DeepKE
DeepKE 2.2.7
Englisch | 简体中文
Ein auf Deep Learning basierendes Toolkit zur Wissensextraktion
für die Konstruktion von Wissensgraphen
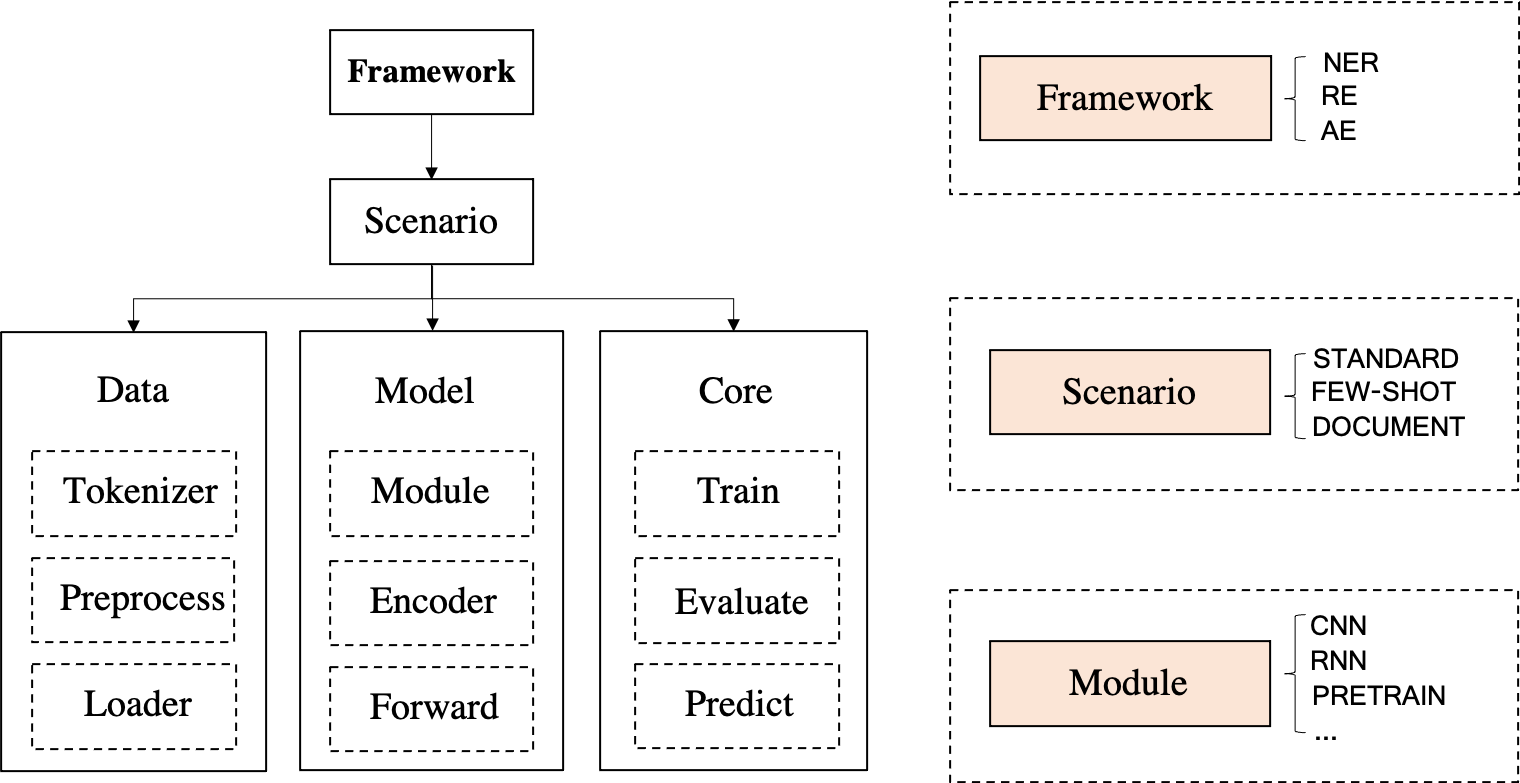
DeepKE ist ein Wissensextraktions-Toolkit für die Erstellung von Wissensgraphen, das cnSchema , ressourcenarme , dokumentenbasierte und multimodale Szenarien für die Entitäts- , Beziehungs- und Attributextraktion unterstützt. Für Einsteiger stellen wir Dokumente, Online-Demos, Papiere, Folien und Poster zur Verfügung.
\ in Dateipfaden;wisemodel oder modescape .Wenn Sie während der Installation von DeepKE und DeepKE-LLM auf Probleme stoßen, lesen Sie bitte die Tipps oder reichen Sie umgehend ein Problem ein. Wir helfen Ihnen dann bei der Lösung des Problems!
April, 2024 Wir veröffentlichen ein neues zweisprachiges (Chinesisch und Englisch) schemabasiertes Informationsextraktionsmodell namens OneKE, das auf Chinese-Alpaca-2-13B basiert.Feb, 2024 Wir veröffentlichen einen umfangreichen (0,32 Milliarden Token) hochwertigen zweisprachigen (Chinesisch und Englisch) Informationsextraktions-(IE)-Anweisungsdatensatz mit dem Namen IEPile, zusammen mit zwei mit IEPile trainierten Modellen, baichuan2-13b-iepile-lora und llama2 -13b-iepile-lora.Sep 2023 wurde ein zweisprachiger Chinesisch-Englisch-Information Extraction (IE)-Anweisungsdatensatz namens InstructIE für die anweisungsbasierte Knowledge Graph Construction Task (anweisungsbasierte KGC) veröffentlicht, wie hier beschrieben.June, 2023 Wir aktualisieren DeepKE-LLM, um die Wissensextraktion mit KnowLM, ChatGLM, LLaMA-Serie, GPT-Serie usw. zu unterstützen.Apr, 2023 Wir haben neue Modelle hinzugefügt, darunter CP-NER(IJCAI'23), ASP(EMNLP'22), PRGC(ACL'21), PURE(NAACL'21), bereitgestellte Ereignisextraktionsfunktionen (Chinesisch und Englisch), und bot Kompatibilität mit höheren Versionen von Python-Paketen (z. B. Transformers).Feb, 2023 Wir haben die Verwendung von LLM (GPT-3) mit kontextbezogenem Lernen (basierend auf EasyInstruct) und Datengenerierung unterstützt und ein NER-Modell W2NER (AAAI'22) hinzugefügt. Nov, 2022 Fügen Sie Datenanmerkungsanweisungen für die Entitätserkennung und Beziehungsextraktion, die automatische Kennzeichnung schwach überwachter Daten (Entitätsextraktion und Beziehungsextraktion) hinzu und optimieren Sie das Multi-GPU-Training.
Sept, 2022 Das Papier DeepKE: A Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population wurde vom EMNLP 2022 System Demonstration Track angenommen.
Aug, 2022 Wir haben Datenerweiterungsunterstützung (Chinesisch, Englisch) für die Extraktion von Beziehungen mit geringem Ressourcenaufwand hinzugefügt.
June, 2022 Wir haben multimodale Unterstützung für die Extraktion von Entitäten und Beziehungen hinzugefügt.
May, 2022 Wir haben DeepKE-cnschema mit handelsüblichen Wissensextraktionsmodellen veröffentlicht.
Jan, 2022 Wir haben den Artikel „DeepKE: A Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population“ veröffentlicht
Dec, 2021 Wir haben dockerfile hinzugefügt, um die Umgebung automatisch zu erstellen.
Nov, 2021 Die Demo von DeepKE, die die Echtzeitextraktion ohne Bereitstellung und Schulung unterstützt, wurde veröffentlicht.
Die Dokumentation von DeepKE, die die Details von DeepKE wie Quellcodes und Datensätze enthält, wurde veröffentlicht.
Oct, 2021 pip install deepke
Die Codes von deepke-v2.0 wurden veröffentlicht.
Aug, 2019 Die Codes von deepke-v1.0 wurden veröffentlicht.
Aug, 2018 Das Projekt DeepKE-Startup und die Codes von deepke-v0.1 wurden veröffentlicht.
Es gibt eine Demonstration der Vorhersage. Die GIF-Datei wird von Terminalizer erstellt. Holen Sie sich den Code. 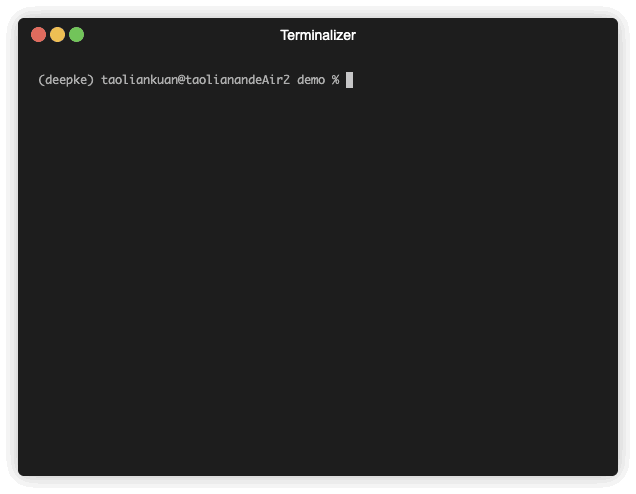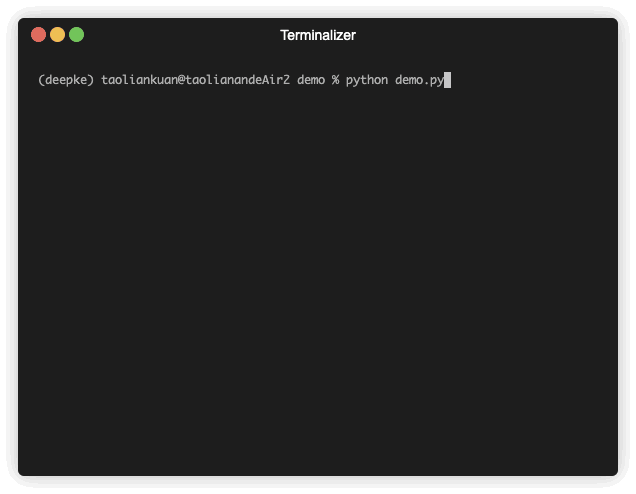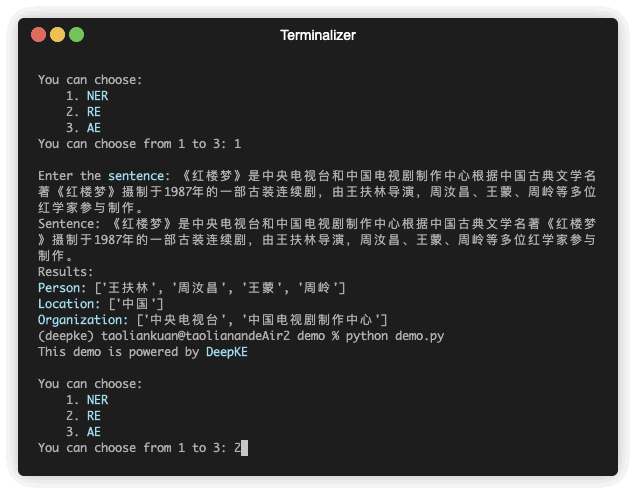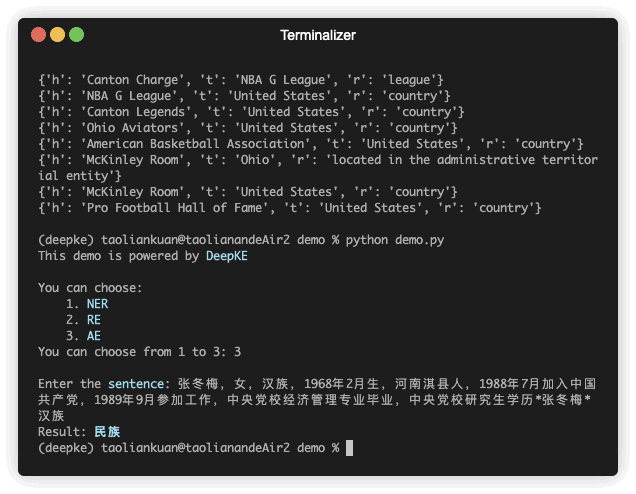
Im Zeitalter großer Modelle nutzt DeepKE-LLM eine völlig neue Umgebungsabhängigkeit.
conda create -n deepke-llm python=3.9
conda activate deepke-llm
cd example/llm
pip install -r requirements.txt
Bitte beachten Sie, dass sich die Datei requirements.txt im Ordner example/llm befindet.
pip install deepke .Schritt 1: Laden Sie den Basiscode herunter
git clone --depth 1 https://github.com/zjunlp/DeepKE.git Schritt 2: Erstellen Sie mit Anaconda eine virtuelle Umgebung und betreten Sie diese.
conda create -n deepke python=3.8
conda activate deepkeInstallieren Sie DeepKE mit Quellcode
pip install -r requirements.txt
python setup.py install
python setup.py develop Installieren Sie DeepKE mit pip ( NICHT empfohlen! ).
pip install deepkeSchritt 3: Geben Sie das Aufgabenverzeichnis ein
cd DeepKE/example/re/standardSchritt 4 Laden Sie den Datensatz herunter oder befolgen Sie die Anmerkungsanweisungen, um Daten zu erhalten
wget 120.27.214.45/Data/re/standard/data.tar.gz
tar -xzvf data.tar.gzViele Arten von Datenformaten werden unterstützt und Einzelheiten finden Sie in jedem Teil.
Step5 Training (Parameter für das Training können im conf -Ordner geändert werden)
Wir unterstützen die visuelle Parameteroptimierung mithilfe von wandb .
python run.py Step6- Vorhersage (Parameter für die Vorhersage können im conf Ordner geändert werden)
Ändern Sie den Pfad des trainierten Modells in predict.yaml . Der absolute Pfad des Modells muss verwendet werden, z. B. xxx/checkpoints/2019-12-03_ 17-35-30/cnn_ epoch21.pth .
python predict.pySchritt 1: Installieren Sie den Docker-Client
Installieren Sie Docker und starten Sie den Docker-Dienst.
Schritt 2: Rufen Sie das Docker-Image ab und führen Sie den Container aus
docker pull zjunlp/deepke:latest
docker run -it zjunlp/deepke:latest /bin/bashDie übrigen Schritte sind dieselben wie ab Schritt 3 in der manuellen Umgebungskonfiguration .
Python == 3.8
Die Erkennung benannter Entitäten versucht, in unstrukturiertem Text erwähnte benannte Entitäten zu lokalisieren und in vordefinierte Kategorien wie Personennamen, Organisationen, Standorte, Organisationen usw. zu klassifizieren.
Die Daten werden in .txt Dateien gespeichert. Einige Beispiele sind wie folgt (Benutzer können Daten basierend auf den Tools Doccano und MarkTool kennzeichnen oder die schwache Überwachung mit DeepKE verwenden, um Daten automatisch abzurufen):
| Satz | Person | Standort | Organisation |
|---|---|---|---|
| 本报北京9月4日讯记者杨涌报道:部分省区人民日报宣传发行工作座谈会9月3日在4日在京举行. | 杨涌 | 北京 | 人民日报 |
| 《红楼梦》由王扶林导演,周汝昌、王蒙、周岭等多位专家参与制作. | 王扶林, 周汝昌, 王蒙, 周岭 | ||
| 秦始皇兵马俑位于陕西省西安市,是世界八大奇迹之一. | 秦始皇 | 陕西省,西安市 |
Lesen Sie den detaillierten Prozess in der spezifischen README-Datei
STANDARD (vollständig überwacht)
Wir unterstützen LLM und stellen das Standardmodell DeepKE-cnSchema-NER bereit, das ohne Schulung Entitäten in cnSchema extrahiert.
Schritt 1 Geben Sie DeepKE/example/ner/standard ein. Laden Sie den Datensatz herunter.
wget 120.27.214.45/Data/ner/standard/data.tar.gz
tar -xzvf data.tar.gz Step2- Schulung
Der Datensatz und die Parameter können im data bzw. im conf -Ordner angepasst werden.
python run.pyStep3- Vorhersage
python predict.pyWENIGE SCHÜSSE
Schritt 1 Geben Sie DeepKE/example/ner/few-shot ein. Laden Sie den Datensatz herunter.
wget 120.27.214.45/Data/ner/few_shot/data.tar.gz
tar -xzvf data.tar.gz Step2 Training im Low-Ressourcen-Setting
Das Verzeichnis, in dem das Modell geladen und gespeichert wird, und die Konfigurationsparameter können im Ordner conf angepasst werden.
python run.py +train=few_shot Benutzer können load_path in conf/train/few_shot.yaml ändern, um das vorhandene geladene Modell zu verwenden.
Schritt 3: Fügen Sie - predict zu conf/config.yaml hinzu, ändern Sie loda_path als Modellpfad und write_path als den Pfad, in dem die vorhergesagten Ergebnisse in conf/predict.yaml gespeichert werden, und führen Sie dann python predict.py aus
python predict.pyMULTIMODAL
Schritt 1 Geben Sie DeepKE/example/ner/multimodal ein. Laden Sie den Datensatz herunter.
wget 120.27.214.45/Data/ner/multimodal/data.tar.gz
tar -xzvf data.tar.gzWir verwenden von RCNN erkannte Objekte und visuelle Erdungsobjekte aus Originalbildern als visuelle lokale Informationen, wobei RCNN über schneller_rcnn und visuelle Erdung über onestage_grounding erfolgt.
Step2 Training im multimodalen Setting
data bzw. im conf -Ordner angepasst werden.load_path in conf/train.yaml als den Pfad, in dem das zuletzt trainierte Modell gespeichert wurde. Und die im Training generierten Pfadspeicherprotokolle können durch log_dir angepasst werden. python run.pyStep3- Vorhersage
python predict.pyUnter Beziehungsextraktion versteht man die Aufgabe, semantische Beziehungen zwischen Entitäten aus einem unstrukturierten Text zu extrahieren.
Die Daten werden in .csv Dateien gespeichert. Einige Beispiele sind wie folgt (Benutzer können Daten basierend auf den Tools Doccano und MarkTool kennzeichnen oder die schwache Überwachung mit DeepKE verwenden, um Daten automatisch abzurufen):
| Satz | Beziehung | Kopf | Head_offset | Schwanz | Tail_offset |
|---|---|---|---|---|---|
| 《岳父也是爹》是王军执导的电视剧, 由马恩然、范明主演. | 导演 | 岳父也是爹 | 1 | 王军 | 8 |
| 《九玄珠》是在纵横中文网连载的一部小说,作者是龙马. | 连载网站 | 九玄珠 | 1 | 纵横中文网 | 7 |
| 提起杭州的美景,西湖总是第一个映入脑海的词语. | 所在城市 | 西湖 | 8 | 杭州 | 2 |
!HINWEIS: Wenn es mehrere Entitätstypen für eine Beziehung gibt, kann den Entitätstypen die Beziehung als Eingaben vorangestellt werden.
Lesen Sie den detaillierten Prozess in der spezifischen README-Datei
STANDARD (vollständig überwacht)
Wir unterstützen LLM und stellen das Standardmodell DeepKE-cnSchema-RE zur Verfügung, das ohne Schulung Beziehungen in cnSchema extrahiert.
Schritt 1: Geben Sie den Ordner DeepKE/example/re/standard ein. Laden Sie den Datensatz herunter.
wget 120.27.214.45/Data/re/standard/data.tar.gz
tar -xzvf data.tar.gz Step2- Schulung
Der Datensatz und die Parameter können im data bzw. im conf -Ordner angepasst werden.
python run.pyStep3- Vorhersage
python predict.pyWENIGE SCHÜSSE
Schritt 1 Geben Sie DeepKE/example/re/few-shot ein. Laden Sie den Datensatz herunter.
wget 120.27.214.45/Data/re/few_shot/data.tar.gz
tar -xzvf data.tar.gz Schritt 2 Training
data bzw. im conf -Ordner angepasst werden.train_from_saved_model in conf/train.yaml als den Pfad, in dem das zuletzt trainierte Modell gespeichert wurde. Und die im Training generierten Pfadspeicherprotokolle können durch log_dir angepasst werden. python run.pyStep3- Vorhersage
python predict.py DOKUMENTIEREN
Schritt 1 Geben Sie DeepKE/example/re/document ein. Laden Sie den Datensatz herunter.
wget 120.27.214.45/Data/re/document/data.tar.gz
tar -xzvf data.tar.gz Step2- Schulung
data bzw. im conf -Ordner angepasst werden.train_from_saved_model in conf/train.yaml als den Pfad, in dem das zuletzt trainierte Modell gespeichert wurde. Und die im Training generierten Pfadspeicherprotokolle können durch log_dir angepasst werden. python run.pyStep3- Vorhersage
python predict.pyMULTIMODAL
Schritt 1 Geben Sie DeepKE/example/re/multimodal ein. Laden Sie den Datensatz herunter.
wget 120.27.214.45/Data/re/multimodal/data.tar.gz
tar -xzvf data.tar.gzWir verwenden von RCNN erkannte Objekte und visuelle Erdungsobjekte aus Originalbildern als visuelle lokale Informationen, wobei RCNN über schneller_rcnn und visuelle Erdung über onestage_grounding erfolgt.
Step2- Schulung
data bzw. im conf -Ordner angepasst werden.load_path in conf/train.yaml als den Pfad, in dem das zuletzt trainierte Modell gespeichert wurde. Und die im Training generierten Pfadspeicherprotokolle können durch log_dir angepasst werden. python run.pyStep3- Vorhersage
python predict.pyBei der Attributextraktion werden Attribute für Entitäten in einem unstrukturierten Text extrahiert.
Die Daten werden in .csv Dateien gespeichert. Einige Beispiele wie folgt:
| Satz | Att | Ent | Ent_offset | Val | Val_offset |
|---|---|---|---|---|---|
| Am 2. Dezember 1968 wurde das Buch veröffentlicht | Nein | 张冬梅 | 0 | 汉族 | 6 |
| 诸葛亮,字孔明,三国时期杰出的军事家、文学家、发明家. | Nein | 诸葛亮 | 0 | 三国时期 | 8 |
| 1. Oktober 2014 | 上映时间 | 黄金时代 | 19 | 1. Oktober 2014 | 0 |
Lesen Sie den detaillierten Prozess in der spezifischen README-Datei
STANDARD (vollständig überwacht)
Schritt 1: Geben Sie den Ordner DeepKE/example/ae/standard ein. Laden Sie den Datensatz herunter.
wget 120.27.214.45/Data/ae/standard/data.tar.gz
tar -xzvf data.tar.gz Step2- Schulung
Der Datensatz und die Parameter können im data bzw. im conf -Ordner angepasst werden.
python run.pyStep3- Vorhersage
python predict.py.tsv Dateien gespeichert, einige Beispiele sind wie folgt:| Satz | Ereignistyp | Auslösen | Rolle | Argument | |
|---|---|---|---|---|---|
| 据《欧洲时报》报道, 当地时间27日, 法国巴黎卢浮宫博物馆员工因不满工作条件恶化而罢工,导致该博物馆也因此闭门谢客一天. | 组织行为-罢工 | 罢工 | 罢工人员 | 法国巴黎卢浮宫博物馆员工 | |
| 时间 | 当地时间27日 | ||||
| 所属组织 | 法国巴黎卢浮宫博物馆 | ||||
| 中国外运2019年上半年归母净利润增长17%: 收购了少数股东股权 | 财经/交易-出售/收购 | 收购 | 出售方 | 少数股东 | |
| 收购方 | 中国外运 | ||||
| 交易物 | 股权 | ||||
| 美国亚特兰大航展13日发生一起表演机坠机事故,飞行员弹射出舱并安全着陆,事故没有造成人员伤亡. | 灾害/意外-坠机 | 坠机 | 时间 | 13. Oktober | |
| 地点 | 美国亚特兰 | ||||
Lesen Sie den detaillierten Prozess in der spezifischen README-Datei
STANDARD (vollständig überwacht)
Schritt 1: Geben Sie den Ordner DeepKE/example/ee/standard ein. Laden Sie den Datensatz herunter.
wget 120.27.214.45/Data/ee/DuEE.zip
unzip DuEE.zipSchritt 2 Training
Der Datensatz und die Parameter können im data bzw. im conf -Ordner angepasst werden.
python run.pySchritt 3 Vorhersage
python predict.py 1. Using nearest mirror , THU in China, wird die Installation von Anaconda beschleunigen; Aliyun in China wird pip install XXX beschleunigen .
2.Wenn ModuleNotFoundError: No module named 'past' auftritt, führen Sie pip install future aus.
3. Die Online-Installation der vorab trainierten Sprachmodelle dauert langsam. Wir empfehlen, vorab trainierte Modelle vor der Verwendung herunterzuladen und im pretrained Ordner zu speichern. Lesen Sie README.md in jedem Aufgabenverzeichnis, um die spezifischen Anforderungen zum Speichern vorab trainierter Modelle zu überprüfen.
4. Die alte Version von DeepKE befindet sich im Zweig deepke-v1.0. Benutzer können den Zweig ändern, um die alte Version zu verwenden. Die alte Version wurde komplett auf die Standard-Relationsextraktion (example/re/standard) umgestellt.
5.Wenn Sie den Quellcode ändern möchten, wird empfohlen, DeepKE mit Quellcodes zu installieren. Wenn nicht, funktioniert die Änderung nicht. Siehe Problem
6.Weitere verwandte Arbeiten zur Wissensextraktion mit geringen Ressourcen finden Sie in Knowledge Extraction in Low-Ressource Scenarios: Survey and Perspective.
7. Stellen Sie sicher, dass die genauen Versionen der Anforderungen in requirements.txt vorliegen.
In der nächsten Version planen wir die Veröffentlichung eines stärkeren LLM für KE.
In der Zwischenzeit bieten wir eine langfristige Wartung an, um Fehler zu beheben , Probleme zu lösen und neue Anforderungen zu erfüllen. Wenn Sie also Probleme haben, wenden Sie sich bitte an uns.
Dateneffiziente Konstruktion von Wissensgraphen, 高效知识图谱构建 (Tutorial zu CCKS 2022) [Folien]
Effiziente und robuste Konstruktion von Wissensgraphen (Tutorial zu AACL-IJCNLP 2022) [Folien]
PromptKG-Familie: eine Galerie mit Forschungsarbeiten, Toolkits und Papierlisten zum Thema Prompt Learning und KG [Ressourcen]
Wissensextraktion in ressourcenarmen Szenarien: Umfrage und Perspektive [Umfrage][Papierliste]
Doccano、MarkTool、LabelStudio: Datenanmerkungs-Toolkits
LambdaKG: Eine Bibliothek und Benchmark für PLM-basierte KG-Einbettungen
EasyInstruct: Ein benutzerfreundliches Framework zum Unterrichten großer Sprachmodelle
Lesematerialien :
Dateneffiziente Konstruktion von Wissensgraphen, 高效知识图谱构建 (Tutorial zu CCKS 2022) [Folien]
Effiziente und robuste Konstruktion von Wissensgraphen (Tutorial zu AACL-IJCNLP 2022) [Folien]
PromptKG-Familie: eine Galerie mit Forschungsarbeiten, Toolkits und Papierlisten zum Thema Prompt Learning und KG [Ressourcen]
Wissensextraktion in ressourcenarmen Szenarien: Umfrage und Perspektive [Umfrage][Papierliste]
Zugehöriges Toolkit :
Doccano、MarkTool、LabelStudio: Datenanmerkungs-Toolkits
LambdaKG: Eine Bibliothek und Benchmark für PLM-basierte KG-Einbettungen
EasyInstruct: Ein benutzerfreundliches Framework zum Unterrichten großer Sprachmodelle
Bitte zitieren Sie unseren Artikel, wenn Sie DeepKE in Ihrer Arbeit verwenden
@inproceedings { EMNLP2022_Demo_DeepKE ,
author = { Ningyu Zhang and
Xin Xu and
Liankuan Tao and
Haiyang Yu and
Hongbin Ye and
Shuofei Qiao and
Xin Xie and
Xiang Chen and
Zhoubo Li and
Lei Li } ,
editor = { Wanxiang Che and
Ekaterina Shutova } ,
title = { DeepKE: {A} Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population } ,
booktitle = { {EMNLP} (Demos) } ,
pages = { 98--108 } ,
publisher = { Association for Computational Linguistics } ,
year = { 2022 } ,
url = { https://aclanthology.org/2022.emnlp-demos.10 }
}Ningyu Zhang, Haofen Wang, Fei Huang, Feiyu Xiong, Liankuan Tao, Xin Xu, Honghao Gui, Zhenru Zhang, Chuanqi Tan, Qiang Chen, Xiaohan Wang, Zekun Xi, Xinrong Li, Haiyang Yu, Hongbin Ye, Shuofei Qiao, Peng Wang , Yuqi Zhu, Xin Xie, Xiang Chen, Zhoubo Li, Lei Li, Xiaozhuan Liang, Yunzhi Yao, Jing Chen, Yuqi Zhu, Shumin Deng, Wen Zhang, Guozhou Zheng, Huajun Chen
Community-Mitwirkende: thredreams, eltociear, Ziwen Xu, Rui Huang, Xiaolong Weng


