中文版文档
Die Retrieval Augmentation Generation (RAG)-Technologie fördert die Integration von Domänenanwendungen mit großen Sprachmodellen. Allerdings weist RAG Probleme wie eine große Lücke zwischen Vektorähnlichkeit und Wissensschlusskorrelation sowie Unempfindlichkeit gegenüber Wissenslogik (wie numerische Werte, Zeitbeziehungen, Expertenregeln usw.) auf, die die Implementierung professioneller Wissensdienste behindern.
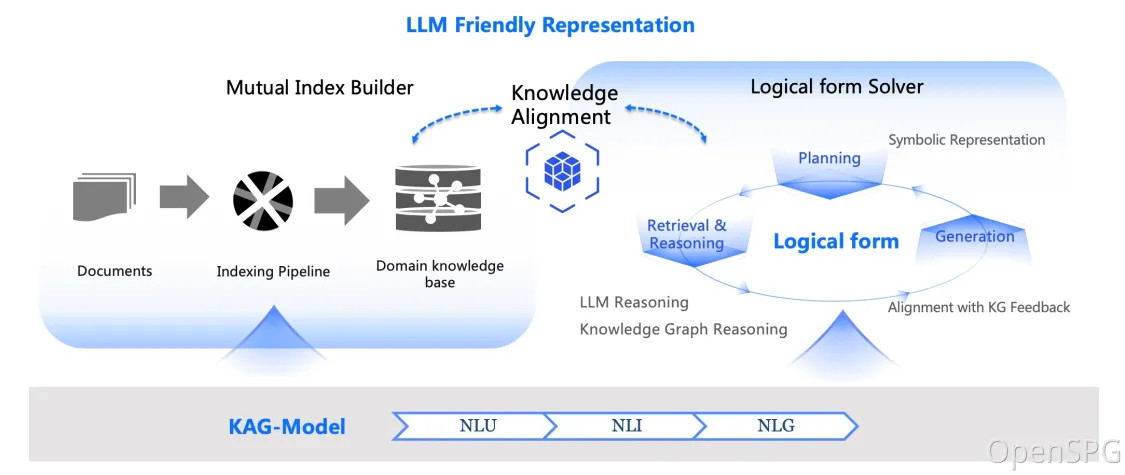
Am 24. Oktober 2024 veröffentlichte OpenSPG v0.5 und veröffentlichte damit offiziell das professionelle Domänenwissensdienst-Framework der Knowledge Augmented Generation (KAG). Ziel von KAG ist es, die Vorteile von Knowledge Graph und Vector Retrieval voll auszunutzen und große Sprachmodelle und Knowledge Graphen durch vier Aspekte bidirektional zu verbessern, um RAG-Herausforderungen zu lösen: (1) LLM-freundliche Wissensdarstellung, (2) Knowledge Graph und Originaltext Der gegenseitige Index zwischen Fragmenten, (3) eine hybride Argumentationsmaschine, die von logischen Formen geleitet wird, (4) Wissensabgleich mit semantischem Denken.
KAG ist bei Multi-Hop-Frage- und Antwortaufgaben deutlich besser als NaiveRAG, HippoRAG und andere Methoden. Der F1-Score bei hotpotQA ist relativ um 19,6 % gestiegen, und der F1-Score bei 2wiki ist relativ um 33,5 % gestiegen. Wir haben KAG erfolgreich auf die beiden Frage- und Antwortaufgaben zum Fachwissen der Ant Group angewendet, darunter E-Government-Frage und -Antwort und E-Health-Frage und -Antwort, und die Professionalität wurde im Vergleich zur RAG-Methode erheblich verbessert.

Das KAG-Framework besteht aus drei Teilen: kg-builder, kg-solver und kag-model. Diese Version umfasst nur die ersten beiden Teile, kag-model wird in Zukunft schrittweise als Open-Source-Version veröffentlicht.
kg-builder implementiert eine Wissensdarstellung, die für große Sprachmodelle (LLM) geeignet ist. Basierend auf der hierarchischen Struktur von DIKW (Daten, Informationen, Wissen und Weisheit) verbessert die IT die Fähigkeit zur Wissensdarstellung von SPG und ist mit der Informationsextraktion ohne Schemaeinschränkungen und der professionellen Wissenskonstruktion mit Schemaeinschränkungen für denselben Wissenstyp (z. B. Entitätstyp) kompatibel und Ereignistyp) unterstützt es auch die gegenseitige Indexdarstellung zwischen der Diagrammstruktur und dem ursprünglichen Textblock, was das effiziente Abrufen der Begründungsfrage- und Antwortphase unterstützt.
kg-solver verwendet eine durch logische Symbole gesteuerte hybride Lösungs- und Argumentationsmaschine, die drei Arten von Operatoren umfasst: Planung, Argumentation und Abruf, um Probleme in natürlicher Sprache in einen Problemlösungsprozess umzuwandeln, der Sprache und Symbole kombiniert. In diesem Prozess kann jeder Schritt unterschiedliche Operatoren verwenden, wie z. B. exakte Übereinstimmungsabfrage, Textabfrage, numerische Berechnung oder semantisches Denken, um die Integration von vier verschiedenen Problemlösungsprozessen zu realisieren: Abruf, Knowledge-Graph-Argumentation, sprachliche Argumentation und numerische Berechnung .
Im Kontext privater Wissensdatenbanken existieren häufig unstrukturierte Daten, strukturierte Informationen und die Erfahrung von Unternehmensexperten nebeneinander. KAG referenziert die DIKW-Hierarchie, um SPG auf eine LLM-freundliche Version zu aktualisieren. Für unstrukturierte Daten wie Nachrichten, Ereignisse, Protokolle und Bücher sowie strukturierte Daten wie Transaktionen, Statistiken und Genehmigungen sowie Geschäftserfahrung und Domänenwissensregeln setzt KAG Techniken wie Layoutanalyse, Wissensextraktion, Eigenschaftsnormalisierung ein. und semantische Ausrichtung, um rohe Geschäftsdaten und Expertenregeln in einen einheitlichen Geschäftswissensgraphen zu integrieren.

Dies macht es kompatibel mit der schemafreien Informationsextraktion und der schemabeschränkten Fachwissenskonstruktion für denselben Wissenstyp (z. B. Entitätstyp, Ereignistyp) und unterstützt die indexübergreifende Darstellung zwischen der Diagrammstruktur und dem ursprünglichen Textblock . Diese gegenseitige Indexdarstellung ist hilfreich bei der Konstruktion eines invertierten Index basierend auf der Diagrammstruktur und fördert die einheitliche Darstellung und Argumentation logischer Formen.

KAG schlägt eine logisch formal geführte Hybridlösung und Inferenz-Engine vor. Die Engine umfasst drei Arten von Operatoren: Planung, Argumentation und Abruf, die Probleme in natürlicher Sprache in Problemlösungsprozesse umwandeln, die Sprache und Notation kombinieren. In diesem Prozess kann jeder Schritt unterschiedliche Operatoren verwenden, wie z. B. exakte Übereinstimmungsabfrage, Textabfrage, numerische Berechnung oder semantisches Denken, um die Integration von vier verschiedenen Problemlösungsprozessen zu realisieren: Abruf, Knowledge-Graph-Argumentation, sprachliche Argumentation und numerische Berechnung .

Nach der Optimierung haben wir nicht nur die Anpassungsfähigkeit von KAG in vertikalen Feldern überprüft, sondern sie auch mit der bestehenden RAG-Methode in der Multi-Hop-Frage und Antwort allgemeiner Datensätze verglichen. Wir haben festgestellt, dass es offensichtlich besser ist als die SOTA-Methode, wobei F1 bei 2wiki um 33,5 % und bei hotpotQA um 19,6 % zunimmt. Wir verfeinern dieses Framework weiter und haben seine Wirksamkeit durch End-to-End-Experimente und Metriken für Ablationsexperimente nachgewiesen. Wir demonstrieren die Gültigkeit dieses Rahmenwerks durch logisch-symbolbasiertes Denken und konzeptionelle Ausrichtung.
Definition der Identifizierungsregeln für „Glücksspiel-Apps“.
Definieren Sie die riskAppTaxo-Regel
Define (s:App)-[p:belongTo]->(o:`TaxOfRiskApp`/`GamblingApp`) {
Structure {
(s)
}
Constraint {
R1("risk label marked as gambling") s.riskMark like "%Gambling%"
}
}Definieren Sie die Identifikationsregeln für „App-Entwickler“.
Definieren Sie die App-Entwicklerregel
Define (s:Person)-[p:developed]->(o:App) {
Structure {
(s)-[:hasDevice]->(d:Device)-[:install]->(o)
}
Constraint {
deviceNum = group(s,o).count(d)
R1("device installed same app"): deviceNum > 5
}
}Definieren Sie die Regeln für die Identifizierung von „Glücksspiel-App-Entwicklern“.
Definieren Sie eine RiskUser-Regel für Glücksspiel-Apps
Define (s:Person)-[p:belongTo]->(o:`TaxOfRiskUser`/`DeveloperOfGamblingApp`) {
Structure {
(s)-[:developed]->(app:`TaxOfRiskApp`/`GamblingApp`)
}
Constraint {
}
}

Die wichtigsten Schritte im Argumentationsprozess sind wie folgt.
Konvertieren Sie Probleme in natürlicher Sprache in ausführbare logische Ausdrücke, die auf der konzeptionellen Modellierung im Rahmen des Projekts basieren, und beziehen Sie sich auf das Black Product Mining-Dokument.
Senden Sie den konvertierten logischen Ausdruck zur Ausführung an den OpenSPG-Reasoner, um das Ergebnis der Benutzerklassifizierung zu erhalten.
Generieren Sie Antworten auf die Klassifizierungsergebnisse des Benutzers.
In Kombination mit der OpenSPG-Konzeptmodellierung kann KAG die Schwierigkeit der Abfrage von Diagrammen zur Konvertierung natürlicher Sprache verringern, die datenorientierte Konvertierung in eine klassifizierungskonzeptorientierte Konvertierung ändern und die Feldanwendung von Fragen und Antworten in natürlicher Sprache im ursprünglichen OpenSPG-Projekt schnell realisieren.
Systemversion empfehlen:
macOS User:macOS Monterey 12.6 or later
Linux User:CentOS 7 / Ubuntu 20.04 or later
Windows User:Windows 10 LTSC 2021 or laterSoftwareanforderungen:
macOS / Linux User:Docker,Docker Compose
Windows User:WSL 2 / Hyper-V,Docker,Docker ComposeVerwenden Sie die folgenden Befehle, um die Datei docker-compose.yml herunterzuladen und die Dienste mit Docker Compose zu starten.
# setze die HOME-Umgebungsvariable (nur Windows-Benutzer müssen diesen Befehl ausführen)# set HOME=%USERPROFILE%curl -sSL https://raw.githubusercontent.com/OpenSPG/openspg/refs/heads/master/dev/release/ docker-compose.yml -o docker-compose.yml docker compose -f docker-compose.yml up -d
Navigieren Sie mit Ihrem Browser zur Standard-URL des KAG-Produkts: http://127.0.0.1:8887
Eine ausführliche Einführung finden Sie im Produkthandbuch.
Lesen Sie Abschnitt 3.1, um die Installation der Engine und des abhängigen Images abzuschließen.
macOS-/Linux-Entwickler
# Create conda env: conda create -n kag-demo python=3.10 && conda activate kag-demo
# Clone code: git clone https://github.com/OpenSPG/KAG.git
# Install KAG: cd KAG && pip install -e .Windows-Entwickler
# Install the official Python 3.8.10 or later, install Git.
# Create and activate Python venv: py -m venv kag-demo && kag-demoScriptsactivate
# Clone code: git clone https://github.com/OpenSPG/KAG.git
# Install KAG: cd KAG && pip install -e .Eine detaillierte Einführung in das Toolkit finden Sie in der Kurzanleitung. Anschließend können Sie die integrierten Komponenten verwenden, um die Leistungsergebnisse der integrierten Datensätze zu reproduzieren und diese Komponenten auf neue Geschäftsszenarien anzuwenden.
Wenn die von KAG bereitgestellten integrierten Komponenten Ihren Anforderungen nicht entsprechen, können Sie die Implementierung von kag-builder und kag-solver selbst erweitern. Weitere Informationen finden Sie unter KAG-Builder Extension und KAG-Solver Extension.

KAG verwendet BuilderChain, um Komponenten wie Reader, Splitter, Mapping, Extractor, Aligner und Vectorizer zu verketten. Entwickler können die von kag vordefinierte BuilderChain verwenden, um die Diagrammerstellung abzuschließen, oder vordefinierte Komponenten zusammenstellen und BuilderChain erhalten.
Gleichzeitig können Entwickler die Komponenten im Builder anpassen und zur Ausführung in die BuilderChain einbetten.
kag
├──interface
│ ├── builder
│ │ ├── aligner_abc.py
│ │ ├── extractor_abc.py
│ │ ├── mapping_abc.py
│ │ ├── reader_abc.py
│ │ ├── splitter_abc.py
│ │ ├── vectorizer_abc.py
│ │ └── writer_abc.pyDer Kag-Löser führt Solver-Pipelines aus, die aus Reasoner-, Generator- und Reflektorkomponenten bestehen. KAG bietet Standard-Reasoner, -Generator und -Reflektor. Entwickler können auch benutzerdefinierte Implementierungen basierend auf den folgenden APIs bereitstellen:
kag
├── solver
│ ├── logic
│ │ └── solver_pipeline.py
├── interface
├── retriever
│ ├── chunk_retriever_abc.py
│ └── kg_retriever_abc.py
└── solver
├── kag_generator_abc.py
├── kag_memory_abc.py
├── kag_reasoner_abc.py
├── kag_reflector_abc.py
└── lf_planner_abc.pyKAG unterstützt das Andocken an MaaS-APIs, die mit OpenAI-Diensten wie Qwen/DeepSeek/GPT kompatibel sind, und unterstützt auch das Andocken an lokale Modelle, die von vLLM/Ollama bereitgestellt werden. Entwickler können Unterstützung für benutzerdefinierte Modelldienste basierend auf der Schnittstelle llm_client hinzufügen.
kag
├── common
├── llm
├── client
│ ├── llm_client.py
│ ├── ollama_client.py
│ ├── openai_client.py
│ ├── vllm_client.pyKAG unterstützt den Aufruf von OpenAI-Repräsentationsmodellen und dergleichen, einschließlich OpenAI-Einbettungsdiensten und des von Ollama bereitgestellten bge-m3-Modells. Es unterstützt auch das Laden und Verwenden lokaler Einbettungsmodelle.
kag
├── common
├── vectorizer
│ ├── vectorizer.py
│ ├── openai_vectorizer.py
│ ├── local_bge_m3_vectorizer.py
│ ├── local_bge_vectorizer.pyBei der Integration mit anderen Frameworks können externe Geschäftsdaten und Expertenwissen als Eingabe zum Aufrufen der Kag-Builder-Pipeline verwendet werden, um die Erstellung des Wissensgraphen abzuschließen. Sie können auch den Kag-Solver aufrufen, um den Frage-und-Antwort-Begründungsprozess abzuschließen, und das Begründungsergebnis und der Zwischenprozess werden dem Geschäftssystem angezeigt.
Die Art und Weise, wie andere Frameworks kag integrieren, kann einfach wie folgt beschrieben werden:

Domänenwissensinjektion, um die Fusion von Domänenkonzeptgraphen und Entitätsgraphen zu realisieren
Optimierung des Kag-Modells zur Verbesserung der Effizienz der KG-Konstruktion und der Fragen und Antworten
Halluzination Hemmung von Wissenslogikbeschränkungen
Wenn Sie diese Software verwenden, zitieren Sie sie bitte wie folgt:
KAG: Förderung von LLMs in professionellen Bereichen durch Knowledge Augmented Generation
KGFabric: Ein skalierbares Knowledge Graph Warehouse für die Datenverbindung in Unternehmen
@article{liang2024kag, title={KAG: Boosting LLMs in Professional Domains via Knowledge Augmented Generation}, Autor={Liang, Lei und Sun, Mengshu und Gui, Zhengke und Zhu, Zhongshu und Jiang, Zhouyu und Zhong, Ling und Qu, Yuan und Zhao, Peilong und Bo, Zhongpu und Yang, Jin und andere}, journal={arXiv preprint arXiv:2409.13731}, Jahr={2024}}@article{yikgfabric, title={KGFabric: Ein skalierbares Knowledge Graph Warehouse für Unternehmen Datenverbindung}, Autor={Yi, Peng und Liang, Lei und Da Zhang, Yong Chen und Zhu, Jinye und Liu, Xiangyu und Tang, Kun und Chen, Jialin und Lin, Hao und Qiu, Leijie und Zhou, Jun}}Apache-Lizenz 2.0