datalens
1.0.0
Dies ist ein persönliches Experiment, bei dem LLMs verwendet werden, um unstrukturierte Jobdaten anhand benutzerdefinierter Kriterien zu bewerten. Herkömmliche Jobsuchplattformen stützen sich auf starre Filtersysteme, doch vielen Nutzern fehlen solche konkreten Kriterien. Mit Datalens können Sie Ihre Präferenzen auf natürlichere Weise definieren und dann jede Stellenausschreibung nach Relevanz bewerten.
Einige Kriterien sind möglicherweise wichtiger als andere, daher werden „Muss-Kriterien“ doppelt so stark gewichtet wie normale Kriterien.
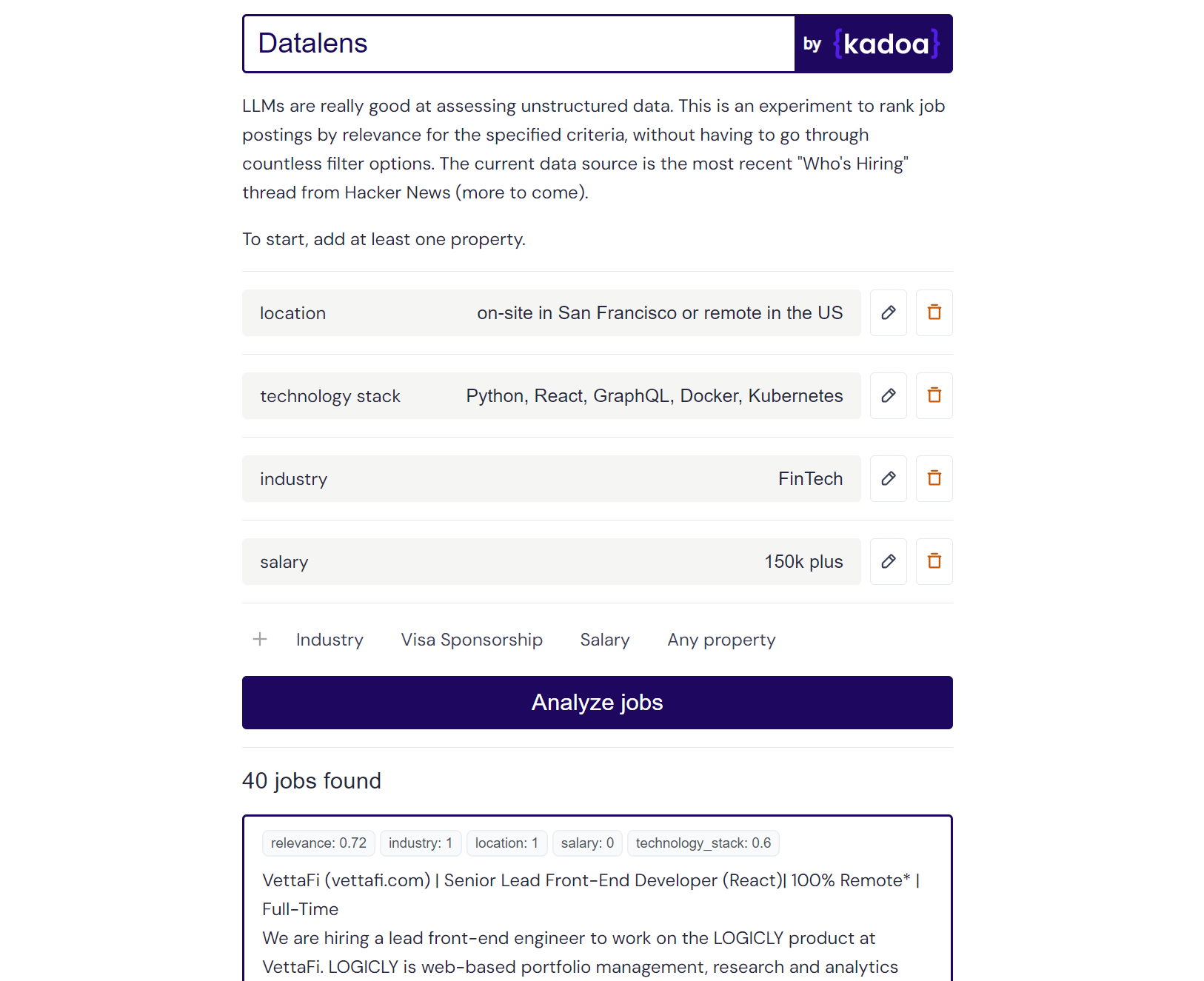
Beispielergebnis für Claude-2:
Here are the scores for the provided job posting:
{
"location": 1.0,
"technology_stack": 0.8,
"industry": 0.0,
"salary": 0.0
}
Explanation:
- Location is a perfect match (1.0) as the role is in San Francisco which meets the "on-site in San Francisco or remote in the US" criteria.
- Technology stack is a partial match (0.8) as Python, React, and Kubernetes are listed which meet some but not all of the specified technologies.
- Industry is no match (0.0) as the company is in the creative/AI space.
- Salary is no match (0.0) as the posting does not mention the salary range. However, the full compensation is variable. Assigned a score of 0.6.
Sie können jede beliebige Jobdatenquelle hinzufügen. Ich habe es mit dem aktuellsten „Who's Hiring“-Thread von Hacker News vorkonfiguriert, aber Sie können Ihre eigenen Quellen hinzufügen.
Fügen Sie neue Jobquellen hinzu, indem Sie „sources_config.json“ aktualisieren. Beispiel:
{
"name": "SourceName",
"endpoint": "API_ENDPOINT",
"handler": "handler_function_name",
"headers": {
"x-api-key": "YOUR_API_KEY"
}
}
Ich habe mein eigenes Tool Kadoa verwendet, um die Jobdaten von den Unternehmensseiten abzurufen, Sie können aber auch jede andere herkömmliche Scraping-Methode verwenden.
Hier sind einige vorgefertigte öffentliche Endpunkte zum Abrufen aller Stellenausschreibungen dieser Unternehmen (täglich aktualisiert):
{
"name": "Anduril",
"endpoint": "https://services.kadoa.com/jobs/pages/64e74d936addab49669d6319?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
},
{
"name": "Tesla",
"endpoint": "https://services.kadoa.com/jobs/pages/64eb63f6b91574b2149c0cae?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
},
{
"name": "SpaceX",
"endpoint": "https://services.kadoa.com/jobs/pages/64eb5f1b7350bf774df35f7f?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
}
Lassen Sie mich wissen, ob weitere Unternehmen hinzugefügt werden sollten. Gerne gewähren wir Ihnen auch einen Testzugang zu Kadoa.
Die Relevanzbewertung funktioniert am besten mit gpt-4-0613 , das granulare Bewertungen zwischen 0 und 1 zurückgibt. claude-2 funktioniert auch ganz gut, wenn Sie Zugriff darauf haben. gpt-3.5-turbo-0613 kann verwendet werden, gibt jedoch häufig binäre Bewertungen von 0 oder 1 für Kriterien zurück, da die Nuancen zur Unterscheidung zwischen teilweisen und vollständigen Übereinstimmungen fehlen.
Aus Kostengründen ist das Standardmodell gpt-3.5-turbo-0613 . Sie können von GPT zu Claude wechseln, indem Sie use_claude durch use_openai ersetzen.
Die kontinuierliche Ausführung dieses Skripts kann zu einer hohen API-Nutzung führen. Gehen Sie daher bitte verantwortungsbewusst damit um. Ich protokolliere die Kosten für jeden GPT-Anruf.
Um die App auszuführen, benötigen Sie:
Kopieren Sie die Datei .env.example und füllen Sie sie aus.
Führen Sie den Flask-Server aus:
cd server
cp .env.example .env
pip install -r requirements.txt
py main
Navigieren Sie zum Client-Verzeichnis und installieren Sie Knotenabhängigkeiten:
cd client
npm install
Führen Sie den Next.js-Client aus:
cd client
npm run dev


