Dieses Projekt wurde basierend auf dem Projekt https://github.com/Spritualkb/yuque-spider-plus/ geändert
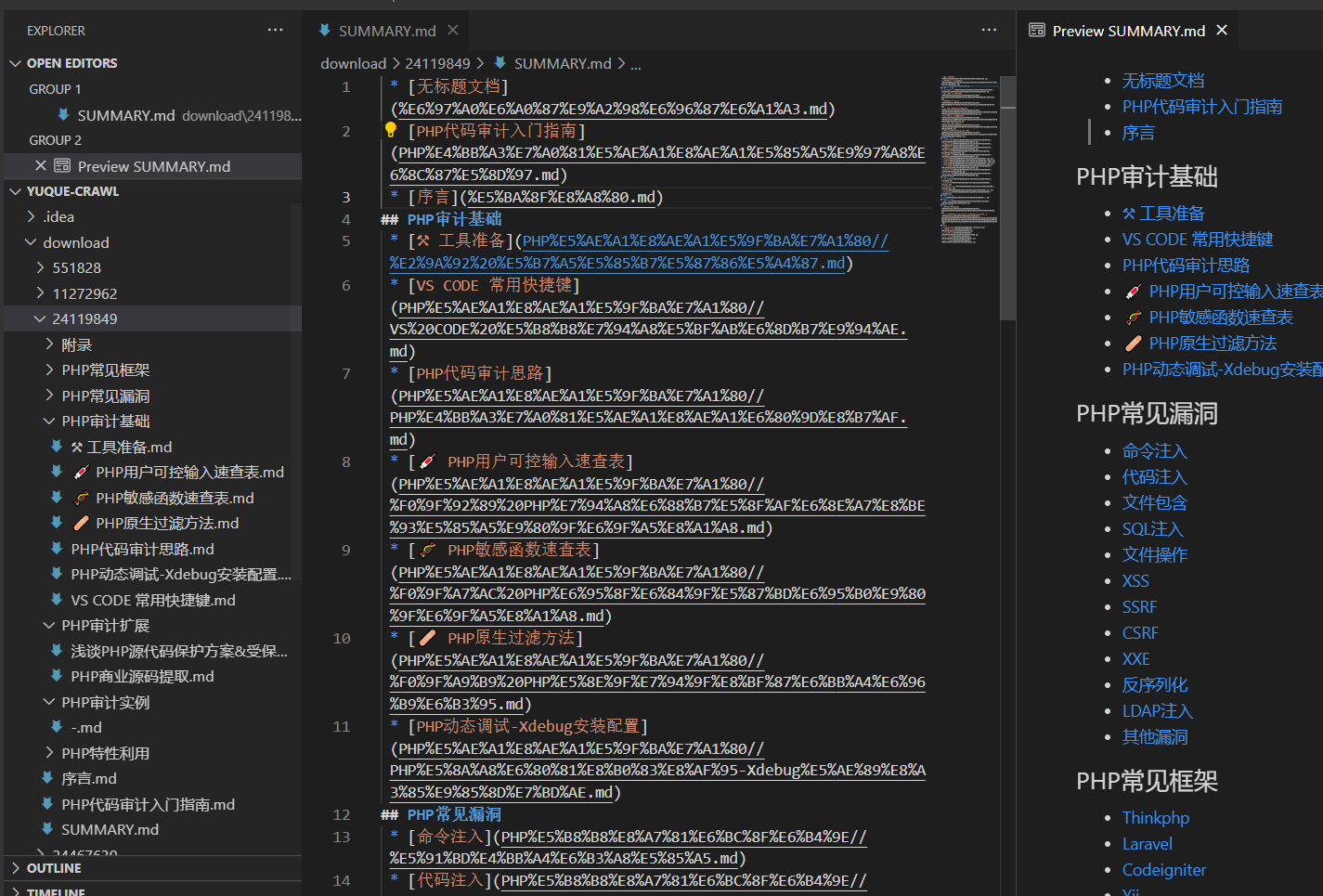
Das Yuque-Tool zum Crawlen von Dokumenten (Crawler) kann die gesamte Yuque-Wissensdatenbank jedes Benutzers im Markdown-Format speichern (einschließlich der vollständigen Verzeichnisstruktur und des Index). Es behebt das Problem, dass Sonderzeichen in Dateinamen zu nicht vorhandenen Pfaden führen.

Verwendung: Python3 installieren
https://www.python.org/downloads/
Führen Sie das Installations- und Ausführungsmodul aus
pip install requests tqdm urllib3Führen Sie den Crawl aus:
python3 main.py 语雀文档地址
Demo: python3 main.py https://www.yuque.com/burpheart/phpaudit
在没有登录语雀的情况下:
复制别人知识库时,查看cookie
在登录语雀的情况下:
直接复制所有cookie

Befehlszeile
Beispiel 1: Geben Sie URL und Cookie an
python main.py " https://www.yuque.com/burpheart/phpaudit " --cookie " verified_books=**** "Beispiel 2: Geben Sie URL, Cookie und Ausgabepfad an
python main . py "https://www.yuque.com/burpheart/phpaudit" - - cookie "verified_books=****" - - output "download"Beispiel 3: Geben Sie nur die URL an
python main.py " https://www.yuque.com/burpheart/phpaudit "Beispiel 4: Geben Sie URL und Ausgabepfad an
python main.py " https://www.yuque.com/burpheart/phpaudit " --output " download "Beispiel 5: Standardparameter verwenden (Hilfeinformationen anzeigen)
python main.pyUm das Problem zu beheben, dass einige Bilder nicht lokal geladen werden können, laden Sie die Netzwerkbilder herunter und ersetzen Sie den dem Markdown entsprechenden Bildpfad durch den relativen Pfad ./assets.