TEMPO
1.0.0

Der offizielle Code für [„TEMPO: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting (ICLR 2024)“].
TEMPO ist eines der allerersten Open-Source -Time Series Foundation-Modelle für die Prognoseaufgabe Version 1.0.
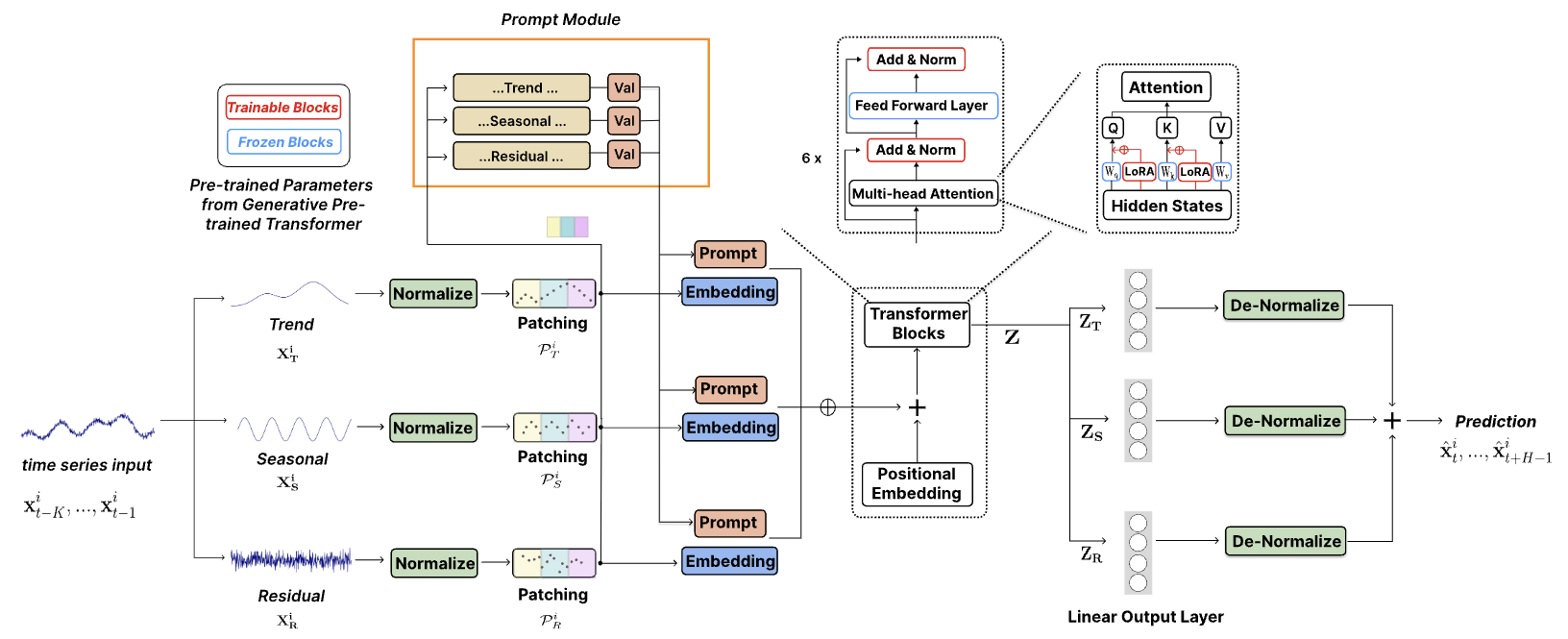
Okt. 2024 : Wir haben unsere Codestruktur optimiert, sodass Benutzer das vorab trainierte Modell herunterladen und Zero-Shot-Inferenz mit einer einzigen Codezeile durchführen können! Weitere Informationen finden Sie in unserer Demo. Die Download-Zählung unseres Models auf HuggingFace ist jetzt nachverfolgbar!
Juni 2024 : Wir haben Demos zur Reproduktion von Zero-Shot-Experimenten in Colab hinzugefügt. Wir haben auch die Demo zum Erstellen des Kundendatensatzes hinzugefügt und führen die Inferenz direkt über unser vorab trainiertes Basismodell durch: Colab
Mai 2024 : TEMPO hat eine GUI-basierte Online-Demo gestartet, die es Benutzern ermöglicht, direkt mit unserem Stiftungsmodell zu interagieren!
Mai 2024 : TEMPO veröffentlicht das vorab trainierte 80M-Fundamentmodell in HuggingFace!
Mai 2024 : ? Wir haben den Code für Vortrainings- und Inferenz-TEMPO-Modelle hinzugefügt. In diesem Ordner finden Sie eine Skript-Demo vor dem Training. Wir haben auch ein Skript für die Inferenz-Demo hinzugefügt.
März 2024 : ? Veröffentlichter TETS-Datensatz von S&P 500, der in multimodalen Experimenten in TEMPO verwendet wird.
März 2024 : ? TEMPO hat den Projektcode und den vorab trainierten Checkpoint online veröffentlicht!
Januar 2024 : TEMPO-Beitrag wird vom ICLR angenommen!
Okt. 2023 : TEMPO-Artikel auf Arxiv veröffentlicht!
conda create -n tempo python=3.8
conda activate tempo
pip install -r requirements.txt
Ein Optimierungsbeispiel, das zeigt, wie Prognosen mit TEMPO durchgeführt werden:
# Third-party library imports
import numpy as np
import torch
from numpy . random import choice
# Local imports
from models . TEMPO import TEMPO
model = TEMPO . load_pretrained_model (
device = torch . device ( 'cuda:0' if torch . cuda . is_available () else 'cpu' ),
repo_id = "Melady/TEMPO" ,
filename = "TEMPO-80M_v1.pth" ,
cache_dir = "./checkpoints/TEMPO_checkpoints"
)
input_data = np . random . rand ( 336 ) # Random input data
with torch . no_grad ():
predicted_values = model . predict ( input_data , pred_length = 96 )
print ( "Predicted values:" )
print ( predicted_values )Bitte versuchen Sie, die Zero-Shot-Experimente auf ETTh2 [hier auf Colab] zu reproduzieren.
Wir verwenden die folgende Colab-Seite, um die Demo zum Erstellen des Kundendatensatzes zu zeigen und die Schlussfolgerung direkt über unser vorab trainiertes Basismodell zu ziehen: [Colab]
Bitte probieren Sie unsere Fundamentmodell-Demo [hier] aus.
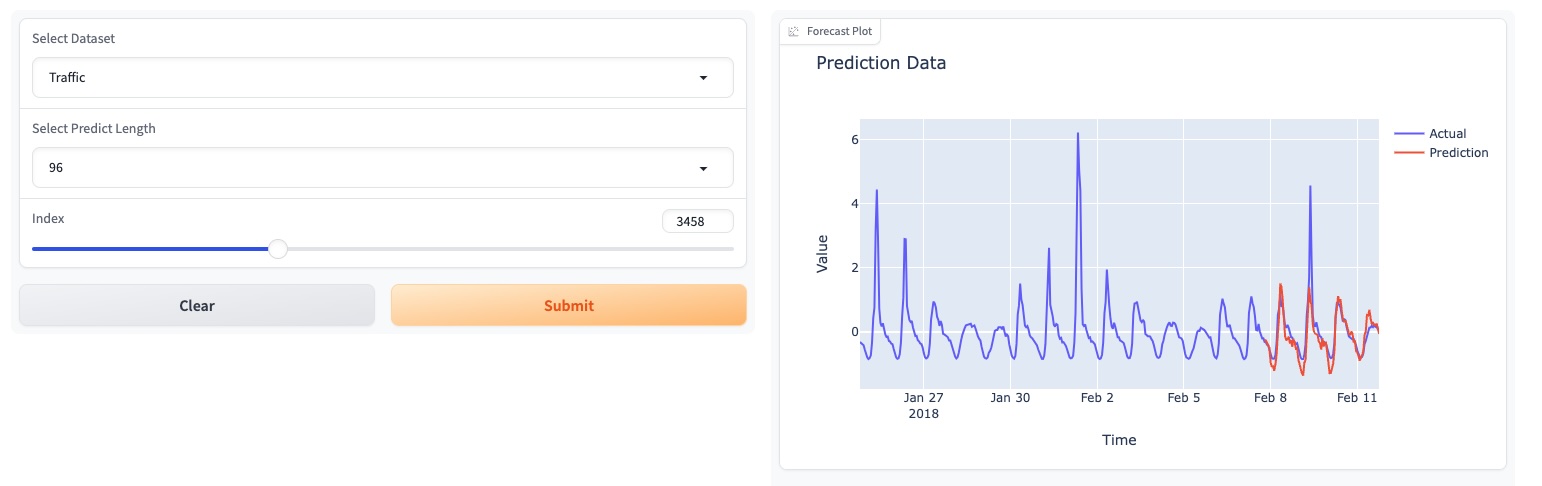
Wir haben auch unsere Modelle auf HuggingFace aktualisiert: [Melady/TEMPO].
Laden Sie die Daten von [Google Drive] oder [Baidu Drive] herunter und legen Sie die heruntergeladenen Daten im Ordner ./dataset ab. Sie können die STL-Ergebnisse auch von [Google Drive] herunterladen und die heruntergeladenen Daten im Ordner ./stl ablegen.
bash [ecl, etth1, etth2, ettm1, ettm2, traffic, weather].sh
Nach dem Training können wir das TEMPO-Modell unter der Nullschusseinstellung testen:
bash [ecl, etth1, etth2, ettm1, ettm2, traffic, weather]_test.sh
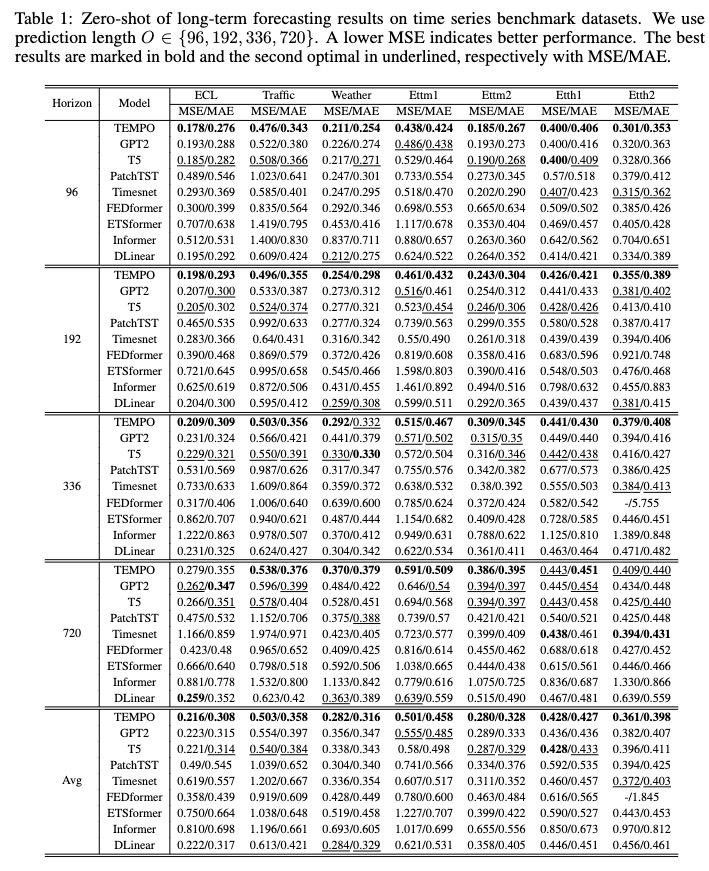
Sie können das vorab trainierte Modell von [Google Drive] herunterladen und dann zum Spaß das Testskript ausführen.
Hier sind die Eingabeaufforderungen, die zum Generieren der entsprechenden Textinformationen von Zeitreihen über [OPENAI ChatGPT-3.5 API] verwendet werden.

Die Zeitreihendaten stammen von [S&P 500]. Hier ist der EBITDA-Fall für ein Unternehmen aus dem Datensatz:
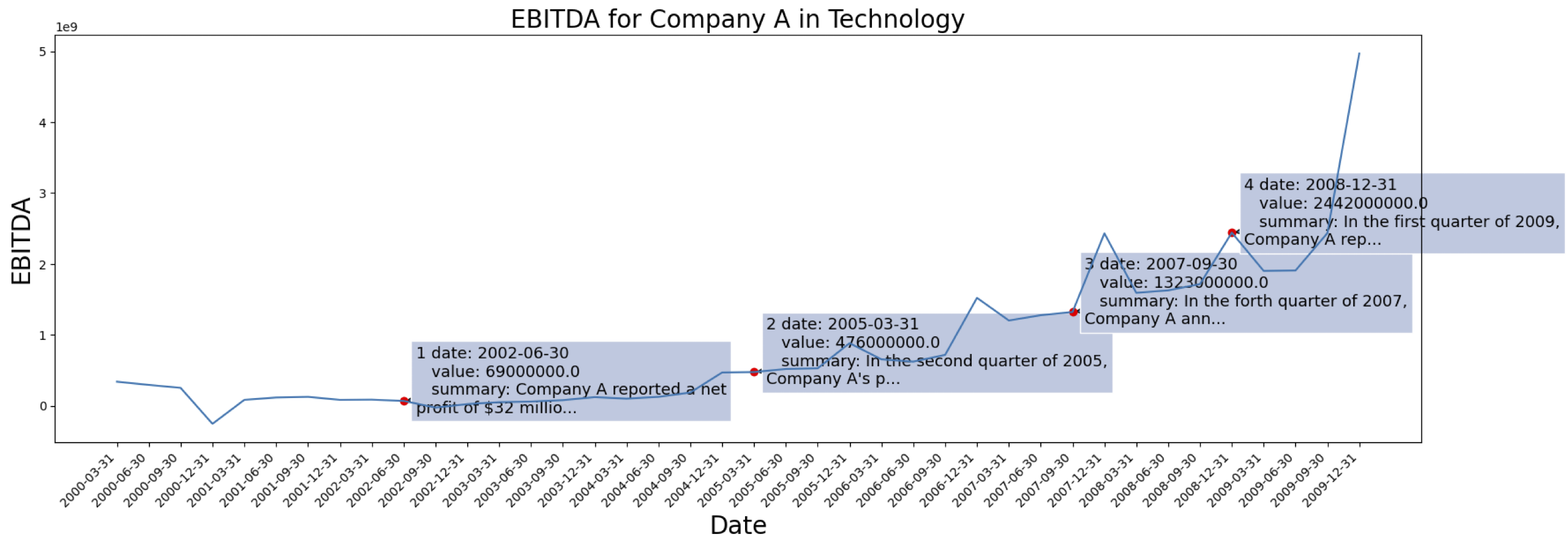
Beispiel für generierte Kontextinformationen für das oben markierte Unternehmen:
Sie können die verarbeiteten Daten mit Texteinbettung von GPT2 herunterladen unter: [TETS].
Wenn Sie daran interessiert sind, TEMPO auf Ihre reale Anwendung anzuwenden, können Sie sich gerne an [email protected] / [email protected] wenden.
@inproceedings{
cao2024tempo,
title={{TEMPO}: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting},
author={Defu Cao and Furong Jia and Sercan O Arik and Tomas Pfister and Yixiang Zheng and Wen Ye and Yan Liu},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=YH5w12OUuU}
}
@article{
Jia_Wang_Zheng_Cao_Liu_2024,
title={GPT4MTS: Prompt-based Large Language Model for Multimodal Time-series Forecasting},
volume={38},
url={https://ojs.aaai.org/index.php/AAAI/article/view/30383},
DOI={10.1609/aaai.v38i21.30383},
number={21},
journal={Proceedings of the AAAI Conference on Artificial Intelligence},
author={Jia, Furong and Wang, Kevin and Zheng, Yixiang and Cao, Defu and Liu, Yan},
year={2024}, month={Mar.}, pages={23343-23351}
}


