Awesome Attention Heads
vey on LLM attention heads
Wichtig
Über dieses Repo. Dies ist eine Plattform, um die neuesten Forschungsergebnisse zu verschiedenen Arten von LLM-Aufmerksamkeitsköpfen zu erhalten. Außerdem haben wir eine Umfrage zu diesen fantastischen Werken veröffentlicht.
Wenn Sie unsere Arbeit zitieren möchten, finden Sie hier unseren Bibtex-Eintrag: CITATION.bib.
Wenn Sie nur die entsprechende Papierliste sehen möchten, springen Sie bitte direkt hierher.
Wenn Sie zu diesem Repo beitragen möchten, lesen Sie hier.
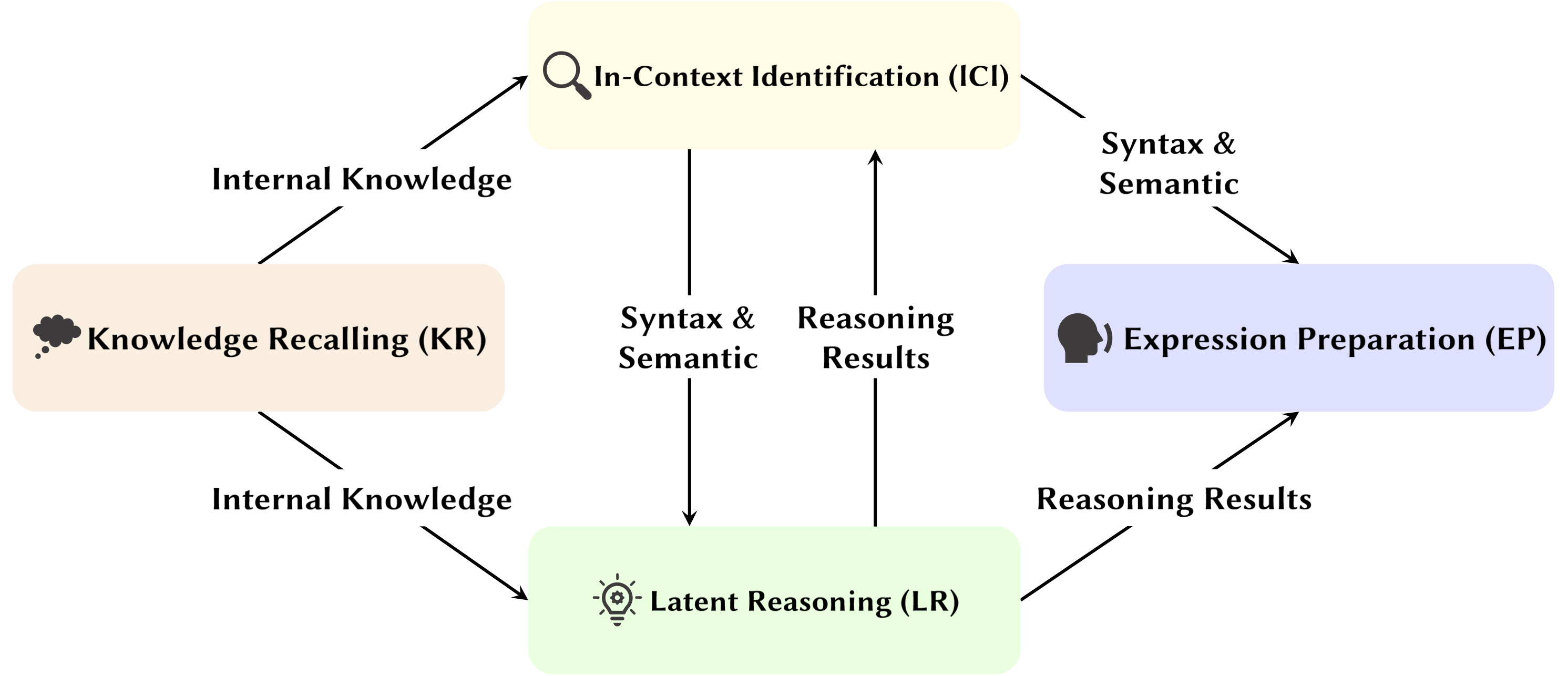
Mit der Entwicklung von Large Language Models (LLMs) wird ihre zugrunde liegende Netzwerkstruktur, der Transformer, eingehend untersucht. Die Erforschung der Transformer-Struktur hilft uns, unser Verständnis dieser „Black Box“ zu verbessern und die Interpretierbarkeit des Modells zu verbessern. In jüngster Zeit gibt es immer mehr Arbeiten, die darauf hindeuten, dass das Modell zwei unterschiedliche Partitionen enthält: Aufmerksamkeitsmechanismen, die für Verhalten, Schlussfolgerung und Analyse verwendet werden, und Feed-Forward-Netzwerke (FFN) zur Wissensspeicherung. Ersteres ist entscheidend für die Offenlegung der funktionalen Fähigkeiten des Modells und führte zu einer Reihe von Studien, die verschiedene Funktionen innerhalb von Aufmerksamkeitsmechanismen untersuchen, die wir Attention Head Mining genannt haben.
In dieser Umfrage befassen wir uns mit den möglichen Mechanismen, wie Aufmerksamkeitsköpfe in LLMs zum Denkprozess beitragen.
Höhepunkte:
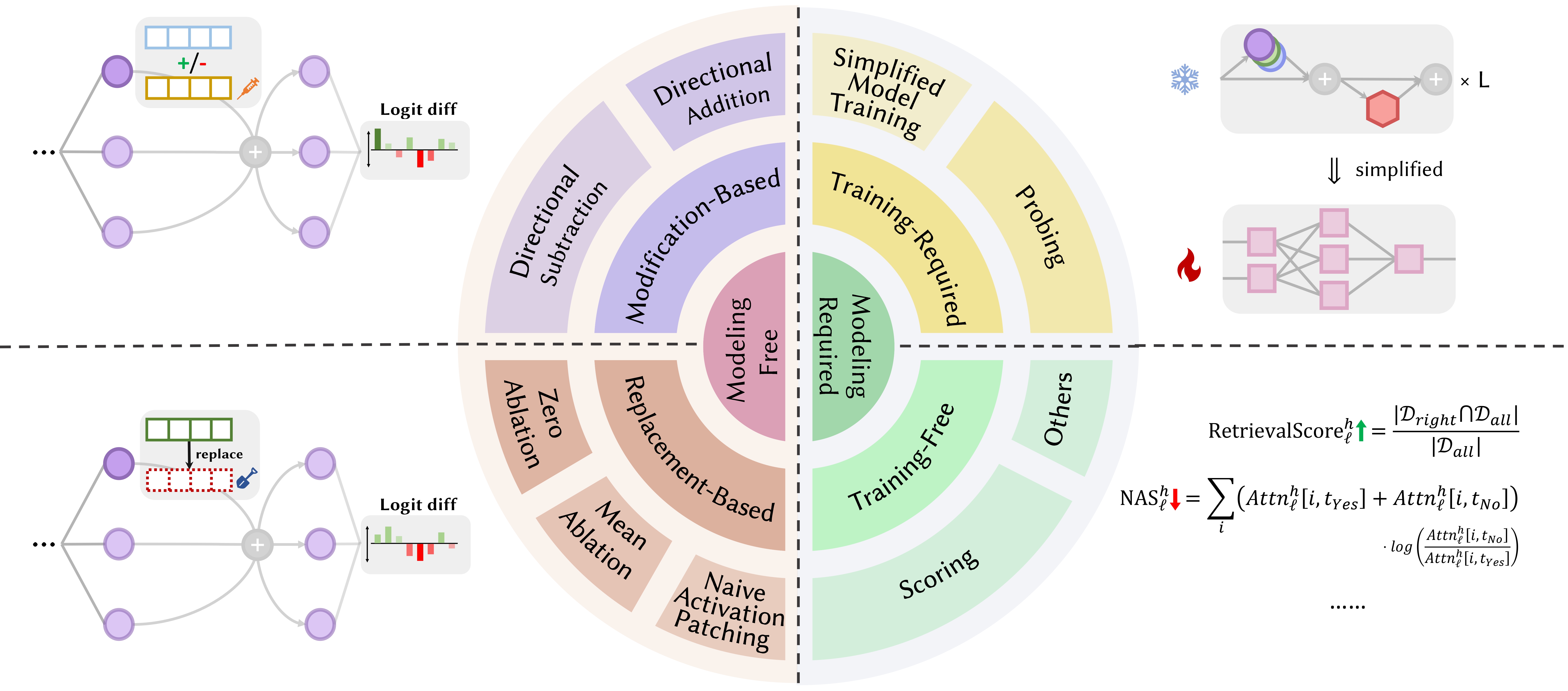
Die folgenden Beiträge sind nach Veröffentlichungsdatum sortiert:
Jahr 2024
| Datum | Papier & Zusammenfassung | Schlagworte | Links |
| 15.11.2024 | SEEKR: Selektive aufmerksamkeitsgesteuerte Wissensspeicherung für kontinuierliches Lernen großer Sprachmodelle | ||
| • Schlägt SEEKR vor, eine selektive, aufmerksamkeitsgesteuerte Methode zur Wissenserhaltung für kontinuierliches Lernen in LLMs, die sich auf wichtige Aufmerksamkeitsköpfe für eine effiziente Destillation konzentriert. • Bewertet anhand der kontinuierlichen Lern-Benchmarks TRACE und SuperNI. • SEEKR erzielte im Vergleich zu anderen Methoden eine vergleichbare oder bessere Leistung mit nur 1 % der Wiedergabedaten. | |||
| 06.11.2024 | Wie Transformatoren Aussagenlogikprobleme lösen: Eine mechanistische Analyse | ||
| • Identifiziert spezifische Aufmerksamkeitsschaltkreise in Transformatoren, die Probleme der Aussagenlogik lösen, wobei der Schwerpunkt auf „Planungs-“ und „Begründungs“-Mechanismen liegt. • Analysierte kleine Transformatoren und Mistral-7B und nutzte Aktivierungs-Patching, um Argumentationswege aufzudecken. • Habe ausgeprägte Aufmerksamkeitsköpfe gefunden, die sich auf die Lokalisierung von Regeln, die Verarbeitung von Fakten und die Entscheidungsfindung im logischen Denken spezialisiert haben. | |||
| 01.11.2024 | Attention Tracker: Erkennen von Prompt-Injection-Angriffen in LLMs | ||
| • Vorgeschlagener Attention Tracker, ein einfacher, aber effektiver, trainingsfreier Schutz, der sofortige Injektionsangriffe auf der Grundlage identifizierter wichtiger Köpfe erkennt. • Identifizierte die wichtigen Köpfe mit lediglich einem kleinen Satz LLM-generierter Zufallssätze in Kombination mit einem naiven Ignorierangriff. • Attention Tracker ist sowohl bei kleinen als auch bei großen LMs effektiv und beseitigt eine erhebliche Einschränkung früherer lernfreier Erkennungsmethoden. | |||
| 28.10.2024 | Arithmetik ohne Algorithmen: Sprachmodelle lösen Mathematik mit einer Menge Heuristiken | ||
| • Identifizierte eine Teilmenge des Modells (eine Schaltung), die den größten Teil des Verhaltens des Modells für die grundlegende arithmetische Logik erklärt, und untersuchte seine Funktionalität. • Analysierte Aufmerksamkeitsmuster mithilfe von arithmetischen Eingabeaufforderungen mit zwei Operanden, arabischen Ziffern und den vier Grundoperatoren (+, −, ×, ÷). • Für Addition, Subtraktion und Division ergeben 6 Aufmerksamkeitsköpfe eine hohe Genauigkeit (97 % im Durchschnitt), während bei der Multiplikation 20 Köpfe erforderlich sind, um eine Genauigkeit von über 90 % zu erreichen. | |||
| 21.10.2024 | Eine psycholinguistische Bewertung der Sensitivität von Sprachmodellen gegenüber Argumentrollen | ||
| • Beobachteter Probandenkopf in einer allgemeineren Umgebung. • Analysierte Aufmerksamkeitsmuster unter der Bedingung von Swap-Argumenten und Replacement-Argumenten. • Obwohl Modelle in der Lage sind, Rollen zu unterscheiden, kann es für Modelle schwierig sein, Argumentrolleninformationen korrekt zu verwenden, da das Problem darin liegt, wie diese Informationen in Verbdarstellungen kodiert werden, was zu einer schwächeren Rollensensitivität führt. | |||
| 17.10.2024 | Aktiv-ruhende Aufmerksamkeitsköpfe: Extreme-Token-Phänomene in LLMs mechanistisch entmystifizieren | ||
| • Es wurde gezeigt, dass extreme Token-Phänomene aus einem aktiv-ruhenden Mechanismus in den Aufmerksamkeitsköpfen entstehen, gekoppelt mit einem gegenseitigen Verstärkungsmechanismus während des Vortrainings. • Verwendung einfacher Transformatoren, die auf die Bigram-Backcopy (BB)-Aufgabe trainiert wurden, um extreme Token-Phänomene zu analysieren und sie auf vorab trainierte LLMs auszuweiten. • Viele der statischen und dynamischen Eigenschaften extremer Token-Phänomene, die von der BB-Aufgabe vorhergesagt werden, stimmen mit Beobachtungen in vorab trainierten LLMs überein. | |||
| 17.10.2024 | Zur Rolle von Aufmerksamkeitsköpfen bei der Sicherheit großer Sprachmodelle | ||
| • schlug eine neuartige Metrik vor, die auf die Aufmerksamkeit mehrerer Köpfe zugeschnitten ist, den Safety Head ImPortant Score (Schiffe), um den Beitrag der einzelnen Köpfe zur Modellsicherheit zu bewerten. • Durchführung von Analysen zur Funktionalität dieser Sicherheitswarnköpfe und Untersuchung ihrer Eigenschaften und Mechanismen. • Bestimmte Aufmerksamkeitsköpfe sind für die Sicherheit von entscheidender Bedeutung. Sicherheitsköpfe überschneiden sich bei fein abgestimmten Modellen, und die Entfernung dieser Köpfe hat nur minimale Auswirkungen auf die Hilfsbereitschaft. | |||
| 14.10.2024 | DuoAttention: Effiziente Long-Context-LLM-Inferenz mit Retrieval- und Streaming-Heads | ||
| • Einführung von DuoAttention, einem Framework, das sowohl die Decodierung als auch das Vorfüllen des Speichers und die Latenz von LLM reduziert, ohne seine Langkontextfähigkeiten zu beeinträchtigen, basierend auf der Entdeckung von Retrieval Heads und Streaming Heads innerhalb von LLM. • Testen Sie die Auswirkungen des Frameworks auf die LLM-Leistung sowohl bei Kurzkontext- als auch bei Langkontextaufgaben sowie auf seine Inferenzeffizienz. • Durch die Anwendung eines vollständigen KV-Cache nur auf Abrufköpfe reduziert DuoAttention die Speichernutzung und Latenz sowohl für die Dekodierung als auch für das Vorabfüllen in Anwendungen mit langem Kontext erheblich. | |||
| 14.10.2024 | Sperrung der Sicherheit der fein abgestimmten LLMs | ||
| • Einführung von SafetyLock, einer neuartigen und effizienten Methode zur Aufrechterhaltung der Sicherheit fein abgestimmter großer Sprachmodelle über verschiedene Risikostufen und Angriffsszenarien hinweg, basierend auf der Entdeckung von Safety Heads innerhalb von LLM. • Bewerten Sie die Wirksamkeit des SafetyLock bei der Verbesserung der Modellsicherheit und Inferenzeffizienz. • Durch die Anwendung von Interventionsvektoren auf Sicherheitsköpfe kann SafetyLock die internen Aktivierungen des Modells während der Inferenz in Richtung Harmlosigkeit modifizieren und so eine präzise Sicherheitsausrichtung mit minimalen Auswirkungen auf die Reaktion erreichen. | |||
| 11.10.2024 | Das Gleiche, aber unterschiedlich: Strukturelle Ähnlichkeiten und Unterschiede in der mehrsprachigen Sprachmodellierung | ||
| • Führte eine eingehende Untersuchung der spezifischen Komponenten durch, auf die mehrsprachige Modelle bei der Ausführung von Aufgaben angewiesen sind, die sprachspezifische morphologische Prozesse erfordern. • Untersuchen Sie die funktionalen Unterschiede interner Modellkomponenten bei der Ausführung von Aufgaben auf Englisch und Chinesisch. • Der Kopierkopf weist in beiden Sprachen eine ähnlich hohe Aktivierungshäufigkeit auf, während der Präteritumskopf im Englischen nur häufig aktiviert wird. | |||
| 08.10.2024 | Rund und rund geht's los! Was macht rotierende Positionskodierungen nützlich? | ||
| • Bereitstellung einer eingehenden Analyse der Interna eines trainierten Gemma 7B-Modells, um zu verstehen, wie RoPE auf mechanischer Ebene verwendet wird. • Die Verwendung unterschiedlicher Frequenzen in den Abfragen und Schlüsseln verstanden. • Es wurde festgestellt, dass die höchsten Frequenzen in RoPE von Gemma 7B geschickt genutzt werden, um spezielle „positionelle“ Aufmerksamkeitsköpfe (Diagonalköpfe, Kopf mit vorherigem Token) zu konstruieren, während die niedrigen Frequenzen vom Apostrophe-Kopf verwendet werden. | |||
| 06.10.2024 | Überarbeitung der kontextbezogenen Lerninferenzschaltung in großen Sprachmodellen | ||
| • Vorschlag einer umfassenden dreistufigen Inferenzschaltung zur Charakterisierung des Inferenzprozesses von ICL. • Unterteilen Sie ICL in drei Phasen: Zusammenfassen, Zusammenführen der Semantik sowie Abrufen und Kopieren von Merkmalen. Analysieren Sie dabei die Rolle, die jede Phase in ICL spielt, und ihren Betriebsmechanismus. • Es wurde festgestellt, dass Vorläufer-Token-Köpfe vor den Induktionsköpfen zunächst die Demonstrationstextdarstellungen vom Vorläufer-Token mit ihren entsprechenden Etiketten-Tokens zusammenführen, selektiv basierend auf der Kompatibilität zwischen der Demonstrations- und Etikettensemantik. | |||
| 01.10.2024 | Sparse-Attention-Zerlegung, angewendet auf die Schaltungsverfolgung | ||
| • Einführung der Sparse Attention Decomposition unter Verwendung von SVD auf Aufmerksamkeitskopfmatrizen, um Kommunikationspfade in GPT-2-Modellen zu verfolgen. • Wird auf die Schaltungsverfolgung in GPT-2 Small für die Indirect Object Identification (IOI)-Aufgabe angewendet. • Identifiziert spärliche, funktionell bedeutsame Kommunikationssignale zwischen Aufmerksamkeitsköpfen und verbessert so die Interpretierbarkeit. | |||
| 09.09.2024 | Enthüllung von Induktionsköpfen: Nachweisbare Trainingsdynamik und Funktionslernen in Transformatoren | ||
| • Das Papier stellt einen verallgemeinerten Induktionskopfmechanismus vor und erklärt, wie Transformatorkomponenten zusammenarbeiten, um In-Context-Learning (ICL) an n-Gramm-Markov-Ketten durchzuführen. • Es analysiert einen Zwei-Aufmerksamkeitsschicht-Transformator mit Gradientenfluss, um Token in Markov-Ketten vorherzusagen. • Der Gradientenfluss konvergiert und ermöglicht ICL durch einen erlernten, funktionsbasierten Induktionskopfmechanismus. | |||
| 16.08.2024 | Eine mechanistische Interpretation des syllogistischen Denkens in autoregressiven Sprachmodellen | ||
| • Die Studie führt eine mechanistische Interpretation des syllogistischen Denkens in LMs ein und identifiziert inhaltsunabhängige Denkkreise. • Schaltkreisentdeckung zum Denken und Untersuchen von Glaubensverzerrungen in Aufmerksamkeitsköpfen. • Identifizierte einen notwendigen Denkkreislauf, der auf syllogistische Schemata übertragbar ist, jedoch anfällig für Kontaminationen durch vorab trainiertes Weltwissen ist. | |||
| 01.08.2024 | Verbesserung der semantischen Konsistenz großer Sprachmodelle durch Modellbearbeitung: Ein auf Interpretierbarkeit ausgerichteter Ansatz | ||
| • Führt einen kostengünstigen Modellbearbeitungsansatz ein, der sich auf Aufmerksamkeitsköpfe konzentriert, um die semantische Konsistenz in LLMs ohne umfangreiche Parameteränderungen zu verbessern. • Aufmerksamkeitsköpfe analysiert, Vorurteile eingefügt und anhand von NLU- und NLG-Datensätzen getestet. • Erzielte bemerkenswerte Verbesserungen der semantischen Konsistenz und Aufgabenleistung mit starker Verallgemeinerung über zusätzliche Aufgaben hinweg. | |||
| 31.07.2024 | Korrektur negativer Verzerrungen in großen Sprachmodellen durch Ausrichtung negativer Aufmerksamkeitswerte | ||
| • Einführung des Negative Attention Score (NAS) zur Quantifizierung und Korrektur negativer Verzerrungen in Sprachmodellen. • Identifizierte negativ voreingenommene Aufmerksamkeitsköpfe und schlug zur Feinabstimmung ein Negative Attention Score Alignment (NASA) vor. • Die NASA hat die Präzisions-Rückruf-Lücke effektiv reduziert und gleichzeitig die Generalisierung bei binären Entscheidungsaufgaben beibehalten. | |||
| 29.07.2024 | Erkennen und Verstehen von Schwachstellen in Sprachmodellen durch mechanistische Interpretierbarkeit | ||
| • Stellt eine Methode vor, die Mechanistic Interpretability (MI) nutzt, um Schwachstellen in LLMs, insbesondere gegnerische Angriffe, zu erkennen und zu verstehen. • Analysiert GPT-2 Small auf Schwachstellen bei der Vorhersage von Akronymen mit drei Buchstaben. • Identifiziert und erklärt erfolgreich spezifische Schwachstellen im Modell im Zusammenhang mit der Aufgabe. | |||
| 22.07.2024 | RazorAttention: Effiziente KV-Cache-Komprimierung durch Retrieval Heads | ||
| • Einführung von RazorAttention, einer schulungsfreien KV-Cache-Komprimierungstechnik, die Abrufköpfe und Kompensationstokens verwendet, um kritische Tokeninformationen zu bewahren. • Evaluierung von RazorAttention für große Sprachmodelle (LLMs) auf Effizienz. • Es wurde eine Reduzierung der KV-Cache-Größe um über 70 % ohne spürbare Leistungseinbußen erreicht. | |||
| 21.07.2024 | Antworten, zusammenbauen, Ass: Verstehen, wie Transformatoren Multiple-Choice-Fragen beantworten | ||
| • Das Papier führt Vokabularprojektion und Aktivierungspatching ein, um versteckte Zustände zu lokalisieren, die die richtigen MCQA-Antworten vorhersagen. • Identifizierte Hauptaufmerksamkeitsköpfe und Schichten, die für die Antwortauswahl in Transformatoren verantwortlich sind. • Aufmerksamkeitsköpfe der mittleren Schicht sind für eine genaue Antwortvorhersage von entscheidender Bedeutung, wobei eine spärliche Anzahl von Köpfen einzigartige Rollen spielt. | |||
| 09.07.2024 | Induktionsköpfe als wesentlicher Mechanismus für den Mustervergleich beim Lernen im Kontext | ||
| • Der Artikel identifiziert Induktionsköpfe als entscheidend für den Mustervergleich beim In-Context-Lernen (ICL). • Bewertete Llama-3-8B und InternLM2-20B zu abstrakten Mustererkennungs- und NLP-Aufgaben. • Abtragende Induktionsköpfe reduzieren die ICL-Leistung um bis zu ~32 %, sodass sie bei der Mustererkennung nahezu zufällig ist. | |||
| 02.07.2024 | Interpretation arithmetischer Mechanismen in großen Sprachmodellen durch vergleichende Neuronenanalyse | ||
| • Einführung der vergleichenden Neuronenanalyse (CNA), um arithmetische Mechanismen in Aufmerksamkeitsköpfen großer Sprachmodelle abzubilden. • Analysierte Rechenfähigkeiten, Modellbereinigung für Rechenaufgaben und Modellbearbeitung zur Reduzierung von Geschlechterverzerrungen. • Identifizierte spezifische Neuronen, die für die Arithmetik verantwortlich sind und durch gezielte Neuronenmanipulation Leistungsverbesserungen und die Minderung von Verzerrungen ermöglichen. | |||
| 01.07.2024 | Steuerung großer Sprachmodelle für den sprachübergreifenden Informationsabruf | ||
| • Einführung des Activation Steered Multilingual Retrieval (ASMR) mit Steuerungsaktivierungen zur Steuerung von LLMs für einen verbesserten sprachübergreifenden Informationsabruf. • Identifizierte Aufmerksamkeitsköpfe in LLMs, die sich auf Genauigkeit und Sprachkohärenz auswirken, und angewandte Steuerungsaktivierungen. • ASMR erreichte Spitzenleistung bei CLIR-Benchmarks wie XOR-TyDi QA und MKQA. | |||
| 25.06.2024 | Wie Transformatoren mit Gradientenabstieg die kausale Struktur lernen | ||
| • Bereitstellung einer Erklärung, wie Transformatoren kausale Strukturen durch Gradienten-basierte Trainingsalgorithmen lernen. • Analysierte die Leistung von Zweischichttransformatoren bei einer Aufgabe namens Zufallssequenzen mit Kausalstruktur. • Der Gradientenabstieg auf einem vereinfachten zweischichtigen Transformator lernt, diese Aufgabe zu lösen, indem er den latenten Kausalgraphen in der ersten Aufmerksamkeitsschicht kodiert. Als Sonderfall lernen Transformatoren, einen Induktionskopf zu entwickeln, wenn Sequenzen aus kontextbezogenen Markov-Ketten generiert werden. | |||
| 21.06.2024 | MoA: Mischung aus geringer Aufmerksamkeit für die automatische Komprimierung großer Sprachmodelle | ||
| • Das Papier stellt Mixture of Attention (MoA) vor, das unterschiedliche spärliche Aufmerksamkeitskonfigurationen für verschiedene Köpfe und Schichten zuschneidet und so Speicher, Durchsatz und Kompromisse zwischen Genauigkeit und Latenz optimiert. • MoA profiliert Modelle, untersucht Aufmerksamkeitskonfigurationen und verbessert die LLM-Komprimierung. • MoA erhöht die effektive Kontextlänge um das 3,9-fache und reduziert gleichzeitig die GPU-Speichernutzung um das 1,2- bis 1,4-fache. | |||
| 19.06.2024 | Zur Schwierigkeit einer getreuen Gedankenkette in großen Sprachmodellen | ||
| • Einführung neuartiger Strategien für kontextbezogenes Lernen, Feinabstimmung und Aktivierungsbearbeitung, um die Denktreue der Chain-of-Thought (CoT) in LLMs zu verbessern. • Diese Strategien anhand mehrerer Benchmarks getestet, um ihre Wirksamkeit zu bewerten. • Es wurden nur begrenzte Erfolge bei der Verbesserung der CoT-Glaubwürdigkeit festgestellt, was die Herausforderung verdeutlicht, in LLMs eine wirklich glaubwürdige Argumentation zu erreichen. | |||
| 04.06.2024 | Iterationsleiter: Eine mechanistische Studie der Gedankenkette | ||
| • Einführung von „Iterationsköpfen“, spezialisierten Aufmerksamkeitsköpfen, die iteratives Denken in Transformern für Chain-of-Thought (CoT)-Aufgaben ermöglichen. • Analyse von Aufmerksamkeitsmechanismen, Verfolgung der Entstehung von CoT und Prüfung der Übertragbarkeit von CoT-Fähigkeiten zwischen Aufgaben. • Iterationsköpfe unterstützen CoT-Argumentation effektiv und verbessern die Interpretierbarkeit des Modells und die Aufgabenleistung. | |||
| 03.06.2024 | LoFiT: Lokalisierte Feinabstimmung von LLM-Darstellungen | ||
| • Einführung von Localized Fine-tuning on LLM Representations (LoFiT), einem zweistufigen Framework zur Identifizierung wichtiger Aufmerksamkeitsköpfe einer bestimmten Aufgabe und zum Erlernen aufgabenspezifischer Offset-Vektoren, um auf die Darstellungen der identifizierten Köpfe einzugreifen. • Identifizierte spärliche Sätze wichtiger Aufmerksamkeitspunkte zur Verbesserung der nachgelagerten Genauigkeit in Bezug auf Wahrhaftigkeit und Argumentation. • LoFiT übertraf andere Repräsentationsinterventionsmethoden und erreichte eine vergleichbare Leistung wie PEFT-Methoden bei TruthfulQA, CLUTRR und MQuAKE, obwohl es in LLMs nur bei 10 % der gesamten Aufmerksamkeitsköpfe intervenierte. | |||
| 28.05.2024 | Wissensschaltkreise in vortrainierten Transformatoren | ||
| • Einführung von „Wissenskreisläufen“ in Transformern, die zeigen, wie spezifisches Wissen durch die Interaktion zwischen Aufmerksamkeitsköpfen, Beziehungsköpfen und MLPs kodiert wird. • GPT-2 und TinyLLAMA analysiert, um Wissenskreise zu identifizieren; evaluierte Wissensbearbeitungstechniken. • Demonstriert, wie Wissenskreise zu Modellverhalten wie Halluzinationen und kontextbezogenem Lernen beitragen. | |||
| 23.05.2024 | Verknüpfung des kontextbezogenen Lernens in Transformers mit dem episodischen Gedächtnis des Menschen | ||
| • Verknüpft kontextbezogenes Lernen in Transformer-Modellen mit dem episodischen Gedächtnis des Menschen und hebt Ähnlichkeiten zwischen Induktionsköpfen und dem kontextuellen Wartungs- und Abrufmodell (CMR) hervor. • Analyse transformatorbasierter LLMs zur Demonstration von CMR-ähnlichem Verhalten in Aufmerksamkeitsköpfen. • CMR-ähnliche Köpfe tauchen in Zwischenschichten auf und spiegeln menschliche Gedächtnisvorurteile wider. | |||
| 07.05.2024 | Wie sagt GPT-2 Akronyme voraus? Extrahieren und Verstehen eines Schaltkreises durch mechanistische Interpretierbarkeit | ||
| • Erste mechanistische Interpretierbarkeitsstudie zu GPT-2 zur Vorhersage von Multi-Token-Akronymen mithilfe von Aufmerksamkeitsköpfen. • Identifizierte und interpretierte einen Schaltkreis aus 8 Aufmerksamkeitsköpfen, der für die Akronymvorhersage verantwortlich ist. • Es wurde nachgewiesen, dass diese 8 Köpfe (~5 % der Gesamtzahl) die Akronym-Vorhersagefunktion konzentrieren. | |||
| 02.05.2024 | Interpretation und Verbesserung großer Sprachmodelle in der arithmetischen Berechnung | ||
| • Führt eine detaillierte Untersuchung der inneren Mechanismen von LLMs durch mathematische Aufgaben ein, die der „Identifizieren-Analysieren-Feinabstimmung“-Pipeline folgen. • Analysierte die Fähigkeit des Modells, arithmetische Aufgaben mit zwei Operanden wie Addition, Subtraktion, Multiplikation und Division auszuführen. • Es wurde festgestellt, dass LLMs häufig einen kleinen Teil (< 5 %) der Aufmerksamkeitsköpfe involvieren, die eine entscheidende Rolle bei der Fokussierung auf Operanden und Operatoren während Berechnungsprozessen spielen. | |||
| 02.05.2024 | Was muss bei einem Induktionskopf stimmen? Eine mechanistische Untersuchung kontextbezogener Lernkreise und ihrer Entstehung | ||
| • Einführung eines von der Optogenetik inspirierten Kausalrahmens zur Untersuchung der Bildung des Induktionskopfes (IH) in Transformatoren. • Analysierte die IH-Entstehung in Transformatoren anhand synthetischer Daten und identifizierte drei zugrunde liegende Teilschaltkreise, die für die IH-Bildung verantwortlich sind. • Es wurde entdeckt, dass diese Teilschaltkreise interagieren, um die IH-Bildung voranzutreiben, was mit einer Phasenänderung im Modellverlust einhergeht. | |||
| 24.04.2024 | Retrieval Head erklärt mechanistisch die Sachlichkeit im langen Kontext | ||
| • Identifizierte „Abrufköpfe“ in Transformatormodellen, die für das Abrufen von Informationen über lange Kontexte hinweg verantwortlich sind. • Systematische Untersuchung von Retrieval-Köpfen in verschiedenen Modellen, einschließlich der Analyse ihrer Rolle beim Denken in der Gedankenkette. • Das Beschneiden von Bergeköpfen führt zu Halluzinationen, während das Beschneiden von Köpfen, die sich nicht im Bergebereich befinden, keinen Einfluss auf die Bergefähigkeit hat. | |||
| 27.03.2024 | Nichtlineare Inferenzzeitintervention: Verbesserung der LLM-Wahrhaftigkeit | ||
| • Einführung der nichtlinearen Inferenzzeitintervention (NL-ITI), die die LLM-Wahrhaftigkeit durch Multi-Token-Prüfung und Intervention ohne Feinabstimmung verbessert. • Evaluierte NL-ITI anhand von Multiple-Choice-Datensätzen, einschließlich TruthfulQA. • Erzielte eine relative Verbesserung der MC1-Genauigkeit von 16 % bei TruthfulQA im Vergleich zum Basis-ITI. | |||
| 28.02.2024 | Wie man Schritt für Schritt denkt: Ein mechanistisches Verständnis der Gedankenkette | ||
| • Bereitstellung einer eingehenden Analyse des CoT-vermittelten Denkens in LLMs im Hinblick auf die neuronalen Funktionskomponenten. • Analyse des CoT-basierten Denkens über fiktionales Denken als Zusammensetzung einer festen Anzahl von Teilaufgaben, die Entscheidungsfindung, Kopieren und induktives Denken erfordern, und Analyse ihres Mechanismus separat. • Es wurde festgestellt, dass Aufmerksamkeitsköpfe Informationsbewegungen zwischen ontologisch verwandten (oder negativ verwandten) Token durchführen, was zu deutlich identifizierbaren Darstellungen dieser Token-Paare führt. | |||
| 28.02.2024 | Das Abschneiden des Kopfes beendet den Konflikt: Ein Mechanismus zur Interpretation und Abschwächung von Wissenskonflikten in Sprachmodellen | ||
| • Führt die PH3-Methode ein, um widersprüchliche Aufmerksamkeitspunkte zu beschneiden und Wissenskonflikte in Sprachmodellen ohne Parameteraktualisierungen zu mildern. • Wendete PH3 an, um die Abhängigkeit von LMs vom internen Speicher im Vergleich zum externen Kontext zu kontrollieren, und testete seine Wirksamkeit bei QS-Aufgaben im offenen Bereich. • PH3 verbesserte die interne Speichernutzung um 44,0 % und die externe Kontextnutzung um 38,5 %. | |||
| 27.02.2024 | Informationsflussrouten: Automatische Interpretation von Sprachmodellen im großen Maßstab | ||
| • Führt „Information Flow Routes“ ein, die Attribution für die graphbasierte Interpretation von Sprachmodellen verwenden und Aktivierungspatches vermeiden. • Experimente mit Lama 2, um wichtige Aufmerksamkeitspunkte und Verhaltensmuster in verschiedenen Bereichen und Aufgaben zu identifizieren. • Aufgedeckte spezialisierte Modellkomponenten; identifizierte konsistente Rollen für Aufmerksamkeitsköpfe, z. B. den Umgang mit Token derselben Wortart. | |||
| 20.02.2024 | Identifizieren semantischer Induktionsköpfe zum Verständnis des Lernens im Kontext | ||
| • Identifiziert und untersucht „semantische Induktionsköpfe“ in großen Sprachmodellen (LLMs), die mit kontextbezogenen Lernfähigkeiten korrelieren. • Analysierte Aufmerksamkeitsköpfe für die Kodierung syntaktischer Abhängigkeiten und Wissensgraphenbeziehungen. • Bestimmte Aufmerksamkeitsköpfe verbessern die Ausgabeprotokolle, indem sie relevante Token abrufen, was für das Verständnis des kontextbezogenen Lernens in LLMs von entscheidender Bedeutung ist. | |||
| 16.02.2024 | Die Entwicklung statistischer Induktionsköpfe: Markov-Ketten im Kontextlernen | ||
| • Führt eine Markov-Ketten-Sequenzmodellierungsaufgabe ein, um zu analysieren, wie In-Context-Learning (ICL)-Fähigkeiten in Transformatoren entstehen und „statistische Induktionsköpfe“ bilden. • Empirische und theoretische Untersuchung des Mehrphasentrainings in Transformatoren auf Markov-Ketten-Aufgaben. • Demonstriert Phasenübergänge von Unigramm- zu Bigramm-Vorhersagen, beeinflusst durch Wechselwirkungen zwischen Transformatorschichten. | |||
| 11.02.2024 | Zusammenfassung der Fakten: Additive Mechanismen hinter dem Faktenrückruf in LLMs | ||
| • Identifiziert und erklärt das „additive Motiv“ bei der Erinnerung an Fakten, bei dem LLMs mehrere unabhängige Mechanismen verwenden, die konstruktiv interferieren, um Fakten abzurufen. • Erweiterte direkte Logit-Attribution zur Analyse von Aufmerksamkeitsköpfen und Entschlüsselung des Verhaltens gemischter Köpfe. • Zeigte, dass die faktische Erinnerung in LLMs aus der Summe mehrerer, unabhängig voneinander unzureichender Beiträge resultiert. | |||
| 05.02.2024 | Wie lernen große Sprachmodelle im Kontext? Abfrage- und Schlüsselmatrizen von In-Context-Heads sind zwei Türme für metrisches Lernen | ||
| • Führt das Konzept ein, dass Abfrage- und Schlüsselmatrizen in kontextbezogenen Köpfen als „zwei Türme“ für das metrische Lernen fungieren und die Ähnlichkeitsberechnung zwischen Beschriftungsmerkmalen erleichtern. • Analysierte kontextbezogene Lernmechanismen; identifizierte spezifische Aufmerksamkeitsköpfe, die für ICL von entscheidender Bedeutung sind. • Reduzierte ICL-Genauigkeit von 87,6 % auf 24,4 % durch Eingriffe in nur 1 % dieser Köpfe. | |||
| 23.01.2024 | Sprachenlernen im Kontext: Architekturen und Algorithmen | ||
| • Einführung von „N-Gramm-Köpfen“, spezialisierten Transformer-Aufmerksamkeitsköpfen, die das kontextbezogene Sprachenlernen (ICLL) durch eingabebedingte Token-Vorhersage verbessern. • Bewertete neuronale Modelle für reguläre Sprachen aus zufälligen endlichen Automaten. • Festverdrahtete N-Gramm-Köpfe verbesserten die Ratlosigkeit im SlimPajama-Datensatz um 6,7 %. | |||
| 16.01.2024 | Die mechanistische Grundlage der Datenabhängigkeit und des abrupten Lernens in einer kontextbezogenen Klassifizierungsaufgabe | ||
| • Der Artikel modelliert die mechanistische Grundlage des In-Context-Lernens (ICL) über die abrupte Bildung von Induktionsköpfen in Nur-Aufmerksamkeits-Netzwerken. • Simulierte ICL-Aufgaben unter Verwendung vereinfachter Eingabedaten und eines zweischichtigen aufmerksamkeitsbasierten Netzwerks. • Die Bildung des Induktionskopfes treibt den abrupten Übergang zur ICL voran, der durch verschachtelte Nichtlinearitäten verfolgt wird. | |||
| 16.01.2024 | Wiederverwendung von Schaltungskomponenten über Aufgaben hinweg in Transformer-Sprachmodellen | ||
| • Das Papier zeigt, dass bestimmte Schaltkreise in GPT-2 über verschiedene Aufgaben hinweg verallgemeinert werden können, und stellt damit die Vorstellung in Frage, dass solche Schaltkreise aufgabenspezifisch seien. • Es untersucht die Wiederverwendung von Schaltkreisen aus der Aufgabe „Indirekte Objektidentifizierung“ (IOI) in der Aufgabe „Farbige Objekte“. • Durch Anpassen von vier Aufmerksamkeitsköpfen wird die Genauigkeit bei der Aufgabe „Farbige Objekte“ von 49,6 % auf 93,7 % erhöht. | |||
| 16.01.2024 | Nachfolgerköpfe: Wiederkehrende, interpretierbare Aufmerksamkeitsköpfe in freier Wildbahn | ||
| • Das Papier stellt „Successor Heads“ vor, Aufmerksamkeitsköpfe in LLMs, die Token mit natürlichen Reihenfolgen, wie Tagen oder Zahlen, erhöhen. • Es analysiert die Bildung von Nachfolgeköpfen über verschiedene Modellgrößen und Architekturen hinweg, wie z. B. GPT-2 und Llama-2. • Nachfolgeköpfe finden sich in Modellen mit Parametern von 31M bis 12B, die abstrakte, wiederkehrende numerische Darstellungen offenbaren. | |||
| 16.01.2024 | Funktionsvektoren in großen Sprachmodellen | ||
| • Der Artikel stellt „Funktionsvektoren (FVs)“ vor, kompakte, kausale Darstellungen von Aufgaben innerhalb autoregressiver Transformatormodelle. • FVs wurden über verschiedene Aufgaben, Modelle und Ebenen des In-Context-Learning (ICL) hinweg getestet. • FVs können summiert werden, um Vektoren zu erstellen, die neue, komplexe Aufgaben auslösen und die interne Vektorzusammensetzung demonstrieren. | |||
| Datum | Papier & Zusammenfassung | Schlagworte | Links |
| 23.12.2023 | Faktenermittlung: Versuch, die sachliche Erinnerung auf Neuronenebene zurückzuentwickeln | ||
| • Untersuchte, wie frühe MLP-Schichten in Pythia 2.8B den sachlichen Rückruf mithilfe verteilter Schaltkreise kodieren, wobei der Schwerpunkt auf Überlagerung und Einbettungen mehrerer Token lag. • Untersuchte die sachliche Suche in MLP-Schichten und testete Hypothesen zur Detokenisierung und zu Hashing-Mechanismen. • Der Faktenabruf funktioniert wie eine verteilte Nachschlagetabelle ohne leicht interpretierbare interne Mechanismen. | |||
| 07.11.2023 | Auf dem Weg zur interpretierbaren Sequenzfortsetzung: Analyse gemeinsamer Schaltkreise in großen Sprachmodellen | ||
| • Demonstrierte die Existenz gemeinsamer Schaltkreise für ähnliche Sequenzfortsetzungsaufgaben. • Analysierte und verglichene Schaltkreise für ähnliche Sequenzfortsetzungsaufgaben, die zunehmende Sequenzen arabischer Ziffern, Zahlwörter und Monate umfassen. • Semantisch verwandte Sequenzen basieren auf gemeinsam genutzten Schaltkreis-Teilgraphen mit analogen Rollen und dem Auffinden ähnlicher Teilschaltkreise über Modelle hinweg mit analoger Funktionalität. | |||
| 23.10.2023 | Lineare Darstellungen von Gefühlen in großen Sprachmodellen | ||
| • Das Papier identifiziert eine lineare Richtung im Aktivierungsraum, die die Stimmungsdarstellung in Large Language Models (LLMs) erfasst. • Sie isolierten diese Stimmungsrichtung und testeten sie an Aufgaben wie der Stanford Sentiment Treebank. • Die Entfernung dieser Stimmungsrichtung führt zu einer Verringerung der Klassifizierungsgenauigkeit um 76 %, was ihre Bedeutung unterstreicht. | |||
| 06.10.2023 | Kopierunterdrückung: Einen Aufmerksamkeitskopf umfassend verstehen | ||
| • Das Papier stellt das Konzept der Kopierunterdrückung in einem GPT-2 Small Attention Head (L10H7) vor, das das naive Kopieren von Token reduziert und die Modellkalibrierung verbessert. • Der Artikel untersucht und erklärt den Mechanismus der Kopierunterdrückung und seine Rolle bei der Selbstreparatur . • 76,9 % des Einflusses von L10H7 auf GPT-2 Small werden erklärt, was es zur umfassendsten Beschreibung der Rolle eines Aufmerksamkeitsleiters macht. | |||
| 22.09.2023 | Inferenzzeitintervention: Wahrhaftige Antworten aus einem Sprachmodell ermitteln | ||
| • Einführung der Inferenz-Zeit-Intervention (ITI) zur Verbesserung der LLM-Wahrhaftigkeit durch Anpassung der Modellaktivierungen in ausgewählten Aufmerksamkeitsköpfen. • Verbesserte Leistung des LLaMA-Modells beim TruthfulQA-Benchmark. • ITI erhöhte den Wahrheitsgehalt des Alpaka-Modells von 32,5 % auf 65,1 %. | |||
| 22.09.2023 | Geburt eines Transformators: Ein Erinnerungsstandpunkt | ||
| • Der Artikel stellt eine gedächtnisbasierte Perspektive auf Transformatoren vor und beleuchtet assoziative Erinnerungen in Gewichtsmatrizen und ihr gradientengesteuertes Lernen. • Empirische Analyse der Trainingsdynamik an einem vereinfachten Transformatormodell mit synthetischen Daten. • Entdeckung des schnellen globalen Bigram-Lernens und der langsameren Entstehung eines „Induktionskopfes“ für kontextbezogene Bigramme. | |||
| 13.09.2023 | Plötzliche Verlusteinbrüche: Syntaxerwerb, Phasenübergänge und Einfachheitsverzerrung in MLMs | ||
| • Identifiziert die syntaktische Aufmerksamkeitsstruktur (SAS) als eine natürlich entstehende Eigenschaft in maskierten Sprachmodellen (MLMs) und ihre Rolle beim Syntaxerwerb. • Analysiert SAS während des Trainings und manipuliert es, um seine kausale Wirkung auf die grammatikalischen Fähigkeiten zu untersuchen. • SAS ist für die Grammatikentwicklung notwendig, aber eine kurze Unterdrückung verbessert die Modellleistung. | |||
| 18.07.2023 | Skaliert die Interpretierbarkeit der Schaltungsanalyse? Hinweise auf Multiple-Choice-Fähigkeiten bei Chinchilla | ||
| • Skalierbare Schaltungsanalyse, angewendet auf ein 70B Chinchilla-Sprachmodell zum Verständnis der Beantwortung von Multiple-Choice-Fragen. • Logit-Attribution, Visualisierung von Aufmerksamkeitsmustern und Aktivierungs-Patching zur Identifizierung und Kategorisierung wichtiger Aufmerksamkeitsköpfe. • Die Funktion „N-tes Element in einer Aufzählung“ wurde in Hinweisköpfen identifiziert, obwohl dies nur eine teilweise Erklärung ist. | |||
| 02.02.2023 | Interpretierbarkeit in freier Wildbahn: eine Schaltung zur indirekten Objektidentifizierung in GPT-2 klein | ||
| • Das Papier führt eine detaillierte Erklärung ein, wie GPT-2 Small die indirekte Objektidentifikation (IOI) mithilfe einer großen Schaltung durchführt, an der 28 Aufmerksamkeitsköpfe beteiligt sind, die in 7 Klassen gruppiert sind. • Sie haben die IOI-Aufgabe in GPT-2 Small mithilfe von kausalen Interventionen und Prognosen rückentwickelt. • Die Studie zeigt, dass eine mechanistische Interpretierbarkeit großer Sprachmodelle möglich ist. | |||
| Datum | Papier & Zusammenfassung | Schlagworte | Links |
| 08.03.2022 | Leiter für kontextbezogenes Lernen und Einführung | ||
| • Der Artikel identifiziert „Induktionsköpfe“ in Transformer-Modellen, die kontextbezogenes Lernen ermöglichen, indem sie Muster in Sequenzen erkennen und kopieren. • Analysiert Aufmerksamkeitsmuster und Induktionsköpfe über verschiedene Schichten in verschiedenen Transformer-Modellen. • Es wurde festgestellt, dass Induktionsköpfe von entscheidender Bedeutung dafür sind, dass Transformers Lernaufgaben im Kontext verallgemeinern und effektiv ausführen können. | |||
| 22.12.2021 | Ein mathematischer Rahmen für Transformatorschaltungen | ||
| • Führt ein mathematisches Framework zum Reverse Engineering kleiner Nur-Aufmerksamkeits-Transformatoren ein, wobei der Schwerpunkt auf dem Verständnis von Aufmerksamkeitsköpfen als unabhängige, additive Komponenten liegt. • Analysierte Null-, Ein- und Zweischichttransformatoren, um die Rolle von Aufmerksamkeitsköpfen bei der Informationsbewegung und -zusammensetzung zu identifizieren. • Entdeckung von „Induktionsköpfen“, die für das kontextbezogene Lernen in Zweischichttransformatoren von entscheidender Bedeutung sind. | |||
| 18.05.2021 | Die Heads-Hypothese: Ein vereinheitlichender statistischer Ansatz zum Verständnis der mehrköpfigen Aufmerksamkeit in BERT | ||
| • Das Papier schlägt eine neuartige Methode namens „Sparse Attention“ vor, die die rechnerische Komplexität von Aufmerksamkeitsmechanismen durch selektive Fokussierung auf wichtige Token reduziert. • Die Methode wurde an maschinellen Übersetzungs- und Textklassifizierungsaufgaben evaluiert. • Das Sparse-Attention-Modell erreicht eine vergleichbare Genauigkeit wie das Dense-Attention-Modell und reduziert gleichzeitig den Rechenaufwand erheblich. | |||
| 01.04.2021 | Haben Aufmerksamkeitsköpfe im BERT Wahlkreisgrammatik gelernt? | ||
| • Die Studie führt eine syntaktische Distanzmethode zur Analyse der Wahlkreisgrammatik in BERT- und RoBERTa-Aufmerksamkeitsköpfen ein. • Die Wahlkreisgrammatik wurde vor und nach der Feinabstimmung von SMS- und NLI-Aufgaben extrahiert und analysiert. • NLI-Aufgaben erhöhen die Fähigkeit zur Grammatikinduzierung im Wahlkreis, während SMS-Aufgaben sie in den oberen Schichten verringern. | |||
| 27.11.2019 | Machen Sie Aufmerksamkeitsköpfe in Bert -Syntaktischen Abhängigkeiten? | ||
| • Das Papier untersucht, ob die individuelle Aufmerksamkeit in Bert -Erfassung syntaktische Abhängigkeiten verwendet, wobei die Aufmerksamkeitsgewichte verwendet werden, um Abhängigkeitsbeziehungen zu extrahieren. • Analysierte Berts Aufmerksamkeitsköpfe mit maximalen Aufmerksamkeitsgewichten und maximalen Spannbäumen und vergleiche sie mit universellen Abhängigkeitsbäumen. • Einige Aufmerksamkeitsköpfe verfolgen spezifische syntaktische Abhängigkeiten besser als Baselines, aber kein Kopf führt ein ganzheitliches Parsen deutlich besser durch. | |||
| 2019-11-01 | Adaptiv spärliche Transformatoren | ||
| • Einführte den adaptiv spärlichen Transformator mit Alpha-Inentmax ein, um eine flexible, kontextabhängige Sparsamkeit in Aufmerksamkeitsköpfen zu ermöglichen. • Angewendet auf maschinelle Übersetzungsdatensätze zur Beurteilung der Interpretierbarkeit und der Kopfdiversität. • Erreichte vielfältige Aufmerksamkeitsverteilungen und verbesserte Interpretierbarkeit ohne Kompromissgenauigkeit. | |||
| 2019-08-01 | Was sieht Bert an? Eine Analyse der Aufmerksamkeit von Bert | ||
| • Das Papier führt Methoden ein, um Berts Aufmerksamkeitsmechanismen zu analysieren und Muster zu enthüllen, die sich mit sprachlichen Strukturen wie Syntax und Coreference übereinstimmen. • Analyse der Aufmerksamkeitsköpfe, Identifizierung von syntaktischen und kernfertigen Mustern und Entwicklung eines aufmerksamkeitsbasierten Probierungsklassifikators. • Berts Aufmerksamkeitsköpfe erfassen wesentliche syntaktische Informationen, insbesondere bei Aufgaben wie der Identifizierung direkter Objekte und der Koreferenz. | |||
| 2019-07-01 | Analyse von Selbstbekämpfung mit mehreren Kopf: Spezialisierte Köpfe machen das schwere Heben, der Rest kann beschnitten werden | ||
| • Das Papier führt eine neuartige Schnittmethode für die Selbstverpflegung mit mehreren Kopf, die selektiv weniger wichtige Köpfe ohne größeren Leistungsverlust beseitigt. • Analyse individueller Aufmerksamkeitsköpfe, Identifizierung ihrer speziellen Rollen und Anwendung einer Schnittmethode auf das Transformatormodell. • Das Beschneiden von 38 von 48 Köpfen im Encoder führte zu einem Rückgang von 0,15 Bleu -Score. | |||
| 2018-11-01 | Eine Analyse von Encoder-Darstellungen in der transformatorbasierten maschinellen Übersetzung | ||
| • Dieses Papier analysiert die internen Darstellungen von Transformator-Encoder-Schichten und konzentriert sich auf syntaktische und semantische Informationen, die von Selbstbekämpfungsköpfen gelernt werden. • Prüfungsaufgaben, Abhängigkeitsbeziehungsextraktion und ein Szenario für Transferlernen. • Niedrigere Ebenen erfassen Syntax, während höhere Schichten mehr semantische Informationen codieren. | |||
| 2016-03-21 | Einbeziehung des Kopiermechanismus in Sequenz-zu-Sequenz-Lernen | ||
| • Führen Sie einen Kopiermechanismus in Sequenz-zu-Sequenz-Modelle ein, um das direkte Kopieren von Eingangs-Token zu ermöglichen und die Handhabung seltener Wörter zu verbessern. • Angewendet auf maschinelle Übersetzungs- und Zusammenfassungsaufgaben. • erzielte erhebliche Verbesserungen der Übersetzungsgenauigkeit, insbesondere bei seltener Wortübersetzung, im Vergleich zu Standard-Sequenz-zu-Sequenz-Modellen. | |||
Ausgabevorlage:
Title: [paper's title]
Head: [head name1] (, [head name2] ...)
Published: [arXiv / ACL / ICLR / NIPS / ...]
Summary:
- Innovation:
- Tasks:
- Significant Result:


