multimedia gpt
1.0.0
Multimedia-GPT verbindet Ihr OpenAI-GPT mit Bild und Audio. Sie können jetzt Bilder, Audioaufnahmen und PDF-Dokumente mit Ihrem OpenAI-API-Schlüssel senden und eine Antwort sowohl im Text- als auch im Bildformat erhalten. Wir fügen derzeit Unterstützung für Videos hinzu. Möglich wird alles durch einen Prompt-Manager, der auf Microsoft Visual ChatGPT basiert und darauf basiert.
Zusätzlich zu allen in Microsoft Visual ChatGPT erwähnten Vision Foundation-Modellen unterstützt Multimedia GPT OpenAI Whisper und OpenAI DALLE! Das bedeutet, dass Sie für die Spracherkennung und Bilderzeugung keine eigenen GPUs mehr benötigen (obwohl Sie dies weiterhin tun können!)
Das Basis-Chat-Modell kann als jedes OpenAI-LLM konfiguriert werden, einschließlich ChatGPT und GPT-4. Wir verwenden standardmäßig text-davinci-003 .
Sie können dieses Projekt gerne forken und Modelle hinzufügen, die für Ihren eigenen Anwendungsfall geeignet sind. Eine einfache Möglichkeit, dies zu tun, ist llama_index. Sie müssen in model.py eine neue Klasse für Ihr Modell erstellen und in multimedia_gpt.py eine Runner-Methode run_<model_name> hinzufügen. Ein Beispiel finden Sie unter run_pdf .
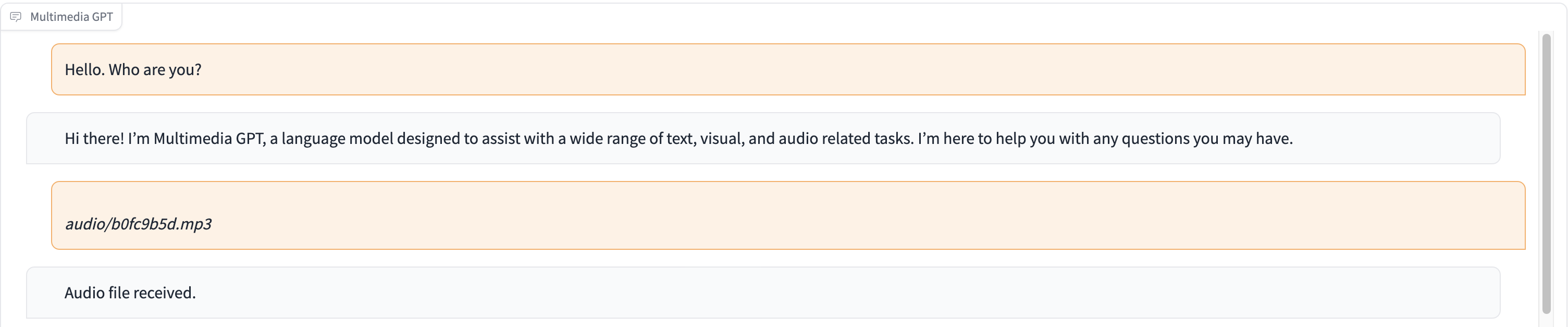
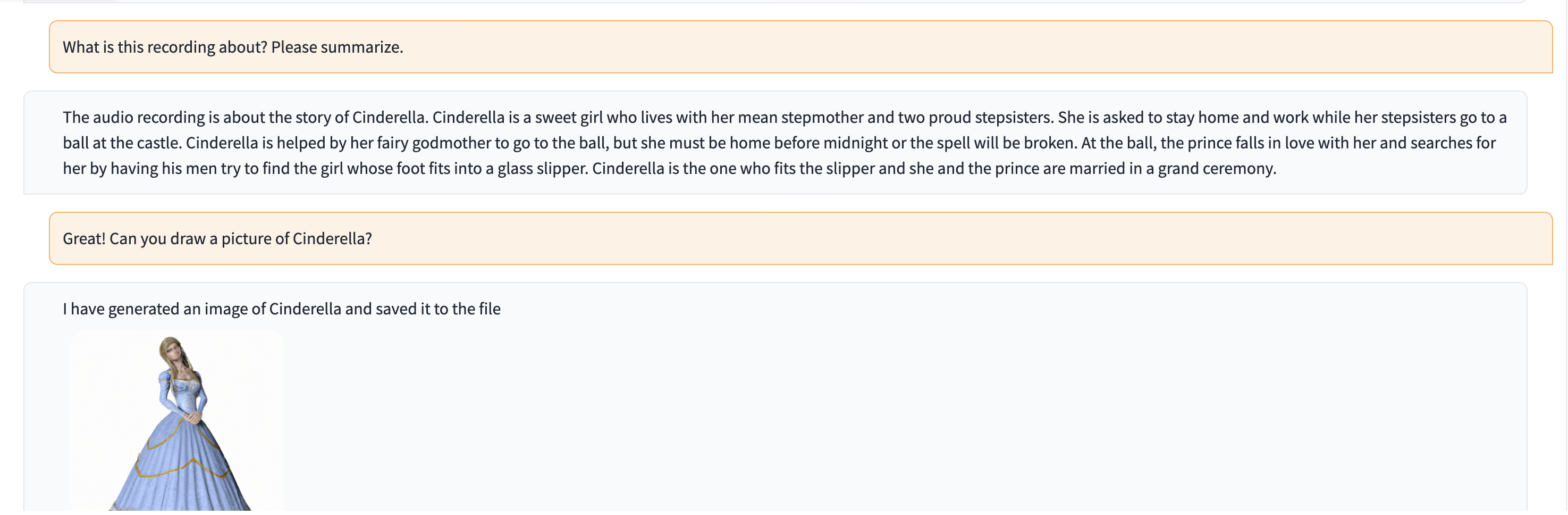
In dieser Demo wird ChatGPT mit einer Aufnahme einer Person gefüttert, die die Geschichte von Aschenputtel erzählt.
# Clone this repository
git clone https://github.com/fengyuli2002/multimedia-gpt
cd multimedia-gpt
# Prepare a conda environment
conda create -n multimedia-gpt python=3.8
conda activate multimedia-gptt
pip install -r requirements.txt
# prepare your private OpenAI key (for Linux / MacOS)
echo " export OPENAI_API_KEY='yourkey' " >> ~ /.zshrc
# prepare your private OpenAI key (for Windows)
setx OPENAI_API_KEY “ < yourkey > ”
# Start Multimedia GPT!
# You can specify the GPU/CPU assignment by "--load", the parameter indicates which foundation models to use and
# where it will be loaded to. The model and device are separated by '_', different models are separated by ','.
# The available Visual Foundation Models can be found in models.py
# For example, if you want to load ImageCaptioning to cuda:0 and whisper to cpu
# (whisper runs remotely, so it doesn't matter where it is loaded to)
# You can use: "ImageCaptioning_cuda:0,Whisper_cpu"
# Don't have GPUs? No worry, you can run DALLE and Whisper on cloud using your API key!
python multimedia_gpt.py --load ImageCaptioning_cpu,DALLE_cpu,Whisper_cpu
# Additionally, you can configure the which OpenAI LLM to use by the "--llm" tag, such as
python multimedia_gpt.py --llm text-davinci-003
# The default is gpt-3.5-turbo (ChatGPT). Dieses Projekt ist eine experimentelle Arbeit und wird nicht in einer Produktionsumgebung bereitgestellt. Unser Ziel ist es, die Kraft der Aufforderung zu erforschen.


