Indian LawyerGPT
1.0.0
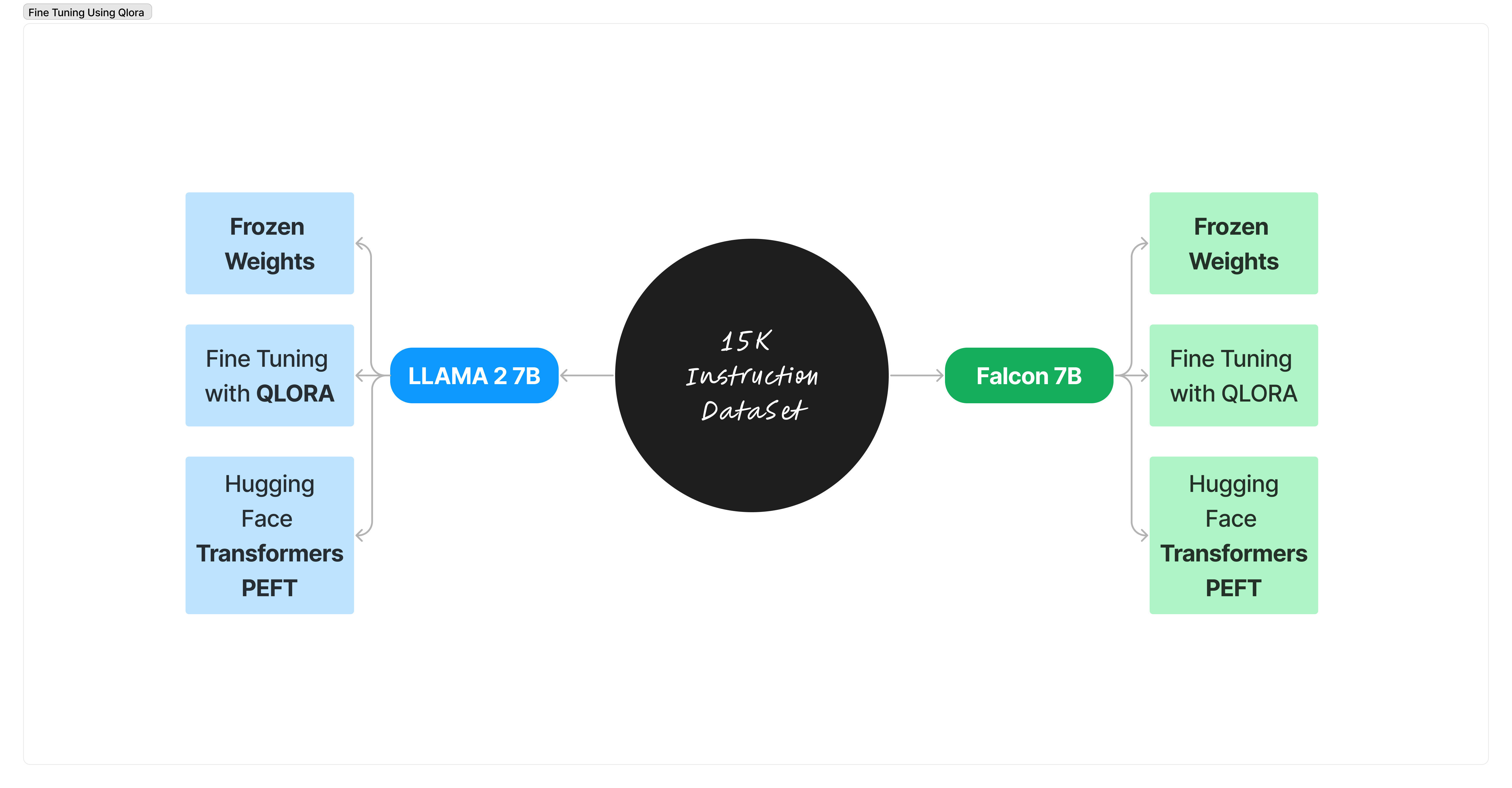
Willkommen zu unserem spannenden Projekt, bei dem wir zwei hochmoderne Sprachmodelle, Falcon-7B und LLAMA 2, anpassen, um das indische Recht zu beherrschen.
Unser Abenteuer begann mit bescheidenen 150 Fragen und Antworten zum indischen Recht. Jetzt stürmen wir mit einem beeindruckenden Datensatz von 3300 Anweisungen voran! Dieses KI-Rechtsprojekt kombiniert:

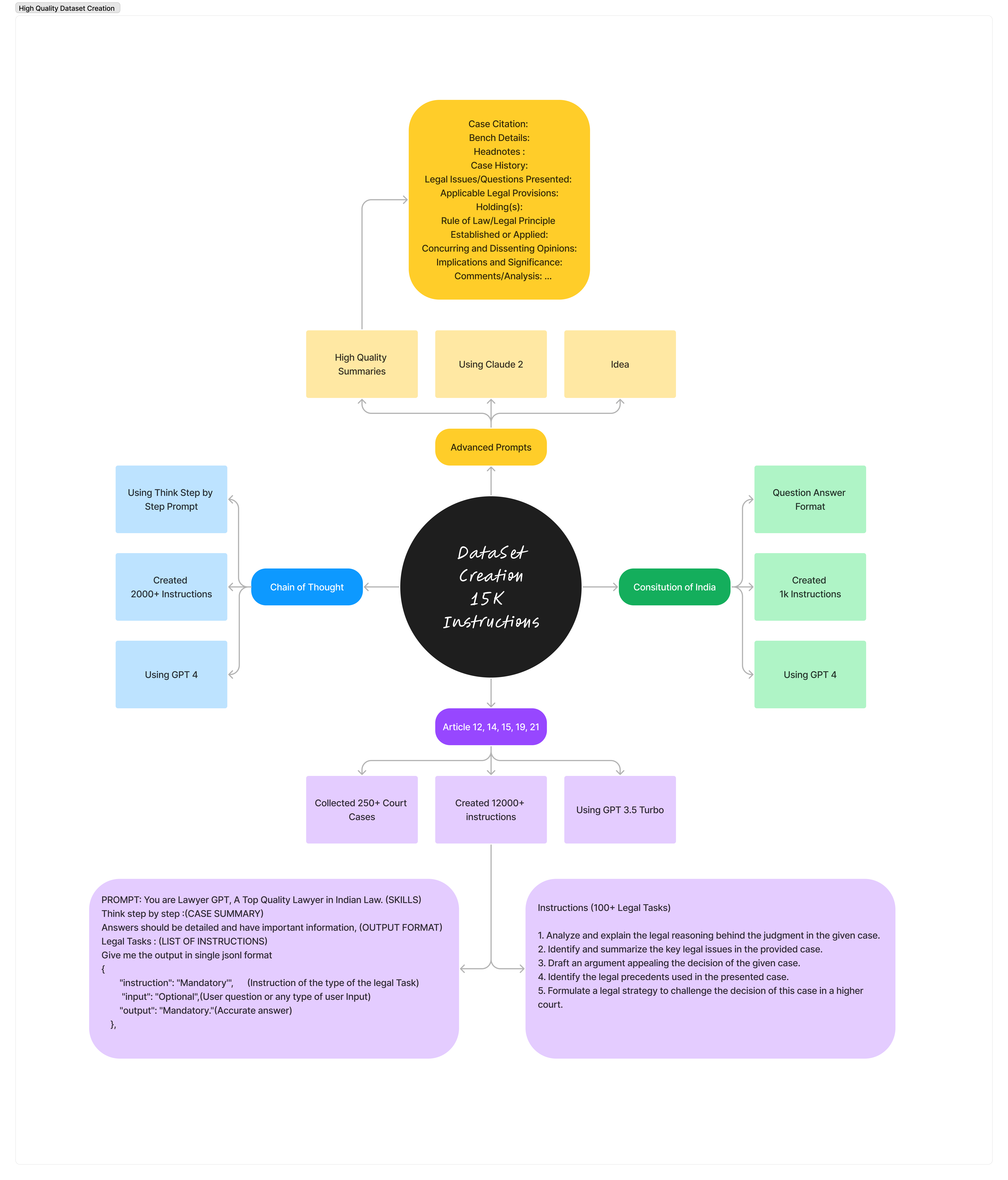
Unser Datensatz ist mit vier Hauptfunktionen ausgestattet: instruction , input , output und prompt . Entwickelt, um unsere Modelle zu KI-Rechtsexperten zu machen! Datensatz zum Hugging Face: https://huggingface.co/datasets/nisaar/Constitution_Of_India_Instruction_Set https://huggingface.co/datasets/nisaar/Articles_Constitution_3300_Instruction_Set https://huggingface.co/datasets/nisaar/LLAMA2_Legal_Dataset_4.4k_Instructions
Erhalten Sie mit TensorBoard einen Platz in der ersten Reihe und verfolgen Sie den Trainingsfortschritt. Starten Sie es, navigieren Sie zum bereitgestellten Localhost-Link und erleben Sie, wie die Modelle Folgendes lernen:


