lorax
v0.12.0: Multi-LoRA prefix caching, fp8 kv cache, Mllama, function calling

LoRAX: Multi-LoRA-Inferenzserver, der auf Tausende fein abgestimmter LLMs skaliert werden kann
LoRAX (LoRA eXchange) ist ein Framework, das es Benutzern ermöglicht, Tausende fein abgestimmter Modelle auf einer einzigen GPU bereitzustellen und so die Bereitstellungskosten drastisch zu senken, ohne Kompromisse beim Durchsatz oder der Latenz einzugehen.
Inhaltsverzeichnis
Merkmale
Modelle
?Erste Schritte
Anforderungen
Starten Sie den LoRAX-Server
Eingabeaufforderung über REST-API
Eingabeaufforderung über Python-Client
Chatten Sie über die OpenAI-API
Nächste Schritte
Danksagungen
Roadmap
Dynamisches Laden des Adapters: Fügen Sie einen beliebigen fein abgestimmten LoRA-Adapter von HuggingFace, Predibase oder einem beliebigen Dateisystem in Ihre Anfrage ein. Er wird just-in-time geladen, ohne gleichzeitige Anfragen zu blockieren. Führen Sie Adapter nach Bedarf zusammen, um im Handumdrehen leistungsstarke Ensembles zu erstellen.
Heterogenes kontinuierliches Batching: Packt Anforderungen für verschiedene Adapter in demselben Batch zusammen und hält Latenz und Durchsatz nahezu konstant mit der Anzahl gleichzeitiger Adapter.
Adapteraustauschplanung: ruft Adapter asynchron vorab ab und lädt sie zwischen GPU- und CPU-Speicher aus, plant Anforderungsstapelung, um den Gesamtdurchsatz des Systems zu optimieren.
Optimierte Inferenz: Optimierungen für hohen Durchsatz und geringe Latenz, einschließlich Tensorparallelität, vorkompilierte CUDA-Kernel (Flash-Attention, Paged Attention, SGMV), Quantisierung, Token-Streaming.
Bereit für die Produktion vorgefertigte Docker-Images, Helm-Charts für Kubernetes, Prometheus-Metriken und verteiltes Tracing mit Open Telemetry. OpenAI-kompatible API, die Chat-Gespräche mit mehreren Runden unterstützt. Private Adapter durch Mandantenisolierung pro Anfrage. Strukturierte Ausgabe (JSON-Modus).
? Kostenlos für kommerzielle Nutzung: Apache 2.0-Lizenz. Genug gesagt?
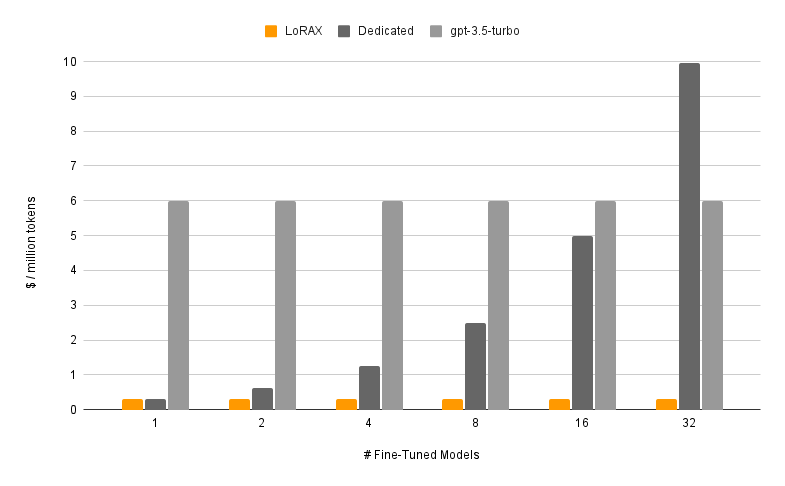
Die Bereitstellung eines fein abgestimmten Modells mit LoRAX besteht aus zwei Komponenten:
Basismodell: vorab trainiertes großes Modell, das von allen Adaptern gemeinsam genutzt wird.
Adapter: Aufgabenspezifische Adaptergewichte, die pro Anfrage dynamisch geladen werden.
LoRAX unterstützt eine Reihe großer Sprachmodelle als Basismodell, darunter Llama (einschließlich CodeLlama), Mistral (einschließlich Zephyr) und Qwen. Eine vollständige Liste der unterstützten Basismodelle finden Sie unter „Unterstützte Architekturen“.
Basismodelle können in fp16 geladen oder mit bitsandbytes , GPT-Q oder AWQ quantisiert werden.
Zu den unterstützten Adaptern gehören LoRA-Adapter, die mithilfe der PEFT- und Ludwig-Bibliotheken trainiert wurden. Alle linearen Schichten im Modell können über LoRA angepasst und in LoRAX geladen werden.
Wir empfehlen, mit unserem vorgefertigten Docker-Image zu beginnen, um das Kompilieren benutzerdefinierter CUDA-Kernel und anderer Abhängigkeiten zu vermeiden.
Zu den Mindestsystemanforderungen für die Ausführung von LoRAX gehören:
Nvidia-GPU (Ampere-Generation oder höher)
CUDA 11.8-kompatible Gerätetreiber und höher
Linux-Betriebssystem
Docker (für diese Anleitung)
Installieren Sie dann nvidia-container-toolkit
sudo systemctl daemon-reload
sudo systemctl restart docker
model=mistralai/Mistral-7B-Instruct-v0.1
volume=$PWD/data
docker run --gpus all --shm-size 1g -p 8080:80 -v $volume:/data
ghcr.io/predibase/lorax:main --model-id $modelEin vollständiges Tutorial einschließlich Token-Streaming und dem Python-Client finden Sie unter „Erste Schritte – Docker“.
Prompt-Basis-LLM:
Curl 127.0.0.1:8080/generieren
-X POST
-d '{ "Eingaben": „[INST] Natalia verkaufte im April Clips an 48 ihrer Freunde, und dann verkaufte sie im Mai halb so viele Clips. Wie viele Clips verkaufte Natalia insgesamt im April und Mai? [/INST] ", "parameters": { "max_new_tokens": 64 } }'
-H 'Inhaltstyp: application/json'Fordern Sie einen LoRA-Adapter an:
Curl 127.0.0.1:8080/generieren
-X POST
-d '{ "Eingaben": „[INST] Natalia verkaufte im April Clips an 48 ihrer Freunde, und dann verkaufte sie im Mai halb so viele Clips. Wie viele Clips verkaufte Natalia insgesamt im April und Mai? [/INST] ", "parameters": { "max_new_tokens": 64, "adapter_id": "vineetsharma/qlora-adapter-Mistral-7B-Instruct-v0.1-gsm8k" } }'
-H 'Inhaltstyp: application/json'Ausführliche Informationen finden Sie unter Referenz – REST-API.
Installieren:
pip install lorax-client
Laufen:
from lorax import Clientclient = Client("http://127.0.0.1:8080")# Prompt the base LLMprompt = "[INST] Natalia verkaufte im April Clips an 48 ihrer Freunde, und im Mai verkaufte sie halb so viele Clips . Wie viele Clips hat Natalia im April und Mai insgesamt verkauft? max_new_tokens=64).generated_text)# Einen LoRA-Adapter auffordernadapter_id = "vineetsharma/qlora-adapter-Mistral-7B-Instruct-v0.1-gsm8k"print(client.generate(prompt, max_new_tokens=64, adapter_id=adapter_id).generated_text )Ausführliche Informationen finden Sie unter Referenz – Python-Client.
Weitere Möglichkeiten zum Ausführen von LoRAX finden Sie unter Erste Schritte – Kubernetes, Erste Schritte – SkyPilot und Erste Schritte – Lokal.
LoRAX unterstützt Multi-Turn-Chat-Konversationen in Kombination mit dynamischem Adapterladen über eine OpenAI-kompatible API. Geben Sie einfach einen beliebigen Adapter als model an.
from openai import OpenAIclient = OpenAI(api_key="EMPTY",base_url="http://127.0.0.1:8080/v1",
)resp = client.chat.completions.create(model="alignment-handbook/zephyr-7b-dpo-lora",messages=[
{"role": "system",content": "Du bist ein freundlicher Chatbot, der immer im Stil eines Piraten antwortet",
},
{"role": "user", "content": "Wie viele Hubschrauber kann ein Mensch auf einmal essen?"},
],max_tokens=100,
)print("Response:", resp.choices[0].message.content)Weitere Informationen finden Sie unter OpenAI-kompatible API.
Hier sind einige weitere interessante, fein abgestimmte Mistral-7B-Modelle zum Ausprobieren:
Alignment-Handbook/zephyr-7b-dpo-lora: Mistral-7b mit DPO anhand des Zephyr-7B-Datensatzes verfeinert.
IlyaGusev/saiga_mistral_7b_lora: Russischer Chatbot basierend auf Open-Orca/Mistral-7B-OpenOrca .
Undi95/Mistral-7B-roleplay_alpaca-lora: Mithilfe von Rollenspielaufforderungen verfeinert.
Weitere LoRA-Adapter finden Sie hier oder versuchen Sie, Ihren eigenen mit PEFT oder Ludwig zu verfeinern.
LoRAX basiert auf der Textgenerierungsinferenz von HuggingFace, die aus Version 0.9.4 (Apache 2.0) stammt.
Wir möchten Punica auch für ihre Arbeit am SGMV-Kernel danken, der zur Beschleunigung der Multi-Adapter-Inferenz unter hoher Last verwendet wird.
Unsere Roadmap ist hier nachverfolgt.


