CQN
1.0.0
Eine Neuimplementierung von Coarse-to-fine Q-Network (CQN) , einem probeneffizienten, wertbasierten RL-Algorithmus für kontinuierliche Steuerung, eingeführt in:
Kontinuierliche Kontrolle mit Verstärkungslernen vom Groben bis zum Feinen
Younggyo Seo, Jafar Uruç, Stephen James
Unsere Kernidee besteht darin, RL-Agenten zu erlernen, die von grob bis fein in den kontinuierlichen Aktionsraum hineinzoomen, sodass wir wertebasierte RL-Agenten für kontinuierliche Kontrolle mit wenigen diskreten Aktionen auf jeder Ebene trainieren können.
Weitere Informationen finden Sie auf unserer Projektwebseite https://youngggyo.me/cqn/.
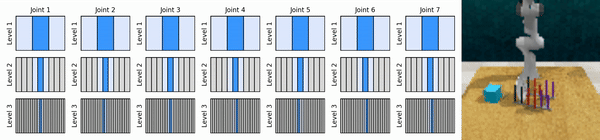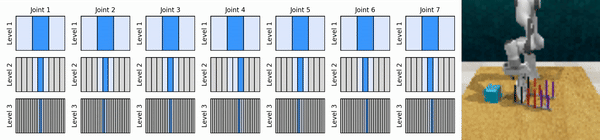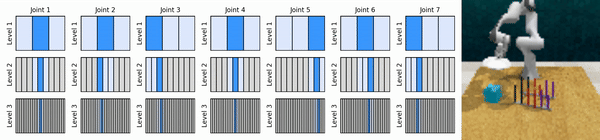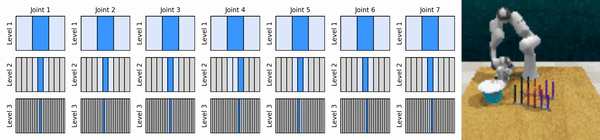
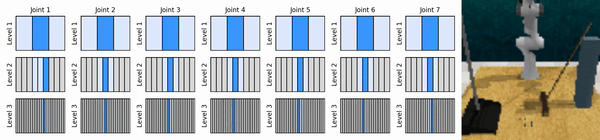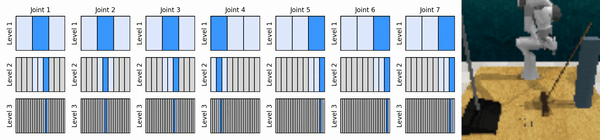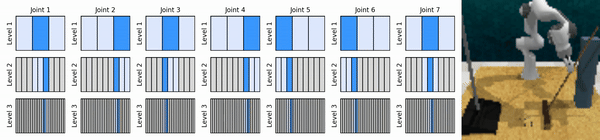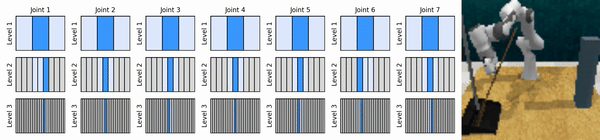
Installieren Sie die Conda-Umgebung:
conda env create -f conda_env.yml
conda activate cqn
Installieren Sie RLBench und PyRep (es sollten die neuesten Versionen mit dem Datum 10. Juli 2024 verwendet werden). Befolgen Sie die Anleitung in den Original-Repositorys für (1) die Installation von RLBench und PyRep und (2) die Aktivierung des Headless-Modus. (Informationen zur Installation von RLBench finden Sie in der README-Datei in RLBench und Robobase.)
git clone https://github.com/stepjam/RLBench
git clone https://github.com/stepjam/PyRep
# Install PyRep
cd PyRep
git checkout 8f420be8064b1970aae18a9cfbc978dfb15747ef
pip install .
# Install RLBench
cd RLBench
git checkout b80e51feb3694d9959cb8c0408cd385001b01382
pip install .
Vorab-Sammeldemonstrationen
cd RLBench/rlbench
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python dataset_generator.py --save_path=/your/own/directory --image_size 84 84 --renderer opengl3 --episodes_per_task 100 --variations 1 --processes 1 --tasks take_lid_off_saucepan --arm_max_velocity 2.0 --arm_max_acceleration 8.0
Experimente durchführen (CQN):
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python train_rlbench.py rlbench_task=take_lid_off_saucepan num_demos=100 dataset_root=/your/own/directory
Führen Sie Basisexperimente durch (DrQv2+):
CUDA_VISIBLE_DEVICES=0 DISPLAY=:0.0 python train_rlbench_drqv2plus.py rlbench_task=take_lid_off_saucepan num_demos=100 dataset_root=/your/own/directory
Führen Sie Experimente durch:
CUDA_VISIBLE_DEVICES=0 python train_dmc.py dmc_task=cartpole_swingup
Warnung: CQN wird in DMC nicht ausführlich getestet
Dieses Repository basiert auf der öffentlichen Implementierung von DrQ-v2
@article{seo2024continuous,
title={Continuous Control with Coarse-to-fine Reinforcement Learning},
author={Seo, Younggyo and Uru{c{c}}, Jafar and James, Stephen},
journal={arXiv preprint arXiv:2407.07787},
year={2024}
}


