AI Guide and Demos zh_CN
1.0.0
Wenn ich auf den vergangenen Lernprozess zurückblicke, haben mir die Videos der Lehrer Ng Enda und Li Hongyi auf meinem Weg des vertieften Lernens große Hilfe geleistet. Ihre humorvollen Erklärungsmethoden und einfachen und intuitiven Erklärungen machen langweiliges theoretisches Lernen lebendig und interessant.
In der Praxis werden sich viele Studenten jedoch zunächst Gedanken darüber machen, wie sie die API großer ausländischer Modelle erhalten können, doch die Angst vor Schwierigkeiten wird den Lernfortschritt immer verzögern und sich allmählich ändern von „nur das Video ansehen“. Ich sehe oft ähnliche Diskussionen im Kommentarbereich, deshalb habe ich beschlossen, meine Freizeit zu nutzen, um Schülern dabei zu helfen, diese Schwelle zu überwinden. Dies ist auch die ursprüngliche Absicht des Projekts.
Dieses Projekt wird keine Tutorials zum wissenschaftlichen Internetzugang bereitstellen und sich auch nicht auf plattformspezifische Schnittstellen verlassen. Stattdessen wird das kompatiblere OpenAI SDK verwendet, um jedem zu helfen, mehr Allgemeinwissen zu erlernen.
Das Projekt beginnt mit einfachen API-Aufrufen und führt Sie schrittweise in die Welt der großen Modelle ein. Dabei erlernen Sie Fähigkeiten wie KI-Videozusammenfassung , LLM-Feinabstimmung und KI-Bildgenerierung .
Es wird dringend empfohlen, sich den Kurs „Einführung in die generative künstliche Intelligenz“ von Lehrer Li Hongyi anzusehen, um gleichzeitig zu lernen: schneller Zugriff auf kursbezogene Links
Jetzt bietet das Projekt auch CodePlayground. Sie können die Umgebung gemäß der Dokumentation konfigurieren, das Skript mit einer Codezeile ausführen und den Charme der KI erleben.
„Aufsätze zu Abschlussarbeiten befinden sich in PaperNotes, und grundlegende Arbeiten zu großen Modellen werden nach und nach hochgeladen.“
Das Basis-Image ist fertig. Wenn Sie noch keine eigene Deep-Learning-Umgebung konfiguriert haben, können Sie es auch mit Docker versuchen.
Gute Reise!
--- : Grundkenntnisse, bei Bedarf ansehen oder vorübergehend überspringen. Die Ergebnisse der Codedatei werden im Artikel angezeigt, es wird jedoch dennoch empfohlen, den Code manuell auszuführen. Es können Anforderungen an den Videospeicher bestehen.API : Der Artikel verwendet nur die API großer Modelle, unterliegt keinen Gerätebeschränkungen und kann ohne GPU ausgeführt werden.LLM : Praxis im Zusammenhang mit großen Sprachmodellen, Codedateien können Videospeicheranforderungen haben.SD : Stable Diffusion, eine Praxis im Zusammenhang mit Vincentschen Diagrammen, und Codedateien stellen Anforderungen an den Videospeicher.File herunterladen, und der Lerneffekt ist derselbe.Setting -> Accelerator ->选择GPU .代码执行程序->更改运行时类型->选择GPU .| Führung | Etikett | Beschreiben | Datei | Online |
|---|---|---|---|---|
| 00. Schritte zum Abrufen der Alibaba Big Model API | API | Wir führen Sie Schritt für Schritt zum Erhalt der API. Wenn Sie sich zum ersten Mal registrieren, müssen Sie eine Identitätsprüfung (Gesichtserkennung) durchführen. | ||
| 01. Erste Einführung in die LLM-API: Umgebungskonfiguration und mehrstufige Dialogdemonstration | API | Dies ist eine einführende Konfiguration und Demonstration. Der Konversationscode wurde aus Alibaba-Entwicklungsdokumenten geändert. | Code | Kaggle Colab |
| 02. Einfacher Einstieg: Erstellen Sie KI-Anwendungen über API und Gradio | API | Anleitung zur Verwendung von Gradio zum Erstellen einer einfachen KI-Anwendung. | Code | Colab |
| 03. Erweiterte Anleitung: Passen Sie die Eingabeaufforderung an, um die Problemlösungsfunktionen für große Modelle zu verbessern | API | Sie erfahren, wie Sie eine Eingabeaufforderung anpassen, um die Fähigkeit großer Modelle zur Lösung mathematischer Probleme zu verbessern. Außerdem werden Gradio- und Nicht-Gradio-Versionen bereitgestellt und Codedetails angezeigt. | Code | Kaggle Colab |
| 04. LoRA verstehen: von der linearen Ebene zum Aufmerksamkeitsmechanismus | --- | Bevor Sie offiziell mit der Praxis beginnen, müssen Sie die Grundkonzepte von LoRA kennen. Dieser Artikel führt Sie von der LoRA-Implementierung auf linearer Ebene zum Aufmerksamkeitsmechanismus. | ||
05. Verstehen Sie AutoModel Reihe von Hugging Face: automatische Modellladeklassen für verschiedene Aufgaben | --- | Das Modul, das wir verwenden werden, ist AutoModel in Hugging Face. Auch dieser Artikel erfordert Kenntnisse (Sie können ihn natürlich überspringen und später lesen, wenn Sie Zweifel haben). | Code | Kaggle Colab |
| 06. Beginnen Sie: Stellen Sie Ihr erstes Sprachmodell bereit | LLM | Durch die Implementierung eines sehr einfachen Sprachmodells stellt das Projekt bisher keine harten Anforderungen an die GPU, sodass Sie weiter lernen können. | Code app_fastapi.py app_flask.py | |
| 07. Erkunden Sie die Beziehung zwischen Modellparametern und Videospeicher sowie die Auswirkungen unterschiedlicher Genauigkeit | --- | Wenn Sie den Zusammenhang zwischen Modellparametern und Videospeicher verstehen und die Importmethoden unterschiedlicher Genauigkeit beherrschen, wird Ihre Modellauswahl geschickter. | ||
| 08. Versuchen Sie, LLM zu verfeinern: Lassen Sie es Tang-Poesie schreiben | LLM | Dieser Artikel ist derselbe wie 03. Erweiterter Leitfaden: Anpassen der Eingabeaufforderung zur Verbesserung der Problemlösungsfähigkeiten großer Modelle. Er konzentriert sich im Wesentlichen auf die „Verwendung“ und nicht auf das „Schreiben“. Sehen Sie sich den Abschnitt „Hyperparameter“ an, um die Auswirkungen auf die Feinabstimmung zu sehen. | Code | Kaggle Colab |
| 09. Vertiefendes Verständnis von Beam Search: Prinzipien, Beispiele und Code-Implementierung | --- | Der Übergang von Beispielen zu Codedemonstrationen und die Erläuterung der Mathematik von Beam Search sollten einige Verwirrungen aus der vorherigen Lektüre beseitigen und schließlich ein einfaches Beispiel für die Verwendung der Hugging Face Transformers-Bibliothek liefern (Sie können es ausprobieren, wenn Sie den vorherigen Artikel übersprungen haben). . | Code | Kaggle Colab |
| 10. Top-K vs. Top-P: Sampling-Strategie und der Einfluss der Temperatur in generativen Modellen | --- | Darüber hinaus zeigen wir Ihnen weitere Generationsstrategien. | Code | Kaggle Colab |
| 11. DPO-Feinabstimmungsbeispiel: Optimierung des großen LLM-Sprachmodells entsprechend den menschlichen Vorlieben | LLM | Ein Beispiel für die Feinabstimmung mithilfe von DPO. | Code | Kaggle Colab |
| 12. Inseq-Feature-Attribution: Interpretieren Sie die Ausgabe von LLM visuell | LLM | Visuelle Beispiele für Übersetzungs- und Texterstellungsaufgaben (Lückenausfüllen). | Code | Kaggle Colab |
| 13. Verstehen Sie mögliche Vorurteile in der KI | LLM | Es ist nicht erforderlich, den Code zu verstehen, er kann als unterhaltsame Erkundungstour in der Freizeit verwendet werden. | Code | Kaggle Colab |
| 14. PEFT: Wenden Sie LoRA schnell auf große Modelle an | --- | Erfahren Sie, wie Sie nach dem Import des Modells LoRA-Ebenen hinzufügen. | Code | Kaggle Colab |
| 15. Verwenden Sie die API, um eine KI-Videozusammenfassung zu implementieren: Erstellen Sie Ihren eigenen KI-Videoassistenten | API und LLM | Sie lernen die Prinzipien gängiger KI-Videozusammenfassungsassistenten kennen und beginnen mit der Implementierung der KI-Videozusammenfassung. | Code - Vollversion Code – Lite-Version ?Skript | Kaggle Colab |
| 16. Verwenden Sie LoRA zur Feinabstimmung der stabilen Diffusion: Zerlegen Sie den Alchemieofen und implementieren Sie Ihr erstes KI-Gemälde | SD | Verwenden Sie LoRA, um das Vincent-Diagrammmodell zu verfeinern, und jetzt können Sie Ihre LoRA-Dateien auch anderen zur Verfügung stellen. | Code Code – Lite-Version | Kaggle Colab |
| 17. Eine kurze Diskussion zur RTN-Modellquantisierung: asymmetrisch vs. symmetrisch.md | --- | Um das quantitative Verhalten des RTN-Modells besser zu verstehen, wird in diesem Artikel INT8 als Beispiel zur Erläuterung verwendet. | Code | Kaggle Colab |
| 18. Überblick über die Modellquantifizierungstechnologie und Analyse des GGUF/GGML-Dateiformats | --- | Dies ist ein Übersichtsartikel, der einige Ihrer Zweifel bei der Verwendung von GGUF/GGML ausräumen kann. | ||
| 19a. Vom Laden zur Konversation: Lokales Ausführen quantisierter LLM-Großmodelle (GPTQ & AWQ) mit Transformers 19b. Vom Laden zur Konversation: Lokales Ausführen quantisierter LLM-Großmodelle (GGUF) mit Llama-cpp-python | LLM | Sie werden ein quantitatives Modell mit 7 Milliarden (7B) Parametern auf Ihrem Computer bereitstellen. Beachten Sie, dass für diesen Artikel keine Grafikkarte erforderlich ist. 19 a Verwendung von Transformern, einschließlich Modellladen in den Formaten GPTQ und AWQ. 19 b Verwendung von Llama-cpp-python, einschließlich Modellladen im GGUF-Format. Darüber hinaus vervollständigen Sie auch die Interaktionsfunktion für den lokalen Dialog mit großen Modellen. | Code-Transformatoren Code-Llama-cpp-python ?Skript | |
| 20. RAG-Einführungspraxis: von der Dokumentenaufteilung über die Vektordatenbank bis hin zur Frage- und Antwortkonstruktion | LLM | RAG-bezogene Praktiken. Erfahren Sie, wie rekursives Text-Chunking funktioniert. | Code | |
| 21. BPE vs. WordPiece: Verstehen Sie das Funktionsprinzip des Tokenizers und der Unterwortsegmentierungsmethode | --- | Grundfunktionen von Tokenizer. Erfahren Sie mehr über gängige Methoden zur Unterwortsegmentierung: BPE und WordPiece. Aufmerksamkeitsmaske (Attention Mask) und Token-Typ-IDs (Token-Typ-IDs) verstehen. | Code | Kaggle Colab |
| 22. Aufgabe – Bert optimiert die Beantwortung extraktiver Fragen | Dies ist eine Aufgabe, die BERT zur Feinabstimmung nachgelagerter Frage- und Antwortaufgaben verwendet. Sie können es ausprobieren und versuchen, an Kaggles „Wettbewerb“ teilzunehmen. Nach einer Woche erhalten Sie einen Leitfaden oder lassen Sie es für später. Im Einführungsartikel wird die Aufgabenbeschreibung nicht behandelt. Zum Lernen werden zwei Versionen des Codes hochgeladen. Machen Sie sich also keine Sorgen. Hier wird es keine Frist geben. | Code - Zuweisung | Kaggle Colab |
Tipp
Wenn Sie lieber das Warehouse abrufen möchten, um .md lokal zu lesen, verwenden Sie bei Auftreten eines Formelfehlers bitte Ctrl+F oder Command+F , suchen Sie nach \_ und ersetzen Sie alles durch _ .
Weiterführende Literatur:
| Führung | Beschreiben |
|---|---|
| a. Verwenden Sie HFD, um den Download von Hugging Face-Modellen und -Datensätzen zu beschleunigen | Wenn Sie der Meinung sind, dass das Herunterladen des Modells zu langsam ist, können Sie zur Konfiguration auf diesen Artikel zurückgreifen. Wenn Proxy-bezogene 443-Fehler auftreten, können Sie auch versuchen, diesen Artikel zu lesen. |
| b. Schnelle Überprüfung grundlegender Befehlszeilenbefehle (gilt für Linux/Mac) | Eine Schnellüberprüfung der Befehlszeilenbefehle enthält grundsätzlich alle im aktuellen Warehouse beteiligten Befehle. Überprüfen Sie sie, wenn Sie verwirrt sind. |
| c. Lösungen für einige Probleme | Hier werden wir einige Probleme lösen, die während des Projektbetriebs auftreten können. - Wie kann ich das Remote-Warehouse abrufen, um alle lokalen Änderungen zu überschreiben? - Wie kann ich von Hugging Face heruntergeladene Dateien anzeigen und löschen und wie ändere ich den Speicherpfad? |
| d. So laden Sie das GGUF-Modell (Lösung für Shared/Shared/Split/00001-of-0000...) | - Erfahren Sie mehr über die neuen Funktionen von Transformers über GGUF. - Verwenden Sie Transformers/Llama-cpp-python/Ollama, um Modelldateien im GGUF-Format zu laden. - Erfahren Sie, wie Sie fragmentierte GGUF-Dateien zusammenführen. – Lösen Sie das Problem, dass LLama-cpp-python nicht ausgelagert werden kann. |
| e. Datenverbesserung: Analyse gängiger Methoden von Torchvision.transforms | - Verstehen Sie häufig verwendete Methoden zur Bilddatenverbesserung. Code |. Kaggle | |
| f. Kreuzentropieverlustfunktion nn.CrossEntropyLoss() Detaillierte Erklärung und Erinnerung an wichtige Punkte (PyTorch) | - Verstehen Sie die mathematischen Prinzipien des Kreuzentropieverlusts und der PyTorch-Implementierung. - Erfahren Sie, worauf Sie bei der ersten Verwendung achten müssen. |
| g. Einbettungsebene nn.Embedding() ausführliche Erklärung und wichtige Punkte (PyTorch) | - Verstehen Sie die Konzepte der Einbettung von Ebenen und Worteinbettungen. - Visualisieren Sie die Einbettung mithilfe vorab trainierter Modelle. Code |. Kaggle | |
| h. Verwenden Sie Docker, um die Deep-Learning-Umgebung schnell zu konfigurieren (Linux). h. Einführung in die grundlegenden Docker-Befehle und allgemeine Fehlerbeseitigung | - Verwenden Sie zwei Befehlszeilen, um die Deep-Learning-Umgebung zu konfigurieren - Einführung in die grundlegenden Docker-Befehle - Beheben Sie drei häufige Fehler während der Verwendung |
Erklärung zum Ordner:
Demos
Alle Codedateien werden dort gespeichert.
Daten
Speichern Sie kleine Daten, die im Code verwendet werden können. Es besteht keine Notwendigkeit, auf diesen Ordner zu achten.
GenAI_PDF
Hier sind die PDF-Dateien der Aufgaben für den Kurs [Einführung in die generative künstliche Intelligenz]. Ich habe sie hochgeladen, weil sie ursprünglich in Google Drive gespeichert wurden.
Führung
Dort werden alle Leitfäden untergebracht.
Vermögenswerte
Hier sind die Bilder, die in der .md-Datei verwendet werden. Es besteht keine Notwendigkeit, auf diesen Ordner zu achten.
PaperNotes
Thesenaufsatz.
CodePlayground
Einige interessante Code-Skript-Beispiele (Toy-Version).
README.md
summaryr.py ?script
AI-Video-/Audio-/Untertitelzusammenfassung.
chat.py ?script
KI-Gespräch.
Einführung in Lernressourcen für generative künstliche Intelligenz
Homepage des Kurses
Offizielles |. Autorisiertes Video: YouTube |
Die Erstellung und Weitergabe der chinesischen Spiegelversion wurde von Lehrer Li Hongyi genehmigt. Vielen Dank an den Lehrer für Ihre selbstlose Wissensweitergabe!
PS Chinesisches Bild wird alle Funktionen des Jobcodes vollständig realisieren (lokaler Betrieb). Der Inhalt von Chinesisch Colab und Kaggle entspricht dem Originaljob. Wählen Sie einfach eine davon aus, um die Studie abzuschließen.
Wählen Sie je nach tatsächlichem Bedarf unten eine Methode zur Vorbereitung der Lernumgebung aus und klicken Sie zum Erweitern auf ► oder Text .
Kaggle (inländische Direktverbindung, empfohlen): Lesen Sie den Artikel „Kaggle: Free GPU Usage Guide, an Ideal Alternative to Colab“, um mehr zu erfahren.
Colab (erfordert wissenschaftlichen Internetzugang)
Die Codedateien im Projekt werden auf beiden Plattformen synchronisiert.
Linux (Ubuntu) :
sudo apt-get update
sudo apt-get install gitmacOS :
Installieren Sie zuerst Homebrew:
/bin/bash -c " $( curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh ) "Führen Sie dann Folgendes aus:
brew install gitWindows :
Von Git für Windows herunterladen und installieren.
Linux (Ubuntu) :
sudo apt-get update
sudo apt-get install wget curlmacOS :
brew install wget curlWindows :
Laden Sie es von den offiziellen Websites von Wget für Windows und Curl herunter und installieren Sie es.
Besuchen Sie die offizielle Website von Anaconda, geben Sie Ihre E-Mail-Adresse ein und überprüfen Sie Ihre E-Mails. Sie sollten Folgendes sehen können:
Klicken Sie auf Download Now , wählen Sie die entsprechende Version aus und laden Sie sie herunter (sowohl Anaconda als auch Miniconda sind verfügbar):

Linux (Ubuntu) :
Installieren Sie Anaconda
Besuchen Sie repo.anaconda.com für die Versionsauswahl.
# 下载 Anaconda 安装脚本(以最新版本为例)
wget https://repo.anaconda.com/archive/Anaconda3-2024.10-1-Linux-x86_64.sh
# 运行安装脚本
bash Anaconda3-2024.10-1-Linux-x86_64.sh
# 按照提示完成安装(先回车,空格一直翻页,翻到最后输入 yes,回车)
# 安装完成后,刷新环境变量或者重新打开终端
source ~ /.bashrcMiniconda installieren (empfohlen)
Besuchen Sie repo.anaconda.com/miniconda für die Versionsauswahl. Miniconda ist eine optimierte Version von Anaconda, die nur Conda und Python enthält.
# 下载 Miniconda 安装脚本
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
# 运行安装脚本
bash Miniconda3-latest-Linux-x86_64.sh
# 按照提示完成安装(先回车,空格一直翻页,翻到最后输入 yes,回车)
# 安装完成后,刷新环境变量或者重新打开终端
source ~ /.bashrcmacOS :
Ersetzen Sie die URL im Linux-Befehl entsprechend.
Installieren Sie Anaconda
Besuchen Sie repo.anaconda.com für die Versionsauswahl.
Miniconda installieren (empfohlen)
Besuchen Sie repo.anaconda.com/miniconda für die Versionsauswahl.
Geben Sie im Terminal den folgenden Befehl ein. Wenn die Versionsinformationen angezeigt werden, ist die Installation erfolgreich.
conda --versioncat << ' EOF ' > ~/.condarc
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirror.nju.edu.cn/anaconda/pkgs/main
- https://mirror.nju.edu.cn/anaconda/pkgs/r
- https://mirror.nju.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirror.nju.edu.cn/anaconda/cloud
pytorch: https://mirror.nju.edu.cn/anaconda/cloud
EOF[!Notiz]
Viele Mirror-Quellen, die letztes Jahr verfügbar waren, sind nicht mehr verfügbar. Informationen zur aktuellen Konfiguration anderer Mirror-Sites finden Sie in diesem sehr schönen Dokument von NTU: Mirror Usage Help.
Hinweis : Wenn Anaconda oder Miniconda bereits installiert ist, wird pip in das System einbezogen und es ist keine zusätzliche Installation erforderlich.
Linux (Ubuntu) :
sudo apt-get update
sudo apt-get install python3-pipmacOS :
brew install python3Windows :
Laden Sie Python herunter und installieren Sie es. Stellen Sie dabei sicher, dass die Option „Python zu PATH hinzufügen“ aktiviert ist.
Öffnen Sie eine Eingabeaufforderung und geben Sie Folgendes ein:
python -m ensurepip --upgradeGeben Sie im Terminal den folgenden Befehl ein. Wenn die Versionsinformationen angezeigt werden, ist die Installation erfolgreich.
pip --versionpip config set global.index-url https://mirrors.aliyun.com/pypi/simpleZiehen Sie das Projekt mit dem folgenden Befehl:
git clone https://github.com/Hoper-J/AI-Guide-and-Demos-zh_CN.git
cd AI-Guide-and-Demos-zh_CNEs gibt keine Begrenzung der Version, sie kann höher sein:
conda create -n aigc python=3.9 Drücken Sie y und geben Sie die Eingabetaste ein, um fortzufahren. Nachdem die Erstellung abgeschlossen ist, aktivieren Sie die virtuelle Umgebung:
conda activate aigcAls Nächstes müssen Sie grundlegende Abhängigkeiten installieren. Nehmen Sie CUDA 11.8 als Beispiel (wenn die Grafikkarte 11.8 nicht unterstützt, müssen Sie den Befehl ändern) und wählen Sie eine der beiden zur Installation aus:
# pip
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# conda
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidiaJetzt haben wir alle erforderlichen Umgebungen erfolgreich konfiguriert und können mit dem Lernen beginnen :) Die verbleibenden Abhängigkeiten werden in jedem Artikel separat aufgeführt.
[!Notiz]
Docker-Images verfügen über vorinstallierte Abhängigkeiten, sodass eine Neuinstallation nicht erforderlich ist.
Installieren Sie zuerst jupyter-lab , das viel einfacher zu verwenden ist als jupyter notebook .
pip install jupyterlabFühren Sie nach Abschluss der Installation den folgenden Befehl aus:
jupyter-lab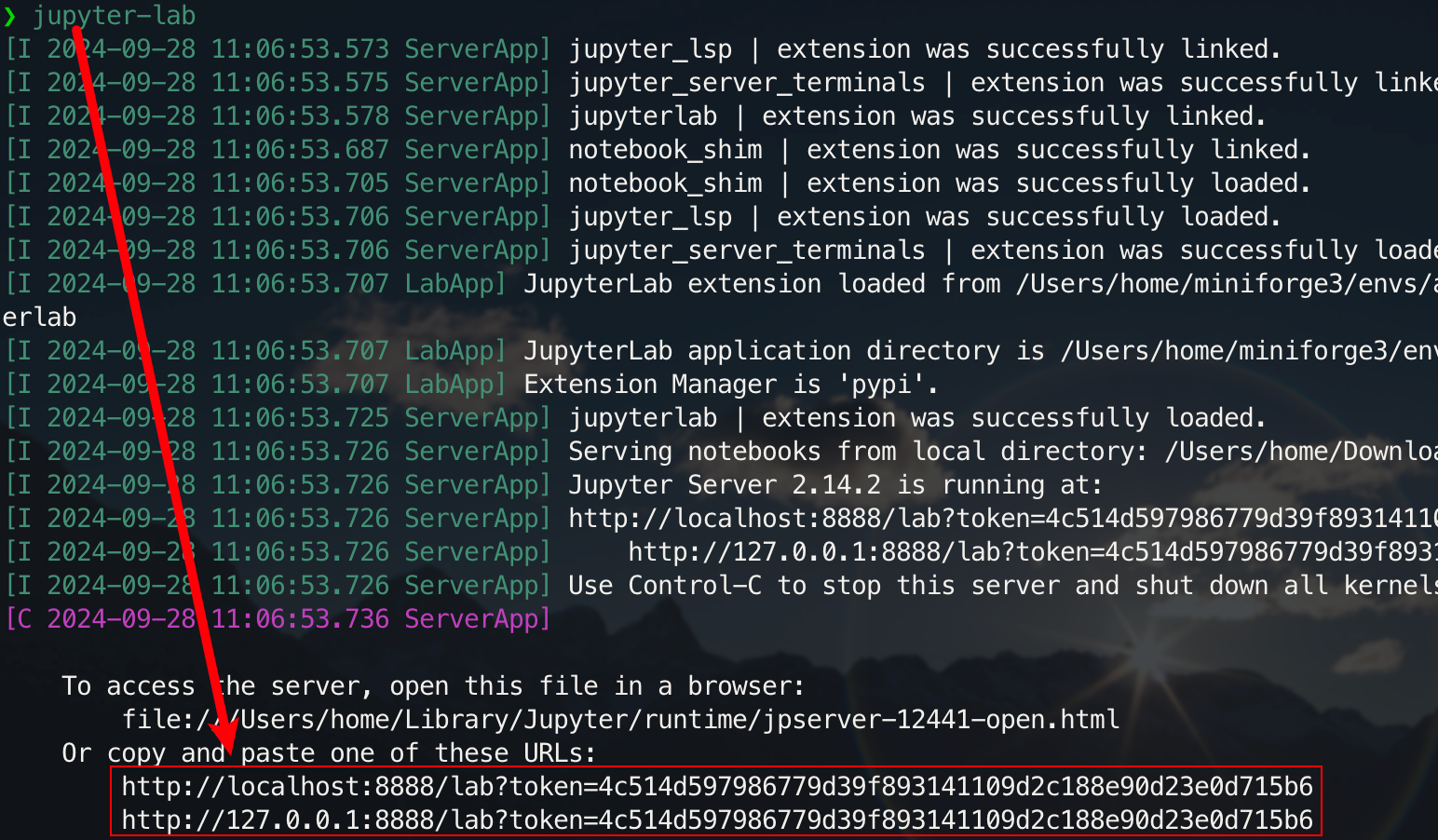
Jetzt können Sie über den Popup-Link darauf zugreifen, der sich normalerweise auf Port 8888 befindet. Für die grafische Benutzeroberfläche halten Sie unter Windows/Linux Ctrl und auf dem Mac Command gedrückt und klicken Sie dann auf den Link, um direkt zu springen. An dieser Stelle erhalten Sie ein vollständiges Bild des Projekts:
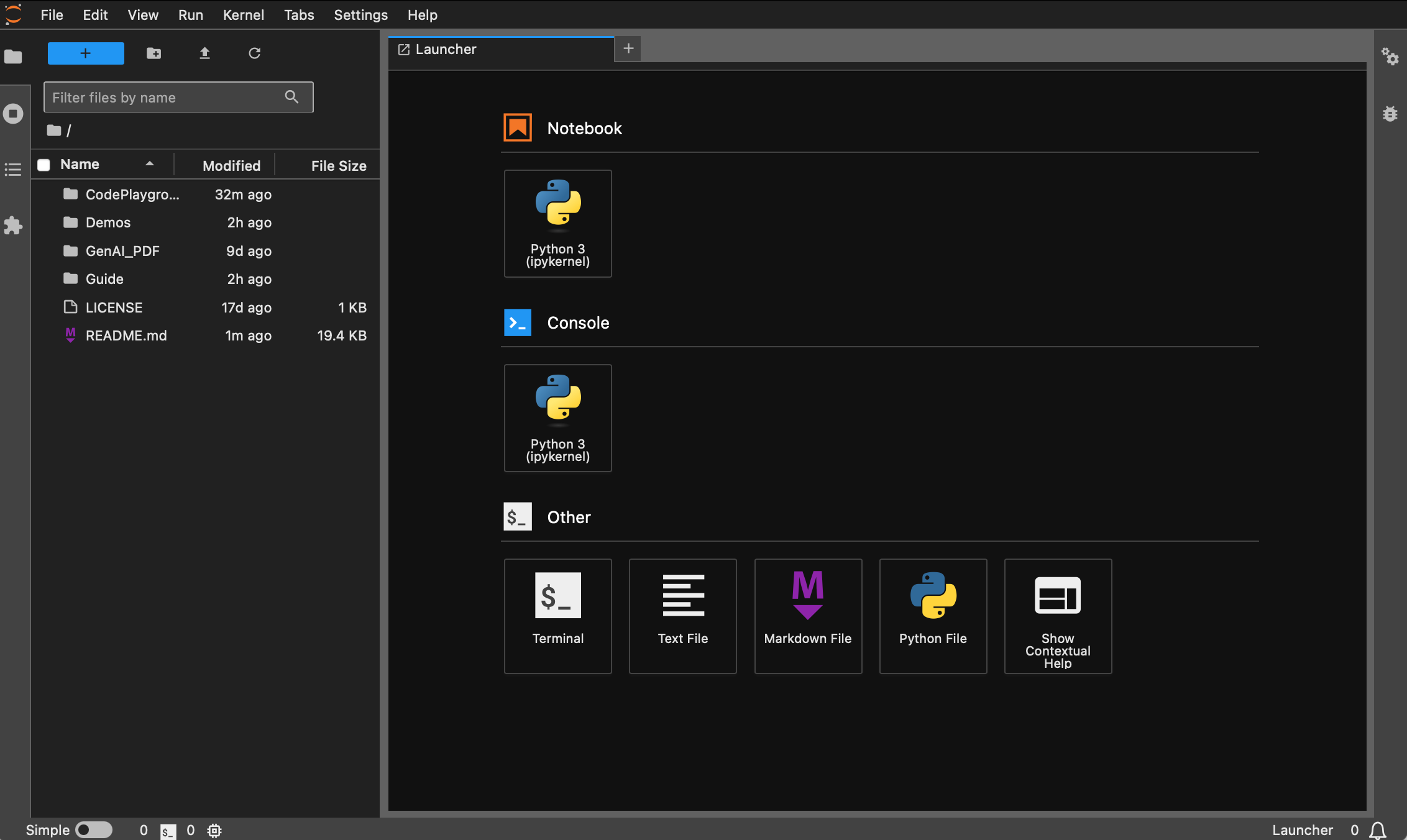
Schüler, die Docker nicht installiert haben, können den Artikel „Verwenden Sie Docker zur schnellen Konfiguration einer Deep-Learning-Umgebung (Linux)“ lesen. Anfängern wird empfohlen, „Einführung in grundlegende Docker-Befehle und allgemeine Fehlerbeseitigung“ zu lesen.
Alle Versionen sind mit gängigen Tools wie sudo , pip , conda , wget , curl und vim vorinstalliert und die inländischen Bildquellen von pip und conda wurden konfiguriert. Gleichzeitig integriert es zsh und einige praktische Befehlszeilen-Plug-Ins (automatische Befehlsvervollständigung, Syntaxhervorhebung und Verzeichnissprung-Tool z ). Darüber hinaus sind jupyter notebook und jupyter lab vorinstalliert und das Standardterminal ist auf zsh eingestellt, um die Deep-Learning-Entwicklung zu erleichtern. Die chinesische Anzeige im Container wurde optimiert, um verstümmelte Zeichen zu vermeiden. Die inländische Spiegeladresse von Hugging Face ist ebenfalls vorkonfiguriert.
pytorch/pytorch:2.5.1-cuda11.8-cudnn9-devel . Die Standardversion python ist 3.11.10. Die Version kann direkt über conda install python==版本号geändert werden.Passende Installation :
wget , curl : Befehlszeilen-Download-Toolsvim , nano : Texteditorgit : Versionskontrolltoolgit-lfs : Git LFS (Großdateispeicher)zip , unzip : Tools zur Dateikomprimierung und -dekomprimierunghtop : Systemüberwachungstooltmux , screen : Sitzungsverwaltungstoolsbuild-essential : Kompilierungstools (z. B. gcc , g++ )iputils-ping , iproute2 , net-tools : Netzwerk-Tools (Bereitstellung von Befehlen wie ping , ip , ifconfig , netstat usw.)ssh : Remote-Verbindungstoolrsync : Dateisynchronisierungstooltree : Datei- und Verzeichnisbäume anzeigenlsof : Zeigt die aktuell auf dem System geöffneten Dateien anaria2 : Multithread-Download-Toollibssl-dev : OpenSSL-EntwicklungsbibliothekPip-Installation :
jupyter notebook , jupyter lab : interaktive Entwicklungsumgebungvirtualenv : Python-Tool zur Verwaltung virtueller Umgebungen, Sie können Conda direkt verwendentensorboard : Visualisierungstool für Deep-Learning-Trainingipywidgets : Jupyter-Widget-Bibliothek zur korrekten Anzeige von FortschrittsbalkenPlugin :
zsh-autosuggestions : Automatische Befehlsvervollständigungzsh-syntax-highlighting : Syntaxhervorhebungz : Schnell zum Verzeichnis springenDie dl -Version (Deep Learning) basiert auf Base und installiert zusätzlich grundlegende Tools und Bibliotheken, die beim Deep Learning verwendet werden können:
Passende Installation :
ffmpeg : Audio- und Videoverarbeitungstoollibgl1-mesa-glx : Abhängigkeit von der Grafikbibliothek (löst einige grafikbezogene Probleme mit dem Deep-Learning-Framework)Pip-Installation :
numpy , scipy : numerische Berechnungen und wissenschaftliche Berechnungenpandas : Datenanalysematplotlib , seaborn : Datenvisualisierungscikit-learn : Werkzeuge für maschinelles Lernentensorflow , tensorflow-addons : ein weiteres beliebtes Deep-Learning-Frameworktf-keras : TensorFlow-Implementierung der Keras-Schnittstelletransformers , datasets : NLP-Tools von Hugging Facenltk , spacy : Werkzeuge zur Verarbeitung natürlicher SpracheWenn zusätzliche Bibliotheken benötigt werden, können diese manuell mit dem folgenden Befehl installiert werden:
pip install --timeout 120 <替换成库名> Hier setzt --timeout 120 einen Timeout von 120 Sekunden, um sicherzustellen, dass auch bei schlechtem Netzwerk noch genügend Zeit für die Installation bleibt. Wenn Sie es nicht einrichten, kann es vorkommen, dass das Installationspaket aufgrund einer Zeitüberschreitung beim Herunterladen in einer häuslichen Umgebung fehlschlägt.
Beachten Sie, dass nicht alle Bilder im Voraus aus dem Lager gezogen werden.
Vorausgesetzt, Sie haben Docker installiert und konfiguriert, benötigen Sie nur zwei Befehlszeilen image_name:tag um die Konfiguration der Deep-Learning-Umgebung abzuschließen. Nach dem Anzeigen der Versionsbeschreibung können Sie eine Auswahl treffen folgt:
hoperj/quickstart:base-torch2.5.1-cuda11.8-cudnn9-develhoperj/quickstart:dl-torch2.5.1-cuda11.8-cudnn9-develDer Pull-Befehl lautet:
docker pull < image_name:tag >Im Folgenden wird die dl -Version als Beispiel verwendet, um den Befehl zu demonstrieren. Wählen Sie eine der auszuführenden Methoden.
docker pull dockerpull.org/hoperj/quickstart:dl-torch2.5.1-cuda11.8-cudnn9-develdocker pull hoperj/quickstart:dl-torch2.5.1-cuda11.8-cudnn9-develDateien können über Baidu Cloud Disk heruntergeladen werden (Alibaba Cloud Disk unterstützt nicht die gemeinsame Nutzung großer komprimierter Dateien).
Die Dateien mit demselben Namen haben denselben Inhalt.
.tar.gzist eine komprimierte Version. Dekomprimieren Sie sie nach dem Herunterladen mit dem folgenden Befehl:gzip -d dl.tar.gz
Angenommen, dl.tar wurde nach ~/Downloads heruntergeladen, dann wechseln Sie in das entsprechende Verzeichnis:
cd ~ /DownloadsLaden Sie dann das Bild:
docker load -i dl.tarIn diesem Modus verwendet der Container direkt die Netzwerkkonfiguration des Hosts. Alle Ports entsprechen den Ports des Hosts und müssen nicht separat zugeordnet werden. Wenn Sie nur einen bestimmten Port zuordnen müssen, ersetzen Sie
--network hostdurch-p port:port.
docker run --gpus all -it --name ai --network host hoperj/quickstart:dl-torch2.5.1-cuda11.8-cudnn9-devel /bin/zsh Für Schüler, die einen Proxy verwenden müssen, fügen Sie -e hinzu, um Umgebungsvariablen festzulegen. Sie können auch den erweiterten Artikel a lesen:
Gehen Sie davon aus, dass die HTTP/HTTPS-Portnummer des Proxys 7890 und SOCKS5 7891 ist:
-e http_proxy=http://127.0.0.1:7890-e https_proxy=http://127.0.0.1:7890-e all_proxy=socks5://127.0.0.1:7891Integriert in den vorherigen Befehl:
docker run --gpus all -it
--name ai
--network host
-e http_proxy=http://127.0.0.1:7890
-e https_proxy=http://127.0.0.1:7890
-e all_proxy=socks5://127.0.0.1:7891
hoperj/quickstart:dl-torch2.5.1-cuda11.8-cudnn9-devel
/bin/zsh[!Tipp]
Informieren Sie sich vorab über die gängigen Abläufe :
- Starten Sie den Container :
docker start <容器名>- Führen Sie den Container aus :
docker exec -it <容器名> /bin/zsh
- Beenden innerhalb des Containers :
Ctrl + Doderexit.- Stoppen Sie den Container :
docker stop <容器名>- Löschen Sie einen Container :
docker rm <容器名>
git clone https://github.com/Hoper-J/AI-Guide-and-Demos-zh_CN.git
cd AI-Guide-and-Demos-zh_CNjupyter lab --ip=0.0.0.0 --port=8888 --no-browser --allow-root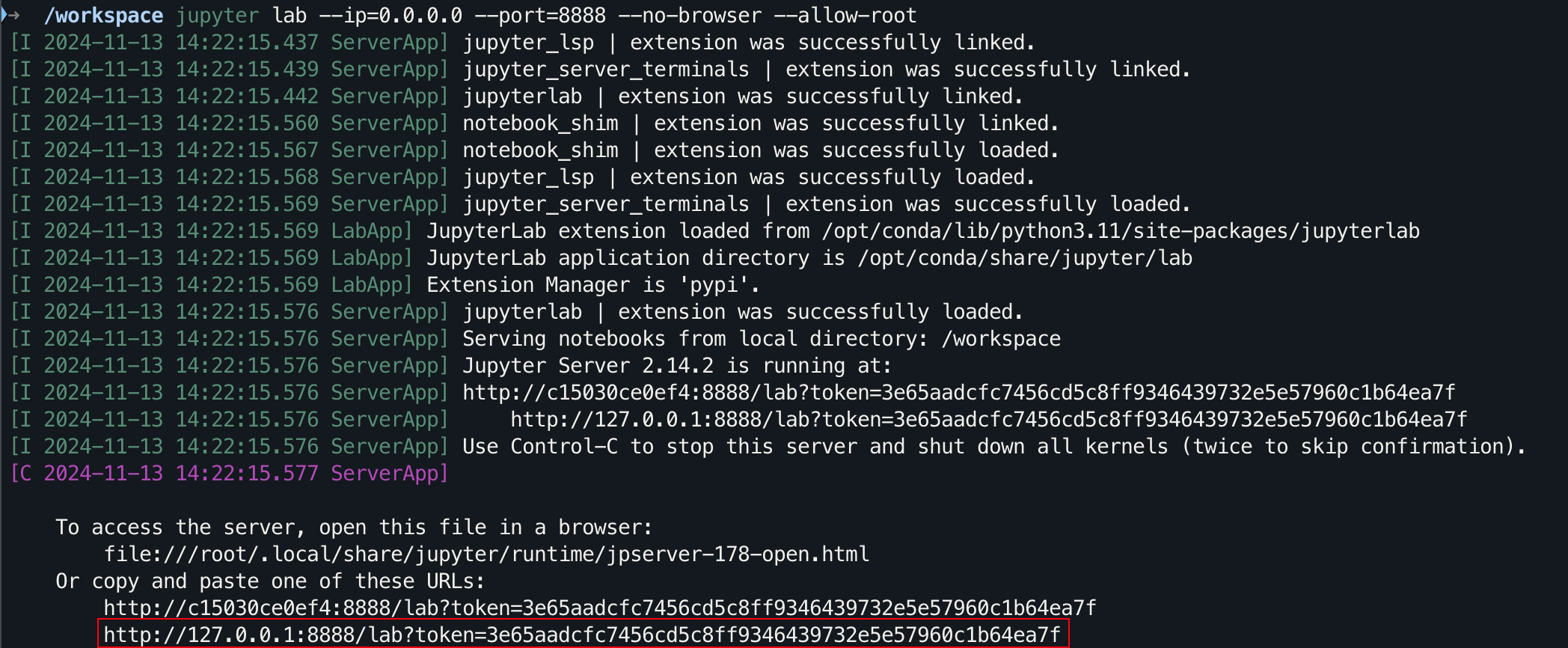
Für die grafische Benutzeroberfläche halten Sie unter Windows/Linux Ctrl und auf dem Mac Command gedrückt und klicken Sie dann auf den Link, um direkt zu springen.
Danke für deinen STAR? Ich hoffe, das hilft.


