bulk
1.0.0
Bulk ist ein schnelles Entwicklertool zum Anbringen einiger Massenetiketten. Bei einem vorbereiteten Datensatz mit 2D-Einbettungen kann eine Schnittstelle generiert werden, mit der Sie schnell umfangreiche, wenn auch weniger präzise Anmerkungen hinzufügen können.
python -m pip install --upgrade pip
python -m pip install bulk
Die Zukunft von Bulk besteht darin, Widgets anzubieten, die Ihnen im Notizbuch helfen können. Derzeit ist der BaseTextExplorer das wichtigste unterstützte Widget. Mit einigen vorverarbeiteten Daten können Sie mit dem Explorer eine 2D-UMAP mit Texteinbettungen durchstöbern.
import pandas as pd
from umap import UMAP
from sklearn . pipeline import make_pipeline
# pip install "embetter[text]"
from embetter . text import SentenceEncoder
# Build a sentence encoder pipeline with UMAP at the end.
enc = SentenceEncoder ( 'all-MiniLM-L6-v2' )
umap = UMAP ()
text_emb_pipeline = make_pipeline (
enc , umap
)
# Load sentences
sentences = list ( pd . read_csv ( "tests/data/text.csv" )[ 'text' ])
# Calculate embeddings
X_tfm = text_emb_pipeline . fit_transform ( sentences )
# Write to disk. Note! Text column must be named "text"
df = pd . DataFrame ({ "text" : sentences })
df [ 'x' ] = X_tfm [:, 0 ]
df [ 'y' ] = X_tfm [:, 1 ]Um das Widget zu verwenden, müssen Sie nur Folgendes ausführen:
from bulk . widgets import BaseTextExplorer
widget = BaseTextExplorer ( df )
widget . show ()Dadurch können wir die Cluster, die in unseren Daten erscheinen, schnell untersuchen. Sie können den Mauszeiger gedrückt halten, um in den Auswahlmodus zu wechseln. Wenn Sie Elemente auswählen, wird rechts eine zufällige Teilmenge angezeigt. Sie können Ihre Auswahl neu berechnen, indem Sie auf die Schaltfläche „Neu berechnen“ klicken.
Wenn Sie eine Auswahl treffen, können Sie das Widget in der rechten Aktualisierung sehen, aber Sie können die Daten auch aus einem Python-Attribut abrufen.
widget . selected_idx
widget . selected_texts
widget . selected_dataframeDie Möglichkeit, diese Cluster zu erkunden, ist nett, aber es fühlt sich so an, als ob wir alles leichter erkunden könnten, wenn uns mehr Werkzeuge zur Verfügung stünden. Insbesondere möchten wir einen Encoder haben, damit wir Abfragen in unserem eingebetteten Bereich verwenden können. Mit der folgenden Benutzeroberfläche können wir viel interaktiver erkunden, indem wir die Farben mit einer Textaufforderung aktualisieren.
from embetter . text import SentenceEncoder
enc = SentenceEncoder ( 'all-MiniLM-L6-v2' )
# Pay attention here! The rows in df needs to align with the rows in X!
widget = BaseTextExplorer ( df , X = X , encoder = enc )
widget . show ()Dank Tools wie ipywidget und anywidget können wir wirklich mit der Entwicklung einiger Tools beginnen, damit das Notebook die Anlaufstelle für Ihre Datenanforderungen bleibt. Mit einigen geeigneten Widgets werden Sie nie in der Lage sein, ein Jupyter-Notebook zu übertreffen!
Das Hauptinteresse dieses Projekts liegt in der Arbeit an Werkzeugen zur Datenqualität. Die Möglichkeit, Datenpunkte in großen Mengen auszuwählen, scheint ein guter Anfang zu sein. Vielleicht können Sie zuerst eine interessante Teilmenge finden, die Sie mit Anmerkungen versehen können. Vielleicht sind Sie überrascht, wenn Sie zwei unterschiedliche Cluster sehen, die eins sein sollten. All diese guten Dinge können im Notizbuch passieren!
Bulk wird außerdem mit einer kleinen Web-App geliefert, die Bokeh verwendet, um Ihnen Anmerkungsschnittstellen basierend auf UMAP-Darstellungen von Einbettungen bereitzustellen. Es bietet eine Schnittstelle für Text. Diese Schnittstelle war die ursprüngliche Schnittstelle/Funktion dieses Projekts.
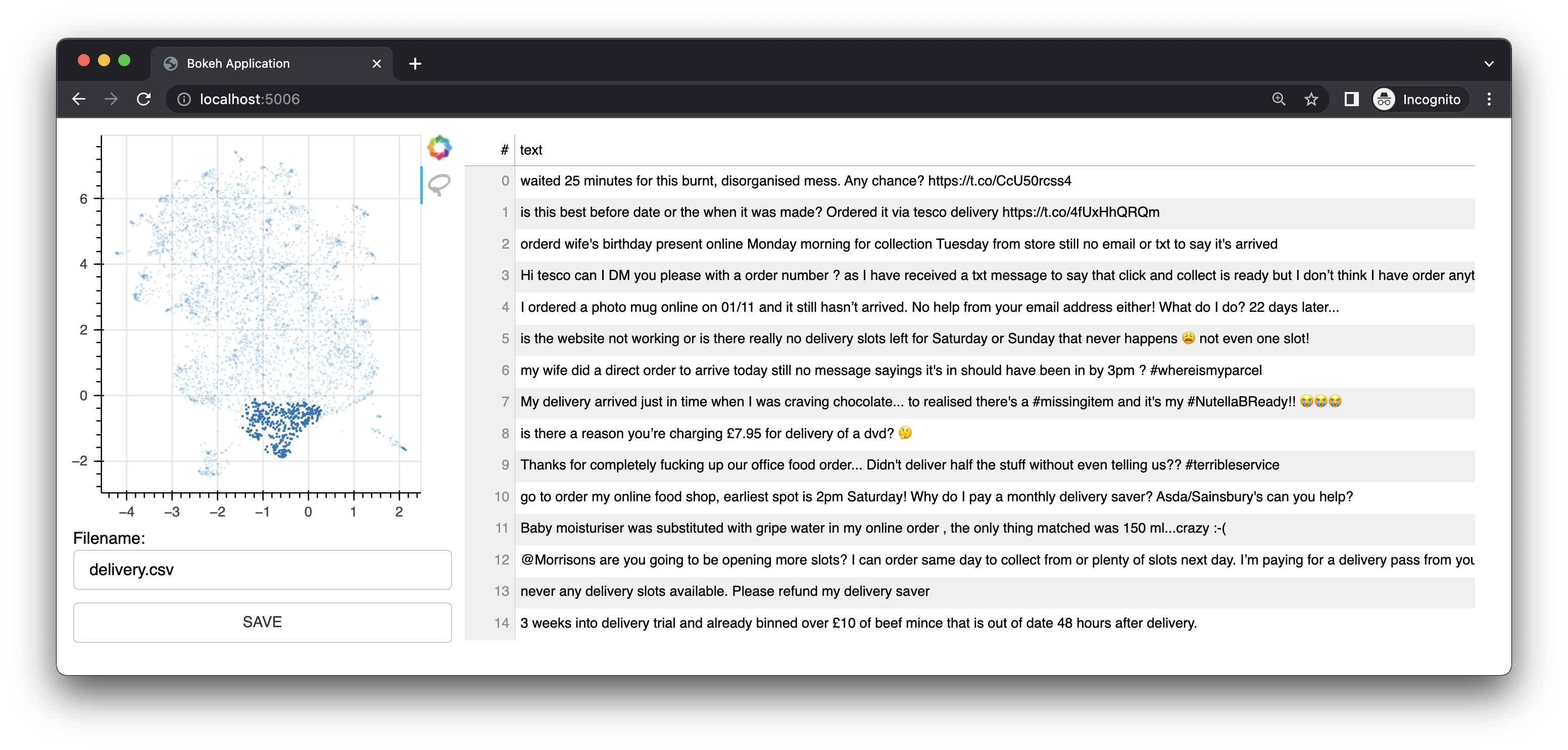
Es verfügt auch über eine Bildschnittstelle.
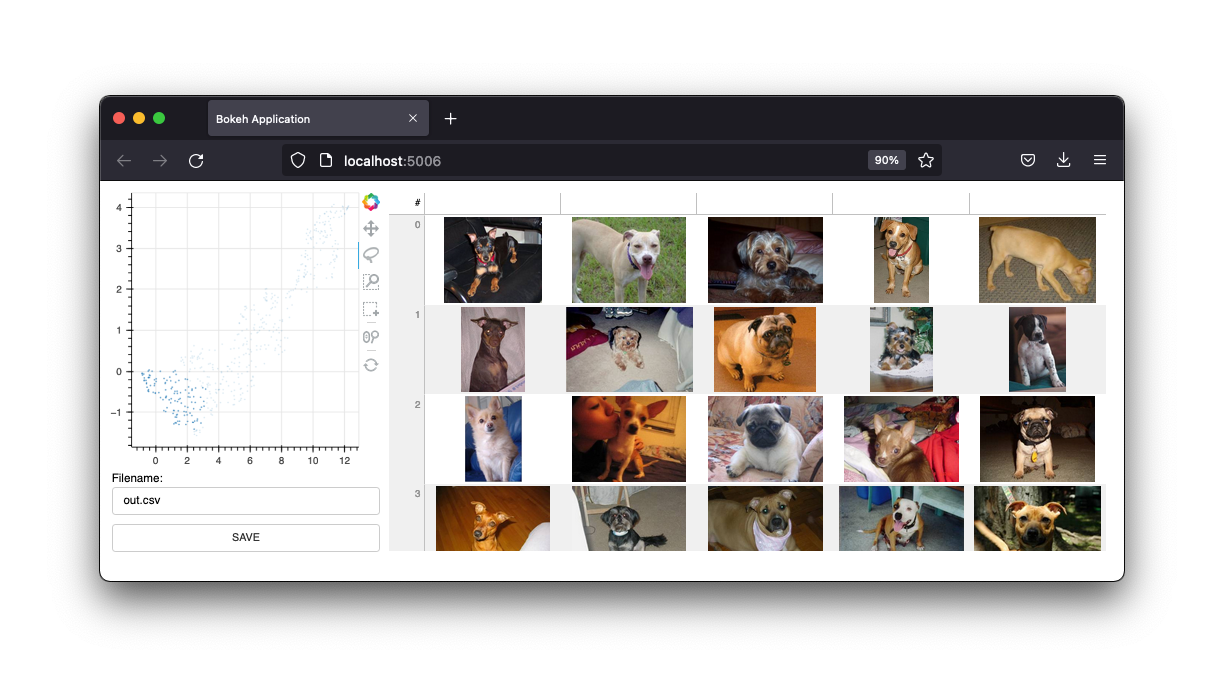
Wir werden diese Schnittstellen beibehalten, aber die Zukunft dieses Projekts werden Widgets aus einem Jupyter-Notebook sein. So wie sie ist, ist die Webapp jedoch sicherlich immer noch nützlich.
Wenn Sie neugierig sind und mehr erfahren möchten, könnten Ihnen dieses Video auf YouTube für Text und dieses Video auf YouTube für Computer Vision gefallen.
Um Massentexte zu verwenden, müssen Sie zunächst eine CSV-Datei vorbereiten.
Notiz
Das folgende Beispiel verwendet Embetter zum Generieren der Einbettungen und Umap zum Reduzieren der Abmessungen. Es steht Ihnen jedoch völlig frei, jedes Texteinbettungstool zu verwenden, das Ihnen gefällt. Sie müssen diese Tools separat installieren. Beachten Sie, dass Embetter unter der Haube Satztransformatoren verwendet.
import pandas as pd
from umap import UMAP
from sklearn . pipeline import make_pipeline
# pip install "embetter[text]"
from embetter . text import SentenceEncoder
# Build a sentence encoder pipeline with UMAP at the end.
text_emb_pipeline = make_pipeline (
SentenceEncoder ( 'all-MiniLM-L6-v2' ),
UMAP ()
)
# Load sentences
sentences = list ( pd . read_csv ( "original.csv" )[ 'sentences' ])
# Calculate embeddings
X_tfm = text_emb_pipeline . fit_transform ( sentences )
# Write to disk. Note! Text column must be named "text"
df = pd . DataFrame ({ "text" : sentences })
df [ 'x' ] = X_tfm [:, 0 ]
df [ 'y' ] = X_tfm [:, 1 ]
df . to_csv ( "ready.csv" , index = False ) Sie können nun diese Datei ready.csv verwenden, um eine Massenbeschriftung anzuwenden.
python -m bulk text ready.csv
Wenn Sie nach einer Beispieldatei zum Ausprobieren suchen, können Sie die Demo-CSV-Datei in diesem Repository herunterladen. Dieser Datensatz enthält eine Teilmenge eines auf Kaggle gefundenen Datensatzes. Das Original finden Sie hier.
Sie können Ihrer CSV-Datei auch eine zusätzliche Spalte namens „Farbe“ übergeben. Diese Spalte wird dann zum Färben der Punkte in der Schnittstelle verwendet.
Sie können auch --keywords an die Befehlszeilen-App übergeben, um Elemente hervorzuheben, die bestimmte Schlüsselwörter enthalten.
python -m bulk text ready.csv --keywords "deliver,card,website,compliment"
Das folgende Beispiel verwendet die embetter -Bibliothek, um einen Datensatz für die Massenbeschriftung von Bildern zu erstellen.
Notiz
Das folgende Beispiel verwendet Embetter zum Generieren der Einbettungen und Umap zum Reduzieren der Abmessungen. Es steht Ihnen jedoch völlig frei, jedes Texteinbettungstool zu verwenden, das Ihnen gefällt. Sie müssen diese Tools separat installieren. Beachten Sie, dass Embetter TIMM unter der Haube verwendet.
import pathlib
import pandas as pd
from sklearn . pipeline import make_pipeline
from umap import UMAP
from sklearn . preprocessing import MinMaxScaler
# pip install "embetter[vision]"
from embetter . grab import ColumnGrabber
from embetter . vision import ImageLoader , TimmEncoder
# Build image encoding pipeline
image_emb_pipeline = make_pipeline (
ColumnGrabber ( "path" ),
ImageLoader ( convert = "RGB" ),
TimmEncoder ( 'xception' ),
UMAP (),
MinMaxScaler ()
)
# Make dataframe with image paths
img_paths = list ( pathlib . Path ( "downloads" , "pets" ). glob ( "*" ))
dataf = pd . DataFrame ({
"path" : [ str ( p ) for p in img_paths ]
})
# Make csv file with Umap'ed model layer
# Note! Bulk assumes the image path column to be called "path"!
X = image_emb_pipeline . fit_transform ( dataf )
dataf [ 'x' ] = X [:, 0 ]
dataf [ 'y' ] = X [:, 1 ]
dataf . to_csv ( "ready.csv" , index = False )Dadurch wird eine CSV-Datei generiert, die in großen Mengen geladen werden kann über;
python -m bulk image ready.csv
Sie können auch eine Reihe von Miniaturansichten für Ihre Bilder erstellen. Dies kann nützlich sein, wenn Sie mit einem großen Datensatz arbeiten.
python -m bulk util resize ready.csv ready2.csv temp
Dadurch wird ein Ordner namens temp mit allen in der Größe geänderten Bildern erstellt. Sie können diesen Ordner dann als Argument --thumbnail-path verwenden.
python -m bulk image ready2.csv --thumbnail-path temp
Sie können die Bulk-Funktion auch verwenden, um einige Datensätze zum Spielen herunterzuladen. Für weitere Informationen:
python -m bulk download --help
Mithilfe der Benutzeroberfläche können Sie möglicherweise sehr schnell Beschriftungen erstellen, die Beschriftungen selbst können jedoch recht laut sein. Der beabsichtigte Anwendungsfall für dieses Tool besteht darin, interessante Teilmengen vorzubereiten, die später in prodi.gy verwendet werden sollen.


