visual chatgpt
1.0.0
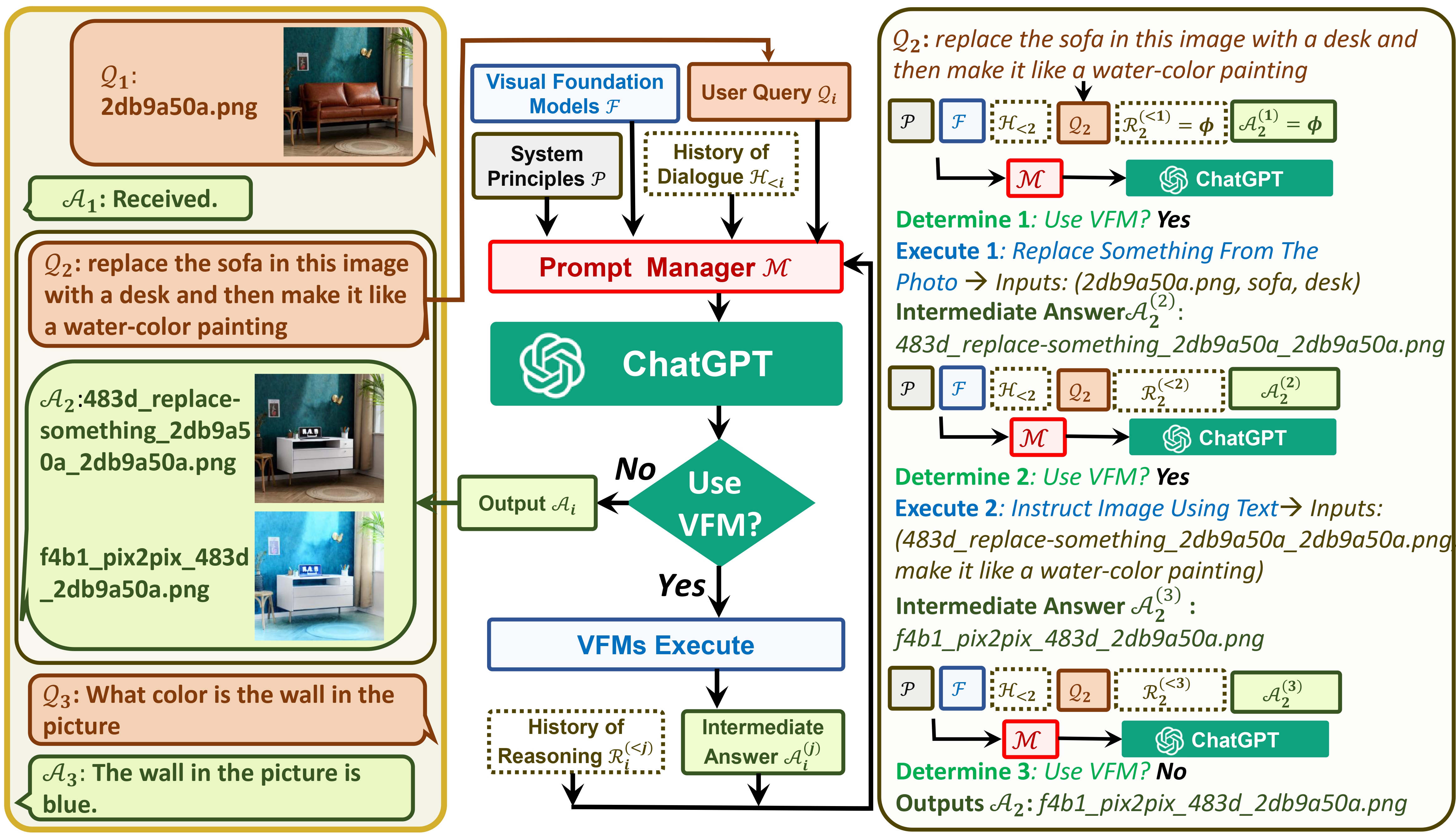
Visual ChatGPT verbindet ChatGPT und eine Reihe von Visual Foundation-Modellen, um das Senden und Empfangen von Bildern während des Chats zu ermöglichen.
Sehen Sie sich unseren Artikel an: Visual ChatGPT: Sprechen, Zeichnen und Bearbeiten mit Visual Foundation Models
Einerseits dient ChatGPT (oder LLMs) als allgemeine Schnittstelle , die ein breites und vielfältiges Verständnis für ein breites Themenspektrum ermöglicht. Andererseits fungieren Foundation Models als Domänenexperten , indem sie fundiertes Wissen in bestimmten Domänen bereitstellen. Durch die Nutzung von allgemeinem und tiefem Wissen wollen wir eine KI aufbauen, die in der Lage ist, eine Vielzahl von Aufgaben zu bewältigen.

# clone the repo
git clone https://github.com/microsoft/visual-chatgpt.git
# Go to directory
cd visual-chatgpt
# create a new environment
conda create -n visgpt python=3.8
# activate the new environment
conda activate visgpt
# prepare the basic environments
pip install -r requirements.txt
# prepare your private OpenAI key (for Linux)
export OPENAI_API_KEY={Your_Private_Openai_Key}
# prepare your private OpenAI key (for Windows)
set OPENAI_API_KEY={Your_Private_Openai_Key}
# Start Visual ChatGPT !
# You can specify the GPU/CPU assignment by "--load", the parameter indicates which
# Visual Foundation Model to use and where it will be loaded to
# The model and device are sperated by underline '_', the different models are seperated by comma ','
# The available Visual Foundation Models can be found in the following table
# For example, if you want to load ImageCaptioning to cpu and Text2Image to cuda:0
# You can use: "ImageCaptioning_cpu,Text2Image_cuda:0"
# Advice for CPU Users
python visual_chatgpt.py --load ImageCaptioning_cpu,Text2Image_cpu
# Advice for 1 Tesla T4 15GB (Google Colab)
python visual_chatgpt.py --load "ImageCaptioning_cuda:0,Text2Image_cuda:0"
# Advice for 4 Tesla V100 32GB
python visual_chatgpt.py --load "ImageCaptioning_cuda:0,ImageEditing_cuda:0,
Text2Image_cuda:1,Image2Canny_cpu,CannyText2Image_cuda:1,
Image2Depth_cpu,DepthText2Image_cuda:1,VisualQuestionAnswering_cuda:2,
InstructPix2Pix_cuda:2,Image2Scribble_cpu,ScribbleText2Image_cuda:2,
Image2Seg_cpu,SegText2Image_cuda:2,Image2Pose_cpu,PoseText2Image_cuda:2,
Image2Hed_cpu,HedText2Image_cuda:3,Image2Normal_cpu,
NormalText2Image_cuda:3,Image2Line_cpu,LineText2Image_cuda:3"
Hier listen wir die GPU-Speichernutzung jedes Visual Foundation-Modells auf. Sie können angeben, welches Ihnen gefällt:
| Stiftungsmodell | GPU-Speicher (MB) |
|---|---|
| Bildbearbeitung | 3981 |
| InstructPix2Pix | 2827 |
| Text2Image | 3385 |
| Bildunterschrift | 1209 |
| Image2Canny | 0 |
| CannyText2Image | 3531 |
| Bild2Linie | 0 |
| LineText2Image | 3529 |
| Image2Hed | 0 |
| HedText2Image | 3529 |
| Image2Scribble | 0 |
| ScribbleText2Image | 3531 |
| Image2Pose | 0 |
| PoseText2Image | 3529 |
| Bild2Seg | 919 |
| SegText2Image | 3529 |
| Bild2Tiefe | 0 |
| DepthText2Image | 3531 |
| Bild2Normal | 0 |
| NormalText2Image | 3529 |
| VisuelleFrageAntworten | 1495 |
Wir schätzen die Open Source der folgenden Projekte:
Hugging Face LangChain Stable Diffusion ControlNet InstructPix2Pix CLIPSeg BLIP
Wenn Sie Hilfe oder Probleme bei der Verwendung von Visual ChatGPT benötigen, senden Sie bitte ein GitHub-Problem.
Für weitere Mitteilungen wenden Sie sich bitte an Chenfei WU ([email protected]) oder Nan DUAN ([email protected]).


