SwiftInfer
1.0.0
Streaming-LLM ist eine Technik zur Unterstützung einer unendlichen Eingabelänge für die LLM-Inferenz. Es nutzt die Aufmerksamkeitssenke, um zu verhindern, dass das Modell zusammenbricht, wenn sich das Aufmerksamkeitsfenster verschiebt. Die ursprüngliche Arbeit ist in PyTorch implementiert. Wir bieten SwiftInfer an, eine TensorRT-Implementierung, um StreamingLLM produktionstauglicher zu machen. Unsere Implementierung basierte auf dem kürzlich veröffentlichten TensorRT-LLM- Projekt.
Wir verwenden die API in TensorRT-LLM, um das Modell zu erstellen und Inferenz auszuführen. Da die API von TensorRT-LLM nicht stabil ist und sich schnell ändert, binden wir unsere Implementierung an den Commit 42af740db51d6f11442fd5509ef745a4c043ce51 , dessen Version v0.6.0 ist. Wir können dieses Repository aktualisieren, wenn die APIs von TensorRT-LLM stabiler werden.
Wenn Sie TensorRT-LLM V0.6.0 erstellt haben, führen Sie einfach Folgendes aus:
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
pip install .Andernfalls sollten Sie zuerst TensorRT-LLM installieren.
Wenn Sie Docker verwenden, können Sie der TensorRT-LLM-Installation folgen, um TensorRT-LLM V0.6.0 zu installieren.
Mit Docker können Sie SwiftInfer installieren, indem Sie einfach Folgendes ausführen:
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
pip install . Wenn Sie Docker nicht verwenden, stellen wir ein Skript zur automatischen Installation von TensorRT-LLM bereit.
Voraussetzungen
Bitte stellen Sie sicher, dass Sie die folgenden Pakete installiert haben:
Stellen Sie sicher, dass die Version von TensorRT >= 9.1.0 und das CUDA-Toolkit >= 12.2 ist.
So installieren Sie tensorrt:
ARCH= $( uname -m )
if [ " $ARCH " = " arm64 " ] ; then ARCH= " aarch64 " ; fi
if [ " $ARCH " = " amd64 " ] ; then ARCH= " x86_64 " ; fi
if [ " $ARCH " = " aarch64 " ] ; then OS= " ubuntu-22.04 " ; else OS= " linux " ; fi
wget https://developer.nvidia.com/downloads/compute/machine-learning/tensorrt/secure/9.1.0/tars/tensorrt-9.1.0.4. $OS . $ARCH -gnu.cuda-12.2.tar.gz
tar xzvf tensorrt-9.1.0.4.linux.x86_64-gnu.cuda-12.2.tar.gz
PY_VERSION= $( python -c ' import sys; print(".".join(map(str, sys.version_info[0:2]))) ' )
PARSED_PY_VERSION= $( echo " ${PY_VERSION // . / } " )
pip install TensorRT-9.1.0.4/python/tensorrt- * -cp ${PARSED_PY_VERSION} - * .whl
export TRT_ROOT= $( realpath TensorRT-9.1.0.4 )Um nccl herunterzuladen, folgen Sie der NCCL-Downloadseite.
Um cudnn herunterzuladen, folgen Sie der cuDNN-Downloadseite.
Befehle
Bevor Sie die folgenden Befehle ausführen, stellen Sie bitte sicher, dass Sie nvcc richtig eingestellt haben. Um es zu überprüfen, führen Sie Folgendes aus:
nvcc --versionFühren Sie Folgendes aus, um TensorRT-LLM und SwiftInfer zu installieren:
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
TRT_ROOT=xxx NCCL_ROOT=xxx CUDNN_ROOT=xxx pip install . Um das Llama-Beispiel auszuführen, müssen Sie zunächst das Hugging Face-Repository für das Modell meta-llama/Llama-2-7b-chat-hf oder andere Llama-basierte Varianten wie lmsys/vicuna-7b-v1.3 klonen. Anschließend können Sie den folgenden Befehl ausführen, um die TensorRT-Engine zu erstellen. Sie müssen <model-dir> durch den tatsächlichen Pfad zum Llama-Modell ersetzen.
cd examples/llama
python build.py
--model_dir < model-dir >
--dtype float16
--enable_context_fmha
--use_gemm_plugin float16
--max_input_len 2048
--max_output_len 1024
--output_dir ./output/7B-streaming-8k-1k-4-2000/trt_engines/fp16/1-gpu/
--max_batch_size 1Als nächstes müssen Sie die von LMSYS-FastChat bereitgestellten MT-Bench-Daten herunterladen.
mkdir mt_bench_data
wget -P ./mt_bench_data https://raw.githubusercontent.com/lm-sys/FastChat/main/fastchat/llm_judge/data/mt_bench/question.jsonlSchließlich können Sie das Llama-Beispiel mit dem folgenden Befehl ausführen.
❗️❗️❗️ Bitte beachten Sie vorher Folgendes:
only_n_first wird verwendet, um die Anzahl der auszuwertenden Stichproben zu steuern. Wenn Sie alle Proben auswerten möchten, entfernen Sie bitte dieses Argument. python ../run_conversation.py
--max_input_length 2048
--max_output_len 1024
--tokenizer_dir < model-dir >
--engine_dir ./output/7B-streaming-8k-1k-4-2000/trt_engines/fp16/1-gpu/
--input_file ./mt_bench_data/question.jsonl
--streaming_llm_start_size 4
--only_n_first 5Sie sollten damit rechnen, dass die Generation wie folgt aussieht:
Wir haben unsere Implementierungen von Streaming-LLM mit der ursprünglichen PyTorch-Version verglichen. Der Benchmark-Befehl für unsere Implementierung ist im Abschnitt „Llama-Beispiel ausführen“ angegeben, während der für die ursprüngliche PyTorch-Implementierung im Ordner „torch_streamingllm“ enthalten ist. Die verwendete Hardware ist unten aufgeführt:
Die Ergebnisse (20 Gesprächsrunden) sind:
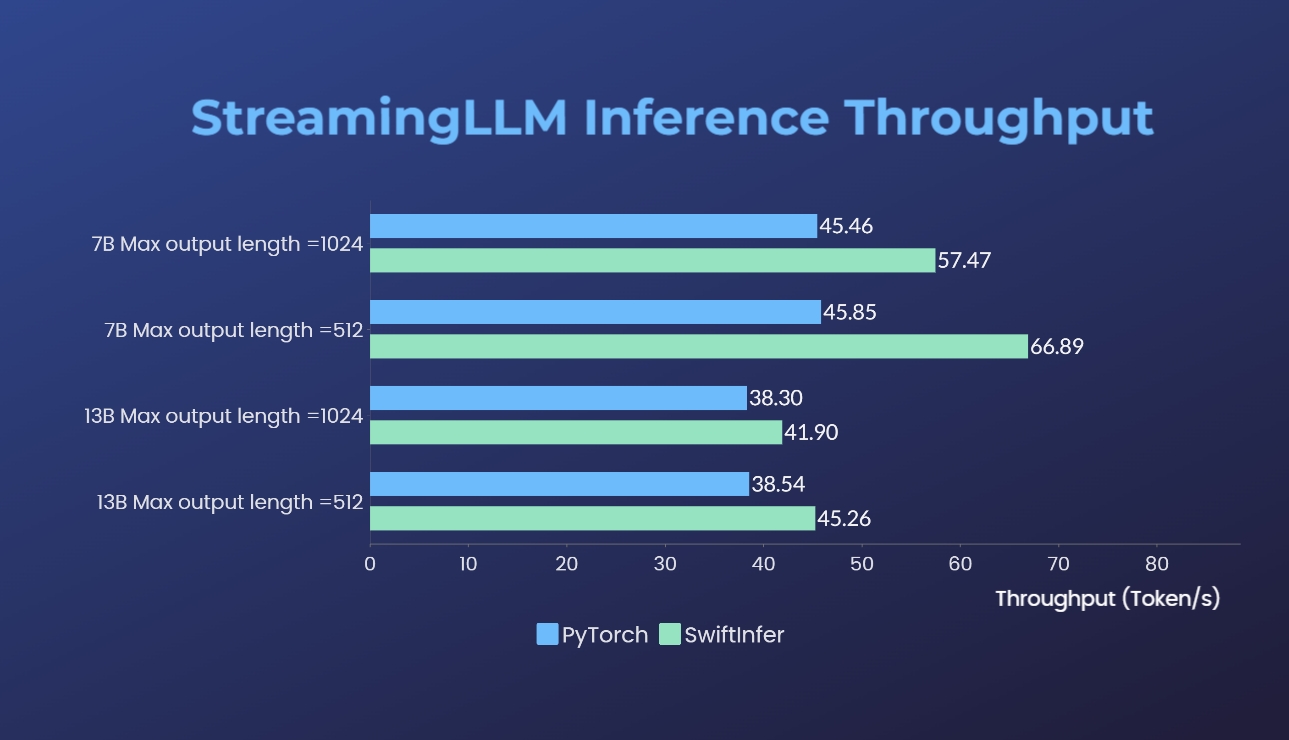
Wir arbeiten weiterhin an der weiteren Leistungsverbesserung und der Anpassung an die TensorRT V0.7.1-APIs. Wir stellen auch fest, dass TensorRT-LLM StreamingLLM in seinem Beispiel integriert hat, es scheint jedoch besser für die Generierung einzelner Texte als für Konversationen in mehreren Runden geeignet zu sein.
Diese Arbeit ist von Streaming-LLM inspiriert, um sie für die Produktion nutzbar zu machen. Während der Entwicklung haben wir auf die folgenden Materialien verwiesen und möchten ihre Bemühungen und ihren Beitrag zur Open-Source-Community und Wissenschaft würdigen.
Wenn Sie StreamingLLM und unsere TensorRT-Implementierung nützlich finden, zitieren Sie bitte unser Repository und die von Xiao et al. vorgeschlagene Originalarbeit. vom MIT Han Lab.
# our repository
# NOTE: the listed authors have equal contribution
@misc { streamingllmtrt2023 ,
title = { SwiftInfer } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/hpcaitech/SwiftInfer} } ,
}
# Xiao's original paper
@article { xiao2023streamingllm ,
title = { Efficient Streaming Language Models with Attention Sinks } ,
author = { Xiao, Guangxuan and Tian, Yuandong and Chen, Beidi and Han, Song and Lewis, Mike } ,
journal = { arXiv } ,
year = { 2023 }
}
# TensorRT-LLM repo
# as TensorRT-LLM team does not provide a bibtex
# please let us know if there is any change needed
@misc { trtllm2023 ,
title = { TensorRT-LLM } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/NVIDIA/TensorRT-LLM} } ,
}

