gpt neox
GPT-NeoX 2.0
In diesem Repository ist die Bibliothek von EleutherAI für das Training umfangreicher Sprachmodelle auf GPUs gespeichert. Unser aktuelles Framework basiert auf dem Megatron-Sprachmodell von NVIDIA und wurde um Techniken von DeepSpeed sowie einige neuartige Optimierungen erweitert. Unser Ziel ist es, dieses Repo zu einem zentralen und zugänglichen Ort zu machen, an dem Techniken zum Trainieren großer autoregressiver Sprachmodelle gesammelt werden und die Forschung im Bereich groß angelegtes Training beschleunigt wird. Diese Bibliothek wird in akademischen, industriellen und staatlichen Labors häufig genutzt, unter anderem von Forschern des Oak Ridge National Lab, CarperAI, Stability AI, Together.ai, der Korea University, der Carnegie Mellon University und der University of Tokyo. Einzigartig unter ähnlichen Bibliotheken unterstützt GPT-NeoX eine Vielzahl von Systemen und Hardware, einschließlich des Starts über Slurm, MPI und den IBM Job Step Manager, und wurde in großem Umfang auf AWS, CoreWeave, ORNL Summit, ORNL Frontier, LUMI usw. ausgeführt andere.
Wenn Sie Modelle mit Milliarden von Parametern nicht von Grund auf trainieren möchten, ist dies wahrscheinlich die falsche Bibliothek. Für generische Inferenzanforderungen empfehlen wir Ihnen stattdessen die Verwendung der Hugging Face transformers -Bibliothek, die GPT-NeoX-Modelle unterstützt.
GPT-NeoX nutzt viele der gleichen Funktionen und Technologien wie die beliebte Megatron-DeepSpeed-Bibliothek, jedoch mit deutlich verbesserter Benutzerfreundlichkeit und neuartigen Optimierungen. Zu den Hauptmerkmalen gehören:
[09.09.2024] Wir unterstützen jetzt Präferenzlernen über DPO, KTO und Belohnungsmodellierung
[9.9.2024] Wir unterstützen jetzt die Integration mit Comet ML, einer Überwachungsplattform für maschinelles Lernen
[21.05.2024] Wir unterstützen jetzt RWKV mit Pipeline-Parallelität!. Siehe die PRs für RWKV und RWKV+Pipeline
[21.03.2024] Wir unterstützen jetzt Mixture-of-Experts (MoE)
[17.03.2024] Wir unterstützen jetzt AMD MI250X GPUs
[15.03.2024] Wir unterstützen Mamba jetzt mit Tensorparallelität! Siehe PR
[10.08.2023] Wir unterstützen jetzt Checkpointing mit AWS S3! Aktivieren Sie mit der Konfigurationsoption s3_path (weitere Einzelheiten finden Sie in der PR).
[20.09.2023] Ab #1035 haben wir Flash Attention 0.x und 1.x als veraltet markiert und die Unterstützung auf Flash Attention 2.x migriert. Wir glauben nicht, dass dies zu Problemen führen wird, aber wenn Sie einen bestimmten Anwendungsfall haben, der alte Flash-Unterstützung mit dem neuesten GPT-NeoX erfordert, melden Sie bitte ein Problem.
[10.08.2023] Wir haben experimentelle Unterstützung für LLaMA 2 und Flash Attention v2 in unserem math-lm-Projekt, das später in diesem Monat hochgeladen wird.
[17.05.2023] Nachdem wir einige verschiedene Fehler behoben haben, unterstützen wir bf16 nun vollständig.
[11.04.2023] Wir haben unsere Flash Attention-Implementierung aktualisiert, um jetzt Alibi-Positionseinbettungen zu unterstützen.
[09.03.2023] Wir haben GPT-NeoX 2.0.0 veröffentlicht, eine aktualisierte Version, die auf dem neuesten DeepSpeed basiert und in Zukunft regelmäßig synchronisiert wird.
Vor dem 09.03.2023 verließ sich GPT-NeoX auf DeeperSpeed, das auf einer alten Version von DeepSpeed (0.3.15) basierte. Um auf die neueste Upstream-DeepSpeed-Version zu migrieren und Benutzern gleichzeitig den Zugriff auf die alten Versionen von GPT-NeoX und DeeperSpeed zu ermöglichen, haben wir zwei versionierte Versionen für beide Bibliotheken eingeführt:
Diese Codebasis wurde hauptsächlich für Python 3.8–3.10 und PyTorch 1.8–2.0 entwickelt und getestet. Dies ist keine strenge Anforderung und andere Versionen und Kombinationen von Bibliotheken funktionieren möglicherweise.
Führen Sie Folgendes aus, um die verbleibenden grundlegenden Abhängigkeiten zu installieren:
pip install -r requirements/requirements.txt
pip install -r requirements/requirements-wandb.txt # optional, if logging using WandB
pip install -r requirements/requirements-tensorboard.txt # optional, if logging via tensorboard
pip install -r requirements/requirements-comet.txt # optional, if logging via Cometaus dem Repository-Stammverzeichnis.
Warnung
Unsere Codebasis basiert auf DeeperSpeed, unserem Zweig der DeepSpeed-Bibliothek mit einigen zusätzlichen Änderungen. Wir empfehlen dringend, Anaconda, eine virtuelle Maschine oder eine andere Form der Umgebungsisolierung zu verwenden, bevor Sie fortfahren. Andernfalls kann es zum Ausfall anderer Repositorys kommen, die auf DeepSpeed basieren.
Wir unterstützen jetzt AMD-GPUs (MI100, MI250X) durch JIT-Fused-Kernel-Kompilierung. Fusionierte Kernel werden nach Bedarf erstellt und geladen. Um Wartezeiten beim Jobstart zu vermeiden, können Sie beim manuellen Prebuild auch Folgendes tun:
python
from megatron . fused_kernels import load
load () Dadurch wird der Erstellungsprozess automatisch an verschiedene GPU-Anbieter (AMD, NVIDIA) angepasst, ohne dass plattformspezifische Codeänderungen erforderlich sind. Um fusionierte Kernel mit pytest weiter zu testen, verwenden Sie pytest tests/model/test_fused_kernels.py
Um Flash-Attention zu verwenden, installieren Sie die zusätzlichen Abhängigkeiten in ./requirements/requirements-flashattention.txt und legen Sie den Aufmerksamkeitstyp in Ihrer Konfiguration entsprechend fest (siehe Konfigurationen). Dies kann bei bestimmten GPU-Architekturen, einschließlich Ampere-GPUs (z. B. A100s), zu erheblichen Geschwindigkeitssteigerungen im Vergleich zur normalen Aufmerksamkeit führen. Weitere Informationen finden Sie im Repository.
NeoX und Deep(er)Speed unterstützen das Training auf mehreren verschiedenen Knoten und Sie haben die Möglichkeit, verschiedene Launcher zu verwenden, um Multi-Knoten-Jobs zu orchestrieren.
Im Allgemeinen muss irgendwo eine „Hostdatei“ vorhanden sein, auf die im folgenden Format zugegriffen werden kann:
node1_ip slots=8
node2_ip slots=8 Dabei enthält die erste Spalte die IP-Adresse für jeden Knoten in Ihrem Setup und die Anzahl der Steckplätze ist die Anzahl der GPUs, auf die dieser Knoten Zugriff hat. In Ihrer Konfiguration müssen Sie den Pfad zur Hostdatei mit "hostfile": "/path/to/hostfile" . Alternativ kann der Pfad zur Hostdatei in der Umgebungsvariablen DLTS_HOSTFILE stehen.
pdsh ist der Standard-Launcher. Wenn Sie pdsh verwenden, müssen Sie lediglich sicherstellen, dass pdsh in Ihrer Umgebung installiert ist: {"launcher": "pdsh"} in Ihren Konfigurationsdateien festlegen.
Wenn Sie MPI verwenden, müssen Sie die MPI-Bibliothek angeben (DeepSpeed/GPT-NeoX unterstützt derzeit mvapich , openmpi , mpich und impi , obwohl openmpi am häufigsten verwendet und getestet wird) und das Flag deepspeed_mpi in Ihrer Konfigurationsdatei übergeben:
{
"launcher" : " openmpi " ,
"deepspeed_mpi" : true
} Wenn Ihre Umgebung richtig eingerichtet ist und die richtigen Konfigurationsdateien vorhanden sind, können Sie deepy.py wie ein normales Python-Skript verwenden und (zum Beispiel) einen Trainingsjob starten mit:
python3 deepy.py train.py /path/to/configs/my_model.yml
Die Verwendung von Slurm kann etwas aufwändiger sein. Wie bei MPI müssen Sie Ihrer Konfiguration Folgendes hinzufügen:
{
"launcher" : " slurm " ,
"deepspeed_slurm" : true
} Wenn Sie keinen SSH-Zugriff auf die Rechenknoten in Ihrem Slurm-Cluster haben, müssen Sie {"no_ssh_check": true} hinzufügen.
In vielen Fällen reichen die oben genannten Standard-Startoptionen nicht aus
In diesen Fällen müssen Sie das DeepSpeed-Multinode-Runner-Dienstprogramm ändern, um Ihren Anwendungsfall zu unterstützen. Im Großen und Ganzen fallen diese Verbesserungen in zwei Kategorien:
In diesem Fall müssen Sie eine neue Multinode-Runner-Klasse zu deepspeed/launcher/multinode_runner.py hinzufügen und diese als Konfigurationsoption in GPT-NeoX verfügbar machen. Beispiele dafür, wie wir dies für Summit JSRun gemacht haben, finden Sie in diesem DeeperSpeed-Commit bzw. diesem GPT-NeoX-Commit.
Wir sind auf viele Fälle gestoßen, in denen wir den MPI/Slurm-Run-Befehl für eine Optimierung oder zum Debuggen ändern möchten (z. B. um die Slurm-Srun-CPU-Bindung zu ändern oder MPI-Protokolle mit dem Rang zu kennzeichnen). In diesem Fall müssen Sie den Ausführungsbefehl der Multinode-Runner-Klasse unter ihrer get_cmd -Methode ändern (z. B. mpirun_cmd für OpenMPI). Beispiele dafür, wie wir dies getan haben, um mithilfe von Slurm und OpenMPI für den Stability-Cluster optimierte und mit Rang versehene Ausführungsbefehle bereitzustellen, finden Sie in diesem DeeperSpeed-Zweig
Im Allgemeinen können Sie nicht über eine einzelne feste Hostdatei verfügen, daher benötigen Sie ein Skript, um eine solche dynamisch zu generieren, wenn Ihr Job beginnt. Ein Beispielskript zum dynamischen Generieren einer Hostdatei mit Slurm und 8 GPUs pro Knoten ist:
#! /bin/bash
GPUS_PER_NODE=8
mkdir -p /sample/path/to/hostfiles
# need to add the current slurm jobid to hostfile name so that we don't add to previous hostfile
hostfile=/sample/path/to/hostfiles/hosts_ $SLURM_JOBID
# be extra sure we aren't appending to a previous hostfile
rm $hostfile & > /dev/null
# loop over the node names
for i in ` scontrol show hostnames $SLURM_NODELIST `
do
# add a line to the hostfile
echo $i slots= $GPUS_PER_NODE >> $hostfile
done $SLURM_JOBID und $SLURM_NODELIST sind Umgebungsvariablen, die Slurm für Sie erstellt. Eine vollständige Liste der verfügbaren Slurm-Umgebungsvariablen, die zum Zeitpunkt der Joberstellung festgelegt werden, finden Sie in der Sbatch-Dokumentation.
Anschließend können Sie ein Sbatch-Skript erstellen, von dem aus Sie Ihren GPT-NeoX-Job starten können. Ein einfaches Sbatch-Skript auf einem Slurm-basierten Cluster mit 8 GPUs pro Knoten würde so aussehen:
#! /bin/bash
# SBATCH --job-name="neox"
# SBATCH --partition=your-partition
# SBATCH --nodes=1
# SBATCH --ntasks-per-node=8
# SBATCH --gres=gpu:8
# Some potentially useful distributed environment variables
export HOSTNAMES= ` scontrol show hostnames " $SLURM_JOB_NODELIST " `
export MASTER_ADDR= $( scontrol show hostnames " $SLURM_JOB_NODELIST " | head -n 1 )
export MASTER_PORT=12802
export COUNT_NODE= ` scontrol show hostnames " $SLURM_JOB_NODELIST " | wc -l `
# Your hostfile creation script from above
./write_hostfile.sh
# Tell DeepSpeed where to find our generated hostfile via DLTS_HOSTFILE
export DLTS_HOSTFILE=/sample/path/to/hostfiles/hosts_ $SLURM_JOBID
# Launch training
python3 deepy.py train.py /sample/path/to/your/configs/my_model.yml
Anschließend können Sie mit sbatch my_sbatch_script.sh einen Trainingslauf starten
Wir bieten auch eine Dockerfile- und Docker-Compose-Konfiguration an, wenn Sie NeoX lieber in einem Container ausführen möchten.
Voraussetzungen für die Ausführung des Containers sind die entsprechenden GPU-Treiber, eine aktuelle Installation von Docker und die Installation des nvidia-container-toolkits. Um zu testen, ob Ihre Installation gut ist, können Sie deren „Beispiel-Workload“ verwenden:
docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
Vorausgesetzt, dass dies ausgeführt wird, müssen Sie NEOX_DATA_PATH und NEOX_CHECKPOINT_PATH in Ihre Umgebung exportieren, um Ihr Datenverzeichnis und das Verzeichnis zum Speichern und Laden von Prüfpunkten anzugeben:
export NEOX_DATA_PATH=/mnt/sda/data/enwiki8 #or wherever your data is stored on your system
export NEOX_CHECKPOINT_PATH=/mnt/sda/checkpoints
Und dann können Sie aus dem gpt-neox-Verzeichnis das Image erstellen und eine Shell in einem Container ausführen
docker compose run gpt-neox bash
Nach dem Build sollten Sie Folgendes tun können:
mchorse@537851ed67de:~$ echo $(pwd)
/home/mchorse
mchorse@537851ed67de:~$ ls -al
total 48
drwxr-xr-x 1 mchorse mchorse 4096 Jan 8 05:33 .
drwxr-xr-x 1 root root 4096 Jan 8 04:09 ..
-rw-r--r-- 1 mchorse mchorse 220 Feb 25 2020 .bash_logout
-rw-r--r-- 1 mchorse mchorse 3972 Jan 8 04:09 .bashrc
drwxr-xr-x 4 mchorse mchorse 4096 Jan 8 05:35 .cache
drwx------ 3 mchorse mchorse 4096 Jan 8 05:33 .nv
-rw-r--r-- 1 mchorse mchorse 807 Feb 25 2020 .profile
drwxr-xr-x 2 root root 4096 Jan 8 04:09 .ssh
drwxrwxr-x 8 mchorse mchorse 4096 Jan 8 05:35 chk
drwxrwxrwx 6 root root 4096 Jan 7 17:02 data
drwxr-xr-x 11 mchorse mchorse 4096 Jan 8 03:52 gpt-neox
Für einen Job mit langer Laufzeit sollten Sie ausführen
docker compose up -d
um den Container im getrennten Modus auszuführen und ihn dann in einer separaten Terminalsitzung auszuführen
docker compose exec gpt-neox bash
Anschließend können Sie jeden gewünschten Job im Container ausführen.
Zu den Bedenken bei längerem Betrieb oder im getrennten Modus gehören:
Wenn Sie das vorgefertigte Container-Image lieber von Dockerhub ausführen möchten, können Sie die Docker-Compose-Befehle stattdessen mit -f docker-compose-dockerhub.yml ausführen, z. B.
docker compose run -f docker-compose-dockerhub.yml gpt-neox bash
Alle Funktionen sollten mit deepy.py gestartet werden, einem Wrapper um den deepspeed -Launcher.
Wir bieten derzeit drei Hauptfunktionen an:
train.py wird für das Training und die Feinabstimmung von Modellen verwendet.eval.py wird verwendet, um ein trainiertes Modell mithilfe des Sprachmodell-Bewertungssystems auszuwerten.generate.py wird verwendet, um Text aus einem trainierten Modell abzutasten.die gestartet werden kann mit:
./deepy.py [script.py] [./path/to/config_1.yml] [./path/to/config_2.yml] ... [./path/to/config_n.yml]Um beispielsweise ein Training zu starten, können Sie laufen
./deepy.py train.py ./configs/20B.yml ./configs/local_cluster.ymlWeitere Einzelheiten zu den einzelnen Einstiegspunkten finden Sie in den Abschnitten „Schulung“ und „Feinabstimmung“, „Inferenz“ und „Bewertung“.
GPT-NeoX-Parameter werden in einer YAML-Konfigurationsdatei definiert, die an den deepy.py-Launcher übergeben wird. Wir haben einige .yml-Beispieldateien in Konfigurationen bereitgestellt, die eine Vielzahl von Funktionen und Modellgrößen zeigen.
Diese Dateien sind im Allgemeinen vollständig, aber nicht optimal. Abhängig von Ihrer spezifischen GPU-Konfiguration müssen Sie beispielsweise möglicherweise einige Einstellungen ändern, z. B. pipe-parallel-size , model-parallel-size um den Grad der Parallelisierung zu erhöhen oder zu verringern, train_micro_batch_size_per_gpu oder gradient-accumulation-steps um die Stapelgröße zu ändern Zugehörige Einstellungen oder das Diktat zero_optimization , um zu ändern, wie Optimiererzustände über Worker hinweg parallelisiert werden.
Eine ausführlichere Anleitung zu den verfügbaren Funktionen und deren Konfiguration finden Sie in der README-Datei zur Konfiguration. Die Dokumentation aller möglichen Argumente finden Sie unter configs/neox_arguments.md.
GPT-NeoX umfasst mehrere Expertenimplementierungen für MoE. Um zwischen ihnen zu wählen, geben Sie moe_type of megablocks (Standard) oder deepspeed an.
Beide basieren auf dem DeepSpeed MoE-Parallelitäts-Framework, das Tensor-Experten-Daten-Parallelität unterstützt. Bei beiden können Sie zwischen Token-Drop und Dropless umschalten (Standardeinstellung, und dafür wurde Megablocks entwickelt). Sinkhorn-Routen folgen bald!
Ein Beispiel für eine grundlegende vollständige Konfiguration finden Sie unter configs/125M-dmoe.yml (für Megablocks Dropless) oder configs/125M-moe.yml.
Den meisten MoE-bezogenen Konfigurationsargumenten wird moe vorangestellt. Einige gängige Konfigurationsparameter und ihre Standardwerte sind wie folgt:
moe_type: megablocks
moe_num_experts: 1 # 1 disables MoE. 8 is a reasonable value.
moe_loss_coeff: 0.1
expert_interval: 2 # See details below
enable_expert_tensor_parallelism: false # See details below
moe_expert_parallel_size: 1 # See details below
moe_token_dropping: false
DeepSpeed kann wie folgt weiter konfiguriert werden:
moe_top_k: 1
moe_min_capacity: 4
moe_train_capacity_factor: 1.0 # Setting to 1.0
moe_eval_capacity_factor: 1.0 # Setting to 1.0
Eine MoE-Schicht ist auf jeder expert_interval Transformatorschicht vorhanden, einschließlich der ersten, also insgesamt 12 Schichten:
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11
Experten wären in diesen Schichten:
0, 2, 4, 6, 8, 10
Standardmäßig verwenden wir Expertendatenparallelität, sodass jede verfügbare Tensorparallelität ( model_parallel_size ) für das Expertenrouting verwendet wird. Zum Beispiel angesichts des Folgenden:
expert_parallel_size: 4
model_parallel_size: 2 # aka tensor parallelism
Bei 32 GPUs sieht das Verhalten wie folgt aus:
expert_parallel_size == model_parallel_size . Durch das Festlegen von enable_expert_tensor_parallelism wird die Tensor-Expertendaten-Parallelität (TED) aktiviert. Die Interpretation des oben Gesagten wäre dann:
expert_parallel_size == 1 oder model_parallel_size == 1 .Beachten Sie also, dass DP durch (MP * EP) teilbar sein muss. Weitere Einzelheiten finden Sie im TED-Papier.
Pipeline-Parallelität wird noch nicht unterstützt – kommt bald!
Es stehen mehrere vorkonfigurierte Datensätze zur Verfügung, darunter die meisten Komponenten des Pile sowie der Pile-Zugsatz selbst, für eine einfache Tokenisierung mithilfe des Einstiegspunkts prepare_data.py .
Um beispielsweise den enwik8-Datensatz mit dem GPT2-Tokenizer herunterzuladen und zu tokenisieren und ihn unter ./data zu speichern, können Sie Folgendes ausführen:
python prepare_data.py -d ./data
oder ein einzelner Shard des Stapels ( pile_subset ) mit dem GPT-NeoX-20B-Tokenizer (vorausgesetzt, Sie haben ihn unter ./20B_checkpoints/20B_tokenizer.json gespeichert):
python prepare_data.py -d ./data -t HFTokenizer --vocab-file ./20B_checkpoints/20B_tokenizer.json pile_subset
Die tokenisierten Daten werden in zwei Dateien gespeichert: [data-dir]/[dataset-name]/[dataset-name]_text_document.bin und [data-dir]/[dataset-name]/[dataset-name]_text_document.idx . Sie müssen das Präfix, das diese beiden Dateien gemeinsam haben, zu Ihrer Trainingskonfigurationsdatei im Feld data-path hinzufügen. Z.B:
" data-path " : " ./data/enwik8/enwik8_text_document " , Um Ihren eigenen Datensatz für das Training mit benutzerdefinierten Daten vorzubereiten, formatieren Sie ihn als eine große JSONL-formatierte Datei, wobei jedes Element in der Liste der Wörterbücher ein separates Dokument ist. Der Dokumenttext sollte unter einem JSON-Schlüssel gruppiert werden, z. B. "text" . In anderen Feldern gespeicherte Zusatzdaten werden nicht verwendet.
Stellen Sie als Nächstes sicher, dass Sie das GPT2-Tokenizer-Vokabular herunterladen und die Dateien über die folgenden Links zusammenführen:
Oder verwenden Sie den 20B-Tokenizer (für den nur eine einzige Vocab-Datei benötigt wird):
(Alternativ können Sie mit dem Befehl Tokenizer.from_pretrained() jede beliebige Tokenizer-Datei bereitstellen, die von der Tokenizer-Bibliothek von Hugging Face geladen werden kann.)
Sie können Ihre Daten jetzt mit tools/datasets/preprocess_data.py vorab tokenisieren. Die Argumente dafür sind unten aufgeführt:
usage: preprocess_data.py [-h] --input INPUT [--jsonl-keys JSONL_KEYS [JSONL_KEYS ...]] [--num-docs NUM_DOCS] --tokenizer-type {HFGPT2Tokenizer,HFTokenizer,GPT2BPETokenizer,CharLevelTokenizer} [--vocab-file VOCAB_FILE] [--merge-file MERGE_FILE] [--append-eod] [--ftfy] --output-prefix OUTPUT_PREFIX
[--dataset-impl {lazy,cached,mmap}] [--workers WORKERS] [--log-interval LOG_INTERVAL]
optional arguments:
-h, --help show this help message and exit
input data:
--input INPUT Path to input jsonl files or lmd archive(s) - if using multiple archives, put them in a comma separated list
--jsonl-keys JSONL_KEYS [JSONL_KEYS ...]
space separate listed of keys to extract from jsonl. Default: text
--num-docs NUM_DOCS Optional: Number of documents in the input data (if known) for an accurate progress bar.
tokenizer:
--tokenizer-type {HFGPT2Tokenizer,HFTokenizer,GPT2BPETokenizer,CharLevelTokenizer}
What type of tokenizer to use.
--vocab-file VOCAB_FILE
Path to the vocab file
--merge-file MERGE_FILE
Path to the BPE merge file (if necessary).
--append-eod Append an <eod> token to the end of a document.
--ftfy Use ftfy to clean text
output data:
--output-prefix OUTPUT_PREFIX
Path to binary output file without suffix
--dataset-impl {lazy,cached,mmap}
Dataset implementation to use. Default: mmap
runtime:
--workers WORKERS Number of worker processes to launch
--log-interval LOG_INTERVAL
Interval between progress updates
Zum Beispiel:
python tools/datasets/preprocess_data.py
--input ./data/mydataset.jsonl.zst
--output-prefix ./data/mydataset
--vocab ./data/gpt2-vocab.json
--merge-file gpt2-merges.txt
--dataset-impl mmap
--tokenizer-type GPT2BPETokenizer
--append-eodAnschließend würden Sie das Training mit den folgenden Einstellungen ausführen, die Ihrer Konfigurationsdatei hinzugefügt wurden:
" data-path " : " data/mydataset_text_document " , Das Training wird mit deepy.py gestartet, einem Wrapper um den Launcher von DeepSpeed, der dasselbe Skript parallel auf vielen GPUs/Knoten startet.
Das allgemeine Nutzungsmuster ist:
python ./deepy.py train.py [path/to/config1.yml] [path/to/config2.yml] ...Sie können eine beliebige Anzahl von Konfigurationen übergeben, die alle zur Laufzeit zusammengeführt werden.
Sie können optional auch ein Konfigurationspräfix übergeben, das davon ausgeht, dass sich alle Ihre Konfigurationen im selben Ordner befinden, und dieses Präfix an ihren Pfad anhängt.
Zum Beispiel:
python ./deepy.py train.py -d configs 125M.yml local_setup.yml Dadurch wird das train.py -Skript auf allen Knoten mit einem Prozess pro GPU bereitgestellt. Die Worker-Knoten und die Anzahl der GPUs werden in der Datei /job/hostfile angegeben (siehe Parameterdokumentation) oder können einfach als num_gpus -Argument übergeben werden, wenn sie auf einem Einzelknoten-Setup ausgeführt werden.
Obwohl dies nicht unbedingt notwendig ist, finden wir es nützlich, die Modellparameter in einer Konfigurationsdatei (z. B. configs/125M.yml ) und die Datenpfadparameter in einer anderen (z. B. configs/local_setup.yml ) zu definieren.
GPT-NeoX-20B ist ein auf dem Pile trainiertes autoregressives Sprachmodell mit 20 Milliarden Parametern. Technische Details zu GPT-NeoX-20B finden Sie im zugehörigen Dokument. Die Konfigurationsdatei für dieses Modell ist sowohl unter ./configs/20B.yml verfügbar als auch in den Download-Links unten enthalten.
Schlanke Gewichte – (Keine Optimierungszustände, für Inferenz oder Feinabstimmung, 39 GB)
Um von der Befehlszeile in einen Ordner namens 20B_checkpoints herunterzuladen, verwenden Sie den folgenden Befehl:
wget --cut-dirs=5 -nH -r --no-parent --reject " index.html* " https://the-eye.eu/public/AI/models/GPT-NeoX-20B/slim_weights/ -P 20B_checkpointsVolle Gewichte – (einschließlich Optimierungsstatus, 268 GB)
Um von der Befehlszeile in einen Ordner namens 20B_checkpoints herunterzuladen, verwenden Sie den folgenden Befehl:
wget --cut-dirs=5 -nH -r --no-parent --reject " index.html* " https://the-eye.eu/public/AI/models/GPT-NeoX-20B/full_weights/ -P 20B_checkpointsGewichte können alternativ über einen BitTorrent-Client heruntergeladen werden. Torrent-Dateien können hier heruntergeladen werden: schlanke Gewichte, volle Gewichte.
Darüber hinaus haben wir während des Trainings 150 Kontrollpunkte gespeichert, einen alle 1.000 Schritte. Wir arbeiten daran, herauszufinden, wie wir diese am besten in großem Maßstab bedienen können. In der Zwischenzeit können Personen, die an einer Zusammenarbeit mit den teilweise ausgebildeten Kontrollpunkten interessiert sind, uns eine E-Mail an [email protected] senden, um den Zugang zu vereinbaren.
Die Pythia Scaling Suite ist eine Reihe von Modellen, die von 70 Millionen Parametern bis zu 12 Milliarden Parametern reichen und auf dem Pile trainiert wurden, um die Forschung zur Interpretierbarkeit und Trainingsdynamik großer Sprachmodelle zu fördern. Weitere Details zum Projekt und Links zu den Modellen finden Sie im Paper und auf dem GitHub des Projekts.
Das Polyglot-Projekt ist ein Versuch, leistungsstarke nicht-englische vorab trainierte Sprachmodelle zu trainieren, um die Zugänglichkeit dieser Technologie für Forscher außerhalb der vorherrschenden Kraftwerke des maschinellen Lernens zu fördern. EleutherAI hat koreanische Sprachmodelle mit 1,3B, 3,8B und 5,8B Parametern trainiert und veröffentlicht, von denen das größte alle anderen öffentlich verfügbaren Sprachmodelle für koreanische Sprachaufgaben übertrifft. Weitere Details zum Projekt und Links zu den Modellen finden Sie hier.
Für die meisten Anwendungen empfehlen wir die Bereitstellung von Modellen, die mit der GPT-NeoX-Bibliothek trainiert wurden, über die Hugging Face Transformers-Bibliothek, die besser für Inferenz optimiert ist.
Wir unterstützen drei Arten der Generierung aus einem vorab trainierten Modell:
Alle drei Arten der Textgenerierung können über python ./deepy.py generate.py -d configs 125M.yml local_setup.yml text_generation.yml gestartet werden, wobei die entsprechenden Werte in configs/text_generation.yml festgelegt sind.
GPT-NeoX unterstützt die Bewertung nachgelagerter Aufgaben durch den Sprachmodell-Bewertungsstrang.
Um ein trainiertes Modell auf dem Evaluierungskabelbaum auszuwerten, führen Sie einfach Folgendes aus:
python ./deepy.py eval.py -d configs your_configs.yml --eval_tasks task1 task2 ... taskn Dabei ist --eval_tasks eine Liste von Bewertungsaufgaben, gefolgt von Leerzeichen, z. B. --eval_tasks lambada hellaswag piqa sciq . Einzelheiten zu allen verfügbaren Aufgaben finden Sie im lm-evaluation-harness-Repository.
GPT-NeoX ist stark nur für das Training optimiert und GPT-NeoX-Modellkontrollpunkte sind nicht sofort mit anderen Deep-Learning-Bibliotheken kompatibel. Um Modelle einfach ladbar und für Endbenutzer nutzbar zu machen und für den weiteren Export in verschiedene andere Frameworks zu ermöglichen, unterstützt GPT-NeoX die Checkpoint-Konvertierung in das Hugging Face Transformers-Format.
Obwohl NeoX eine Reihe verschiedener Architekturkonfigurationen unterstützt, einschließlich AliBi-Positionseinbettungen, sind nicht alle dieser Konfigurationen sauber auf die unterstützten Konfigurationen in Hugging Face Transformers abgebildet.
NeoX unterstützt den Export kompatibler Modelle in die folgenden Architekturen:
Das saubere Training eines Modells, das nicht in eine dieser Hugging Face Transformers-Architekturen passt, erfordert das Schreiben von benutzerdefiniertem Modellierungscode für das exportierte Modell.
Führen Sie Folgendes aus, um einen GPT-NeoX-Bibliotheksprüfpunkt in das ladbare Hugging Face-Format zu konvertieren:
python ./tools/ckpts/convert_neox_to_hf.py --input_dir /path/to/model/global_stepXXX --config_file your_config.yml --output_dir hf_model/save/location --precision {auto,fp16,bf16,fp32} --architecture {neox,mistral,llama}Um dann ein Modell auf den Hugging Face Hub hochzuladen, führen Sie Folgendes aus:
huggingface-cli login
python ./tools/ckpts/upload.pyund geben Sie die angeforderten Informationen ein, einschließlich des HF-Hub-Benutzertokens.
NeoX bietet mehrere Dienstprogramme zum Konvertieren eines vorab trainierten Modellprüfpunkts in ein Format, das innerhalb der Bibliothek trainiert werden kann.
Folgende Modelle bzw. Modellfamilien können in GPT-NeoX geladen werden:
Wir bieten zwei Dienstprogramme zum Konvertieren von zwei verschiedenen Checkpoint-Formaten in ein mit GPT-NeoX kompatibles Format.
Um einen von Meta AI vertriebenen Llama 1- oder Llama 2-Kontrollpunkt aus seinem ursprünglichen Dateiformat (hier oder hier herunterladbar) in die GPT-NeoX-Bibliothek zu konvertieren, führen Sie Folgendes aus:
python tools/ckpts/convert_raw_llama_weights_to_neox.py --input_dir /path/to/model/parent/dir/7B --model_size 7B --output_dir /path/to/save/ckpt --num_output_shards <TENSOR_PARALLEL_SIZE> (--pipeline_parallel if pipeline-parallel-size >= 1)
Um von einem Hugging Face-Modell in ein NeoX-ladbares Modell zu konvertieren, führen Sie tools/ckpts/convert_hf_to_sequential.py aus. Weitere Optionen finden Sie in der Dokumentation in dieser Datei.
Zusätzlich zur lokalen Speicherung von Protokollen bieten wir integrierte Unterstützung für zwei beliebte Frameworks zur Experimentüberwachung: Weights & Biases, TensorBoard und Comet
Weights & Biases zur Aufzeichnung unserer Experimente ist eine Überwachungsplattform für maschinelles Lernen. So verwenden Sie wandb zur Überwachung Ihrer gpt-neox-Experimente:
wandb login ausführen – Ihre Läufe werden automatisch aufgezeichnet../requirements/requirements-wandb.txt gefunden und dort installiert werden. Eine Beispielkonfiguration finden Sie in ./configs/local_setup_wandb.yml .wandb_group können Sie die Laufgruppe benennen und wandb_team können Sie Ihre Läufe einem Organisations- oder Teamkonto zuweisen. Eine Beispielkonfiguration finden Sie in ./configs/local_setup_wandb.yml . Wir unterstützen die Verwendung von TensorBoard über das Feld tensorboard-dir . Abhängigkeiten, die für die TensorBoard-Überwachung erforderlich sind, können unter ./requirements/requirements-tensorboard.txt gefunden und dort installiert werden.
Comet ist eine Überwachungsplattform für maschinelles Lernen. So verwenden Sie Comet zur Überwachung Ihrer gpt-neox-Experimente:
comet login ausführen oder export COMET_API_KEY=<your-key-here> übergebencomet_ml und alle Abhängigkeitsbibliotheken über pip install -r requirements/requirements-comet.txtuse_comet: True . Mit comet_workspace und comet_project können Sie auch anpassen, wo Daten protokolliert werden. Eine vollständige Beispielkonfiguration mit aktiviertem Comet finden Sie in configs/local_setup_comet.yml . Wenn Sie eine Hostdatei zur Verwendung mit dem MPI-basierten DeepSpeed-Launcher bereitstellen müssen, können Sie die Umgebungsvariable DLTS_HOSTFILE so festlegen, dass sie auf die Hostdatei verweist.
Wir unterstützen Profiling mit Nsight Systems, dem PyTorch Profiler und PyTorch Memory Profiling.
Um die Profilerstellung von Nsight Systems zu verwenden, legen Sie die Konfigurationsoptionen profile , profile_step_start und profile_step_stop fest (siehe hier für die Verwendung von Argumenten und hier für eine Beispielkonfiguration).
Um nsys-Metriken zu füllen, starten Sie das Training mit:
nsys profile -s none -t nvtx,cuda -o <path/to/profiling/output> --force-overwrite true
--capture-range=cudaProfilerApi --capture-range-end=stop python $TRAIN_PATH/deepy.py
$TRAIN_PATH/train.py --conf_dir configs <config files>
Die generierte Ausgabedatei kann dann mit der Nsight Systems-GUI angezeigt werden:
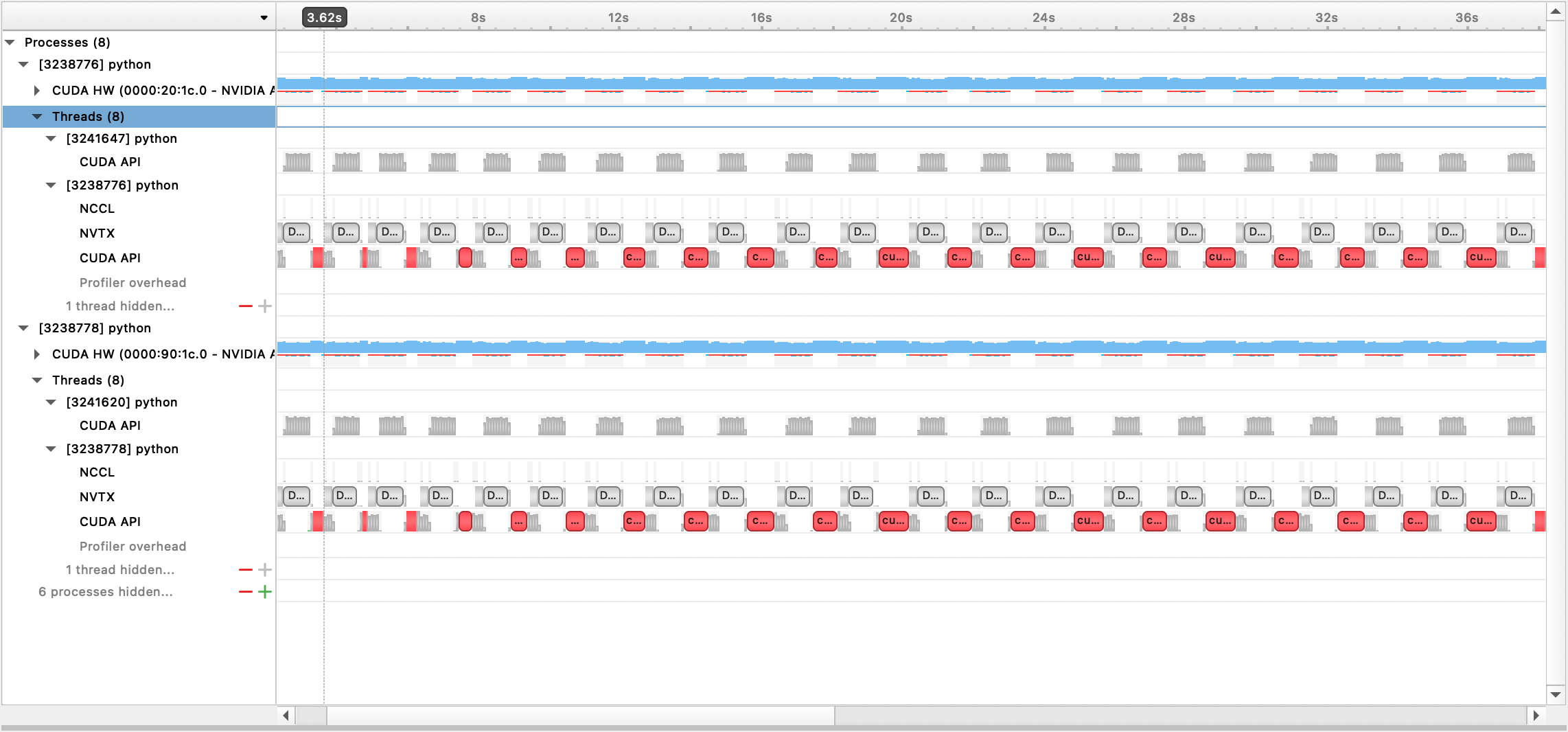
Um den integrierten PyTorch-Profiler zu verwenden, legen Sie die Konfigurationsoptionen profile , profile_step_start und profile_step_stop fest (siehe hier für die Verwendung von Argumenten und hier für eine Beispielkonfiguration).
Der PyTorch-Profiler speichert Spuren in Ihrem tensorboard Protokollverzeichnis. Sie können diese Spuren in TensorBoard anzeigen, indem Sie die Schritte hier ausführen.
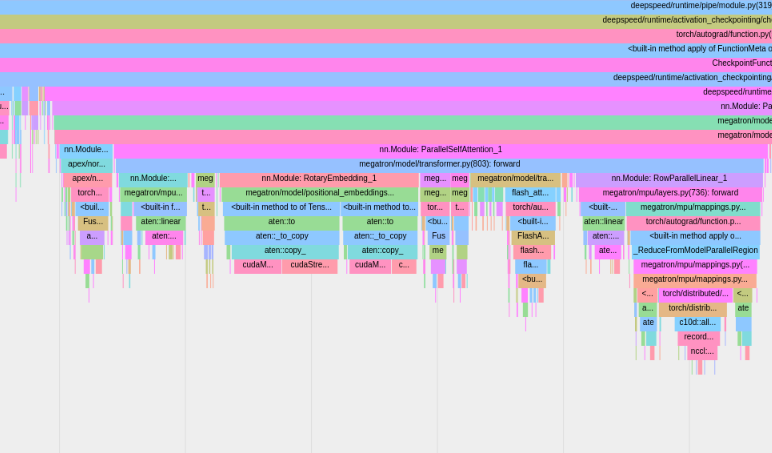
Um PyTorch Memory Profiling zu verwenden, legen Sie die Konfigurationsoptionen memory_profiling und memory_profiling_path fest (siehe hier für die Argumentverwendung und hier für eine Beispielkonfiguration).
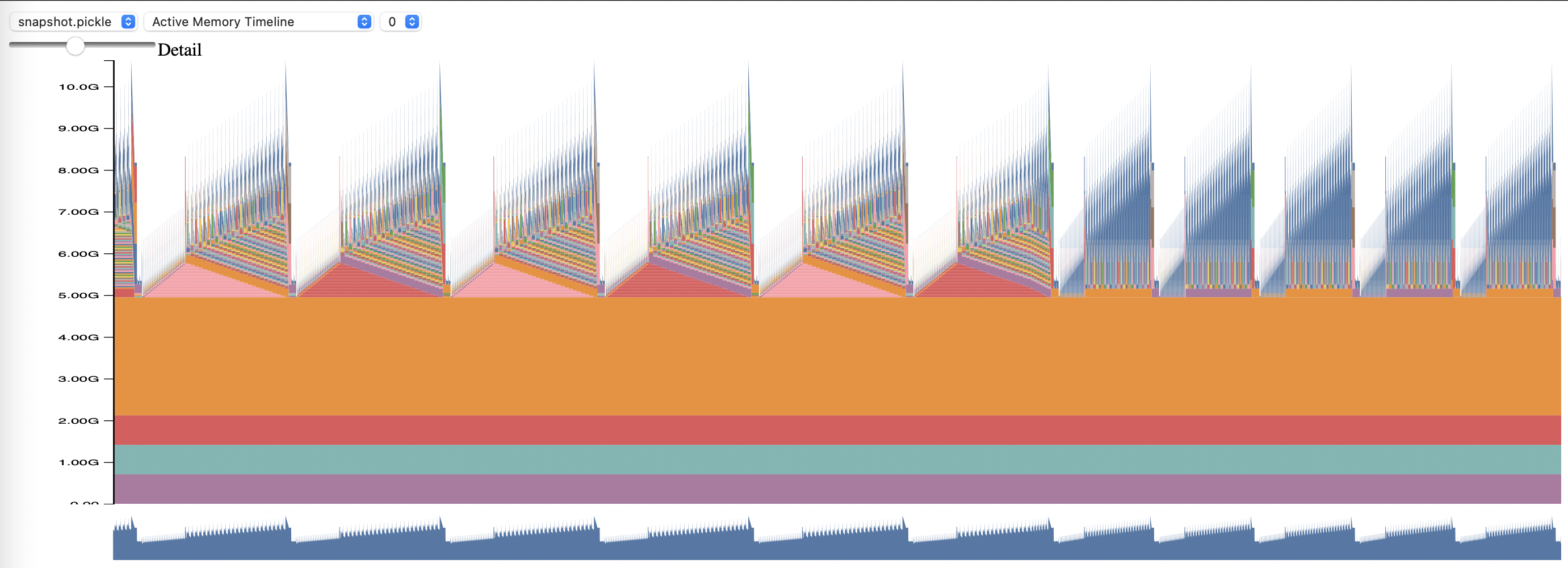
Zeigen Sie das generierte Profil mit dem Skript „memory_viz.py“ an. Laufen mit:
python _memory_viz.py trace_plot <generated_profile> -o trace.html
Die GPT-NeoX-Bibliothek wurde von akademischen und industriellen Forschern weitgehend übernommen und auf viele HPC-Systeme portiert.
Wenn Sie diese Bibliothek für Ihre Recherche als nützlich erachtet haben, wenden Sie sich bitte an uns und lassen Sie es uns wissen! Wir würden Sie gerne in unsere Listen aufnehmen.
EleutherAI und unsere Mitarbeiter haben es in den folgenden Veröffentlichungen verwendet:
Folgende Publikationen anderer Forschungsgruppen nutzen diese Bibliothek:


