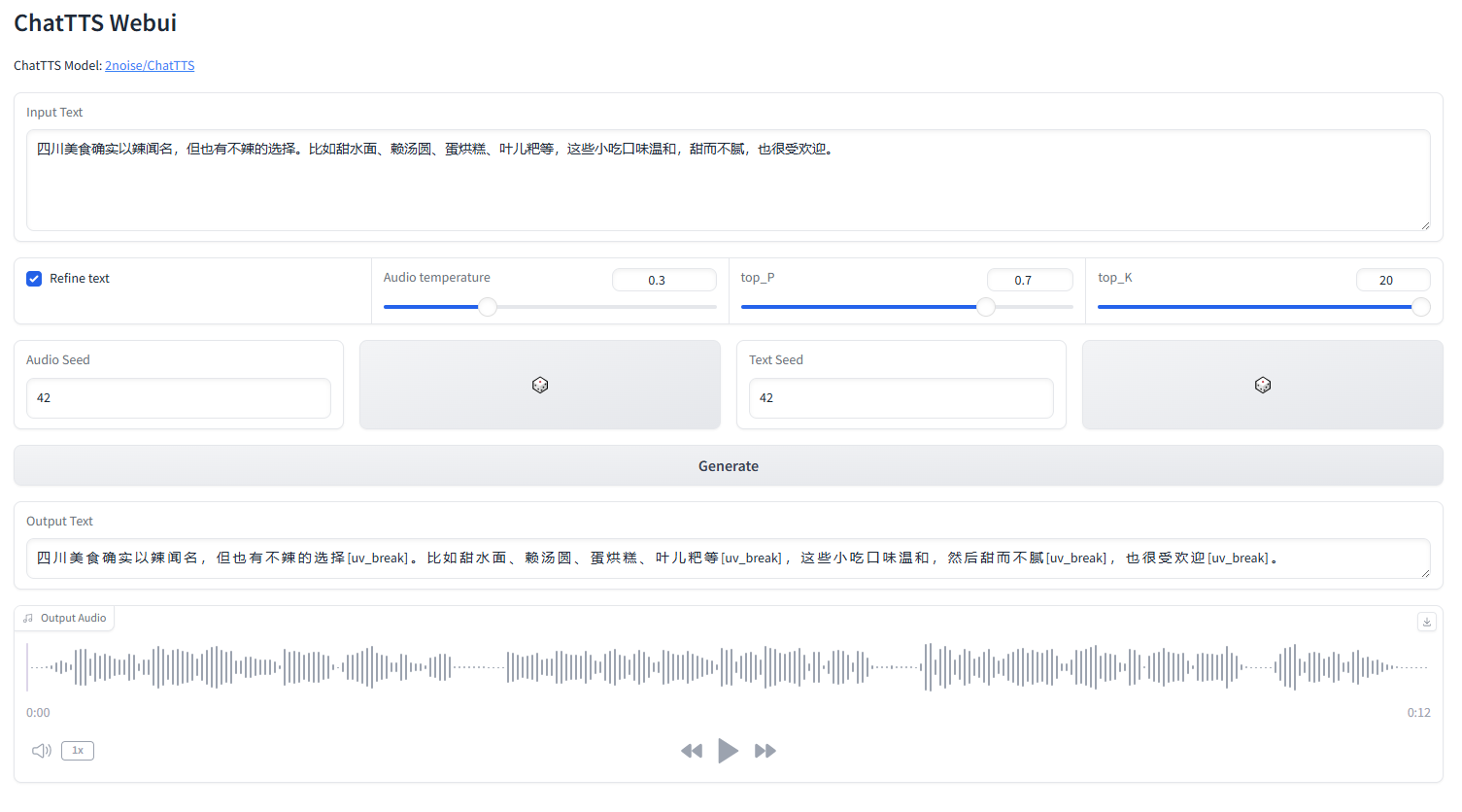
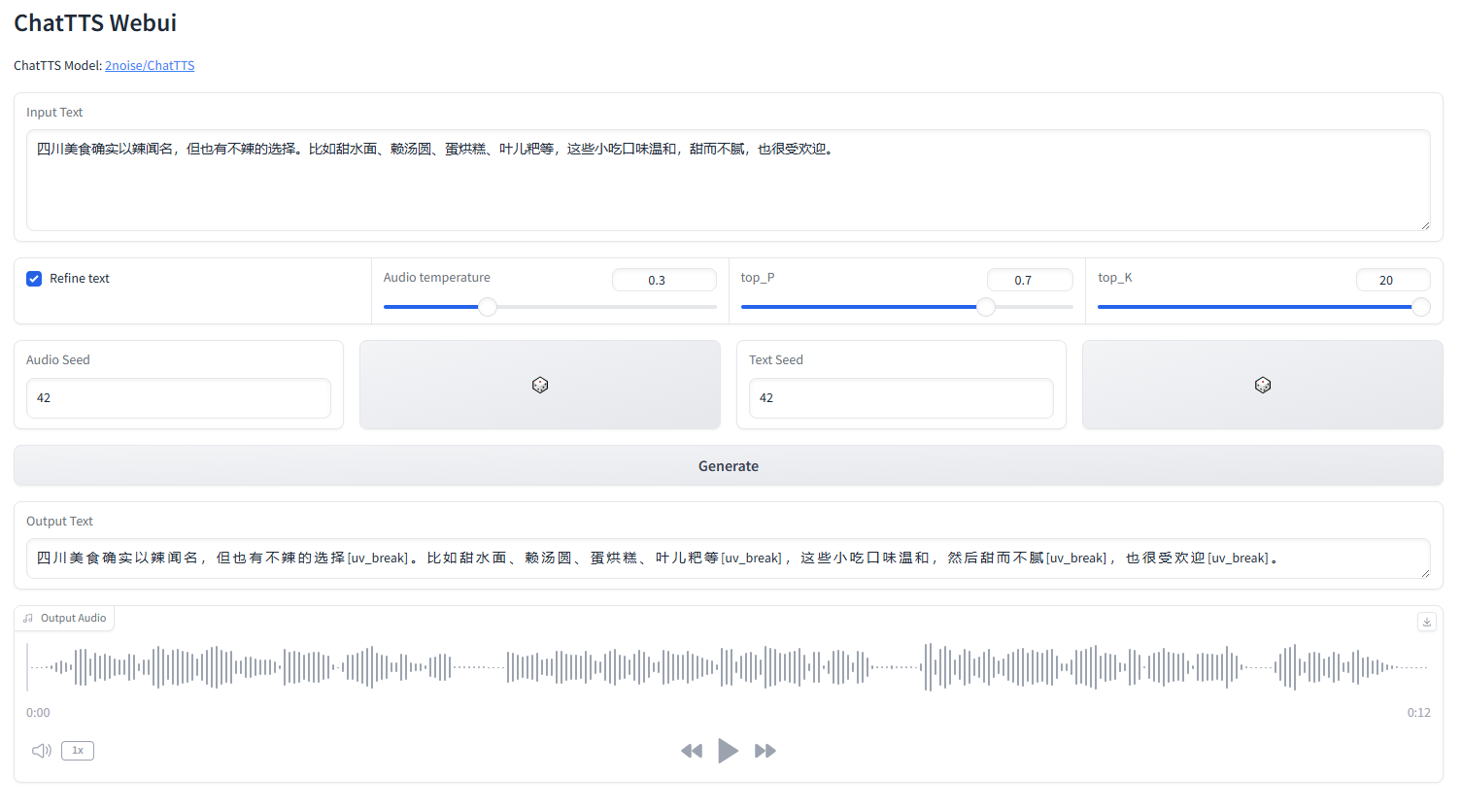
die ChatTTS-Weboberfläche
Starten Sie webui.py
python webui.py
python webui.py --server_port=8080conda create -n chattts python=3.9
conda activate chattts
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
pip install omegaconf vocos transformers vector-quantize-pytorchEnglisch |中文简体
ChatTTS ist ein Text-to-Speech-Modell, das speziell für Dialogszenarien wie den LLM-Assistenten entwickelt wurde. Es unterstützt sowohl Englisch als auch Chinesisch. Unser Modell verfügt über mehr als 100.000 Stunden Training in Chinesisch und Englisch. Die Open-Source-Version auf HuggingFace ist ein 40.000 Stunden vorab trainiertes Modell ohne SFT.
Für formelle Anfragen zu Modell und Roadmap kontaktieren Sie uns bitte unter [email protected]. Sie können unserer QQ-Gruppe beitreten: 808364215 zur Diskussion. Das Hinzufügen von Github-Problemen ist immer willkommen.
Eine detaillierte Beschreibung des Modells finden Sie im Video auf Bilibili
Dieses Repo dient ausschließlich akademischen Zwecken. Es ist für Bildungs- und Forschungszwecke bestimmt und sollte nicht für kommerzielle oder rechtliche Zwecke verwendet werden. Die Autoren übernehmen keine Gewähr für die Richtigkeit, Vollständigkeit oder Zuverlässigkeit der Informationen. Die in diesem Repo verwendeten Informationen und Daten dienen ausschließlich akademischen und Forschungszwecken. Die Daten stammen aus öffentlich zugänglichen Quellen und die Autoren erheben keinen Anspruch auf Eigentums- oder Urheberrechte an den Daten.
ChatTTS ist ein leistungsstarkes Text-to-Speech-System. Es ist jedoch sehr wichtig, diese Technologie verantwortungsvoll und ethisch zu nutzen. Um die Verwendung von ChatTTS einzuschränken, haben wir während des Trainings des 40.000-Stunden-Modells eine kleine Menge hochfrequenten Rauschens hinzugefügt und die Audioqualität mithilfe des MP3-Formats so weit wie möglich komprimiert, um zu verhindern, dass böswillige Akteure sie möglicherweise für Kriminelle nutzen Zwecke. Gleichzeitig haben wir intern ein Erkennungsmodell trainiert und planen, es in Zukunft als Open Source bereitzustellen.
import ChatTTS
from IPython . display import Audio
chat = ChatTTS . Chat ()
chat . load_models ()
texts = [ "" ,]
wavs = chat . infer ( texts , use_decoder = True )
Audio ( wavs [ 0 ], rate = 24_000 , autoplay = True ) ###################################
# Sample a speaker from Gaussian.
import torch
std , mean = torch . load ( 'ChatTTS/asset/spk_stat.pt' ). chunk ( 2 )
rand_spk = torch . randn ( 768 ) * std + mean
params_infer_code = {
'spk_emb' : rand_spk , # add sampled speaker
'temperature' : .3 , # using custom temperature
'top_P' : 0.7 , # top P decode
'top_K' : 20 , # top K decode
}
###################################
# For sentence level manual control.
# use oral_(0-9), laugh_(0-2), break_(0-7)
# to generate special token in text to synthesize.
params_refine_text = {
'prompt' : '[oral_2][laugh_0][break_6]'
}
wav = chat . infer ( "" , params_refine_text = params_refine_text , params_infer_code = params_infer_code )
###################################
# For word level manual control.
text = 'What is [uv_break]your favorite english food?[laugh][lbreak]'
wav = chat . infer ( text , skip_refine_text = True , params_infer_code = params_infer_code ) inputs_en = """
chat T T S is a text to speech model designed for dialogue applications.
[uv_break]it supports mixed language input [uv_break]and offers multi speaker
capabilities with precise control over prosodic elements [laugh]like like
[uv_break]laughter[laugh], [uv_break]pauses, [uv_break]and intonation.
[uv_break]it delivers natural and expressive speech,[uv_break]so please
[uv_break] use the project responsibly at your own risk.[uv_break]
""" . replace ( ' n ' , '' ) # English is still experimental.
params_refine_text = {
'prompt' : '[oral_2][laugh_0][break_4]'
}
audio_array_cn = chat . infer ( inputs_cn , params_refine_text = params_refine_text )
audio_array_en = chat . infer ( inputs_en , params_refine_text = params_refine_text )Für einen 30-sekündigen Audioclip sind mindestens 4 GB GPU-Speicher erforderlich. Für die 4090D-GPU kann sie Audio erzeugen, das etwa 7 semantischen Token pro Sekunde entspricht. Der Echtzeitfaktor (RTF) liegt bei etwa 0,65.
Dies ist ein Problem, das typischerweise bei autoregressiven Modellen (für Bark und Valle) auftritt. Es ist im Allgemeinen schwer zu vermeiden. Man kann mehrere Proben ausprobieren, um ein passendes Ergebnis zu finden.
Im aktuell veröffentlichten Modell sind die einzigen Steuereinheiten auf Token-Ebene [laugh], [uv_break] und [lbreak]. In zukünftigen Versionen werden wir möglicherweise Open-Source-Modelle mit zusätzlichen emotionalen Kontrollfunktionen veröffentlichen.