BabyGPT Build_GPT_From_Scratch
1.0.0
Baby GPT ist ein exploratives Projekt, das darauf abzielt, schrittweise ein GPT-ähnliches Sprachmodell aufzubauen. Das Projekt beginnt mit einem einfachen Bigram-Modell und integriert nach und nach fortgeschrittene Konzepte aus der Transformer-Modellarchitektur.
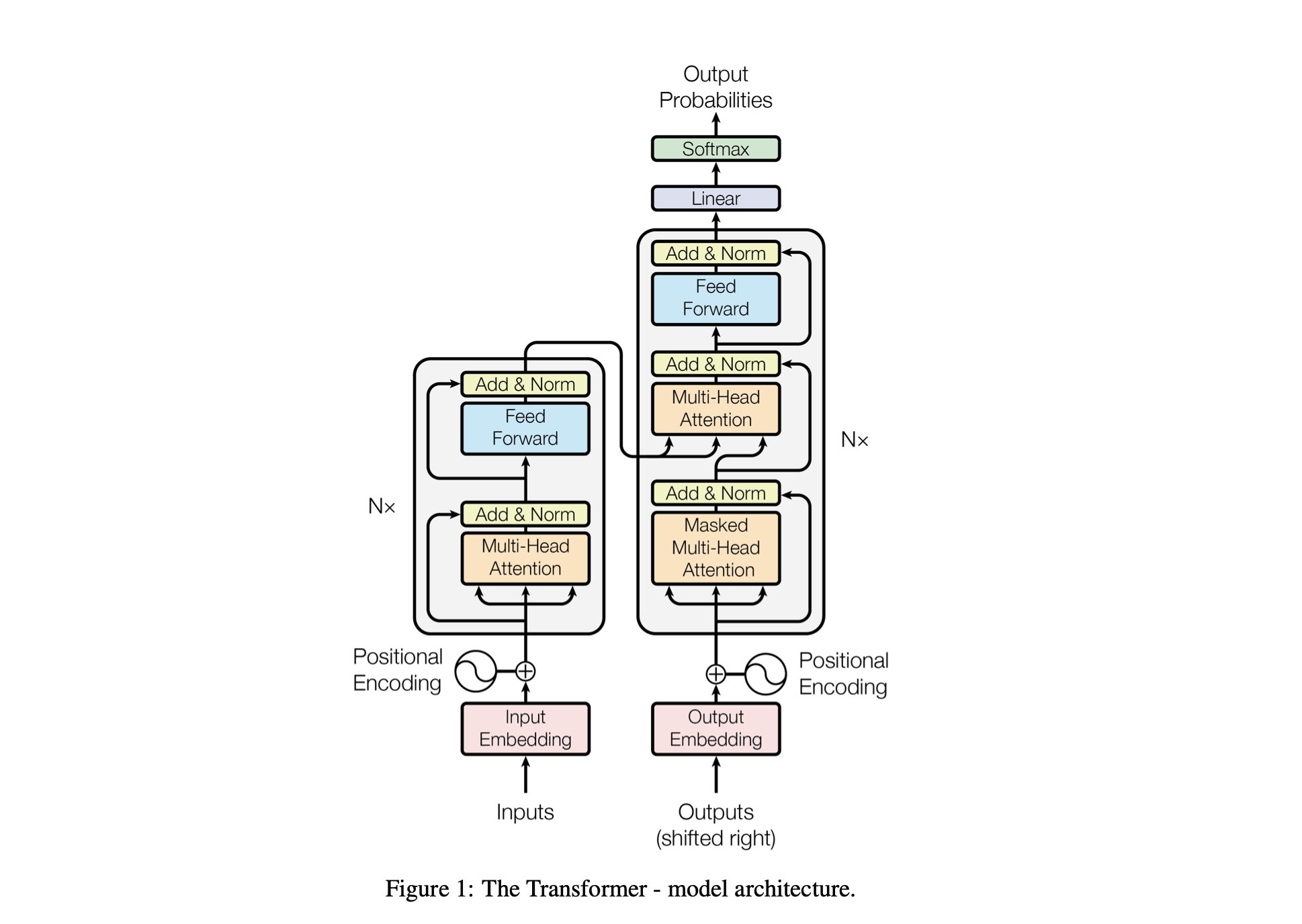
Die Leistung des Modells wird mithilfe der folgenden Hyperparameter optimiert:
batch_size : Die Anzahl der während des Trainings parallel verarbeiteten Sequenzenblock_size : Die Länge der vom Modell verarbeiteten Sequenzend_model : Die Anzahl der Features im Modell (die Größe der Einbettungen)d_k : Die Anzahl der Features pro Aufmerksamkeitskopf.num_iter : Die Gesamtzahl der Trainingsiterationen, die das Modell ausführen wirdNx : Die Anzahl der Transformatorblöcke oder Schichten im Modell.eval_interval : Das Intervall, in dem der Verlust des Modells berechnet und ausgewertet wirdlr_rate : Die Lernrate für den Adam-Optimiererdevice : Wird automatisch auf 'cuda' gesetzt, wenn eine kompatible GPU verfügbar ist, andernfalls standardmäßig auf 'cpu' .eval_iters : Die Anzahl der Iterationen, über die der Bewertungsverlust gemittelt werden sollh : Die Anzahl der Aufmerksamkeitsköpfe im Mehrkopf-Aufmerksamkeitsmechanismusdropout_rate : Die während des Trainings verwendete Abbruchrate, um eine Überanpassung zu verhindernDiese Hyperparameter wurden sorgfältig ausgewählt, um die Fähigkeit des Modells auszubalancieren, ohne Überanpassung aus den Daten zu lernen und die Rechenressourcen effektiv zu verwalten.
| Hyperparameter | CPU-Modell | GPU-Modell |
|---|---|---|
device | 'CPU' | 'cuda' falls verfügbar, sonst 'cpu' |
batch_size | 16 | 64 |
block_size | 8 | 256 |
num_iter | 10000 | 10000 |
eval_interval | 500 | 500 |
eval_iters | 100 | 200 |
d_model | 16 | 512 |
d_k | 4 | 16 |
Nx | 2 | 6 |
dropout_rate | 0,2 | 0,2 |
lr_rate | 0,005 (5e-3) | 0,001 (1e-3) |
h | 2 | 6 |
open('./GPT Series/input.txt', 'r', encoding = 'utf-8')chars_to_int und int_to_chars .encode -Funktion und zurück mit der decode -Funktion.train_data ) und Validierungssätze ( valid_data ).get_batch bereitet Daten in Mini-Batches für das Training vor.BigramLM -Klasse.Mini-Batching ist eine Technik des maschinellen Lernens, bei der die Trainingsdaten in kleine Batches aufgeteilt werden. Jeder Mini-Batch wird während des Modelltrainings separat verarbeitet. Dieser Ansatz hilft bei:
# Function to create mini-batches for training or validation.
def get_batch ( split ):
# Select data based on training or validation split.
data = train_data if split == "train" else valid_data
# Generate random start indices for data blocks, ensuring space for 'block_size' elements.
ix = torch . randint ( len ( data ) - block_size , ( batch_size ,))
# Create input (x) and target (y) sequences from data blocks.
x = torch . stack ([ data [ i : i + block_size ] for i in ix ])
y = torch . stack ([ data [ i + 1 : i + block_size + 1 ] for i in ix ])
# Move data to GPU if available for faster processing.
x , y = x . to ( device ), y . to ( device )
return x , y | Faktor | Kleine Losgröße | Große Losgröße |
|---|---|---|
| Gradientenrauschen | Höher (mehr Varianz bei Aktualisierungen) | Niedriger (konsistentere Updates) |
| Konvergenz | Neigt dazu, mehr Lösungen zu erkunden, einschließlich flacherer Minima | Konvergiert oft zu schärferen Minima |
| Verallgemeinerung | Potenziell besser (aufgrund flacherer Minima) | Möglicherweise schlechter (aufgrund schärferer Minima) |
| Voreingenommenheit | Niedriger (weniger Wahrscheinlichkeit einer Überanpassung an Trainingsdatenmuster) | Höher (möglicherweise zu stark an Trainingsdatenmuster angepasst) |
| Varianz | Höher (aufgrund der stärkeren Erkundung des Lösungsbereichs) | Niedriger (aufgrund der geringeren Erkundung des Lösungsraums) |
| Rechenaufwand | Höher pro Epoche (mehr Updates) | Niedriger pro Epoche (weniger Updates) |
| Speichernutzung | Untere | Höher |
Die Funktion estimate_loss berechnet den durchschnittlichen Verlust für das Modell über eine angegebene Anzahl von Iterationen (eval_iters). Es wird verwendet, um die Leistung des Modells zu bewerten, ohne seine Parameter zu beeinflussen. Das Modell wird auf den Bewertungsmodus eingestellt, um bestimmte Ebenen wie Dropout für eine konsistente Verlustberechnung zu deaktivieren. Nach der Berechnung des durchschnittlichen Verlusts für Trainings- und Validierungsdaten wird das Modell wieder in den Trainingsmodus versetzt. Diese Funktion ist unerlässlich, um den Trainingsverlauf zu überwachen und gegebenenfalls Anpassungen vorzunehmen.
@ torch . no_grad () # Disables gradient calculation to save memory and computations
def estimate_loss ():
result = {} # Dictionary to store the results
model . eval () # Puts the model in evaluation mode
# Iterates over the data splits (training and validation)
for split in [ 'train' , 'valid_date' ]:
# Initializes a tensor to store the losses for each iteration
losses = torch . zeros ( eval_iters )
# Loops over the number of iterations to calculate the average loss
for e in range ( eval_iters ):
X , Y = get_batch ( split ) # Fetches a batch of data
logits , loss = model ( X , Y ) # Gets the model outputs and computes the loss
losses [ e ] = loss . item () # Records the loss for this iteration
# Stores the mean loss for the current split in the result dictionary
result [ split ] = losses . mean ()
model . train () # Sets the model back to training mode
return result # Returns the dictionary with the computed losses Positionskodierung : Hinzufügen von Positionsinformationen zum Modell mit der positional_encodings_table in der BigramLM -Klasse. Wir fügen Positionskodierungen zu den Einbettungen unserer Charaktere hinzu, wie in der Transformer-Architektur.
Hier richten wir den AdamW-Optimierer ein und verwenden ihn zum Trainieren eines neuronalen Netzwerkmodells in PyTorch. Der Adam-Optimierer wird in vielen Deep-Learning-Szenarien bevorzugt, da er die Vorteile von zwei anderen Erweiterungen des stochastischen Gradientenabstiegs kombiniert: AdaGrad und RMSProp. Adam berechnet adaptive Lernraten für jeden Parameter. Adam speichert nicht nur einen exponentiell abfallenden Durchschnitt vergangener quadratischer Gradienten wie RMSProp, sondern speichert auch einen exponentiell abfallenden Durchschnitt vergangener Gradienten, ähnlich dem Momentum. Dadurch kann der Optimierer die Lernrate für jedes Gewicht des neuronalen Netzwerks anpassen, was zu einem effektiveren Training für komplexe Datensätze und Architekturen führen kann.
AdamW ändert die Art und Weise, wie der Gewichtsabfall in den Optimierungsprozess integriert wird, und behebt ein Problem mit dem ursprünglichen Adam-Optimierer, bei dem der Gewichtsabfall nicht gut von den Gradientenaktualisierungen getrennt ist, was zu einer suboptimalen Anwendung der Regularisierung führt. Die Verwendung von AdamW kann manchmal zu einer besseren Trainingsleistung und einer Verallgemeinerung auf unbekannte Daten führen. Wir haben uns für AdamW entschieden, da es in der Lage ist, den Gewichtsverlust effektiver zu handhaben als der Standard-Adam-Optimierer, was möglicherweise zu einem verbesserten Modelltraining und einer verbesserten Generalisierung führt.
optimizer = torch . optim . AdamW ( model . parameters (), lr = lr_rate )
for iter in range ( num_iter ):
# estimating the loss for per X interval
if iter % eval_interval == 0 :
losses = estimate_loss ()
print ( f"step { iter } : train loss is { losses [ 'train' ]:.5f } and validation loss is { losses [ 'valid_date' ]:.5f } " )
# sampling a mini batch of data
xb , yb = get_batch ( "train" )
# Forward Pass
logits , loss = model ( xb , yb )
# Zeroing Gradients: Before computing the gradients, existing gradients are reset to zero. This is necessary because gradients accumulate by default in PyTorch.
optimizer . zero_grad ( set_to_none = True )
# Backward Pass or Backpropogation: Computing Gradients
loss . backward ()
# Updating the Model Parameters
optimizer . step ()Selbstaufmerksamkeit ist ein Mechanismus, der es dem Modell ermöglicht, die Wichtigkeit verschiedener Teile der Eingabedaten unterschiedlich zu gewichten. Es ist eine Schlüsselkomponente der Transformer-Architektur und ermöglicht es dem Modell, sich auf relevante Teile der Eingabesequenz zu konzentrieren, um Vorhersagen zu treffen.
Skalarprodukt-Aufmerksamkeit : Ein einfacher Aufmerksamkeitsmechanismus, der eine gewichtete Summe von Werten basierend auf dem Skalarprodukt zwischen Abfragen und Schlüsseln berechnet.
Skalierte Skalarprodukt-Aufmerksamkeit : Eine Verbesserung gegenüber der Skalarprodukt-Aufmerksamkeit, die die Skalarprodukte entsprechend der Dimensionalität der Tasten verkleinert und verhindert, dass die Farbverläufe während des Trainings zu klein werden.
OneHeadSelfAttention : Implementierung eines einköpfigen Selbstaufmerksamkeitsmechanismus, der es dem Modell ermöglicht, verschiedene Positionen der Eingabesequenz zu berücksichtigen. Die SelfAttention -Klasse demonstriert die Intuition hinter dem Aufmerksamkeitsmechanismus und seiner skalierten Version.
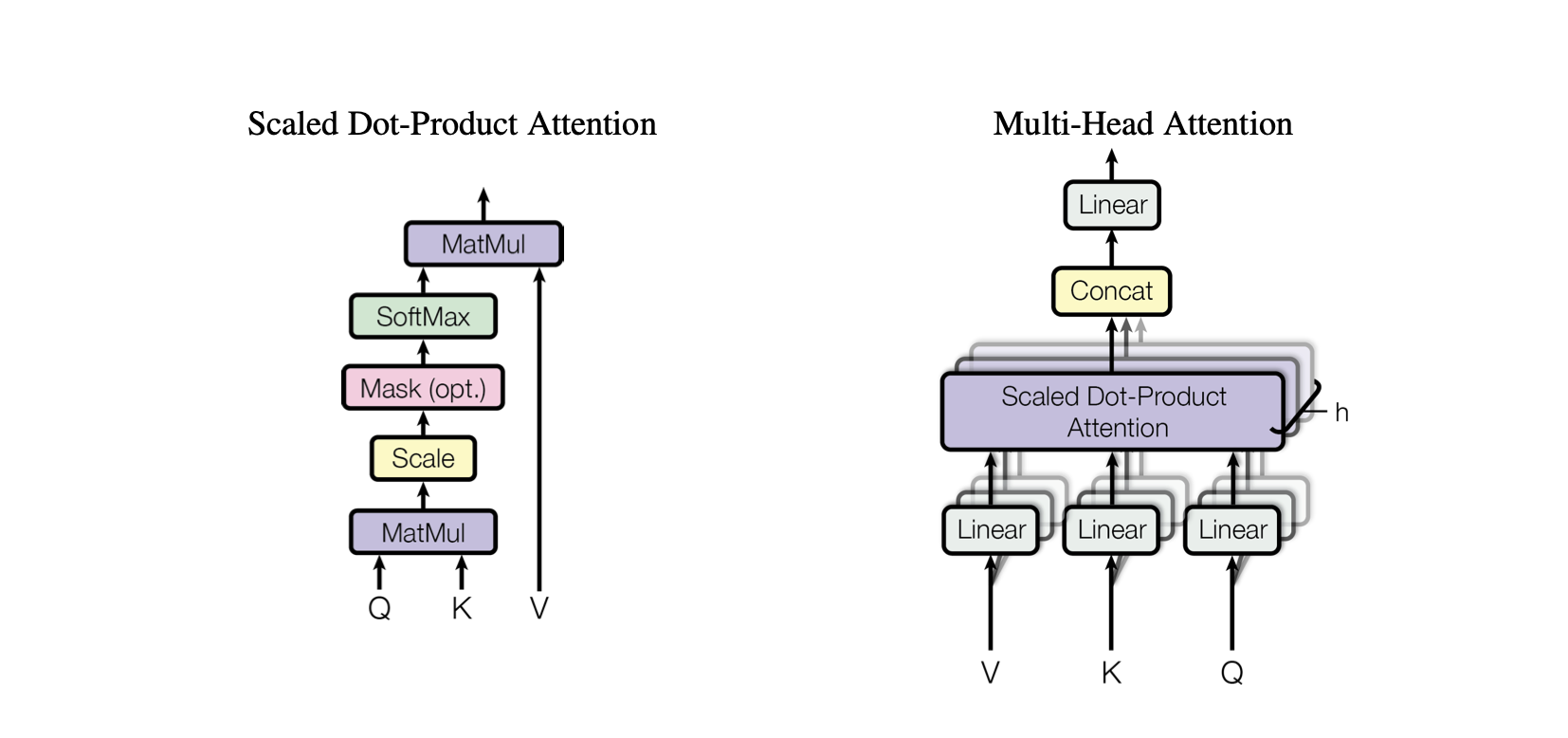
Jedes entsprechende Modell im Baby-GPT-Projekt baut schrittweise auf dem vorherigen auf, beginnend mit der Intuition hinter dem Selbstaufmerksamkeitsmechanismus, gefolgt von praktischen Implementierungen von Punktprodukt- und skalierten Skalarprodukt-Aufmerksamkeiten und gipfelt in der Integration eines One-Attention-Mechanismus. Kopf-Selbstaufmerksamkeitsmodul.
class SelfAttention ( nn . Module ):
"""Self Attention (One Head)"""
""" d_k = C """
def __init__ ( self , d_k ):
super (). __init__ () #superclass initialization for proper torch functionality
# keys
self . keys = nn . Linear ( d_model , d_k , bias = False )
# queries
self . queries = nn . Linear ( d_model , d_k , bias = False )
# values
self . values = nn . Linear ( d_model , d_k , bias = False )
# buffer for the model
self . register_buffer ( 'tril' , torch . tril ( torch . ones ( block_size , block_size )))
def forward ( self , X ):
"""Computing Attention Matrix"""
B , T , C = X . shape
# Keys matrix K
K = self . keys ( X ) # (B, T, C)
# Query matrix Q
Q = self . queries ( X ) # (B, T, C)
# Scaled Dot Product
scaled_dot_product = Q @ K . transpose ( - 2 , - 1 ) * 1 / math . sqrt ( C ) # (B, T, T)
# Masking upper triangle
scaled_dot_product_masked = scaled_dot_product . masked_fill ( self . tril [: T , : T ] == 0 , float ( '-inf' ))
# SoftMax transformation
attention_matrix = F . softmax ( scaled_dot_product_masked , dim = - 1 ) # (B, T, T)
# Weighted Aggregation
V = self . values ( X ) # (B, T, C)
output = attention_matrix @ V # (B, T, C)
retur Die SelfAttention -Klasse stellt einen grundlegenden Baustein des Transformer-Modells dar und kapselt den Selbstaufmerksamkeitsmechanismus mit einem einzigen Kopf. Hier ein Einblick in seine Komponenten und Prozesse:
Initialisierung : Der Konstruktor __init__(self, d_k) initialisiert die linearen Schichten für Schlüssel, Abfragen und Werte, alle mit der Dimensionalität d_k . Diese linearen Transformationen projizieren die Eingabe in verschiedene Unterräume für nachfolgende Aufmerksamkeitsberechnungen.
Puffer : self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size))) registriert eine untere Dreiecksmatrix als persistenten Puffer, der nicht als Modellparameter betrachtet wird. Diese Matrix wird zur Maskierung im Aufmerksamkeitsmechanismus verwendet, um zu verhindern, dass zukünftige Positionen in jedem Berechnungsschritt berücksichtigt werden (nützlich bei der Selbstaufmerksamkeit des Decoders).
Forward Pass : Die Methode forward(self, X) definiert die Berechnung, die bei jedem Aufruf des Self-Attention-Moduls durchgeführt wird
MultiHeadAttention : Kombiniert Ausgaben von mehreren SelfAttention Köpfen in der MultiHeadAttention -Klasse. Die MultiHeadAttention-Klasse ist eine erweiterte Implementierung des Selbstaufmerksamkeitsmechanismus mit einem Kopf aus dem vorherigen Schritt, aber jetzt arbeiten mehrere Aufmerksamkeitsköpfe parallel, wobei sich jeder auf unterschiedliche Teile der Eingabe konzentriert.
class MultiHeadAttention ( nn . Module ):
"""Multi Head Self Attention"""
"""h: #heads"""
def __init__ ( self , h , d_k ):
super (). __init__ ()
# initializing the heads, we want h times attention heads wit size d_k
self . heads = nn . ModuleList ([ SelfAttention ( d_k ) for _ in range ( h )])
# adding linear layer to project the concatenated heads to the original dimension
self . projections = nn . Linear ( h * d_k , d_model )
# adding dropout layer
self . droupout = nn . Dropout ( dropout_rate )
def forward ( self , X ):
# running multiple self attention heads in parallel and concatinate them at channel dimension
combined_attentions = torch . cat ([ h ( X ) for h in self . heads ], dim = - 1 )
# projecting the concatenated heads to the original dimension
combined_attentions = self . projections ( combined_attentions )
# applying dropout
combined_attentions = self . droupout ( combined_attentions )
return combined_attentions
FeedForward : Implementierung eines Feed-Forward-Neuronalen Netzwerks mit ReLU-Aktivierung innerhalb der FeedForward Klasse. Um diese vollständig verbundene Vorwärtskopplung zu unserem Modell hinzuzufügen, wie im ursprünglichen Transformer-Modell.
class FeedForward ( nn . Module ):
"""FeedForward Layer with ReLU activation function"""
def __init__ ( self , d_model ):
super (). __init__ ()
self . net = nn . Sequential (
# 2 linear layers with ReLU activation function
nn . Linear ( d_model , 4 * d_model ),
nn . ReLU (),
nn . Linear ( 4 * d_model , d_model ),
nn . Dropout ( dropout_rate )
)
def forward ( self , X ):
# applying the feedforward layer
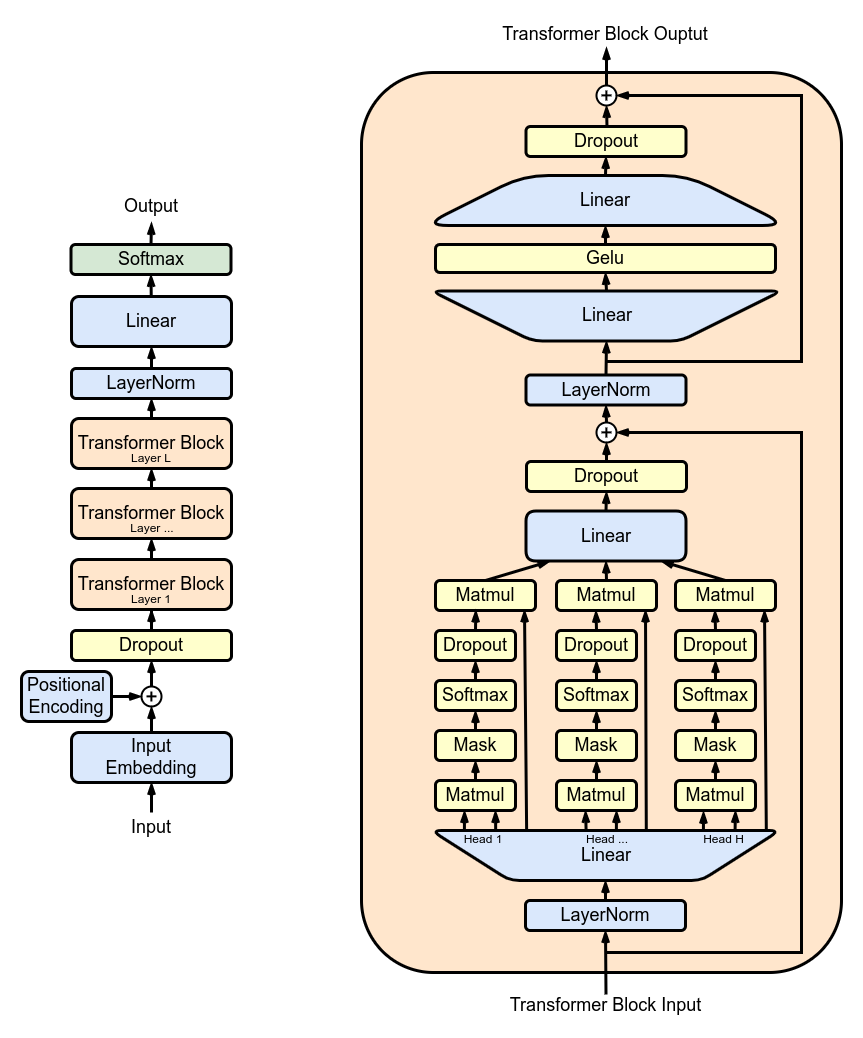
return self . net ( X ) TransformerBlocks : Stapeln von Transformatorblöcken mithilfe der Block -Klasse, um eine tiefere Netzwerkarchitektur zu erstellen. Tiefe und Komplexität: In neuronalen Netzen bezieht sich Tiefe auf die Anzahl der Schichten, über die Daten verarbeitet werden. Jede zusätzliche Schicht (oder jeder zusätzliche Block im Fall von Transformers) ermöglicht es dem Netzwerk, komplexere und abstraktere Merkmale der Eingabedaten zu erfassen.
Sequentielle Verarbeitung: Jeder Transformer-Block verarbeitet die Ausgabe seines vorhergehenden Blocks und baut so nach und nach ein differenzierteres Verständnis der Eingabe auf. Diese sequentielle Verarbeitung ermöglicht es dem Netzwerk, eine tiefgreifende, mehrschichtige Darstellung der Daten zu entwickeln. Komponenten eines Transformatorblocks
# ---------------------------------- Blocks ----------------------------------#
class Block ( nn . Module ):
"""Multiple Blocks of Transformer"""
def __init__ ( self , d_model , h ):
super (). __init__ ()
d_k = d_model // h
# Layer 4: Adding Attention layer
self . attention_head = MultiHeadAttention ( h , d_k ) # h heads of d_k dimensional self-attention
# Layer 5: Feed Forward layer
self . feedforward = FeedForward ( d_model )
# Layer Normalization 1
self . ln1 = nn . LayerNorm ( d_model )
# Layer Normalization 2
self . ln2 = nn . LayerNorm ( d_model )
# Adding additional X for Residual Connections
def forward ( self , X ):
X = X + self . attention_head ( self . ln1 ( X ))
X = X + self . feedforward ( self . ln2 ( X ))
return X ResidualConnections : Erweiterung der Block -Klasse um Restverbindungen, wodurch die Lerneffizienz verbessert wird. Restverbindungen, auch als Sprungverbindungen bekannt, sind eine entscheidende Innovation beim Entwurf tiefer neuronaler Netze, insbesondere in Transformer-Modellen. Sie befassen sich mit einer der größten Herausforderungen beim Training tiefer Netzwerke: dem Problem des verschwindenden Gradienten.
# Adding additional X for Residual Connections
def forward ( self , X ):
X = X + self . attention_head ( self . ln1 ( X ))
X = X + self . feedforward ( self . ln2 ( X ))
return X LayerNorm : Hinzufügen einer Layer-Normalisierung zu unserem Transformer. Normalisierung der Layer-Ausgaben mit nn.LayerNorm(d_model) in der Block -Klasse.
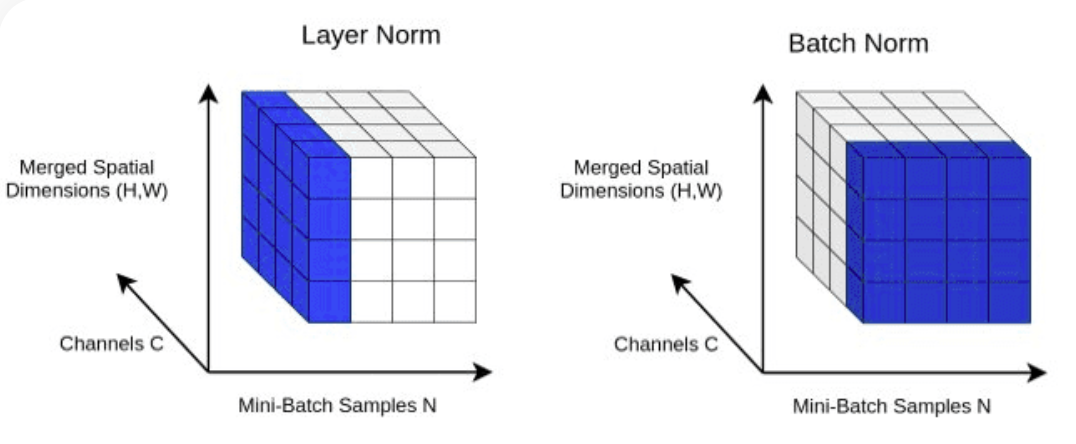
class LayerNorm :
def __init__ ( self , dim , eps = 1e-5 ):
self . eps = eps
self . gamma = torch . ones ( dim )
self . beta = torch . zeros ( dim )
def __call__ ( self , x ):
# orward pass calculaton
xmean = x . mean ( 1 , keepdim = True ) # layer mean
xvar = x . var ( 1 , keepdim = True ) # layer variance
xhat = ( x - xmean ) / torch . sqrt ( xvar + self . eps ) # normalize to unit variance
self . out = self . gamma * xhat + self . beta
return self . out
def parameters ( self ):
return [ self . gamma , self . beta ] Dropout : Wird den Ebenen SelfAttention und FeedForward als Regularisierungsmethode hinzugefügt, um eine Überanpassung zu verhindern. Wir fügen Drop-out hinzu zu:
ScaleUp : Erhöhung der Komplexität des Modells durch Erweiterung von batch_size , block_size , d_model , d_k und Nx . Sie benötigen ein CUDA-Toolkit sowie eine Maschine mit NVIDIA-GPU, um dieses größere Modell zu trainieren und zu testen.
Wenn Sie CUDA zur GPU-Beschleunigung ausprobieren möchten, stellen Sie sicher, dass Sie die entsprechende Version von PyTorch installiert haben, die CUDA unterstützt.
import torch
torch . cuda . is_available ()Sie können dies tun, indem Sie die CUDA-Version in Ihrem PyTorch-Installationsbefehl angeben, etwa in der Befehlszeile:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113

