paxml
paxml release 1.4.0
Pax ist ein Framework zum Konfigurieren und Ausführen von Experimenten zum maschinellen Lernen auf Jax.
Eine ausführlichere Dokumentation zum Starten eines Cloud TPU-Projekts finden Sie auf dieser Seite. Der folgende Befehl reicht aus, um von einer Unternehmensmaschine aus eine Cloud TPU VM mit 8 Kernen zu erstellen.
export ZONE=us-central2-b
export VERSION=tpu-vm-v4-base
export PROJECT= < your-project >
export ACCELERATOR=v4-8
export TPU_NAME=paxml
# create a TPU VM
gcloud compute tpus tpu-vm create $TPU_NAME
--zone= $ZONE --version= $VERSION
--project= $PROJECT
--accelerator-type= $ACCELERATOR Wenn Sie TPU-Pod-Slices verwenden, lesen Sie bitte diese Anleitung. Führen Sie alle Befehle von einem lokalen Computer aus mit gcloud mit der Option --worker=all aus:
gcloud compute tpus tpu-vm ssh $TPU_NAME --zone= $ZONE
--worker=all --command= " <commmands> "In den folgenden Schnellstartabschnitten wird davon ausgegangen, dass Sie auf einer Single-Host-TPU ausgeführt werden, sodass Sie eine SSH-Verbindung zur VM herstellen und die Befehle dort ausführen können.
gcloud compute tpus tpu-vm ssh $TPU_NAME --zone= $ZONENach dem SSH-Versenden der VM können Sie die stabile Paxml-Version von PyPI oder die Entwicklungsversion von Github installieren.
Zur Installation der stabilen Version von PyPI (https://pypi.org/project/paxml/):
python3 -m pip install -U pip
python3 -m pip install paxml jax[tpu]
-f https://storage.googleapis.com/jax-releases/libtpu_releases.html Wenn Probleme mit transitiven Abhängigkeiten auftreten und Sie die native Cloud TPU VM-Umgebung verwenden, navigieren Sie bitte zum entsprechenden Release-Zweig rX.YZ und laden Sie paxml/pip_package/requirements.txt herunter. Diese Datei enthält die genauen Versionen aller transitiven Abhängigkeiten, die in der nativen Cloud TPU VM-Umgebung benötigt werden, in der wir die entsprechende Version erstellen/testen.
git clone -b rX.Y.Z https://github.com/google/paxml
pip install --no-deps -r paxml/paxml/pip_package/requirements.txtZur Installation der Entwicklungsversion von Github und zur einfacheren Bearbeitung des Codes:
# install the dev version of praxis first
git clone https://github.com/google/praxis
pip install -e praxis
git clone https://github.com/google/paxml
pip install -e paxml
pip install " jax[tpu] " -f https://storage.googleapis.com/jax-releases/libtpu_releases.html # example model using pjit (SPMD)
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.lm_cloud.LmCloudSpmd2BLimitSteps
--job_log_dir=gs:// < your-bucket >
# example model using pmap
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.lm_cloud.LmCloudTransformerAdamLimitSteps
--job_log_dir=gs:// < your-bucket >
--pmap_use_tensorstore=TrueBitte besuchen Sie unseren Dokumentenordner für Dokumentationen und Jupyter Notebook-Tutorials. Anweisungen zum Ausführen von Jupyter Notebooks auf einer Cloud TPU-VM finden Sie im folgenden Abschnitt.
Sie können die Beispielnotebooks in der TPU-VM ausführen, in der Sie gerade paxml installiert haben. ####Schritte zum Aktivieren eines Notebooks in einer v4-8
ssh in TPU VM mit Portweiterleitung gcloud compute tpus tpu-vm ssh $TPU_NAME --project=$PROJECT_NAME --zone=$ZONE --ssh-flag="-4 -L 8080:localhost:8080"
Installieren Sie das Jupyter-Notebook auf der TPU-VM und führen Sie ein Downgrade von Markupsafe durch
pip install notebook
pip install markupsafe==2.0.1
jupyter Pfad exportieren export PATH=/home/$USER/.local/bin:$PATH
scp die Beispiel-Notebooks auf Ihre TPU-VM gcloud compute tpus tpu-vm scp $TPU_NAME:<path inside TPU> <local path of the notebooks> --zone=$ZONE --project=$PROJECT
Starten Sie Jupyter Notebook von der TPU-VM aus und notieren Sie sich das von Jupyter Notebook jupyter notebook --no-browser --port=8080 generierte Token
Gehen Sie dann in Ihrem lokalen Browser zu: http://localhost:8080/ und geben Sie das bereitgestellte Token ein
Hinweis: Falls Sie ein zweites Notebook verwenden müssen, während das erste Notebook noch die TPUs belegt, können Sie pkill -9 python3 ausführen, um die TPUs freizugeben.
Hinweis: NVIDIA hat eine aktualisierte Version von Pax mit H100 FP8-Unterstützung und umfassenden GPU-Leistungsverbesserungen veröffentlicht. Weitere Details und Nutzungsanweisungen finden Sie im NVIDIA Rosetta-Repository.
Der Profile Guided Latency Estimator (PGLE)-Workflow misst die tatsächliche Laufzeit von Berechnungen und Kollektiven. Anschließend werden die Profilinformationen für eine bessere Planungsentscheidung an den XLA-Compiler zurückgegeben.
Der Profile Guided Latency Estimator kann manuell oder automatisch verwendet werden. Im automatischen Modus sammelt JAX Profilinformationen und kompiliert ein Modul in einem einzigen Lauf neu. Im manuellen Modus müssen Sie eine Aufgabe zweimal ausführen, das erste Mal zum Sammeln und Speichern von Profilen und das zweite Mal zum Kompilieren und Ausführen mit den bereitgestellten Daten.
Das automatische PGLE kann durch Festlegen der folgenden Umgebungsvariablen aktiviert werden:
XLA_FLAGS="--xla_gpu_enable_latency_hiding_scheduler=true"
JAX_ENABLE_PGLE=true
JAX_PGLE_PROFILING_RUNS=3
JAX_REMOVE_CUSTOM_PARTITIONING_PTR_FROM_CACHE_KEY=True
Optional JAX_PGLE_AGGREGATION_PERCENTILE=85
Oder im JAX kann dies wie folgt eingestellt werden:
import jax
from jax._src import config
with config.enable_pgle(True), config.pgle_profiling_runs(1):
# Run with the profiler collecting performance information.
train_step()
# Automatically re-compile with PGLE profile results
train_step()
...
Sie können die Anzahl der Wiederholungen steuern, die zum Sammeln von Profildaten verwendet werden, indem Sie JAX_PGLE_PROFILING_RUNS ändern. Eine Erhöhung dieses Parameters würde zu besseren Profilinformationen führen, aber auch die Anzahl nicht optimierter Trainingsschritte erhöhen.
Die Parameter JAX_REMOVE_CUSTOM_PARTITIONING_PTR_FROM_CACHE_KEY ermöglichen die Verwendung von Host-Rückrufen mit dem Auto-PGLE.
Das Verringern des Parameters JAX_PGLE_AGGREGATION_PERCENTILE kann hilfreich sein, wenn die Leistung zwischen den Schritten zu laut ist, um nicht relevante Kennzahlen herauszufiltern.
Achtung: Auto PGLE funktioniert nicht für vorkompilierte Module. Da JAX das Modul während der Ausführung neu kompilieren muss, funktioniert das Auto-PGLE weder für AoT noch im folgenden Fall:
import jax
from jax._src import config
train_step_compiled = train_step().lower().compile()
with config.enable_pgle(True), config.pgle_profiling_runs(1):
train_step_compiled()
# No effect since module was pre-compiled.
train_step_compiled()
Wenn Sie dennoch einen manuellen Profile Guided Latency Estimator verwenden möchten, ist der Workflow in XLA/GPU wie folgt:
Sie können dies tun, indem Sie Folgendes festlegen:
export XLA_FLAGS= " --xla_gpu_enable_latency_hiding_scheduler=true " import os
from etils import epath
import jax
from jax . experimental import profiler as exp_profiler
# Define your profile directory
profile_dir = 'gs://my_bucket/profile'
jax . profiler . start_trace ( profile_dir )
# run your workflow
# for i in range(10):
# train_step()
# Stop trace
jax . profiler . stop_trace ()
profile_dir = epath . Path ( profile_dir )
directories = profile_dir . glob ( 'plugins/profile/*/' )
directories = [ d for d in directories if d . is_dir ()]
rundir = directories [ - 1 ]
logging . info ( 'rundir: %s' , rundir )
# Post process the profile
fdo_profile = exp_profiler . get_profiled_instructions_proto ( os . fspath ( rundir ))
# Save the profile proto to a file.
dump_dir = rundir / 'profile.pb'
dump_dir . parent . mkdir ( parents = True , exist_ok = True )
dump_dir . write_bytes ( fdo_profile ) Nach diesem Schritt erhalten Sie eine Datei profile.pb unter dem im Code gedruckten rundir .
Sie müssen die Datei profile.pb an das Flag --xla_gpu_pgle_profile_file_or_directory_path übergeben.
export XLA_FLAGS= " --xla_gpu_enable_latency_hiding_scheduler=true --xla_gpu_pgle_profile_file_or_directory_path=/path/to/profile/profile.pb " Um die Protokollierung im XLA zu aktivieren und zu überprüfen, ob das Profil gut ist, legen Sie die Protokollierungsebene so fest, dass sie INFO enthält:
export TF_CPP_MIN_LOG_LEVEL=0Führen Sie den echten Workflow aus. Wenn Sie diese Protokolle im laufenden Protokoll gefunden haben, bedeutet dies, dass der Profiler im Planer zum Ausblenden der Latenz verwendet wird:
2023-07-21 16:09:43.551600: I external/xla/xla/service/gpu/gpu_hlo_schedule.cc:478] Using PGLE profile from /tmp/profile/plugins/profile/2023_07_20_18_29_30/profile.pb
2023-07-21 16:09:43.551741: I external/xla/xla/service/gpu/gpu_hlo_schedule.cc:573] Found profile, using profile guided latency estimator
Pax läuft auf Jax. Details zum Ausführen von Jax-Jobs auf Cloud TPU finden Sie hier. Details zum Ausführen von Jax-Jobs auf einem Cloud TPU-Pod finden Sie hier
Wenn Abhängigkeitsfehler auftreten, lesen Sie bitte die Datei requirements.txt im Zweig, der der stabilen Version entspricht, die Sie installieren. Verwenden Sie beispielsweise für die stabile Version 0.4.0 den Zweig r0.4.0 und sehen Sie sich die Datei „requirements.txt“ für die genauen Versionen der Abhängigkeiten an, die für die stabile Version verwendet werden.
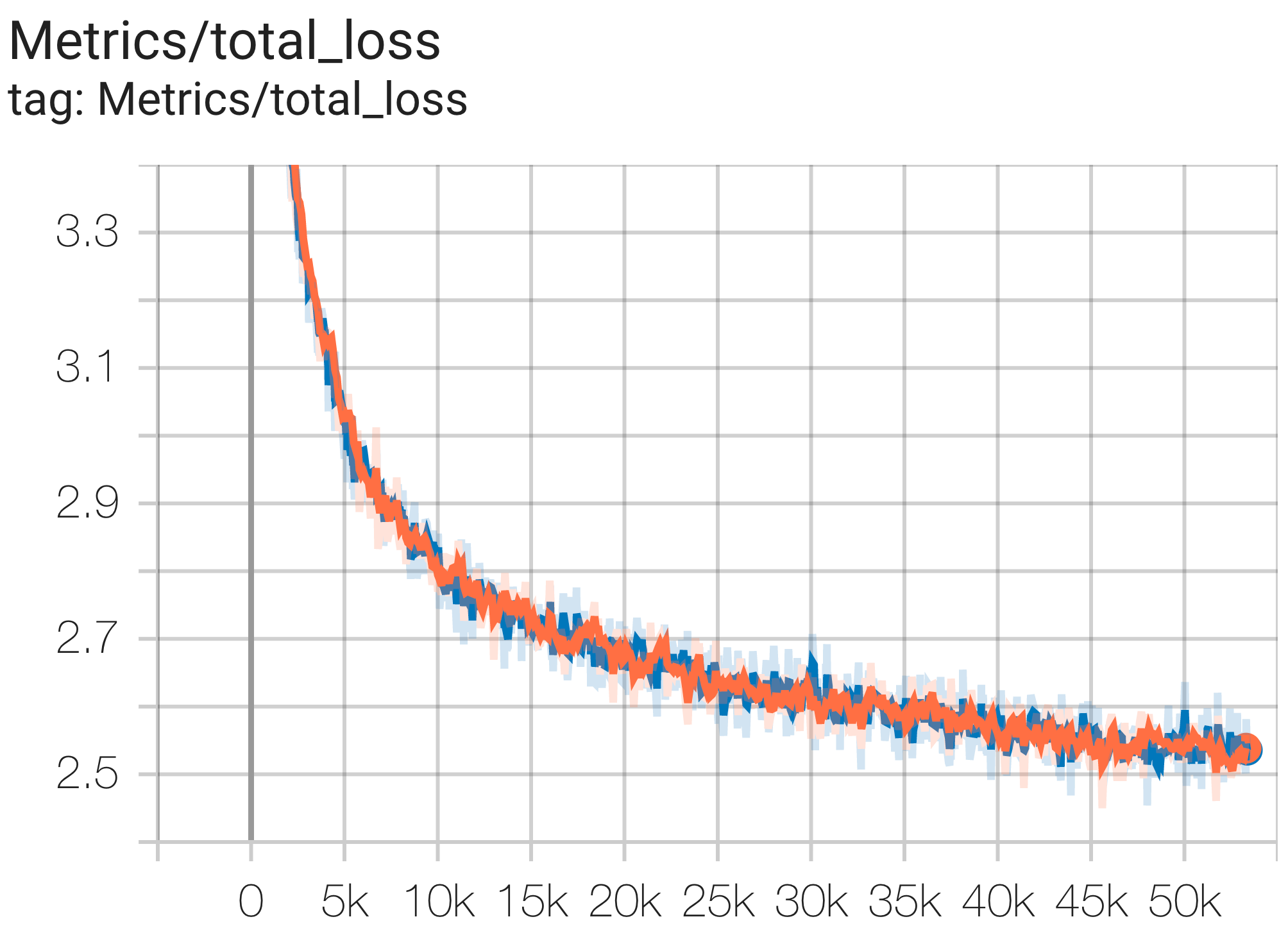
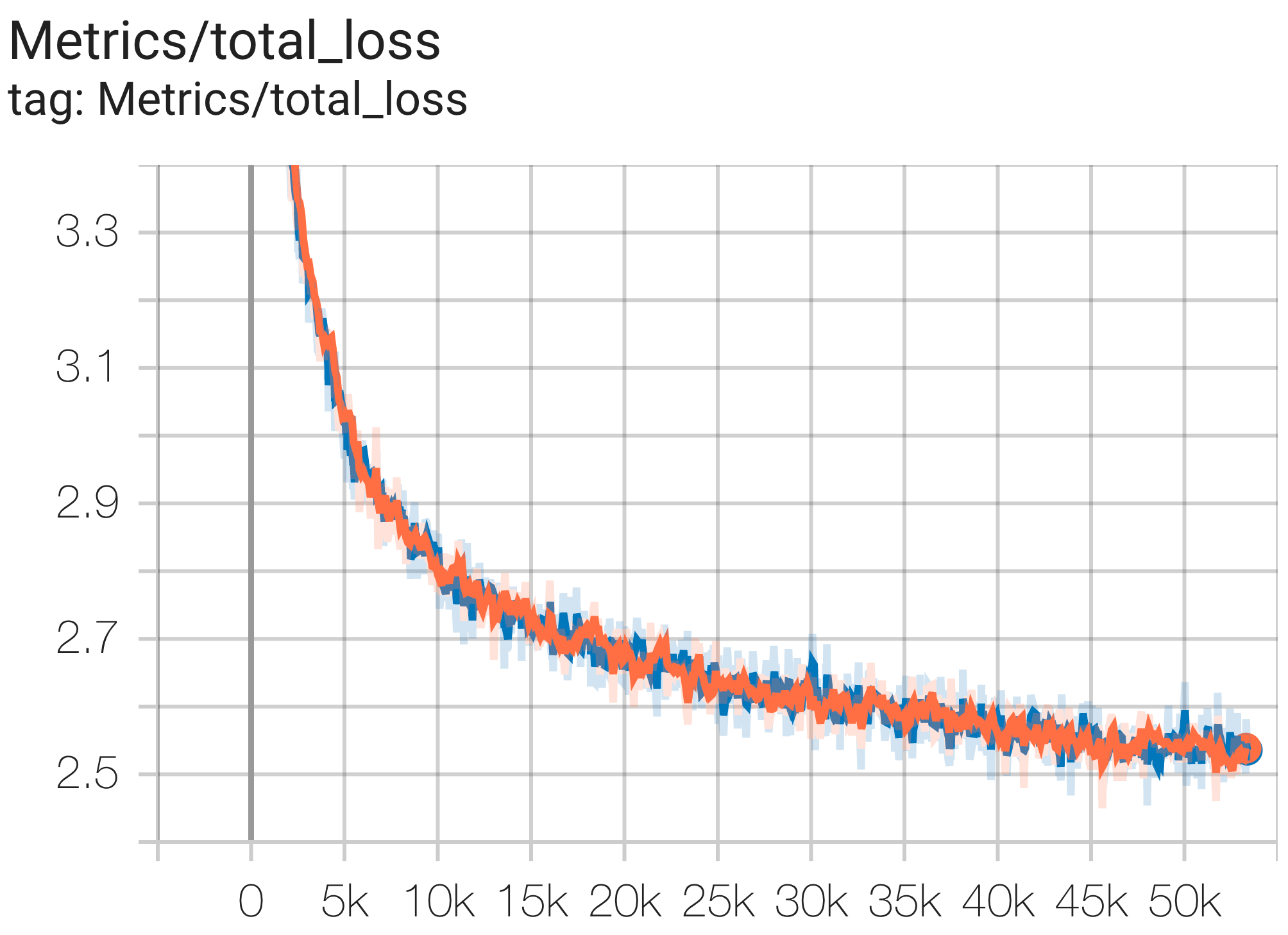
Hier sind einige Beispiele für Konvergenzläufe mit dem c4-Datensatz.
Sie können ein 1B Params-Modell auf dem C4-Datensatz auf TPU v4-8 ausführen, indem Sie die Konfiguration C4Spmd1BAdam4Replicas aus c4.py wie folgt verwenden:
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4Spmd1BAdam4Replicas
--job_log_dir=gs:// < your-bucket > Sie können die Verlustkurve und log perplexity wie folgt beobachten:
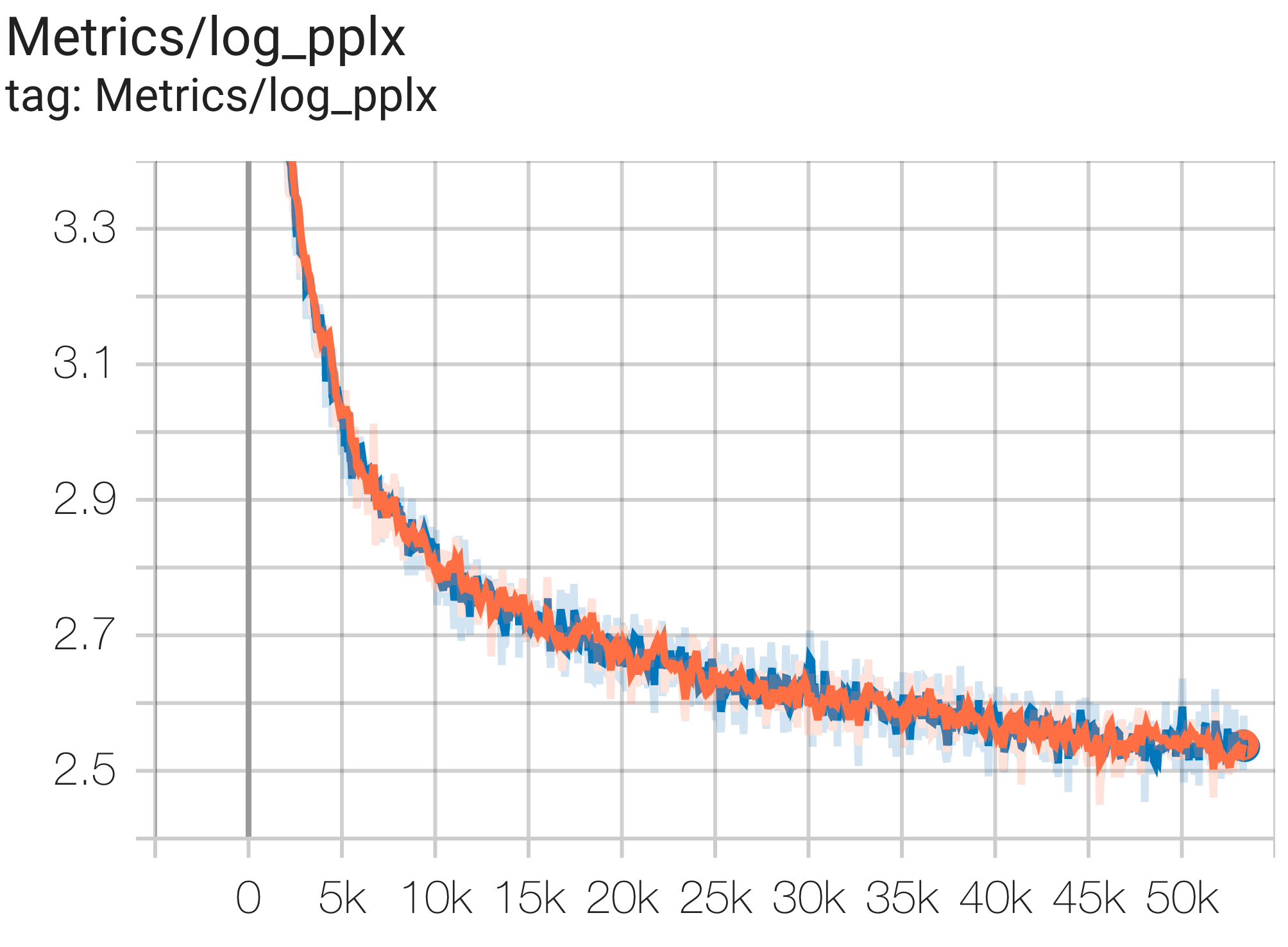
Sie können ein 16B Parametermodell auf einem C4-Datensatz auf TPU v4-64 ausführen, indem Sie die Konfiguration C4Spmd16BAdam32Replicas aus c4.py wie folgt verwenden:
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4Spmd16BAdam32Replicas
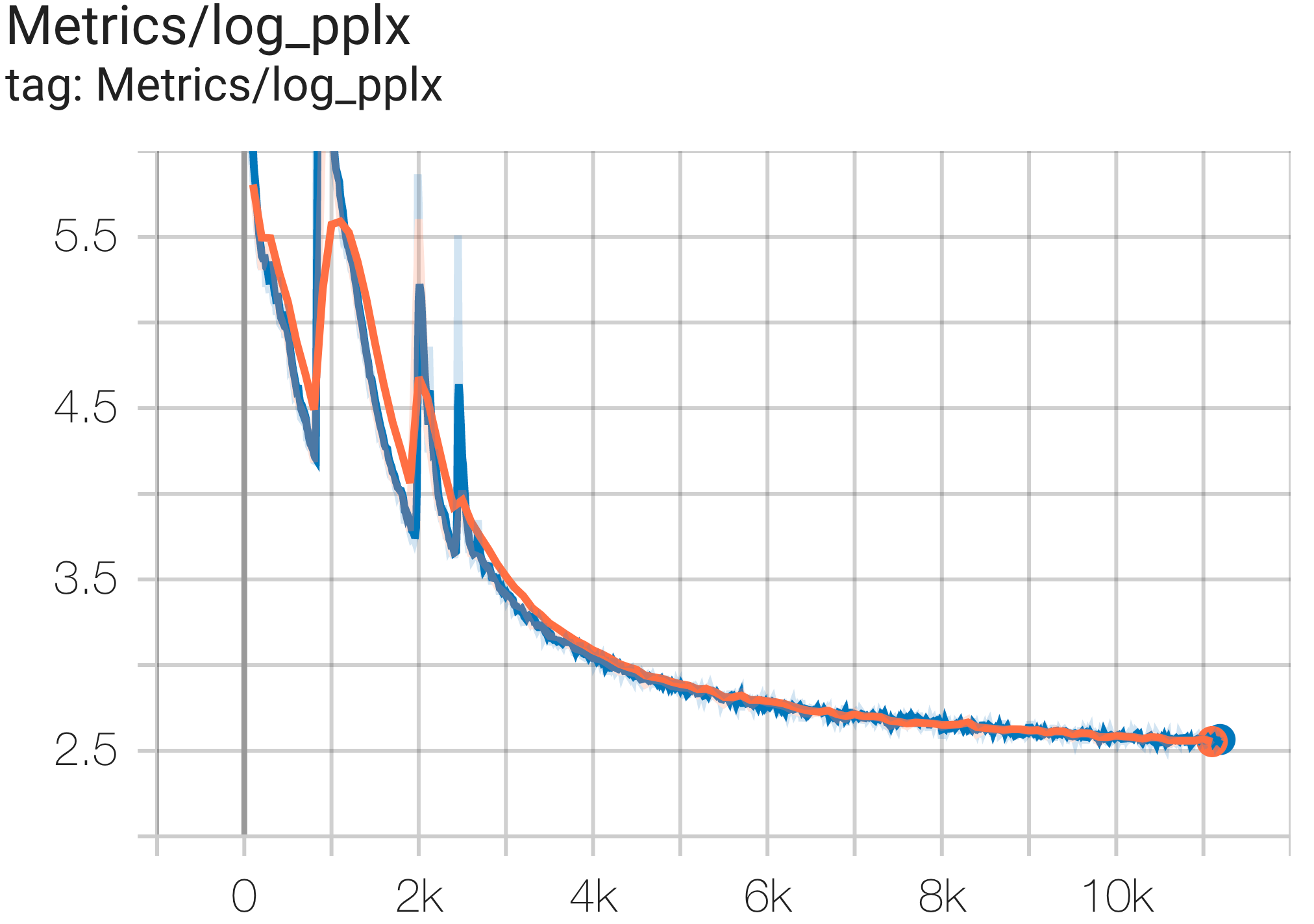
--job_log_dir=gs:// < your-bucket > Sie können die Verlustkurve und log perplexity wie folgt beobachten:
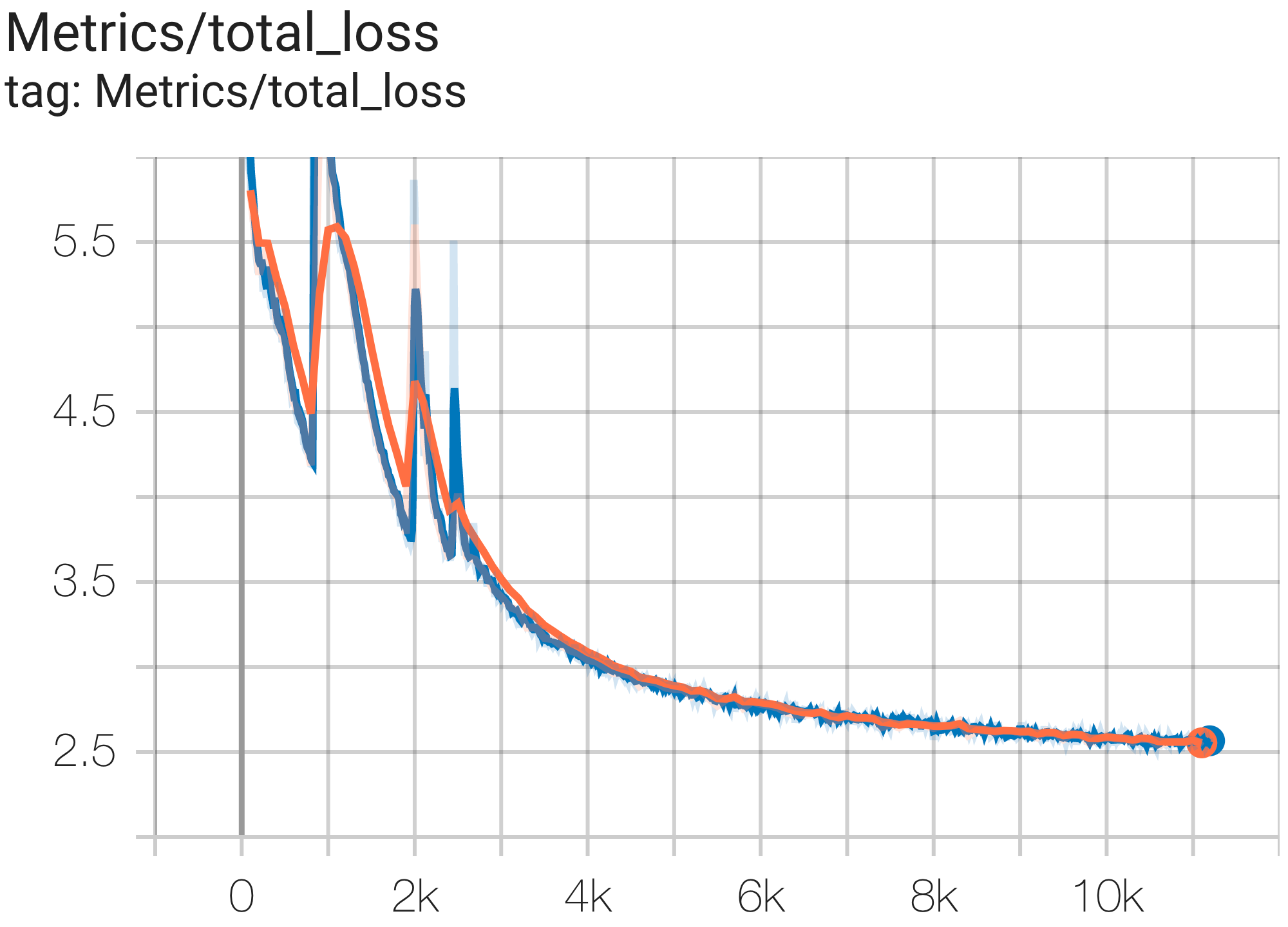
Sie können das GPT3-XL-Modell auf dem c4-Datensatz auf TPU v4-128 ausführen, indem Sie die Konfiguration C4SpmdPipelineGpt3SmallAdam64Replicas aus c4.py wie folgt verwenden:
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4SpmdPipelineGpt3SmallAdam64Replicas
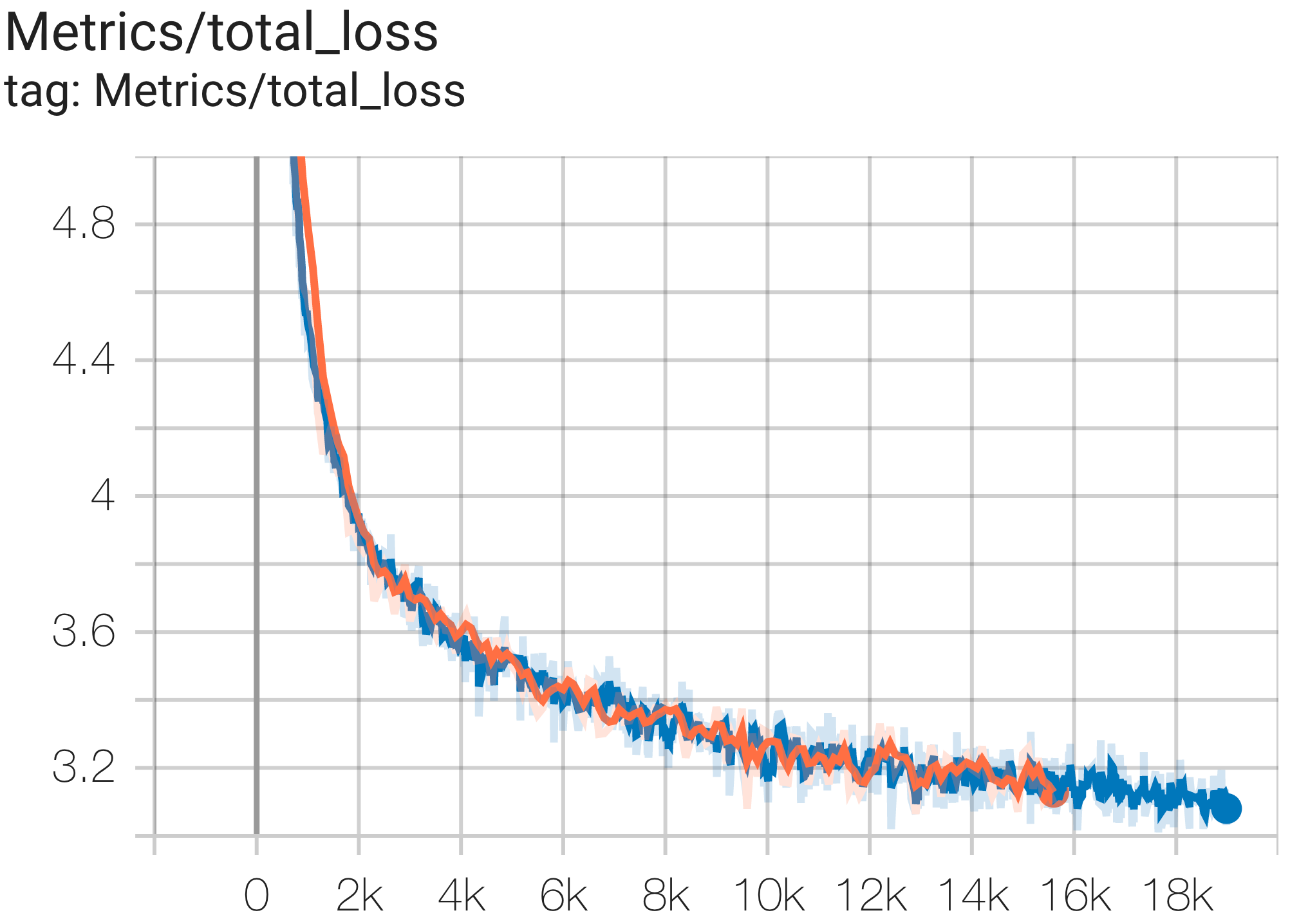
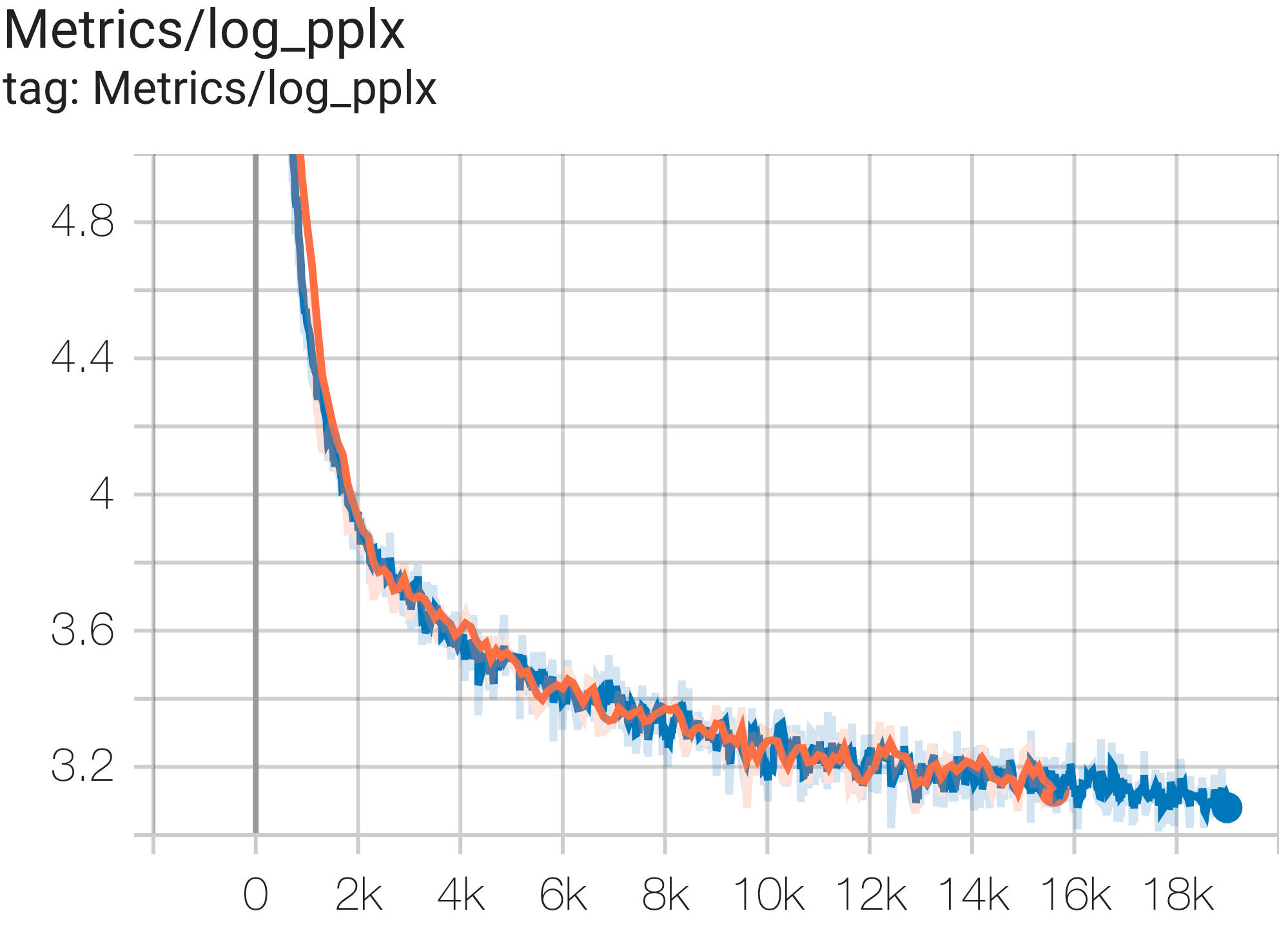
--job_log_dir=gs:// < your-bucket > Sie können die Verlustkurve und log perplexity wie folgt beobachten:
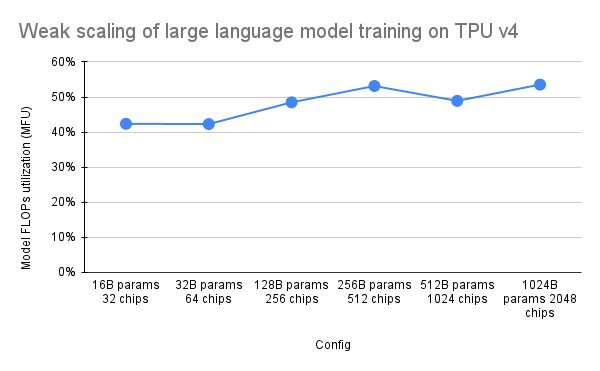
Das PaLM-Papier führte eine Effizienzmetrik namens Model FLOPs Utilization (MFU) ein. Dies wird als Verhältnis des beobachteten Durchsatzes (z. B. in Token pro Sekunde für ein Sprachmodell) zum theoretischen maximalen Durchsatz eines Systems gemessen, das 100 % der Spitzen-FLOPs nutzt. Es unterscheidet sich von anderen Methoden zur Messung der Rechenauslastung, da es keine FLOPs berücksichtigt, die für die Rematerialisierung der Aktivierung während des Rückwärtsdurchlaufs aufgewendet werden. Dies bedeutet, dass sich die durch MFU gemessene Effizienz direkt in der End-to-End-Trainingsgeschwindigkeit niederschlägt.
Um die MFU einer wichtigen Klasse von Workloads auf TPU v4 Pods mit Pax zu bewerten, haben wir eine ausführliche Benchmark-Kampagne für eine Reihe von reinen Decoder-Transformer-Sprachmodell-Konfigurationen (GPT) durchgeführt, deren Größe zwischen Milliarden und Billionen Parametern liegt auf dem c4-Datensatz. Die folgende Grafik zeigt die Trainingseffizienz unter Verwendung des Musters „schwache Skalierung“, bei dem wir die Modellgröße proportional zur Anzahl der verwendeten Chips vergrößert haben.
Die Multislice-Konfigurationen in diesem Repo beziehen sich auf 1. Singlie-Slice-Konfigurationen für Syntax/Modellarchitektur und 2. MaxText-Repo für Konfigurationswerte.
Wir stellen Beispielläufe unter „c4_multislice.py“ als Ausgangspunkt für Pax auf Multislice bereit.
Auf dieser Seite finden Sie eine ausführlichere Dokumentation zur Verwendung von Ressourcen in der Warteschlange für ein Cloud-TPU-Projekt mit mehreren Slices. Im Folgenden werden die Schritte gezeigt, die zum Einrichten von TPUs zum Ausführen von Beispielkonfigurationen in diesem Repository erforderlich sind.
export ZONE=us-central2-b
export VERSION=tpu-vm-v4-base
export PROJECT= < your-project >
export ACCELERATOR=v4-128 # or v4-384 depending on which config you run Um beispielsweise C4Spmd22BAdam2xv4_128 auf zwei Slices von v4-128 auszuführen, müssten Sie TPUs wie folgt einrichten:
export TPU_PREFIX= < your-prefix > # New TPUs will be created based off this prefix
export QR_ID= $TPU_PREFIX
export NODE_COUNT= < number-of-slices > # 1, 2, or 4 depending on which config you run
# create a TPU VM
gcloud alpha compute tpus queued-resources create $QR_ID --accelerator-type= $ACCELERATOR --runtime-version=tpu-vm-v4-base --node-count= $NODE_COUNT --node-prefix= $TPU_PREFIX Die zuvor beschriebenen Setup-Befehle müssen auf ALLEN Workern in ALLEN Slices ausgeführt werden. Sie können 1) SSH in jeden Worker und jedes Slice einzeln ausführen; oder 2) for-Schleife mit --worker=all als folgenden Befehl verwenden.
for (( i = 0 ; i < $NODE_COUNT ; i ++ ))
do
gcloud compute tpus tpu-vm ssh $TPU_PREFIX - $i --zone=us-central2-b --worker=all --command= " pip install paxml && pip install orbax==0.1.1 && pip install " jax[tpu] " -f https://storage.googleapis.com/jax-releases/libtpu_releases.html "
done Um die Multislice-Konfigurationen auszuführen, öffnen Sie die gleiche Anzahl an Terminals wie Ihr $NODE_COUNT. Öffnen Sie für unsere Experimente mit 2 Slices ( C4Spmd22BAdam2xv4_128 ) zwei Terminals. Führen Sie dann jeden dieser Befehle einzeln von jedem Terminal aus aus.
Führen Sie vom Terminal 0 aus den Trainingsbefehl für Slice 0 wie folgt aus:
export TPU_PREFIX= < your-prefix >
export EXP_NAME=C4Spmd22BAdam2xv4_128
export LIBTPU_INIT_ARGS= " --xla_jf_spmd_threshold_for_windowed_einsum_mib=0 --xla_tpu_spmd_threshold_for_allgather_cse=10000 --xla_enable_async_all_gather=true --xla_tpu_enable_latency_hiding_scheduler=true TPU_MEGACORE=MEGACORE_DENSE "
gcloud compute tpus tpu-vm ssh $TPU_PREFIX -0 --zone=us-central2-b --worker=all
--command= " LIBTPU_INIT_ARGS= $LIBTPU_INIT_ARGS
python3 /home/yooh/.local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4_multislice. ${EXP_NAME} --job_log_dir=gs://<your-bucket> "Führen Sie von Terminal 1 aus gleichzeitig den Trainingsbefehl für Slice 1 wie folgt aus:
export TPU_PREFIX= < your-prefix >
export EXP_NAME=C4Spmd22BAdam2xv4_128
export LIBTPU_INIT_ARGS= " --xla_jf_spmd_threshold_for_windowed_einsum_mib=0 --xla_tpu_spmd_threshold_for_allgather_cse=10000 --xla_enable_async_all_gather=true --xla_tpu_enable_latency_hiding_scheduler=true TPU_MEGACORE=MEGACORE_DENSE "
gcloud compute tpus tpu-vm ssh $TPU_PREFIX -1 --zone=us-central2-b --worker=all
--command= " LIBTPU_INIT_ARGS= $LIBTPU_INIT_ARGS
python3 /home/yooh/.local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4_multislice. ${EXP_NAME} --job_log_dir=gs://<your-bucket> "Diese Tabelle enthält Details dazu, wie die MaxText-Variablennamen in Pax übersetzt wurden.
Beachten Sie, dass MaxText über eine „Skala“ verfügt, die für Endwerte mit mehreren Parametern (base_num_decoder_layers, base_emb_dim, base_mlp_dim, base_num_heads) multipliziert wird.
Erwähnenswert ist außerdem, dass Pax DCN und ICN MESH_SHAPE als Array abdeckt, während es in MaxText separate Variablen für data_parallelism, fsdp_parallelism und tensor_parallelism für DCN und ICI gibt. Da diese Werte standardmäßig auf 1 gesetzt sind, werden in dieser Übersetzungstabelle nur Variablen mit Werten größer als 1 erfasst.
Das heißt, ICI_MESH_SHAPE = [ici_data_parallelism, ici_fsdp_parallelism, ici_tensor_parallelism] und DCN_MESH_SHAPE = [dcn_data_parallelism, dcn_fsdp_parallelism, dcn_tensor_parallelism]
| Pax C4Spmd22BAdam2xv4_128 | MaxText 2xv4-128.sh | (nach Anwendung der Skalierung) | ||
|---|---|---|---|---|
| Skala (auf die nächsten 4 Variablen angewendet) | 3 | |||
| NUM_LAYERS | 48 | base_num_decoder_layers | 16 | 48 |
| MODEL_DIMS | 6144 | base_emb_dim | 2048 | 6144 |
| HIDDEN_DIMS | 24576 | MODEL_DIMS * 4 (= base_mlp_dim) | 8192 | 24576 |
| NUM_HEADS | 24 | base_num_heads | 8 | 24 |
| DIMS_PER_HEAD | 256 | head_dim | 256 | |
| PERCORE_BATCH_SIZE | 16 | pro_device_batch_size | 16 | |
| MAX_SEQ_LEN | 1024 | max_target_length | 1024 | |
| VOCAB_SIZE | 32768 | vocab_size | 32768 | |
| FPROP_DTYPE | jnp.bfloat16 | dtype | bfloat16 | |
| USE_REPEATED_LAYER | WAHR | |||
| SUMMARY_INTERVAL_STEPS | 10 | |||
| ICI_MESH_SHAPE | [1, 64, 1] | ici_fsdp_parallelism | 64 | |
| DCN_MESH_SHAPE | [2, 1, 1] | dcn_data_parallelism | 2 |
Input ist eine Instanz der BaseInput -Klasse zum Abrufen von Daten in das Modell zum Trainieren/Auswerten/Dekodieren.
class BaseInput :
def get_next ( self ):
pass
def reset ( self ):
pass Es verhält sich wie ein Iterator: get_next() gibt eine NestedMap zurück, wobei jedes Feld ein numerisches Array mit der Batchgröße als führende Dimension ist.
Jede Eingabe wird durch eine Unterklasse von BaseInput.HParams konfiguriert. Auf dieser Seite verwenden wir p , um eine Instanz eines BaseInput.Params zu bezeichnen, und es wird in input instanziiert.
In Pax sind Daten immer Multihost: Für jeden Jax-Prozess wird eine separate, unabhängige input instanziiert. Ihre Parameter haben unterschiedliche p.infeed_host_index , die automatisch von Pax festgelegt werden.
Daher ist die auf jedem Host angezeigte lokale Batchgröße p.batch_size und die globale Batchgröße ist (p.batch_size * p.num_infeed_hosts) . Man sieht oft, dass p.batch_size auf jax.local_device_count() * PERCORE_BATCH_SIZE gesetzt ist.
Aufgrund dieser Multihost-Natur muss input ordnungsgemäß aufgeteilt werden.
Für das Training darf jede input niemals identische Batches ausgeben, und für die Auswertung eines endlichen Datensatzes muss jede input nach der gleichen Anzahl von Batches enden. Die beste Lösung besteht darin, dass die Eingabeimplementierung die Daten ordnungsgemäß aufteilt, sodass sich die einzelnen input auf verschiedenen Hosts nicht überschneiden. Andernfalls kann man auch unterschiedliche Zufallsstartwerte verwenden, um doppelte Chargen während des Trainings zu vermeiden.
input.reset() wird nie für Trainingsdaten aufgerufen, kann aber zum Auswerten (oder Dekodieren) von Daten verwendet werden.
Für jeden Auswertungs- (oder Dekodierungs-)Lauf ruft Pax N Stapel von input ab, indem er input.get_next() N -mal aufruft. Die Anzahl der verwendeten Chargen, N , kann eine vom Benutzer über p.eval_loop_num_batches festgelegte feste Zahl sein; oder N kann dynamisch sein ( p.eval_loop_num_batches=None ), dh wir rufen input.get_next() auf, bis alle Daten erschöpft sind (durch Auslösen von StopIteration oder tf.errors.OutOfRange ).
Wenn p.reset_for_eval=True , wird p.eval_loop_num_batches ignoriert und N wird dynamisch als die Anzahl der Batches zur Erschöpfung der Daten bestimmt. In diesem Fall sollte p.repeat auf „False“ gesetzt werden, da dies andernfalls zu einer unendlichen Dekodierung/Auswertung führen würde.
Wenn p.reset_for_eval=False , ruft Pax p.eval_loop_num_batches -Stapel ab. Dies sollte mit p.repeat=True gesetzt werden, damit die Daten nicht vorzeitig erschöpft werden.
Beachten Sie, dass LingvoEvalAdaptor-Eingaben p.reset_for_eval=True erfordern.
N : statisch | N : dynamisch | |
|---|---|---|
p.reset_for_eval=True | Jeder Evaluierungslauf verwendet die | Eine Epoche pro Evaluierungslauf. |
: : erste N Chargen. Nicht: eval_loop_num_batches : | ||
| : : wird noch unterstützt. : wird ignoriert. Eingabe muss: | ||
| : : : endlich sein : | ||
: : : ( p.repeat=False ) : | ||
p.reset_for_eval=False | Jeder Evaluierungslauf verwendet | Nicht unterstützt. |
: : nicht überlappendes N : : | ||
| : : Chargen auf einem rollenden : : | ||
| : : Basis, nach : : | ||
: : eval_loop_num_batches : : | ||
| : : . Eingabe muss wiederholt werden : : | ||
| : : auf unbestimmte Zeit : : | ||
: : ( p.repeat=True ) oder : : | ||
| : : Andernfalls kann es zu einer Erhöhung kommen : : | ||
| : : Ausnahme : : |
Wenn decode/eval in genau einer Epoche ausgeführt wird (d. h. wenn p.reset_for_eval=True ), muss die Eingabe das Sharding korrekt verarbeiten, sodass jeder Shard im selben Schritt angehoben wird, nachdem genau die gleiche Anzahl von Batches erzeugt wurde. Dies bedeutet normalerweise, dass die Eingabe die Auswertungsdaten auffüllen muss. Dies erfolgt automatisch durch SeqIOInput und LingvoEvalAdaptor (mehr dazu weiter unten).
Für die meisten Eingaben rufen wir immer nur get_next() auf, um Datenstapel abzurufen. Eine Ausnahme bildet ein Typ von Bewertungsdaten, bei dem auch die Art und Weise, wie Metriken berechnet werden, für das Eingabeobjekt definiert ist.
Dies wird nur mit SeqIOInput unterstützt, das einen kanonischen Evaluierungs-Benchmark definiert. Insbesondere verwendet Pax predict_metric_fns und score_metric_fns() die in der SeqIO-Aufgabe definiert sind, um Bewertungsmetriken zu berechnen (obwohl Pax nicht direkt vom SeqIO-Evaluator abhängt).
Wenn ein Modell mehrere Eingaben verwendet, entweder zwischen Training/Evaluierung oder unterschiedliche Trainingsdaten zwischen Vortraining/Feinabstimmung, müssen Benutzer sicherstellen, dass die von den Eingaben verwendeten Tokenizer identisch sind, insbesondere beim Importieren verschiedener Eingaben, die von anderen implementiert wurden.
Benutzer können die Tokenizer auf ihre Richtigkeit überprüfen, indem sie einige IDs mit input.ids_to_strings() dekodieren.
Es ist immer eine gute Idee, die Daten anhand einiger Chargen auf ihre Richtigkeit zu überprüfen. Benutzer können den Parameter einfach in einem Colab reproduzieren und die Daten überprüfen:
p = ... # specify the intended input param
inp = p . Instantiate ()
b = inp . get_next ()
print ( b ) Trainingsdaten sollten normalerweise keinen festen Zufallsstartwert verwenden. Dies liegt daran, dass die Trainingsdaten beginnen, sich zu wiederholen, wenn der Trainingsauftrag vorzeitig ausgeführt wird. Insbesondere für Lingvo-Eingaben empfehlen wir, p.input.file_random_seed = 0 für Trainingsdaten zu setzen.
Um zu testen, ob das Sharding korrekt gehandhabt wird, können Benutzer manuell unterschiedliche Werte für p.num_infeed_hosts, p.infeed_host_index festlegen und prüfen, ob die instanziierten Eingaben unterschiedliche Batches ausgeben.
Pax unterstützt drei Arten von Eingaben: SeqIO, Lingvo und benutzerdefiniert.
SeqIOInput kann zum Importieren von Datensätzen verwendet werden.
SeqIO-Eingaben kümmern sich automatisch um das korrekte Sharding und Padding der Auswertungsdaten.
LingvoInputAdaptor kann zum Importieren von Datensätzen verwendet werden.
Die Eingabe wird vollständig an die Lingvo-Implementierung delegiert, die das Sharding möglicherweise automatisch übernimmt oder nicht.
Für die auf GenericInput basierende Lingvo-Eingabeimplementierung mit einem festen packing_factor empfehlen wir die Verwendung LingvoInputAdaptorNewBatchSize um eine größere Batchgröße für die innere Lingvo-Eingabe anzugeben und die gewünschte (normalerweise viel kleinere) Batchgröße auf p.batch_size zu setzen.
Für Evaluierungsdaten empfehlen wir die Verwendung LingvoEvalAdaptor um Sharding und Padding für die Ausführung von Eval über eine Epoche hinweg zu handhaben.
Benutzerdefinierte Unterklasse von BaseInput . Benutzer implementieren ihre eigene Unterklasse, typischerweise mit tf.data oder SeqIO.
Benutzer können auch eine vorhandene Eingabeklasse erben, um nur die Nachbearbeitung von Stapeln anzupassen. Zum Beispiel:
class MyInput ( base_input . LingvoInputAdaptor ):
def get_next ( self ):
batch = super (). get_next ()
# modify batch: batch.new_field = ...
return batchHyperparameter sind ein wichtiger Bestandteil bei der Definition von Modellen und der Konfiguration von Experimenten.
Zur besseren Integration mit Python-Tools verwendet Pax/Praxis einen auf Python-Datenklassen basierenden Konfigurationsstil für Hyperparameter.
class Linear ( base_layer . BaseLayer ):
"""Linear layer without bias."""
class HParams ( BaseHParams ):
"""Associated hyperparams for this layer class.
Attributes:
input_dims: Depth of the input.
output_dims: Depth of the output.
"""
input_dims : int = 0
output_dims : int = 0Es ist auch möglich, HParams-Datenklassen zu verschachteln. Im folgenden Beispiel ist das linear_tpl-Attribut ein verschachteltes Linear.HParams.
class FeedForward ( base_layer . BaseLayer ):
"""Feedforward layer with activation."""
class HParams ( BaseHParams ):
"""Associated hyperparams for this layer class.
Attributes:
input_dims: Depth of the input.
output_dims: Depth of the output.
has_bias: Adds bias weights or not.
linear_tpl: Linear layer params.
activation_tpl: Activation layer params.
"""
input_dims : int = 0
output_dims : int = 0
has_bias : bool = True
linear_tpl : BaseHParams = sub_config_field ( Linear . HParams )
activation_tpl : activations . BaseActivation . HParams = sub_config_field (
ReLU . HParams )Ein Layer repräsentiert eine beliebige Funktion, möglicherweise mit trainierbaren Parametern. Eine Ebene kann andere Ebenen als untergeordnete Ebenen enthalten. Ebenen sind die wesentlichen Bausteine von Modellen. Ebenen erben vom Flax nn.Module.
Typischerweise definieren Ebenen zwei Methoden:
Diese Methode erstellt trainierbare Gewichte und untergeordnete Ebenen.
Diese Methode definiert die Vorwärtsausbreitungsfunktion und berechnet einige Ausgaben basierend auf den Eingaben. Darüber hinaus kann fprop Zusammenfassungen hinzufügen oder Hilfsverluste verfolgen.
Fiddle ist eine Open-Source-Python-First-Konfigurationsbibliothek, die für ML-Anwendungen entwickelt wurde. Pax/Praxis unterstützt die Interoperabilität mit Fiddle Config/Partial(s) und einige erweiterte Funktionen wie eifrige Fehlerprüfung und gemeinsame Parameter.
fdl_config = Linear . HParams . config ( input_dims = 1 , output_dims = 1 )
# A typo.
fdl_config . input_dimz = 31337 # Raises an exception immediately to catch typos fast!
fdl_partial = Linear . HParams . partial ( input_dims = 1 )Mit Fiddle können Ebenen für die gemeinsame Nutzung konfiguriert werden (z. B. nur einmal instanziiert mit gemeinsam genutzten trainierbaren Gewichten).
Ein Modell definiert lediglich das Netzwerk, typischerweise eine Sammlung von Schichten, und definiert Schnittstellen für die Interaktion mit dem Modell, z. B. Dekodierung usw.
Einige Beispiele für Basismodelle sind:
Eine Aufgabe enthält noch ein weiteres Modell und einen Lerner/Optimierer. Die einfachste Task-Unterklasse ist eine SingleTask , die die folgenden Hparams erfordert:
class HParams ( base_task . BaseTask . HParams ):
""" Task parameters .
Attributes :
name : Name of this task object , must be a valid identifier .
model : The underlying JAX model encapsulating all the layers .
train : HParams to control how this task should be trained .
metrics : A BaseMetrics aggregator class to determine how metrics are
computed .
loss_aggregator : A LossAggregator aggregator class to derermine how the
losses are aggregated ( e . g single or MultiLoss )
vn : HParams to control variational noise .| PyPI-Version | Begehen |
|---|---|
| 0.1.0 | 546370f5323ef8b27d38ddc32445d7d3d1e4da9a |
Copyright 2022 Google LLC
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.