
Xuan Ju 1* , Yiming Gao 1* , Zhaoyang Zhang 1*# , Ziyang Yuan 1 , Xintao Wang 1 , Ailing Zeng, Yu Xiong, Qiang Xu, Ying Shan 1
1 ARC Lab, Tencent PCG 2 The Chinese University of Hong Kong * Gleicher Beitrag # Projektleiter
Videodatensätze spielen eine entscheidende Rolle bei der Videogenerierung wie Sora. Bestehende Text-Video-Datensätze sind jedoch häufig unzureichend, wenn es darum geht , lange Videosequenzen zu verarbeiten und Aufnahmeübergänge zu erfassen . Um diese Einschränkungen zu beheben, führen wir MiraData ein, einen Videodatensatz, der speziell für Aufgaben zur Erstellung langer Videos entwickelt wurde. Um die zeitliche Konsistenz und Bewegungsintensität bei der Videogenerierung besser beurteilen zu können, führen wir außerdem MiraBench ein, das bestehende Benchmarks um 3D-Konsistenz und Tracking-basierte Bewegungsstärkemetriken erweitert. Weitere Details finden Sie in unserem Forschungspapier.
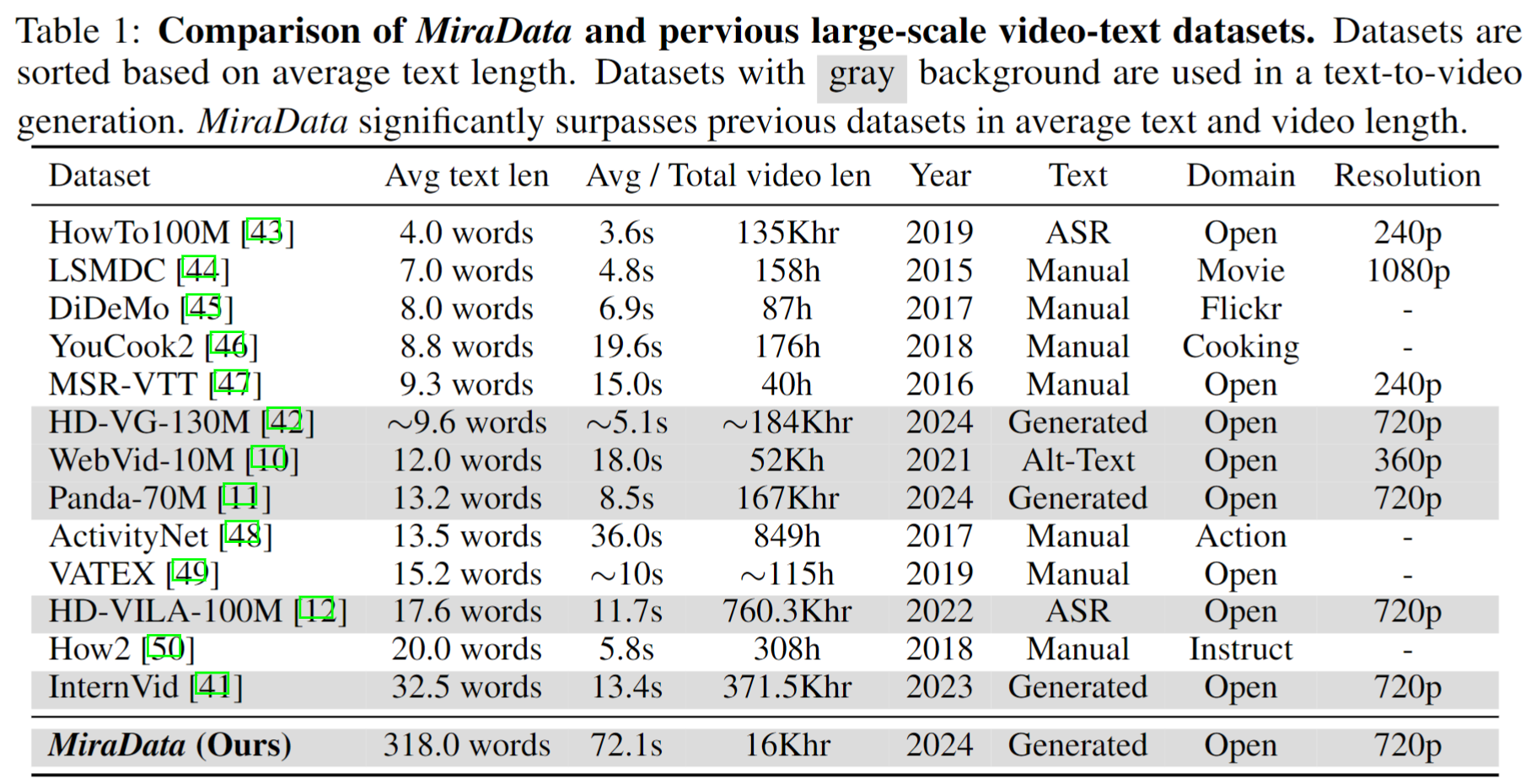
Wir veröffentlichen vier Versionen von MiraData, die 330K-, 93K-, 42K- und 9K-Daten enthalten.
Die Metadatei für diese Version von MiraData wird in Google Drive und HuggingFace Dataset bereitgestellt. Um die Zusammensetzung unserer Metadatei besser und schneller zu verstehen, greifen wir außerdem nach dem Zufallsprinzip auf eine Reihe von 100 Videoclips zurück, auf die hier zugegriffen werden kann. Die Metadatei enthält die folgenden Indexinformationen:
{download_id}.{clip_id}Um die Videos herunterzuladen und in Clips aufzuteilen, laden Sie zunächst die Metadateien von Google Drive oder HuggingFace Dataset herunter. Sobald Sie über die Metadateien verfügen, können Sie die folgenden Skripte verwenden, um die Videobeispiele herunterzuladen:
python download_data.py --meta_csv {meta file} --download_start_id {the start of download id} --download_end_id {the end of download id} --raw_video_save_dir {the path of saving raw videos} --clip_video_save_dir {the path of saving cutted video}
Wir werden die Videobeispiele aus unserem Datensatz / Github / unserer Projektwebseite entfernen, solange Sie sie benötigen. Bitte kontaktieren Sie uns für die Anfrage.
Um die MiraData zu sammeln, wählen wir zunächst manuell YouTube-Kanäle in verschiedenen Szenarien aus und beziehen Videos von HD-VILA-100M, Videovo, Pixabay und Pexels ein. Anschließend werden alle Videos in den entsprechenden Kanälen mit PySceneDetect heruntergeladen und aufgeteilt. Anschließend haben wir mehrere Modelle verwendet, um die kurzen Clips zusammenzufügen und Videos mit geringer Qualität herauszufiltern. Anschließend haben wir Videoclips mit langer Dauer ausgewählt. Schließlich haben wir alle Videoclips mit GPT-4V beschriftet.

Jedes Video in MiraData wird von strukturierten Untertiteln begleitet. Diese Bildunterschriften bieten detaillierte Beschreibungen aus verschiedenen Perspektiven und erhöhen so die Fülle des Datensatzes.
Sechs Arten von Bildunterschriften
Wir haben die vorhandenen visuellen Open-Source-LLM-Methoden und GPT-4V getestet und festgestellt, dass die Untertitel von GPT-4V eine bessere Genauigkeit und Kohärenz beim semantischen Verständnis in Bezug auf die zeitliche Abfolge aufweisen.
Um die Kosten für Anmerkungen und die Genauigkeit der Untertitel in Einklang zu bringen, nehmen wir für jedes Video gleichmäßig 8 Bilder auf und ordnen sie in einem 2x4-Raster eines großen Bildes an. Anschließend verwenden wir das Untertitelmodell von Panda-70M, um jedes Video mit einer aus einem Satz bestehenden Untertitel zu versehen, der als Hinweis auf den Hauptinhalt dient, und geben ihn in unsere fein abgestimmte Eingabeaufforderung ein. Indem wir die fein abgestimmte Eingabeaufforderung und ein 2x4 großes Bild an GPT-4V übertragen, können wir Untertitel für mehrere Dimensionen in nur einer Gesprächsrunde effizient ausgeben. Der spezifische Eingabeaufforderungsinhalt ist in caption_gpt4v.py zu finden, und wir heißen jeden herzlich willkommen, zu den qualitativ hochwertigeren Text-Video-Daten beizutragen. ?
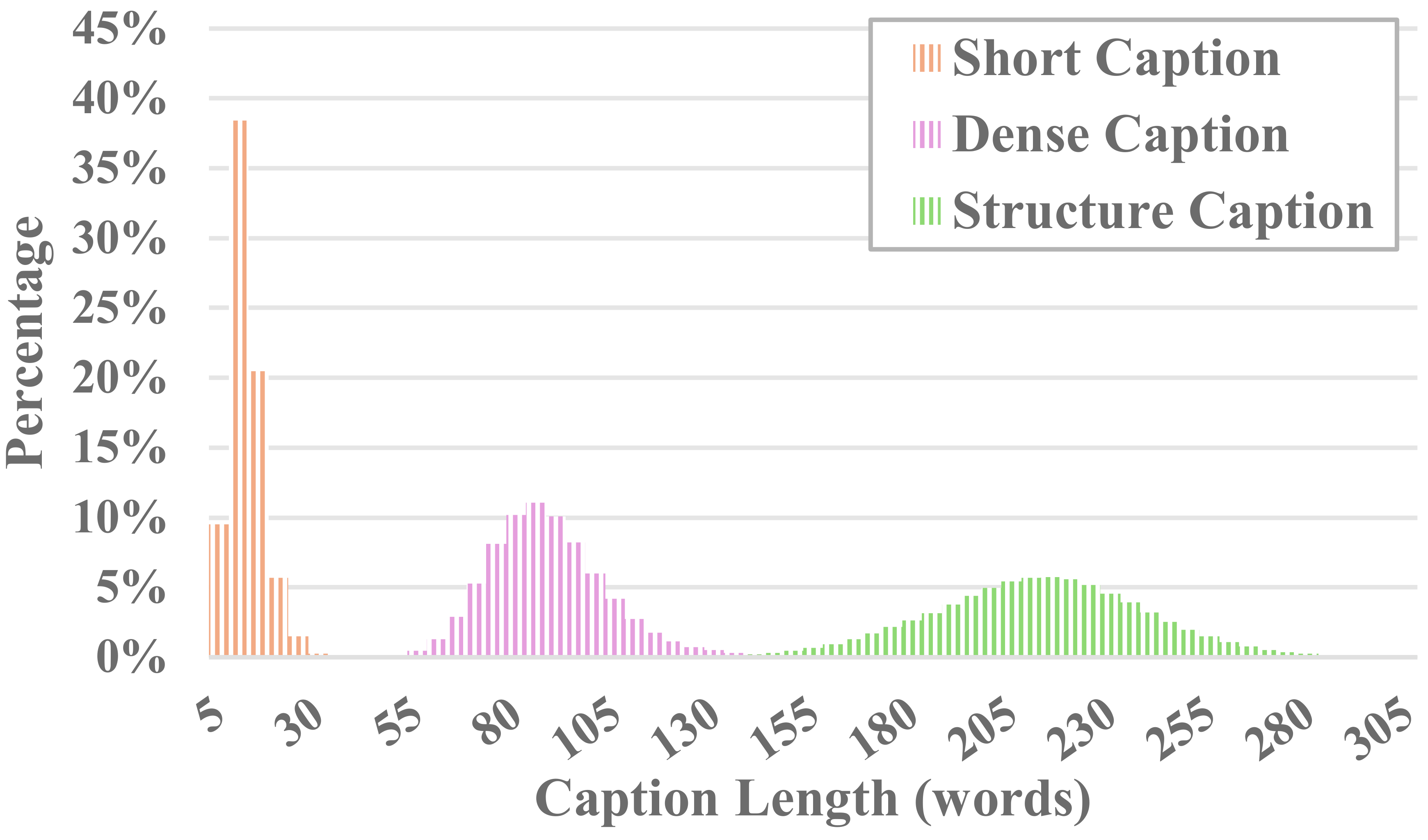

Um die Erzeugung langer Videos zu bewerten, entwerfen wir in MiraBench 17 Bewertungsmetriken aus sechs Perspektiven, darunter zeitliche Konsistenz, zeitliche Bewegungsstärke, 3D-Konsistenz, visuelle Qualität, Text-Video-Ausrichtung und Verteilungskonsistenz. Diese Metriken umfassen die meisten gängigen Bewertungsstandards, die in früheren Videogenerierungsmodellen und Text-zu-Video-Benchmarks verwendet wurden.
Um generierte Videos auszuwerten, richten Sie bitte zunächst eine Python-Umgebung ein über:
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu116
pip install -r requirements.txt
Führen Sie dann die Auswertung durch:
python calculate_score.py --meta_file data/evaluation_example/meta_generated.csv --frame_dir data/evaluation_example/frames_generated --gt_meta_file data/evaluation_example/meta_gt.csv --gt_frame_dir data/evaluation_example/frames_gt --output_folder data/evaluation_example/results --ckpt_path data/ckpt --device cuda
Sie können dem Beispiel in data/evaluation_example folgen, um Ihre selbst generierten Videos auszuwerten.
Siehe LIZENZ.
Wenn Sie dieses Projekt für Ihre Forschung nützlich finden, zitieren Sie bitte unseren Artikel. ?
@misc{ju2024miradatalargescalevideodataset,
title={MiraData: A Large-Scale Video Dataset with Long Durations and Structured Captions},
author={Xuan Ju and Yiming Gao and Zhaoyang Zhang and Ziyang Yuan and Xintao Wang and Ailing Zeng and Yu Xiong and Qiang Xu and Ying Shan},
year={2024},
eprint={2407.06358},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2407.06358},
}
Bei Fragen senden Sie bitte eine E-Mail [email protected] .
MiraData steht unter der GPL-v3-Lizenz und wird für die kommerzielle Nutzung unterstützt. Wenn Sie eine kommerzielle Lizenz für MiraData benötigen, können Sie uns gerne kontaktieren.


