu erkennen oder zu generieren. Die Statistiken werden wie folgt angezeigt:
| Datensätze | Aufgaben | Abkürzung. | #Probe |
|---|---|---|---|
| USTC TFC 2016 | Erkennung von Malware-Verkehr | MTD | 50,7K |
| ISCX-Botnetz 2014 | Botnet-Erkennung | BND | 25,0K |
| DoHBrw 2020 | Bösartige DoH-Erkennung | MDD | 47,8K |
| CSIC 2010 | Erkennung von Web-Angriffen | BÜNDEL | 34,5K |
| DAPT 2020 | APT-Angriffserkennung | AAD | 10,0K |
| ISCX VPN 2016 | Verschlüsselte VPN-Erkennung | EVD | 64,8K |
| ISCX Tor 2016 | Tor-Verhaltenserkennung | Noch offen | 40,0K |
| CSTNET 2023 | Verschlüsselte App-Klassifizierung | EAC | 97,6K |
| KW-100 2018 | Website-Fingerprinting | WF | 7,4K |
| APP-53 2023 | Konzeptdrift | CD | 109,8K |
1. Umgebungsvorbereitung 2. Training TrafficLLM 2.1. Vorbereiten des vorab trainierten Checkpoints 2.2. Vorverarbeitungsdatensatz 2.3. Training des Traffic-Domain-Tokenizers (optional) 2.4. Optimierung neuronaler Sprachanweisungen 2.5. Aufgabenspezifische Verkehrsoptimierung 2.6. Erweiterbare Anpassung mit PEFT (EA-PEFT) 3. Evaluierung von TrafficLLM 3.1. Vorbereiten von Kontrollpunkten und Daten 3.2. Laufende EvaluierungInhaltsverzeichnis:
1. Umgebungsvorbereitung [Zurück nach oben]
Bitte klonen Sie das Repo und installieren Sie die erforderliche Umgebung, indem Sie die folgenden Befehle ausführen.
conda create -n Trafficllm Python=3.9 conda activate Trafficllm# Klonen Sie unseren TrafficLLMgit-Klon https://github.com/ZGC-LLM-Safety/TrafficLLM.gitcd TrafficLLM# Erforderliche Bibliotheken installierenpip install -r Anforderungen.txt# Wenn Trainingpip rouge_chinese nltk jieba Datensätze installiert
TrafficLLM verwendet drei Kerntechniken: Verkehrsdomänen-Tokenisierung zur Verarbeitung von Anweisungen und Verkehrsdaten, zweistufige Tuning-Pipeline zum Verständnis der Textsemantik und zum Erlernen von Verkehrsmustern über verschiedene Aufgaben hinweg sowie EA-PEFT zur Aktualisierung Modellparameter für die Anpassung neuer Szenarien.
TrafficLLM wird auf der Grundlage bestehender Open-Source-LLMs trainiert. Bitte befolgen Sie die Anweisungen zur Vorbereitung der Kontrollpunkte.
ChatGLM2 : Bereiten Sie das Basismodell ChatGLM vor, bei dem es sich um ein Open-Source-LLM mit leichten Bereitstellungsanforderungen handelt. Bitte laden Sie die Gewichte hier herunter. Wir verwenden im Allgemeinen das v2-Modell mit 6B-Parametern.
Other LLMs : Um andere LLMs für Verkehrsanalyseaufgaben anzupassen, können Sie die Trainingsdaten im Repo wiederverwenden und ihre Trainingsskripte gemäß den offiziellen Anweisungen ändern. Beispielsweise ist Llama2 erforderlich, um den neuen Datensatz in den Konfigurationen zu registrieren.
Um geeignete Trainingsdaten für das LLM-Lernen aus den rohen Verkehrsdatensätzen zu extrahieren, entwickeln wir spezielle Extraktoren, um Verkehrsdatensätze für verschiedene Aufgaben vorzuverarbeiten. Der Vorverarbeitungscode enthält die folgenden zu konfigurierenden Parameter.
input : Der Pfad des Rohdatenverkehrsdatensatzes (Der Hauptverzeichnispfad, der beschriftete Unterverzeichnisse enthält. Jedes beschriftete Unterverzeichnis enthält die rohen .pcap-Dateien, die vorverarbeitet werden sollen).
dataset_name : Der Name des Rohverkehrsdatensatzes (er hilft bei der Beurteilung, ob der Name in den Codes von TrafficLLM registriert wurde).
traffic_task : Erkennungsaufgaben oder Generierungsaufgaben.
granularity : Granularität auf Paket- oder Flussebene.
output_path : Pfad des Ausgabe-Trainingsdatensatzes.
output_name : Name des Ausgabe-Trainingsdatensatzes.
Dies ist eine Instanz zur Vorverarbeitung roher Verkehrsdatensätze für Verkehrserkennungsaufgaben auf Paketebene.
CD-Vorverarbeitung python preprocess_dataset.py --input /Your/Raw/Dataset/Path --dataset_name /Your/Raw/Dataset/Name --traffic_task Erkennung --granularity packet --output_path /Your/Output/Dataset/Path --output_name /Your /Output/Dataset/Name
TrafficLLM führt einen Traffic-Domain-Tokenizer ein, um neuronale Sprache und Verkehrsdaten zu verarbeiten. Wenn Sie einen benutzerdefinierten Tokenizer mit Ihrem eigenen Datensatz trainieren möchten, ändern Sie bitte den model_name und data_path im Code.
model_name : Der Basismodellpfad, der den nativen Tokenizer enthält.
data_path : Die aus dem Vorverarbeitungsprozess extrahierten Trainingsdatensätze.
Bitte folgen Sie dem Befehl, um den Code zu verwenden.
CD-Tokenisierung python Traffic_tokenizer.py
Daten vorbereiten: Die Neural Language Instruction Tuning-Daten sind unsere gesammelten Instruktionsdatensätze für das Verständnis von Verkehrsanalyseaufgaben.
Optimierung starten: Nach den oben genannten Schritten können Sie mit der Optimierung der ersten Stufe beginnen, indem Sie Trafficllm_stage1.sh verwenden. Es gibt ein Beispiel wie unten:
PRE_SEQ_LEN=128
LR=2e-2
NUM_GPUS=1export CUDA_VISIBLE_DEVICES=1
Torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py
--do_train
--train_file ../datasets/instructions/instructions.json
--validation_file ../datasets/instructions/instructions.json
--preprocessing_num_workers 10
--prompt_column-Anweisung
--response_column Ausgabe
--overwrite_cache
--cache_dir ../cache
--model_name_or_path ../models/chatglm2/chatglm2-6b
--output_dir ../models/chatglm2/peft/instruction
--overwrite_output_dir
--max_source_length 1024
--max_target_length 32
--per_device_train_batch_size 1
--per_device_eval_batch_size 1
--gradient_accumulation_steps 16
--predict_with_generate
--max_steps 20000
--logging_steps 10
--save_steps 4000
--learning_rate $LR
--pre_seq_len $PRE_SEQ_LEN Daten vorbereiten: Die aufgabenspezifischen Verkehrsoptimierungsdatensätze sind die Trainingsdatensätze, die aus dem Vorverarbeitungsschritt für verschiedene nachgelagerte Aufgaben extrahiert wurden.
Optimierung starten: Nach den oben genannten Schritten können Sie mit der Optimierung der zweiten Stufe beginnen, indem Sie Trafficllm_stage2.sh verwenden. Es gibt ein Beispiel wie unten:
PRE_SEQ_LEN=128
LR=2e-2
NUM_GPUS=1export CUDA_VISIBLE_DEVICES=1
Torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py
--do_train
--train_file ../datasets/ustc-tfc-2016/ustc-tfc-2016_detection_packet_train.json
--validation_file ../datasets/ustc-tfc-2016/ustc-tfc-2016_detection_packet_train.json
--preprocessing_num_workers 10
--prompt_column-Anweisung
--response_column Ausgabe
--overwrite_cache
--cache_dir ../cache
--model_name_or_path ../models/chatglm2/chatglm2-6b
--output_dir ../models/chatglm2/peft/ustc-tfc-2016-detection-packet
--overwrite_output_dir
--max_source_length 1024
--max_target_length 32
--per_device_train_batch_size 1
--per_device_eval_batch_size 1
--gradient_accumulation_steps 16
--predict_with_generate
--max_steps 20000
--logging_steps 10
--save_steps 4000
--learning_rate $LR
--pre_seq_len $PRE_SEQ_LEN TrafficLLM verwendet EA-PEFT, um die Parameter-Effektiven Feinabstimmungsmodelle (PEFT) mit einer erweiterbaren Anpassung zu organisieren, die TrafficLLM bei der einfachen Anpassung unterstützen kann neue Umgebungen. Der TrafficLLM-Adapter ermöglicht flexible Vorgänge zum Aktualisieren alter Modelle oder zum Registrieren neuer Aufgaben.
model_name : Der Pfad des Basismodells.
tuning_data : Der neue Umgebungsdatensatz.
adaptation_task : Aktualisieren oder registrieren (alte Modelle aktualisieren oder neue Aufgaben registrieren).
task_name : Der Name der Downstream-Aufgabe, die aktualisiert oder eingefügt werden soll.
Es gibt ein Beispiel für die Aktualisierung von TrafficLLM mit MTD-Aufgaben (Malware Traffic Daetection).
cd EA-PEFT python ea-peft.py --model_name /Your/Base/Model/Path --tuning_data /Your/New/Dataset/Path --adaptation_task update --task_name MTD
Prüfpunkte: Sie können versuchen, TrafficLLM zu evaluieren, indem Sie Ihr eigenes Modell oder unsere veröffentlichten Prüfpunkte verwenden.
Daten: Während des Vorverarbeitungsschritts teilen wir Testdatensätze auf und erstellen Etikettendateien für verschiedene Datensätze zur Auswertung. Bitte beachten Sie die Vorverarbeitungscodes.
Um die Effektivität von TrafficLLM für verschiedene nachgelagerte Aufgaben zu messen, führen Sie bitte die Evaluierungscodes aus.
model_name : Der Pfad des Basismodells.
traffic_task : Erkennungsaufgaben oder Generierungsaufgaben.
test_file : Die während der Vorverarbeitungsschritte extrahierten Testdatensätze.
label_file : Die während der Vorverarbeitungsschritte extrahierte Etikettendatei.
ptuning_path : Der PEFT-Modellpfad für die aufgabenspezifische Auswertung.
Es gibt ein Beispiel für die Ausführung einer Evaluierung von MTD-Aufgaben.
Python-Bewertung.py --model_name /Ihre/Basis/Modell/Pfad --traffic_task Erkennung --test_file datasets/ustc-tfc-2016/ustc-tfc-2016_detection_packet_test.json --label_file datasets/ustc-tfc-2016/ustc- tfc-2016_label.json --ptuning_path models/chatglm2/peft/ustc-tfc-2016-detection-packet/checkpoints-20000/
Sie können TrafficLLM auf Ihrem lokalen Gerät bereitstellen. Konfigurieren Sie zunächst den Modellpfad in config.json, um die aus den Trainingsschritten gesammelten PEFT-Modelle zu registrieren. Es gibt ein Beispiel zum Registrieren von 6 Aufgaben in TrafficLLM:
{ "model_path": "models/chatglm2/chatglm2-6b/", "peft_path": "models/chatglm2/peft/", "peft_set": { "NLP": " Instruction/Checkpoint-8000/", "MTD": "ustc-tfc-2016-detection-packet/checkpoint-10000/", "BND": "iscx-botnet-2014-detection-packet/checkpoint-5000/", „WAD“: „csic-2010-detection-packet/checkpoint-6000/“, „AAD“: „dapt-2020-detection-packet/checkpoint-20000/“, „EVD“: „iscx-vpn-2016-detection -packet/checkpoint-4000/", "TBD": "iscx-tor-2016-detection-packet/checkpoint-10000/"
}, „tasks“: { „Malware Traffic Detection“: „MTD“, „Botnet Detection“: „BND“, „Web Attack Detection“: „WAD“, „APT Attack Detection“: „AAD“, „Encrypted VPN Detection ": "EVD", "Tor-Verhaltenserkennung": "TBD"
}
} Dann sollten Sie die Preprompt in der prepromt -Funktion von inference.py und Trafficllm_server.py hinzufügen. Der Preprompt ist der Präfixtext, der in den Trainingsdaten während der aufgabenspezifischen Verkehrsoptimierung verwendet wird.
Um mit TrafficLLM im Terminal-Modus zu chatten, können Sie den folgenden Befehl ausführen:
python inference.py --config=config.json --prompt="Ihr Anweisungstext +: + Verkehrsdaten"
Das können Sie Starten Sie die Website-Demo von TrafficLLM mit dem folgenden Befehl:
streamlit run Trafficllm_server.py
Diese Demo führt einen Webserver von TrafficLLM aus. Greifen Sie auf http://Your-Server-IP:Port zu, um in der Chatbox zu chatten.
Vielen Dank an die verwandte Arbeit ChatGLM2 und Llama2, die als Grundlage für unser Framework und unsere Codes dient. Das Design des TrafficLLM-Gebäudes ist von ET-BERT und GraphGPT inspiriert. Vielen Dank für ihre wunderbaren Arbeiten.