llmjudge
1.0.0
Die Bewertung von LLMs in einem Szenario mit offenem Ende ist schwierig, es besteht ein wachsender Konsens darüber, dass bestehende Benchmarks fehlen und erfahrene Praktiker es vorziehen, Vibe-Check- Modelle selbst zu verwenden. Ich habe auf anekdotische Bewertungen von Entwicklern und Forschern zurückgegriffen, denen ich vertraue, wobei Chatbot Arena eine hervorragende Ergänzung darstellt. Die Motivation hinter diesem Repo ist die immer beliebter werdende Methode, starke LLMs als Richter für Modelle zu verwenden. Diese Methode gibt es schon seit einigen Monaten bei Modellen wie JudgeLM und neuerdings MT-Bench.
Möglicherweise haben Sie diesen Thread gesehen oder auch nicht. Laut den Autoren des Tweets bei Arize AI ist bei der Verwendung von LLMs als Richter Vorsicht geboten, insbesondere im Hinblick auf die Verwendung numerischer Punkteauswertungen. Es scheint, dass LLMs sehr schlecht im Umgang mit kontinuierlichen Bereichen sind, was deutlich deutlich wird , wenn man sie dazu auffordert, Jüngste Arbeiten haben eine starke Korrelation zwischen MT-Bench und Human Judgement (Arena Elo) festgestellt, was bedeutet, dass LLMs in der Lage sind, Richter zu sein. Was ist hier also los?
Nachfolgend finden Sie die vollständigen Details und Ergebnisse.
Aus Kostengründen werde ich mich zunächst auf die in den Tweets beschriebene Rechtschreib-/Rechtschreibfehleraufgabe konzentrieren. Ich mache mir ein wenig Sorgen, dass das quantitative X dieser Aufgabe die Erkenntnisse dieses Experiments verunreinigen wird, aber wir werden sehen. Ich begrüße eine umfassendere Analyse dieses Phänomens. Meine Ergebnisse sind angesichts der begrenzten Experimente mit Vorsicht zu genießen
Ich habe aus den Aufsätzen von Paul Graham einen Datensatz zu Rechtschreibung oder Rechtschreibfehlern erstellt und bin mir nicht sicher, welcher Name passender ist. Diese Wahl erfolgte hauptsächlich aus Bequemlichkeit, da ich den Datensatz schon früher beim Drucktest von Kontextfenstern verwendet habe. Ich habe einen Kontext von 3.000 Wörtern aus den Aufsätzen extrahiert und Rechtschreibfehler bei zufälligen Wörtern basierend auf dem gewünschten Rechtschreibverhältnis eingefügt. Im Pseudocode:
misspell_ratio
words = split context into words
misspell_count = calculate number of words to misspell based on ratio
FOR word = sample(words, misspell_count)
IF length(word) > 3
extract random character
ELSE:
add random character
END FOR
Der vollständige Code ist als Notizbuch verfügbar.
Anhand des generierten Datensatzes veranlassen wir LLMs, die Anzahl falsch geschriebener Wörter in einem Kontext mithilfe verschiedener Bewertungsvorlagen zu bewerten. Wir verwenden die folgenden APIs
GPT-4: gpt-4-0125-preview
GPT-3.5: gpt-3.5-turbo-1106
bei Temperatur = 0.
Test 1. Lassen Sie uns bestätigen, dass LLMs Schwierigkeiten haben, numerische Bereiche in einer Zero-Shot-Einstellung zu verarbeiten. Wir fordern GPT-3.5 und GPT-4 mit einer numerischen Bewertungsvorlage auf, die von Punktzahl 0 bis Punktzahl 10 reicht.
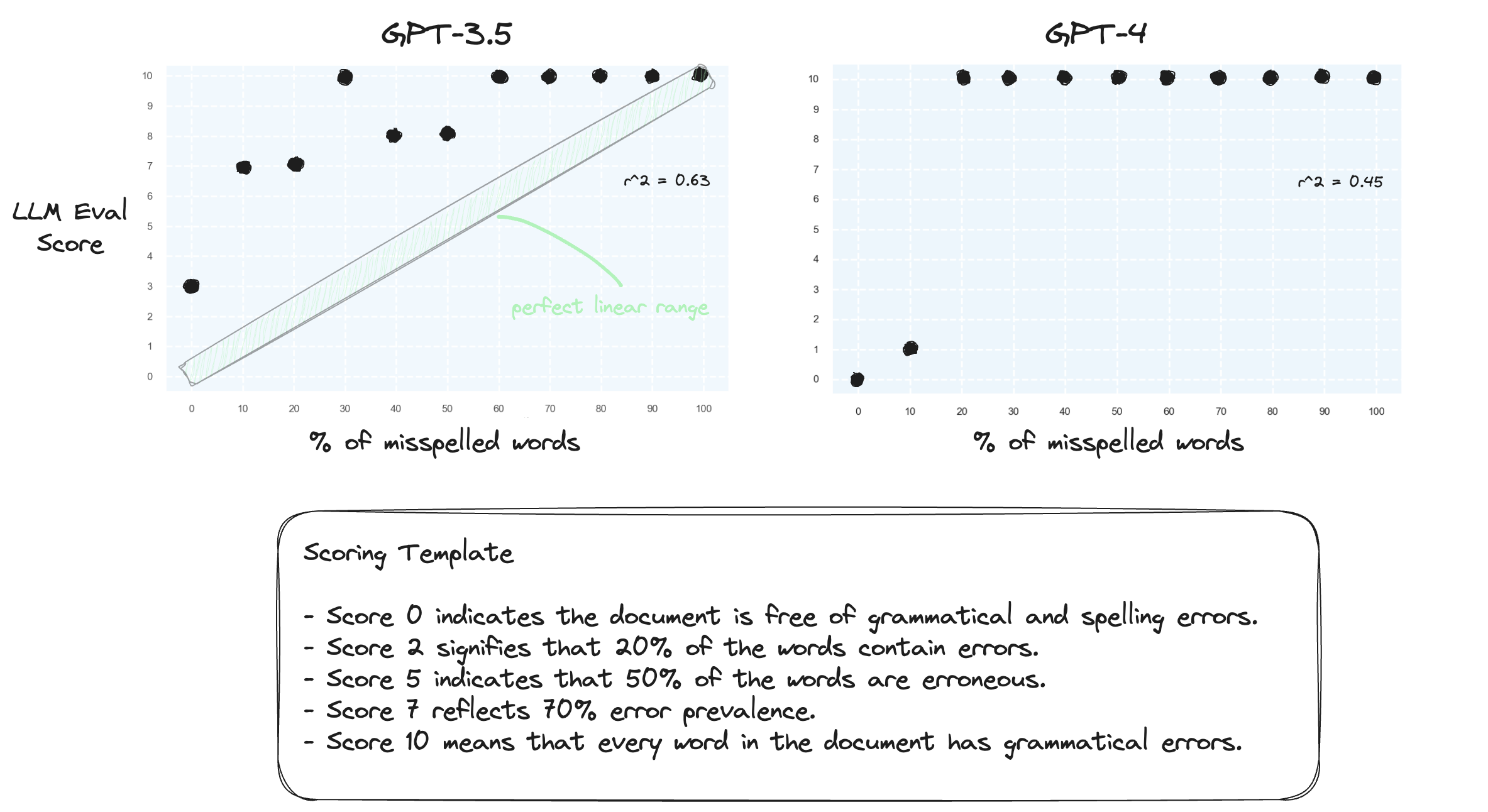
Erwartungsgemäß verschätzen sich beide gravierend.
Test 2. Was passiert, wenn wir den Bewertungsbereich umkehren? Eine Punktzahl von 10 bedeutet nun ein perfekt geschriebenes Dokument.
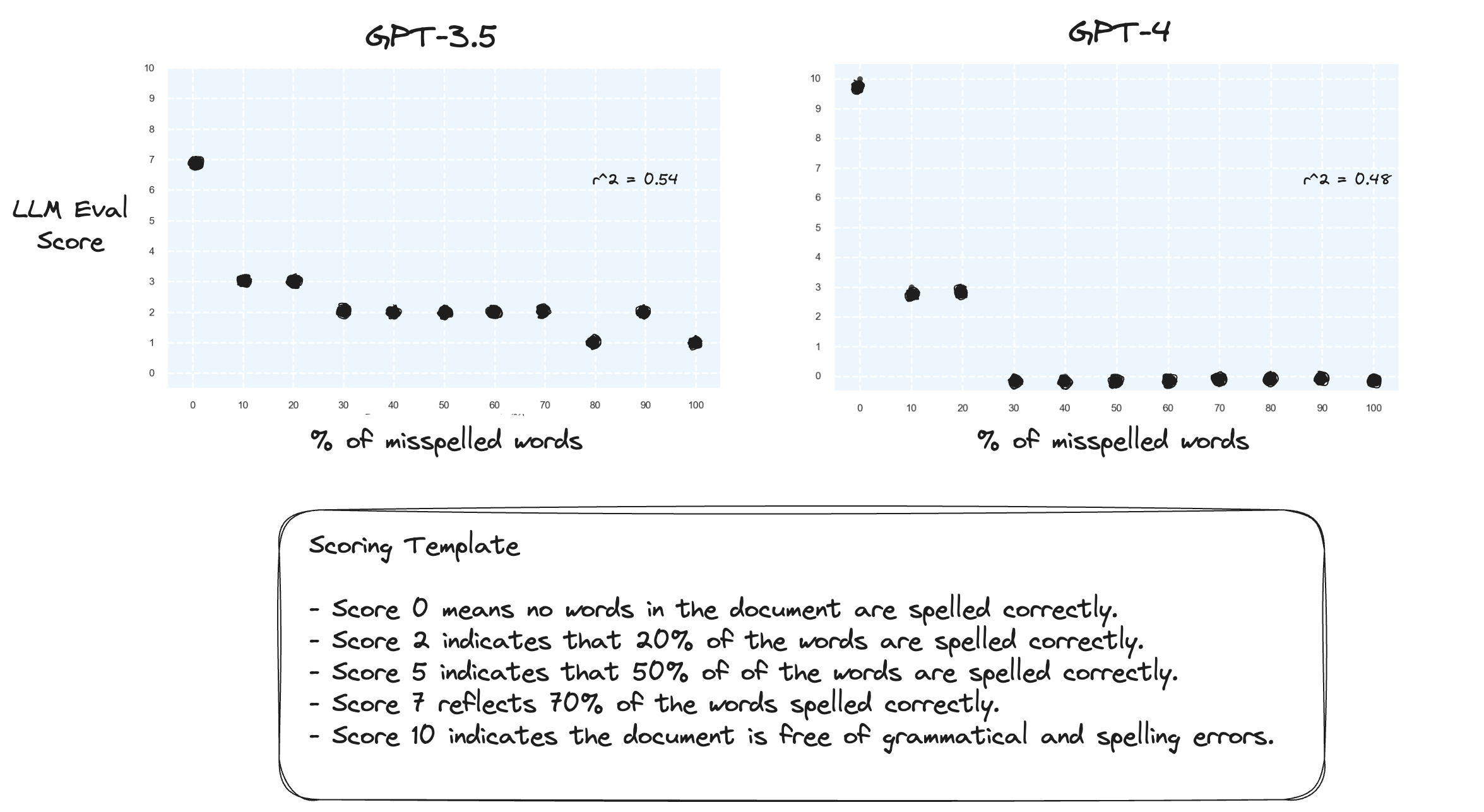
Das scheint keinen großen Unterschied zu machen.
Test 3. Wenn wir der Hypothese von Arize glauben würden, könnten wir Verbesserungen sehen, wenn wir eine Bewertungsrubrik vermeiden und stattdessen „beschriftete Noten“ verwenden. In diesem Fall habe ich mich entschieden, auf eine 5-Punkte-Bewertungsskala umzusteigen.
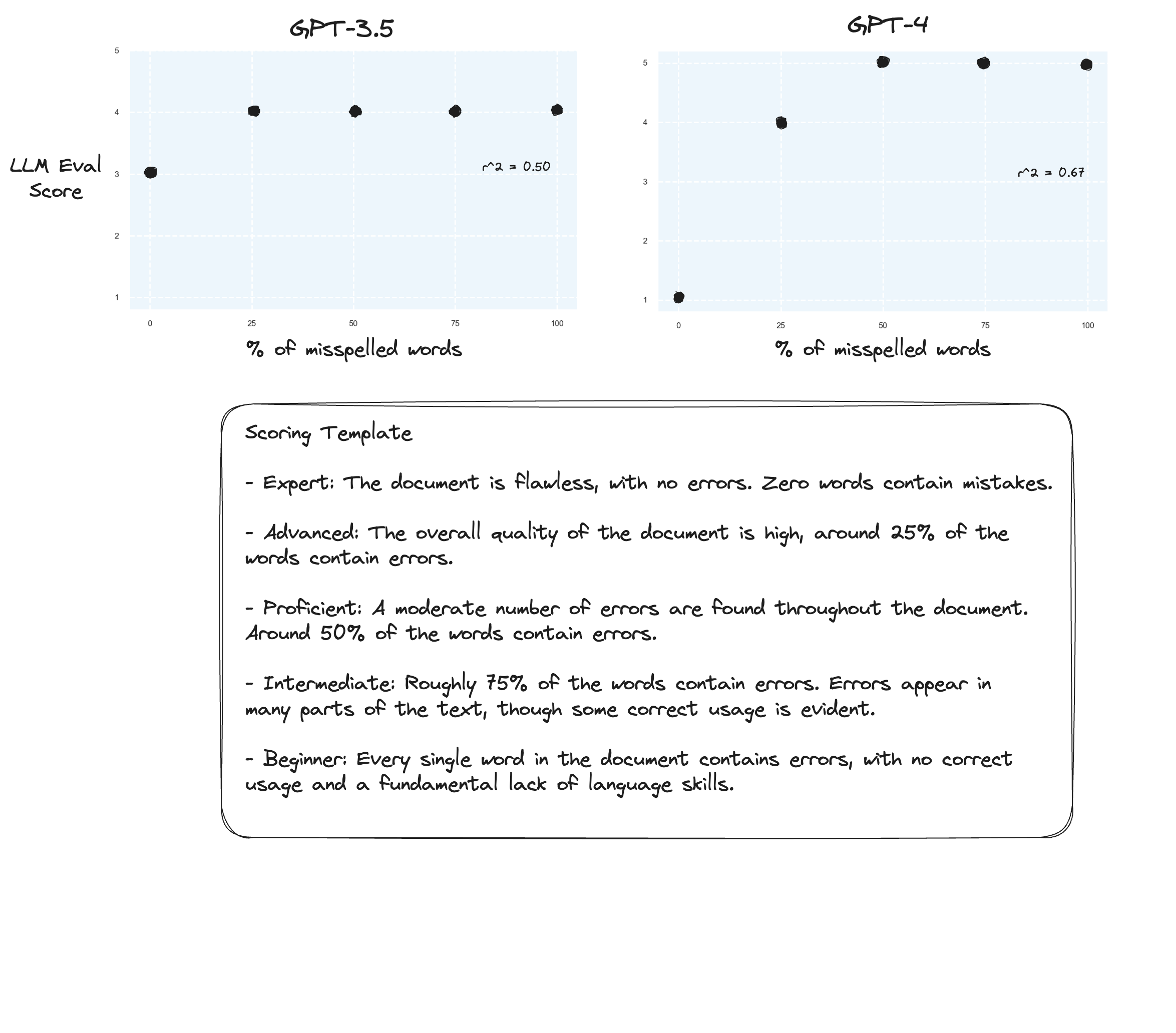
Vielleicht leichte Verbesserungen? Schwer ehrlich zu sagen. Ich bin nicht beeindruckt.
Test 4. Was ist mit der Zero-Shot-Gedankenkette?

gpt-3.5 wurde für zwei der Eingabeaufforderungen in Unsinn umgewandelt. Wie erwartet stellt gpt-4 eine Verbesserung fest, wenn es zum lauten Nachdenken aufgefordert wird. Beachten Sie, dass es sehr zögerlich wird, eine Punktzahl von 10 zu vergeben.
Test 5. Wie vom Autor von Prometheus vorgeschlagen; Die Zuordnung jeder Punktzahl mit einer eigenen Erklärung verbessert wahrscheinlich die Fähigkeit der LLMs, über den gesamten numerischen Bereich zu benoten. In Kombination mit CoT führt dies zu Folgendem:

Weitere Verbesserungen für gpt-4. Es ist immer noch sehr zurückhaltend, die Grenzwerte 0 und 10 zu vergeben.
Test 6. Nachdem ich mehr über MT Bench gelesen hatte, beschloss ich, einen alternativen Ansatz zu testen, bei dem paarweise Vergleiche anstelle einer isolierten Bewertung verwendet wurden. Normalerweise wären hierfür O(n * log N)-Vergleiche erforderlich, aber da wir die Reihenfolge bereits kennen, habe ich mir gedacht, dass wir nur die schwierigsten Fälle testen würden: Vergleich von 0 % Rechtschreibfehlern mit 10 % Rechtschreibfehlern, 10 % mit 20 % und so weiter für insgesamt 10 Vergleiche. Beachten Sie, dass ich auch Zero-Shot-CoT verwendet habe.
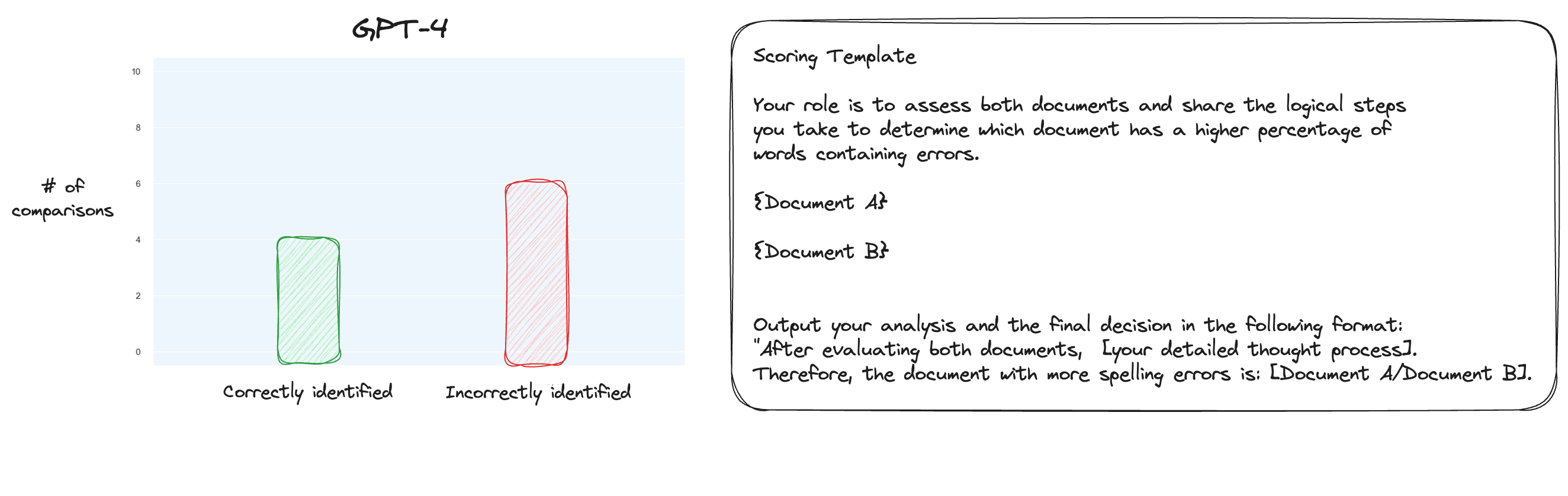
Meine Hypothese war, dass GPT-4 in einem Szenario, in dem es zwei Texte innerhalb seines Kontextfensters vergleichen konnte, hervorragende Leistungen erbracht hätte, aber ich habe mich geirrt. Zu meiner Überraschung hat dies die Sache überhaupt nicht verbessert. Sicherlich ist dies der schwierigste aller möglichen Vergleiche, aber alles in allem ist es immer noch eine einfache Aufgabe. Vielleicht sind die quantitativen Aspekte dieser Aufgabe für LLMs einfach von Natur aus sehr schwierig. Hmm, vielleicht muss ich eine bessere Proxy-Aufgabe finden ...
(31/1) Ich habe die Interna von MT-Bench durchgesehen und war sehr überrascht, dass sie GPT-4 einfach auffordern, Ergebnisse auf einer Skala von 1-10 zu bewerten. Sie bieten zwar alternative Bewertungsoptionen wie paarweise Vergleiche mit einer Basislinie, die empfohlene Option ist jedoch die numerische. Auch die Urteilsaufforderung ist unerwartet einfach:
Bitte handeln Sie als unparteiischer Richter und bewerten Sie die Qualität der Antwort eines KI-Assistenten auf die unten angezeigte Benutzerfrage. Bei Ihrer Bewertung sollten Faktoren wie Nützlichkeit, Relevanz, Genauigkeit, Tiefe, Kreativität und Detaillierungsgrad der Antwort berücksichtigt werden. Beginnen Sie Ihre Bewertung mit einer kurzen Erklärung. Seien Sie so objektiv wie möglich. Nachdem Sie Ihre Erklärung abgegeben haben, müssen Sie die Antwort auf einer Skala von 1 bis 10 bewerten, indem Sie sich strikt an das folgende Format halten: [Bewertung], zum Beispiel: „Bewertung: 5“. [Frage] {question} [Der Anfang der Antwort des Assistenten] {answer} [Das Ende der Antwort des Assistenten]
Wenn man glauben will, dass dies alles ist, was man in MT-Bench beurteilen kann, dann fange ich an, die Verwendung der Rechtschreibfehler-Aufgabe als Proxy-Aufgabe in Frage zu stellen ...
(2/2) Ich möchte GPT-4 dazu bringen, falsch geschriebene Texte durch einen paarweisen Vergleich statt durch eine isolierte Bewertung zu beurteilen. Dies ist eine der alternativen Beurteilungsmethoden für MT Bench (obwohl eine isolierte Bewertung empfohlen wird), und ich vermute, dass sie für diese Aufgabe besser geeignet ist. Die CoT- und vollständigen Mapping-Ergebnisse sind definitiv eine Verbesserung, aber ich denke, dass noch viel zu tun ist. Der Nachteil der paarweisen Bewertung besteht natürlich darin, dass Sie deutlich mehr API-Aufrufe benötigen, um das vollständige Ranking zu ermitteln (in der Praxis).


