DreamerGPT
1.0.0
 DreamerGPT: Feinabstimmung der Modellanweisungen in chinesischer Sprache
DreamerGPT: Feinabstimmung der Modellanweisungen in chinesischer Sprache? DreamerGPT ist ein von Xu Hao, Chi Huixuan, Bei Yuanchen und Liu Danyang initiiertes Projekt zur Feinabstimmung des chinesischen Unterrichts in großen Sprachen.
Lesen Sie in der englischen Version .

 1. Projekteinführung
1. ProjekteinführungZiel dieses Projekts ist es, die Anwendung großer chinesischer Sprachmodelle in vertikaleren Feldszenarien zu fördern.
Unser Ziel ist es, große Modelle zu verkleinern und jedem zu helfen, einen personalisierten Expertenassistenten in seinem eigenen vertikalen Bereich zu haben. Er kann ein psychologischer Berater, ein Code-Assistent, ein persönlicher Assistent oder Ihr eigener Sprachlehrer sein DreamerGPT ist ein Sprachmodell, das die bestmöglichen Ergebnisse liefert, die niedrigsten Schulungskosten aufweist und besser für Chinesisch optimiert ist. Das DreamerGPT-Projekt wird weiterhin iteratives Sprachmodell-Hot-Start-Training (einschließlich LLaMa, BLOOM), Instruktionstraining, Verstärkungslernen und vertikale Feldfeinabstimmung eröffnen und weiterhin zuverlässige Trainingsdaten und Bewertungsziele iterieren. Aufgrund des begrenzten Projektpersonals und der begrenzten Ressourcen ist die aktuelle Version V0.1 auf chinesisches LLaMa für LLaMa-7B und LLaMa-13B optimiert und fügt chinesische Funktionen, Sprachausrichtung und andere Funktionen hinzu. Derzeit gibt es noch Mängel bei den Funktionen für lange Dialoge und beim logischen Denken. Weitere Iterationspläne finden Sie in der nächsten Version des Updates.
Das Folgende ist eine Quantisierungsdemo basierend auf 8b (das Video ist nicht beschleunigt). Derzeit werden auch Inferenzbeschleunigung und Leistungsoptimierung iteriert:
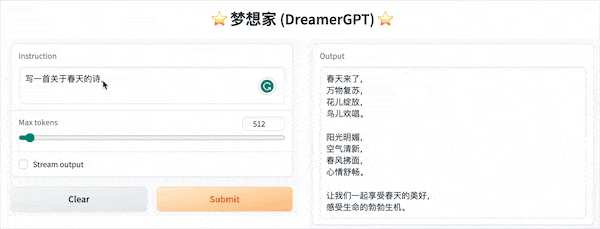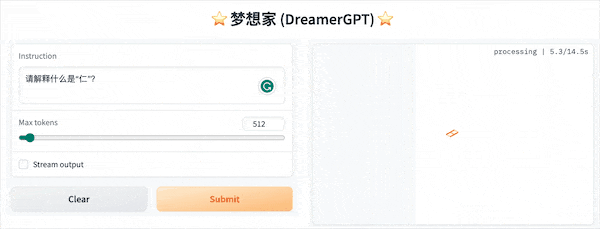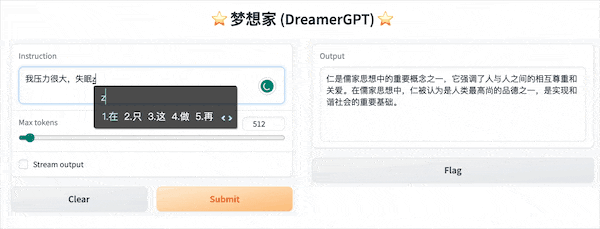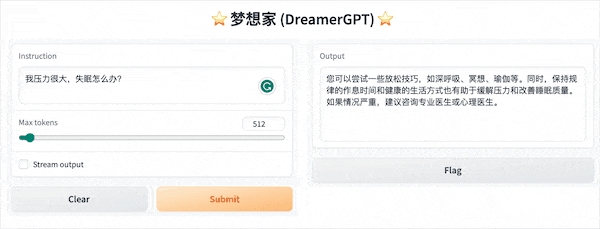
Weitere Demodisplays:
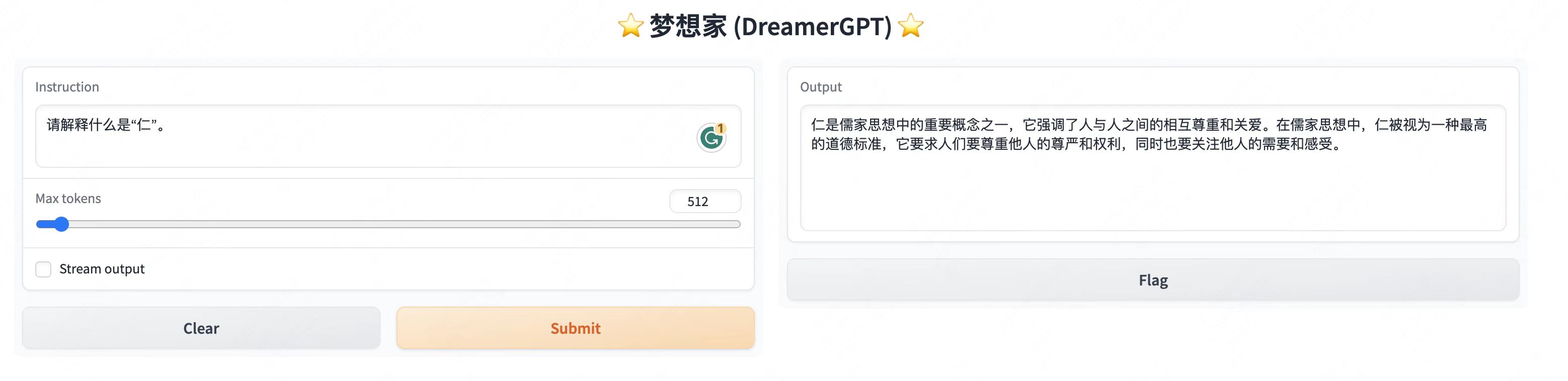

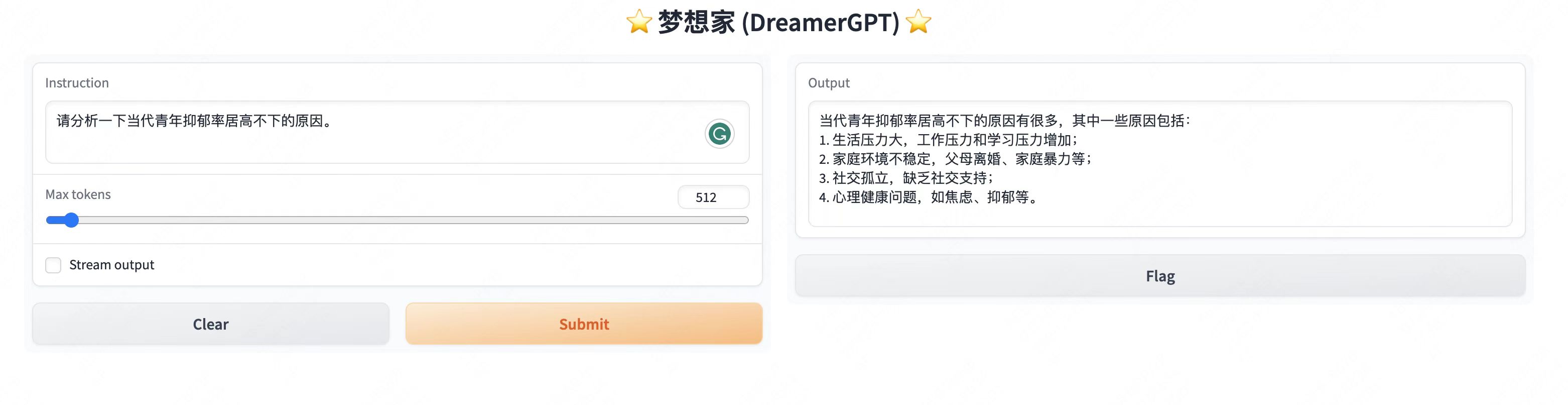
 2. Neuestes Update
2. Neuestes Update  [17.06.2023] Update V0.2-Version: LLaMa Firefly-Version für inkrementelles Training, BLOOM-LoRA-Version (
[17.06.2023] Update V0.2-Version: LLaMa Firefly-Version für inkrementelles Training, BLOOM-LoRA-Version ( finetune_bloom.py , generate_bloom.py ).
[23.04.2023] Offizielles chinesisches Open-Source-Kommando zur Feinabstimmung des großen Dreamer-Modells (DreamerGPT) , das derzeit das Download-Erlebnis der Version V0.1 bietet
Bestehende Modelle (kontinuierliches inkrementelles Training, weitere Modelle müssen aktualisiert werden):
| Modellname | Trainingsdaten = | Gewicht herunterladen |
|---|---|---|
| V0.2 | --- | --- |
| D13b-3-3 | D13b-2-3 + Glühwürmchenzug-1 | [Umarmendes Gesicht] |
| D7b-5-1 | D7b-4-1 + Glühwürmchen-Zug-1 | [Umarmendes Gesicht] |
| V0.1 | --- | --- |
| D13b-1-3-1 | Chinese-alpaca-lora-13b-hot start + COIG-part1, COIG-translate + PsyQA-5 | [Google Drive] [HuggingFace] |
| D13b-2-2-2 | Chinese-alpaca-lora-13b-hot start + firefly-train-0 + COIG-part1, COIG-translate | [Google Drive] [HuggingFace] |
| D13b-2-3 | Chinese-alpaca-lora-13b-hot start + firefly-train-0 + COIG-part1, COIG-translate + PsyQA-5 | [Google Drive] [HuggingFace] |
| D7b-4-1 | Chinese-alpaca-lora-7b-hotstart+firefly-train-0 | [Google Drive] [HuggingFace] |
Vorschau auf die Modellbewertung
 3. Modell- und Datenvorbereitung
3. Modell- und DatenvorbereitungModellgewicht herunterladen:
Die Daten werden einheitlich im folgenden JSON-Format verarbeitet:
{
" instruction " : " ... " ,
" input " : " ... " ,
" output " : " ... "
}Skript zum Herunterladen und Vorverarbeiten von Daten:
| Daten | Typ |
|---|---|
| Alpaka-GPT4 | Englisch |
| Firefly (in mehrere Kopien vorverarbeitet, Formatausrichtung) | chinesisch |
| COIG | Chinesisch, Code, Chinesisch und Englisch |
| PsyQA (in mehreren Kopien vorverarbeitet, Format ausgerichtet) | Chinesische psychologische Beratung |
| BELLE | chinesisch |
| Fries | Chinesisches Gespräch |
| Couplets (in mehreren Kopien vorverarbeitet, Format ausgerichtet) | chinesisch |
Hinweis: Die Daten stammen von der Open-Source-Community und können über Links abgerufen werden.
 4. Trainingscode und Skripte
4. Trainingscode und SkripteCode- und Skripteinführung:
finetune.py : Anweisungen zur Feinabstimmung des Hotstart-/inkrementellen Trainingscodesgenerate.py : Inferenz-/Testcodescripts/ : Skripte ausführenscripts/rerun-2-alpaca-13b-2.sh , Erläuterungen zu den einzelnen Parametern finden Sie scripts/README.md .  5. Anwendung
5. AnwendungEinzelheiten und verwandte Fragen finden Sie bei Alpaca-LoRA.
pip install -r requirements.txtGewichtsfusion (am Beispiel von Alpaca-Lora-13b):
cd scripts/
bash merge-13b-alpaca.shParameterbedeutung (bitte ändern Sie den entsprechenden Pfad selbst):
--base_model , Lama-Originalgewicht--lora_model , chinesisches-Lama/Alpaka-Lora-Gewicht--output_dir , Pfad zur Ausgabe der FusionsgewichteNehmen Sie den folgenden Trainingsprozess als Beispiel, um das laufende Skript zu zeigen.
| Start | f1 | f2 | f3 |
|---|---|---|---|
| Chinese-alpaca-lora-13b-hot start, Versuchsnummer: 2 | Daten: firefly-train-0 | Daten: COIG-Teil1, COIG-Übersetzung | Daten: PsyQA-5 |
cd scripts/
# 热启动f1
bash run-2-alpaca-13b-1.sh
# 增量训练f2
bash rerun-2-alpaca-13b-2.sh
bash rerun-2-alpaca-13b-2-2.sh
# 增量训练f3
bash rerun-2-alpaca-13b-3.shErläuterung wichtiger Parameter (bitte ändern Sie die entsprechenden Pfade selbst):
--resume_from_checkpoint '前一次执行的LoRA权重路径'--train_on_inputs False--val_set_size 2000 Wenn der Datensatz selbst relativ klein ist, kann er entsprechend reduziert werden, z. B. 500, 200Beachten Sie, dass Sie 5.3 ignorieren und direkt mit 5.4 fortfahren können, wenn Sie die fein abgestimmten Gewichte für die Inferenz direkt herunterladen möchten.
Ich möchte zum Beispiel die fein abgestimmten Ergebnisse von rerun-2-alpaca-13b-2.sh auswerten:
1. Interaktion mit der Webversion:
cd scripts/
bash generate-2-alpaca-13b-2.sh2. Batch-Inferenz und Ergebnisse speichern:
cd scripts/
bash save-generate-2-alpaca-13b-2.shErläuterung wichtiger Parameter (bitte ändern Sie die entsprechenden Pfade selbst):
--is_ui False : Unabhängig davon, ob es sich um eine Webversion handelt, ist der Standardwert True--test_input_path 'xxx.json' : Pfad der Eingabeanweisungtest.json im entsprechenden LoRA-Gewichtsverzeichnis gespeichert.  6. Bewertungsbericht
6. Bewertungsbericht Derzeit gibt es 8 Arten von Testaufgaben in den Bewertungsbeispielen (numerische Ethik und zu bewertender Duolun-Dialog), jede Kategorie hat 10 Beispiele, und die 8-Bit-quantifizierte Version wird gemäß der Schnittstelle mit GPT-4/GPT 3.5 bewertet ( (Die nicht quantifizierte Version hat eine höhere Punktzahl.) Jede Probe wird in einem Bereich von 0 bis 10 bewertet. Evaluierungsbeispiele finden Sie unter test_data/ .
以下是五个类似 ChatGPT 的系统的输出。请以 10 分制为每一项打分,并给出解释以证明您的分数。输出结果格式为:System 分数;System 解释。
Prompt:xxxx。
答案:
System1:xxxx。
System2:xxxx。
System3:xxxx。
System4:xxxx。
System5:xxxx。Hinweis: Die Bewertung dient nur als Referenz (im Vergleich zu GPT 3.5). Die Bewertung von GPT 4 ist genauer und referenzieller.
| Testaufgaben | Detailliertes Beispiel | Anzahl der Proben | D13b-1-3-1 | D13b-2-2-2 | D13b-2-3 | D7b-4-1 | ChatGPT |
|---|---|---|---|---|---|---|---|
| Gesamtpunktzahl für jedes Element | --- | 80 | 100 | 100 | 100 | 100 | 100 |
| Wissenswertes | 01qa.json | 10 | 80* | 78 | 78 | 68 | 95 |
| übersetzen | 02translate.json | 10 | 77* | 77* | 77* | 64 | 86 |
| Textgenerierung | 03generate.json | 10 | 56 | 65* | 55 | 61 | 91 |
| Stimmungsanalyse | 04analyse.json | 10 | 91 | 91 | 91 | 88* | 88* |
| Leseverständnis | 05understanding.json | 10 | 74* | 74* | 74* | 76,5 | 96,5 |
| Chinesische Merkmale | 06chinese.json | 10 | 69* | 69* | 69* | 43 | 86 |
| Codegenerierung | 07code.json | 10 | 62* | 62* | 62* | 57 | 96 |
| Ethik, Antwortverweigerung | 08alignment.json | 10 | 87* | 87* | 87* | 71 | 95,5 |
| mathematisches Denken | (zu bewerten) | -- | -- | -- | -- | -- | -- |
| Mehrere Dialogrunden | (zu bewerten) | -- | -- | -- | -- | -- | -- |
| Testaufgaben | Detailliertes Beispiel | Anzahl der Proben | D13b-1-3-1 | D13b-2-2-2 | D13b-2-3 | D7b-4-1 | ChatGPT |
|---|---|---|---|---|---|---|---|
| Gesamtpunktzahl für jedes Element | --- | 80 | 100 | 100 | 100 | 100 | 100 |
| Wissenswertes | 01qa.json | 10 | 65 | 64 | 63 | 67* | 89 |
| übersetzen | 02translate.json | 10 | 79 | 81 | 82 | 89* | 91 |
| Textgenerierung | 03generate.json | 10 | 65 | 73* | 63 | 71 | 92 |
| Stimmungsanalyse | 04analyse.json | 10 | 88* | 91 | 88* | 85 | 71 |
| Leseverständnis | 05understanding.json | 10 | 75 | 77 | 76 | 85* | 91 |
| Chinesische Merkmale | 06chinese.json | 10 | 82* | 83 | 82* | 40 | 68 |
| Codegenerierung | 07code.json | 10 | 72 | 74 | 75* | 73 | 96 |
| Ethik, Antwortverweigerung | 08alignment.json | 10 | 71* | 70 | 67 | 71* | 94 |
| mathematisches Denken | (zu bewerten) | -- | -- | -- | -- | -- | -- |
| Mehrere Dialogrunden | (zu bewerten) | -- | -- | -- | -- | -- | -- |
Insgesamt weist das Modell eine gute Leistung in den Bereichen Übersetzung , Stimmungsanalyse , Leseverständnis usw. auf.
Zwei Personen punkteten manuell und bildeten dann den Durchschnitt.
| Testaufgaben | Detailliertes Beispiel | Anzahl der Proben | D13b-1-3-1 | D13b-2-2-2 | D13b-2-3 | D7b-4-1 | ChatGPT |
|---|---|---|---|---|---|---|---|
| Gesamtpunktzahl für jedes Element | --- | 80 | 100 | 100 | 100 | 100 | 100 |
| Wissenswertes | 01qa.json | 10 | 83* | 82 | 82 | 69,75 | 96,25 |
| übersetzen | 02translate.json | 10 | 76,5* | 76,5* | 76,5* | 62,5 | 84 |
| Textgenerierung | 03generate.json | 10 | 44 | 51,5* | 43 | 47 | 81,5 |
| Stimmungsanalyse | 04analyse.json | 10 | 89* | 89* | 89* | 85,5 | 91 |
| Leseverständnis | 05understanding.json | 10 | 69* | 69* | 69* | 75,75 | 96 |
| Chinesische Merkmale | 06chinese.json | 10 | 55* | 55* | 55* | 37,5 | 87,5 |
| Codegenerierung | 07code.json | 10 | 61,5* | 61,5* | 61,5* | 57 | 88,5 |
| Ethik, Antwortverweigerung | 08alignment.json | 10 | 84* | 84* | 84* | 70 | 95,5 |
| Numerische Ethik | (zu bewerten) | -- | -- | -- | -- | -- | -- |
| Mehrere Dialogrunden | (zu bewerten) | -- | -- | -- | -- | -- | -- |
 7. Inhalt der nächsten Versionsaktualisierung
7. Inhalt der nächsten VersionsaktualisierungTODO-Liste:
 Einschränkungen, Nutzungsbeschränkungen und Haftungsausschlüsse
Einschränkungen, Nutzungsbeschränkungen und HaftungsausschlüsseDas auf Basis aktueller Daten und Basismodelle trainierte SFT-Modell weist hinsichtlich der Wirksamkeit noch folgende Probleme auf:
Sachliche Anweisungen können zu falschen Antworten führen, die den Tatsachen widersprechen.
Schädliche Anweisungen können nicht richtig identifiziert werden, was zu diskriminierenden, schädlichen und unethischen Bemerkungen führen kann.
Die Fähigkeiten des Modells müssen in einigen Szenarien, die Argumentation, Codierung, mehrere Dialogrunden usw. umfassen, noch verbessert werden.
Aufgrund der Einschränkungen des oben genannten Modells verlangen wir, dass der Inhalt dieses Projekts und die daraus resultierenden Derivate nur für akademische Forschungszwecke verwendet werden dürfen und nicht für kommerzielle Zwecke oder Zwecke verwendet werden dürfen, die der Gesellschaft Schaden zufügen. Der Projektentwickler übernimmt keinerlei Schäden, Verluste oder rechtliche Haftung, die durch die Nutzung dieses Projekts entstehen (einschließlich, aber nicht beschränkt auf Daten, Modelle, Codes usw.).
 Zitat
ZitatWenn Sie den Code, die Daten oder Modelle dieses Projekts verwenden, zitieren Sie bitte dieses Projekt.
@misc{DreamerGPT,
author = {Hao Xu, Huixuan Chi, Yuanchen Bei and Danyang Liu},
title = {DreamerGPT: Chinese Instruction-tuning for Large Language Model.},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/DreamerGPT/DreamerGPT}},
}
 Kontaktieren Sie uns
Kontaktieren Sie unsEs gibt noch viele Mängel in diesem Projekt. Bitte geben Sie uns Ihre Anregungen und Fragen und wir werden unser Bestes geben, um dieses Projekt zu verbessern.
E-Mail: [email protected]


