Magika ist ein neuartiges KI-gestütztes Tool zur Erkennung von Dateitypen, das auf den jüngsten Fortschritten des Deep Learning basiert, um eine genaue Erkennung zu ermöglichen. Unter der Haube verwendet Magika ein benutzerdefiniertes, hochoptimiertes Keras-Modell, das nur etwa wenige MB wiegt und eine präzise Dateiidentifizierung innerhalb von Millisekunden ermöglicht, selbst wenn es auf einer einzelnen CPU ausgeführt wird.
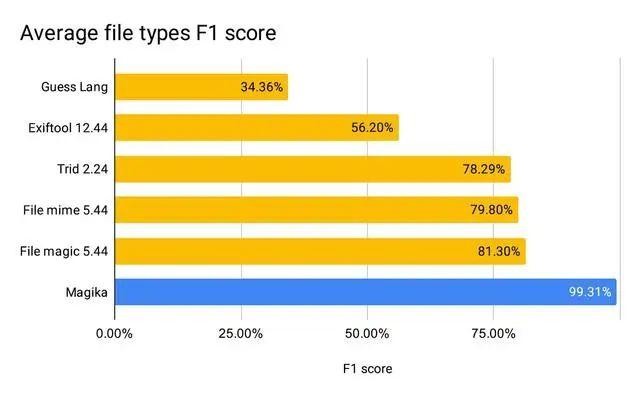
Bei einer Auswertung mit über 1 Mio. Dateien und über 100 Inhaltstypen (die sowohl binäre als auch textuelle Dateiformate abdecken) erreicht Magika eine Präzision und Wiedererkennung von über 99 %. Magika wird in großem Umfang eingesetzt, um die Sicherheit von Google-Nutzern zu verbessern, indem Gmail-, Drive- und Safe Browsing-Dateien an die richtigen Sicherheits- und Inhaltsrichtlinienscanner weitergeleitet werden. Lesen Sie mehr in unserem Forschungsbericht!
Sie können Magika ohne Installation ausprobieren, indem Sie unsere Web-Demo verwenden, die lokal in Ihrem Browser läuft!
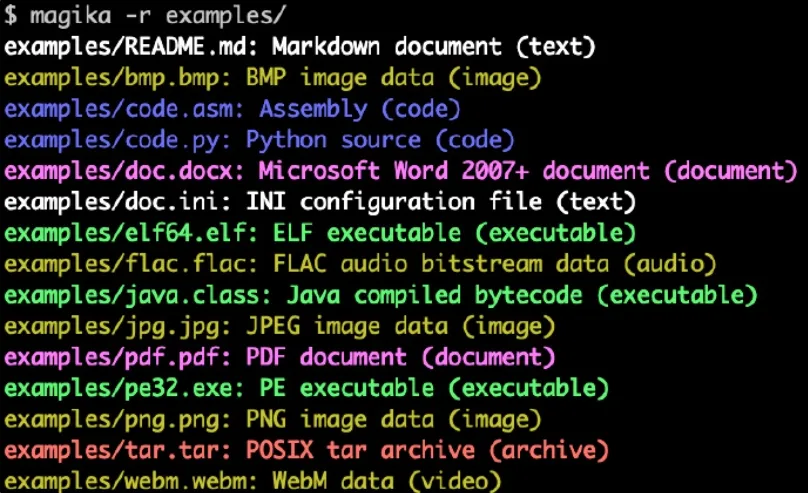
Hier ist ein Beispiel dafür, wie die Ausgabe der Magika-Befehlszeile aussieht:
Für mehr Kontext können Sie unseren ersten Ankündigungsbeitrag im OSS-Blog von Google lesen

Wichtig
Wir sind dabei, eine Reihe neuer Dinge zu veröffentlichen, und sie stehen zum Testen bereit!
Ein neues ML-Modell mit Unterstützung für mehr als 200 Inhaltstypen.
Eine neue in Rust geschriebene CLI. Dies ersetzt die bisherige in Python geschriebene CLI. Weitere Informationen hier. Die Rust-Codebasis kann auch für in Rust geschriebene Anwendungen verwendet werden, siehe Dokumentation.
Python-Paket 0.6.0rc1: Diese Version liefert das neue Modell mit Unterstützung für mehr als 200 Inhaltstypen, der in Rust geschriebenen CLI (die die alte in Python geschriebene ersetzt) und einer überarbeiteten Python-API mit einigen wichtigen Änderungen, siehe Dokumentation und das Changelog! Wenn Sie Dokumente zur stabilen Version benötigen, durchsuchen Sie dieses Repository mit dem neuesten Stable-Tag hier.
Verfügbar als in Rust geschriebenes Befehlszeilentool, als Python-API, als Rust-API und als experimentelle TFJS-Version (die unsere Webdemo unterstützt).
Trainiert anhand eines Datensatzes von über 25 Millionen Dateien mit mehr als 100 Inhaltstypen.
Nach unserer Bewertung erreicht Magika eine durchschnittliche Präzision und Erinnerung von über 99 % und übertrifft damit bestehende Ansätze.
Mehr als 200 Inhaltstypen (siehe vollständige Liste).
Nachdem das Modell geladen wurde (dies ist ein einmaliger Mehraufwand), beträgt die Inferenzzeit etwa 5 ms pro Datei.
Stapelverarbeitung: Sie können mehrere Dateien gleichzeitig an die Befehlszeile und die API übergeben, und Magika verwendet Stapelverarbeitung, um die Inferenzzeit zu beschleunigen. Sie können Magika sogar mit Tausenden von Dateien gleichzeitig aufrufen. Sie können -r auch zum rekursiven Scannen eines Verzeichnisses verwenden.
Nahezu konstante Inferenzzeit unabhängig von der Dateigröße; Magika verwendet nur eine begrenzte Teilmenge der Bytes der Datei.
Magika verwendet ein Schwellenwertsystem pro Inhaltstyp, das bestimmt, ob der Vorhersage für das Modell „vertrauen“ oder ob eine generische Bezeichnung wie „Generisches Textdokument“ oder „Unbekannte Binärdaten“ zurückgegeben werden soll.
Unterstützt drei verschiedene Vorhersagemodi, die die Fehlertoleranz optimieren: high-confidence , medium-confidence und best-guess .
Es ist Open Source! (Und es kommt noch mehr.)
Weitere Einzelheiten finden Sie in der Dokumentation zum Python-Paket und zum JS-Paket (Dev-Dokumente).
Erste Schritte
Python-Befehlszeile
Python-API
Experimentelles TFJS-Modell und NPM-Paket
Installation
Läuft auf Docker
Verwendung
Entwicklungs-Setup
Wichtige Dokumentation
Bekannte Einschränkungen und Beiträge
Häufig gestellte Fragen
Zusätzliche Ressourcen
Forschungsarbeit und Zitat
Lizenz
Haftungsausschluss
Magika ist als magika auf PyPI verfügbar:
$ pip Magika installieren
Wenn Sie Magika nur als Befehlszeile verwenden möchten, können Sie stattdessen $ pipx install magika verwenden.
git clone https://github.com/google/magika cd magika/ docker build -t magika . docker run -it --rm -v $(pwd):/magika magika -r /magika/tests_data
Die neue Befehlszeile ist in Rust geschrieben und im magika -Python-Paket verfügbar.
Beispiele:
$ cd tests_data/basic && magika -r *asm/code.asm: Assembly (Code) batch/simple.bat: DOS-Batchdatei (Code) c/code.c: C-Quelle (Code) css/code.css: CSS-Quelle (Code) csv/magika_test.csv: CSV-Dokument (Code) dockerfile/Dockerfile: Dockerfile (Code) docx/doc.docx: Microsoft Word 2007+ Dokument (Dokument) epub/doc.epub: EPUB-Dokument (Dokument) epub/magika_test.epub: EPUB-Dokument (Dokument) flac/test.flac: FLAC-Audio-Bitstream-Daten (Audio) handlebars/example.handlebars: Lenkerquelle (Code) html/doc.html: HTML-Dokument (Code) ini/doc.ini: INI-Konfigurationsdatei (Text) javascript/code.js: JavaScript-Quelle (Code) jinja/example.j2: Jinja-Vorlage (Code) jpeg/magika_test.jpg: JPEG-Bilddaten (Bild) json/doc.json: JSON-Dokument (Code) latex/sample.tex: LaTeX-Dokument (Text) makefile/simple.Makefile: Makefile-Quelle (Code) markdown/README.md: Markdown-Dokument (Text) [...]
$ magika ./tests_data/basic/python/code.py --json
[
{ „path“: „./tests_data/basic/python/code.py“, „result“: { „status“: „ok“, „value“: { „dl“: { „description“: „Python-Quelle“ , „extensions“: [ „py“, „pyi“
], „group“: „code“, „is_text“: true, „label“: „python“, „mime_type“: „text/x-python“
}, „output“: { „description“: „Python-Quelle“, „extensions“: [ „py“, „pyi“
], „group“: „code“, „is_text“: true, „label“: „python“, „mime_type“: „text/x-python“
}, „Score“: 0,753000020980835
}
}
}
]$ cat doc.ini | Magie - -: INI-Konfigurationsdatei (Text)
$magika --help
Bestimmt den Inhaltstyp von Dateien mit Deep-Learning
Verwendung: magika [OPTIONEN] [PFAD]...
Argumente: [PFAD]...
Liste der Pfade zu den zu analysierenden Dateien.
Verwenden Sie einen Bindestrich (-), um aus der Standardeingabe zu lesen (kann nur einmal verwendet werden).
Optionen:
-r, --recursive
Identifiziert Dateien in Verzeichnissen, anstatt das Verzeichnis selbst zu identifizieren
--no-dereferenz
Identifiziert symbolische Links so, wie sie sind, anstatt ihren Inhalt dadurch zu identifizieren, dass man ihnen folgt
--Farben
Druckt unabhängig von der Terminalunterstützung mit Farben
--keine-Farben
Druckt unabhängig von der Terminalunterstützung ohne Farben
-s, --output-score
Gibt zusätzlich zum Inhaltstyp den Vorhersagewert aus
-i, --mime-type
Gibt den MIME-Typ anstelle der Inhaltstypbeschreibung aus
-l, --label
Druckt eine einfache Beschriftung anstelle der Beschreibung des Inhaltstyps
--json
Druckt im JSON-Format
--jsonl
Druckt im JSONL-Format
--format <BENUTZERDEFINIERT>
Druckt in einem benutzerdefinierten Format (für Details verwenden Sie --help).
Die folgenden Platzhalter werden unterstützt:
%p Der Dateipfad
%l Die eindeutige Bezeichnung, die den Inhaltstyp identifiziert
%d Die Beschreibung des Inhaltstyps
%g Die Gruppe des Inhaltstyps
%m Der MIME-Typ des Inhaltstyps
%e Mögliche Dateierweiterungen für den Inhaltstyp
%s Die Punktzahl des Inhaltstyps für die Datei
%S Die Bewertung des Inhaltstyps für die Datei in Prozent
%b Die Modellausgabe, wenn sie überschrieben wird (andernfalls leer)
%% Ein Literal %
-h, --help
Hilfe drucken (Zusammenfassung mit '-h' anzeigen)
-V, --version
DruckversionEine ausführlichere Dokumentation finden Sie hier.
Beispiele:
>>> from magika import Magika>>> m = Magika()>>> res = m.identify_bytes(b"# BeispielnDies ist ein Beispiel für Markdown!")>>> print(res.output.label)markdown
Ausführliche Dokumentation finden Sie in der Python-Dokumentation.
Wir bieten Magika auch als experimentelles Paket für Personen an, die an der Verwendung in einer Web-App interessiert sind. Beachten Sie, dass die Leistung der Magika JS-Implementierung deutlich langsamer ist und Sie damit rechnen sollten, mehr als 100 ms pro Datei aufzuwenden.
Weitere Informationen finden Sie in der js-Dokumentation.
Weitere Informationen finden Sie im Abschnitt „Entwicklungssetup“ in den Python-Dokumenten.
Dokumentation zur CLI
Dokumentation zur neuen Rust CLI
Dokumentation über die Bindungen für verschiedene Sprachen
Liste der unterstützten Inhaltstypen (für Version 1, weitere folgen).
Liste der unterstützten Inhaltstypen für das neue Modell
Dokumentation zur Interpretation von Magikas Ausgabe.
Häufig gestellte Fragen
Magika verbessert sich deutlich gegenüber dem Stand der Technik, aber es gibt immer Raum für Verbesserungen! Es kann noch mehr Arbeit geleistet werden, um die Erkennungsgenauigkeit zu erhöhen, zusätzliche Inhaltstypen zu unterstützen, Bindungen für mehr Sprachen usw. durchzuführen.
Diese erste Version zielt nicht auf die Erkennung von Polyglotten ab und wir freuen uns auf die Beispiele von Gegnern aus der Community. Wir würden uns auch freuen, von der Community über aufgetretene Probleme, Fehlerkennungen, Funktionswünsche, Bedarf an Unterstützung für zusätzliche Inhaltstypen usw. zu hören.
Sehen Sie sich unsere offenen GitHub-Probleme an, um zu sehen, was auf unserer Roadmap steht. Bitte melden Sie Fehlerkennungen oder Funktionswünsche, indem Sie entweder GitHub-Probleme öffnen (bevorzugt) oder uns eine E-Mail an [email protected] senden.
HINWEIS: Senden Sie KEINE Berichte über Dateien, die personenbezogene Daten enthalten könnten, da der Bericht (einen kleinen) Teil des Dateiinhalts enthält!
Weitere Informationen finden Sie unter CONTRIBUTING.md .
Wir haben hier eine Reihe von FAQs zusammengestellt.
Googles OSS-Blogbeitrag zur Magika-Ankündigung.
Web-Demo: Web-Demo.
In unserer Forschungsarbeit beschreiben wir, wie wir Magika entwickelt haben und welche Entscheidungen wir getroffen haben.
Wenn Sie diese Software für Ihre Recherche nutzen, zitieren Sie sie bitte wie folgt:
@misc{magika, title={{Magika: AI-Powered Content-Type Detection}}, author={{Fratantonio, Yanick und Invernizzi, Luca und Farah, Loua und Kurt, Thomas und Zhang, Marina und Albertini, Ange und Galilee , Francois und Metitieri, Giancarlo und Cretin, Julien und Petit-Bianco, Alexandre und Tao, David und Bursztein, Elie}}, Jahr={2024}, eprint={2409.13768}, archivePrefix={arXiv}, PrimaryClass={cs. CR}, url={https://arxiv.org/abs/2409.13768},
}Bitte kontaktieren Sie uns direkt unter [email protected]
Apache 2.0; Weitere Informationen finden Sie unter LICENSE .
Dieses Projekt ist kein offizielles Google-Projekt. Es wird von Google nicht unterstützt und Google lehnt ausdrücklich jegliche Gewährleistung hinsichtlich seiner Qualität, Marktgängigkeit oder Eignung für einen bestimmten Zweck ab.