TaskMatrix
1.0.0
TaskMatrix verbindet ChatGPT und eine Reihe von Visual Foundation-Modellen, um das Senden und Empfangen von Bildern während des Chats zu ermöglichen.
Sehen Sie sich unseren Artikel an: Visual ChatGPT: Sprechen, Zeichnen und Bearbeiten mit Visual Foundation Models
Jetzt unterstützt TaskMatrix GroundingDINO und segmentiert alles! Danke @jordddan für seine Bemühungen. Für den Fall der Bildbearbeitung wird GroundingDINO zunächst verwendet, um Begrenzungsrahmen zu lokalisieren, die durch einen bestimmten Text geführt werden. Dann wird segment-anything verwendet, um die zugehörige Maske zu generieren, und schließlich wird stabiles Diffusions-Inpainting verwendet, um das Bild basierend auf der Maske zu bearbeiten.
python visual_chatgpt.py --load "Text2Box_cuda:0,Segmenting_cuda:0,Inpainting_cuda:0,ImageCaptioning_cuda:0"find xxx in the image oder segment xxx in the image . xxx ist ein Objekt. TaskMatrix gibt das Erkennungs- oder Segmentierungsergebnis zurück!Jetzt kann TaskMatrix Chinesisch unterstützen! Vielen Dank an @Wang-Xiaodong1899 für seine Bemühungen.
Wir schlagen die Vorlagenidee in TaskMatrix vor!
template_model = True hinzu Vielen Dank an @ShengmingYin und @thebestannie für die Bereitstellung eines Vorlagenbeispiels in der InfinityOutPainting -Klasse (siehe folgendes GIF).
python visual_chatgpt.py --load "Inpainting_cuda:0,ImageCaptioning_cuda:0,VisualQuestionAnswering_cuda:0" aus.extend the image to 2048x1024 für TaskMatrix!InfinityOutPainting Vorlage kann TaskMatrix Bilder durch Zusammenarbeit mit vorhandenen ImageCaptioning , Inpainting und VisualQuestionAnswering Grundmodellen nahtlos auf jede beliebige Größe erweitern, ohne dass zusätzliche Schulungen erforderlich sind .TaskMatrix braucht den Einsatz der Community! Wir freuen uns über Ihren Beitrag, um neue und interessante Funktionen hinzuzufügen!

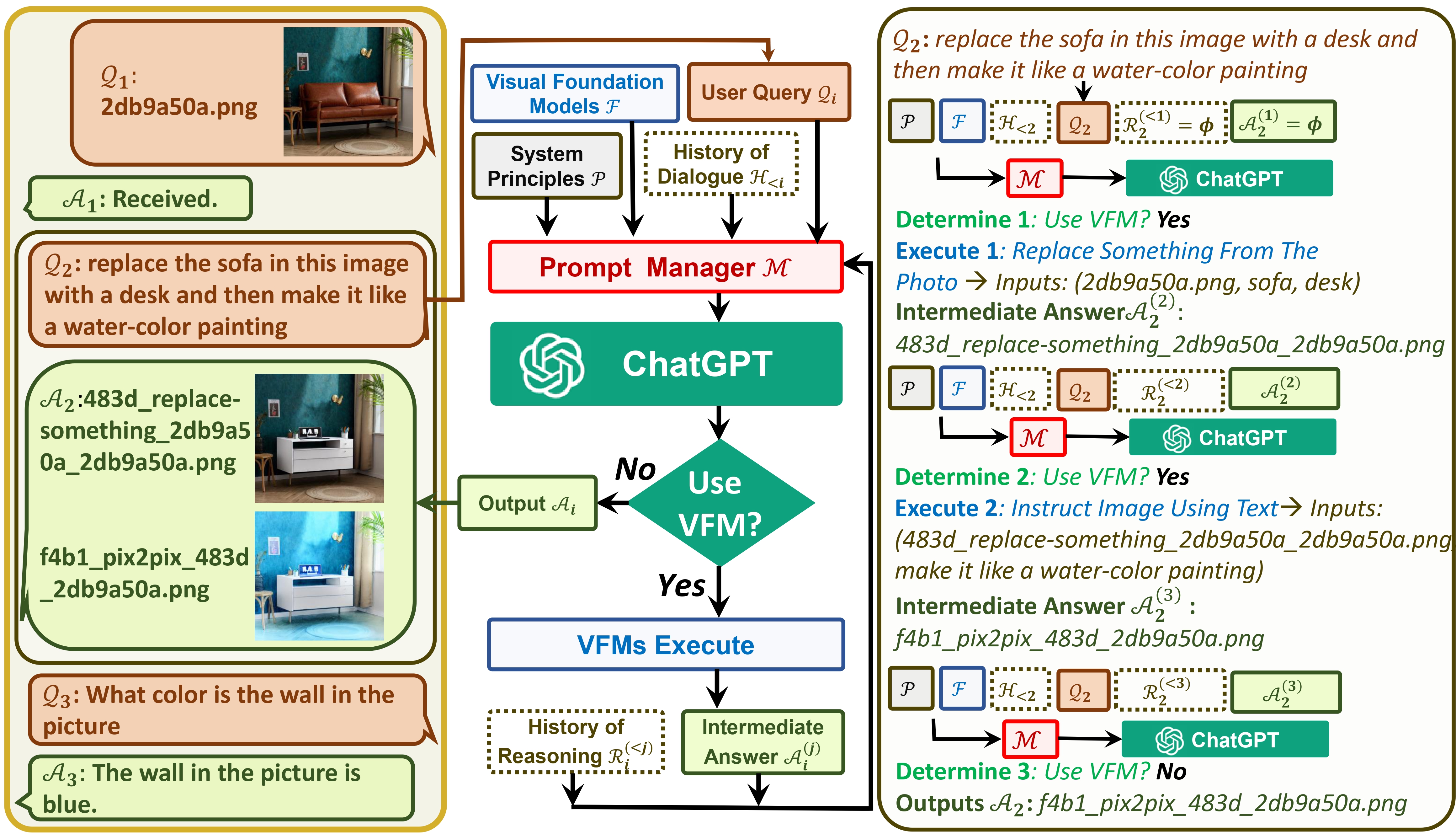
Einerseits dient ChatGPT (oder LLMs) als allgemeine Schnittstelle , die ein breites und vielfältiges Verständnis für ein breites Themenspektrum ermöglicht. Andererseits fungieren Foundation Models als Domänenexperten , indem sie fundiertes Wissen in bestimmten Domänen bereitstellen. Durch die Nutzung von allgemeinem und tiefem Wissen wollen wir eine KI aufbauen, die in der Lage ist, verschiedene Aufgaben zu bewältigen.
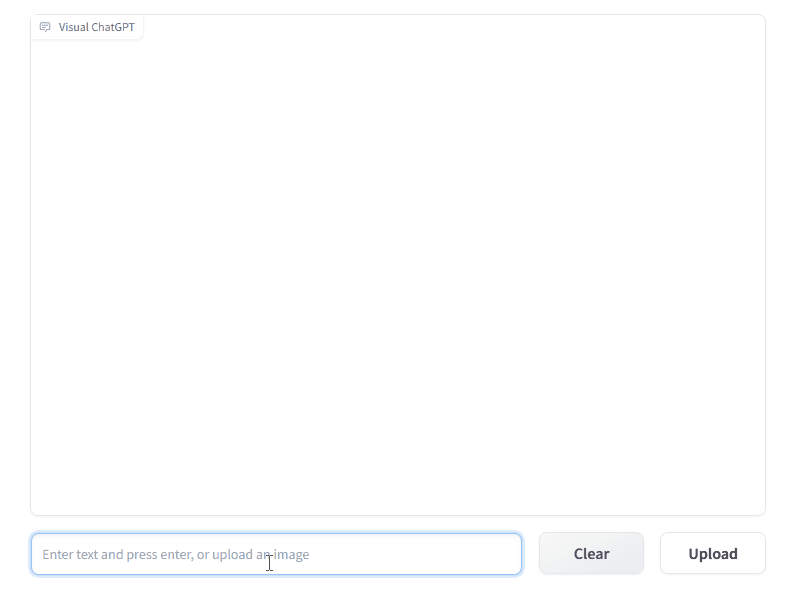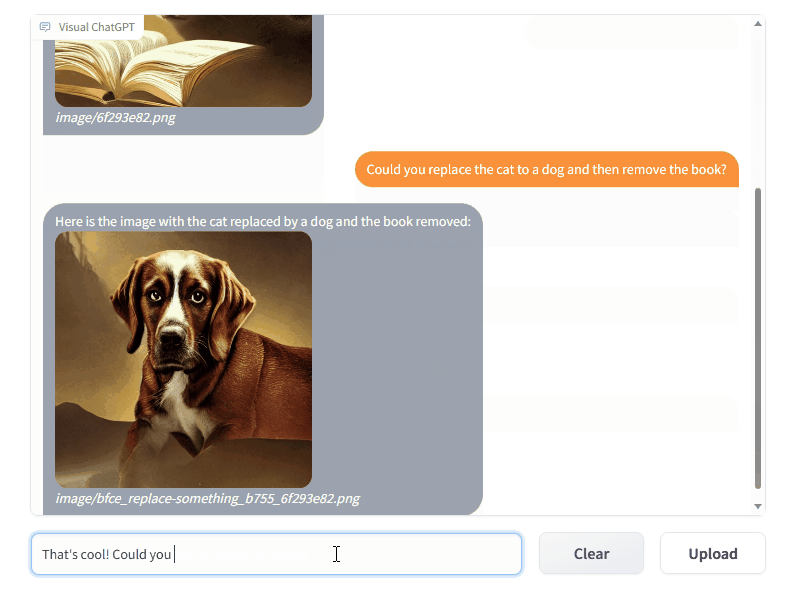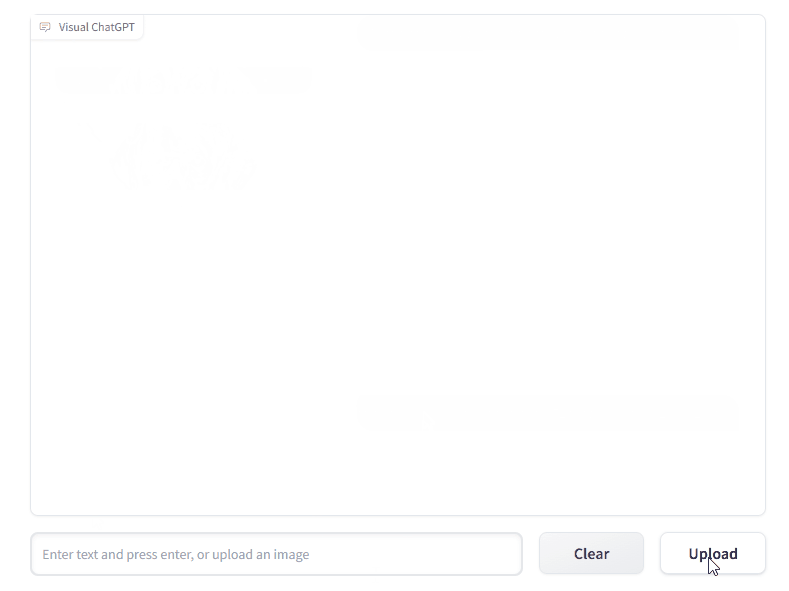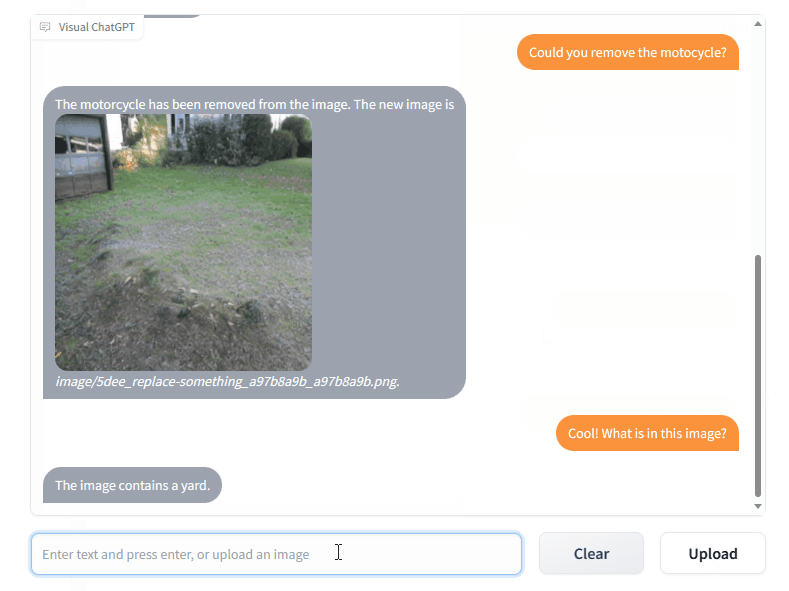
# clone the repo
git clone https://github.com/microsoft/TaskMatrix.git
# Go to directory
cd visual-chatgpt
# create a new environment
conda create -n visgpt python=3.8
# activate the new environment
conda activate visgpt
# prepare the basic environments
pip install -r requirements.txt
pip install git+https://github.com/IDEA-Research/GroundingDINO.git
pip install git+https://github.com/facebookresearch/segment-anything.git
# prepare your private OpenAI key (for Linux)
export OPENAI_API_KEY={Your_Private_Openai_Key}
# prepare your private OpenAI key (for Windows)
set OPENAI_API_KEY={Your_Private_Openai_Key}
# Start TaskMatrix !
# You can specify the GPU/CPU assignment by "--load", the parameter indicates which
# Visual Foundation Model to use and where it will be loaded to
# The model and device are separated by underline '_', the different models are separated by comma ','
# The available Visual Foundation Models can be found in the following table
# For example, if you want to load ImageCaptioning to cpu and Text2Image to cuda:0
# You can use: "ImageCaptioning_cpu,Text2Image_cuda:0"
# Advice for CPU Users
python visual_chatgpt.py --load ImageCaptioning_cpu,Text2Image_cpu
# Advice for 1 Tesla T4 15GB (Google Colab)
python visual_chatgpt.py --load "ImageCaptioning_cuda:0,Text2Image_cuda:0"
# Advice for 4 Tesla V100 32GB
python visual_chatgpt.py --load "Text2Box_cuda:0,Segmenting_cuda:0,
Inpainting_cuda:0,ImageCaptioning_cuda:0,
Text2Image_cuda:1,Image2Canny_cpu,CannyText2Image_cuda:1,
Image2Depth_cpu,DepthText2Image_cuda:1,VisualQuestionAnswering_cuda:2,
InstructPix2Pix_cuda:2,Image2Scribble_cpu,ScribbleText2Image_cuda:2,
SegText2Image_cuda:2,Image2Pose_cpu,PoseText2Image_cuda:2,
Image2Hed_cpu,HedText2Image_cuda:3,Image2Normal_cpu,
NormalText2Image_cuda:3,Image2Line_cpu,LineText2Image_cuda:3"
Hier listen wir die GPU-Speichernutzung jedes Visual Foundation-Modells auf. Sie können angeben, welches Ihnen gefällt:
| Stiftungsmodell | GPU-Speicher (MB) |
|---|---|
| Bildbearbeitung | 3981 |
| InstructPix2Pix | 2827 |
| Text2Image | 3385 |
| Bildunterschrift | 1209 |
| Image2Canny | 0 |
| CannyText2Image | 3531 |
| Bild2Linie | 0 |
| LineText2Image | 3529 |
| Image2Hed | 0 |
| HedText2Image | 3529 |
| Image2Scribble | 0 |
| ScribbleText2Image | 3531 |
| Image2Pose | 0 |
| PoseText2Image | 3529 |
| Bild2Seg | 919 |
| SegText2Image | 3529 |
| Bild2Tiefe | 0 |
| DepthText2Image | 3531 |
| Bild2Normal | 0 |
| NormalText2Image | 3529 |
| VisuelleFrageAntworten | 1495 |
Wir schätzen die Open Source der folgenden Projekte:
Hugging Face LangChain Stable Diffusion ControlNet InstructPix2Pix CLIPSeg BLIP
Wenn Sie Hilfe oder Probleme mit der TaskMatrix benötigen, senden Sie bitte ein GitHub-Problem.
Für weitere Mitteilungen wenden Sie sich bitte an Chenfei WU ([email protected]) oder Nan DUAN ([email protected]).
Marken Dieses Projekt kann Marken oder Logos für Projekte, Produkte oder Dienstleistungen enthalten. Die autorisierte Nutzung von Microsoft-Marken oder -Logos unterliegt den Marken- und Markenrichtlinien von Microsoft und muss diesen entsprechen. Die Verwendung von Microsoft-Marken oder -Logos in geänderten Versionen dieses Projekts darf keine Verwirrung stiften oder eine Sponsorschaft durch Microsoft implizieren. Jegliche Verwendung von Marken oder Logos Dritter unterliegt den Richtlinien dieser Drittanbieter.
Die empfohlenen Modelle in diesem Repo sind nur Beispiele, die für wissenschaftliche Forschungen verwendet werden, die das Konzept der Aufgabenautomatisierung und des Benchmarkings mit dem unter Visual ChatGPT veröffentlichten Artikel untersuchen: Talking, Drawing and Editing with Visual Foundation Models. Benutzer können die Modelle in diesem Repo entsprechend ihrem Forschungsbedarf ersetzen. Wenn Sie die empfohlenen Modelle in diesem Repo verwenden, müssen Sie die jeweiligen Lizenzen dieser Modelle einhalten. Microsoft übernimmt keine Haftung für etwaige Verletzungen von Rechten Dritter, die sich aus Ihrer Nutzung dieses Repos ergeben. Benutzer erklären sich damit einverstanden, Microsoft von sämtlichen Schäden, Kosten und Anwaltsgebühren im Zusammenhang mit Ansprüchen aus diesem Repo freizustellen und schadlos zu halten. Wenn jemand der Meinung ist, dass dieses Repo Ihre Rechte verletzt, benachrichtigen Sie bitte die E-Mail-Adresse des Projektinhabers.


