ke dialogue
1.0.0


Dies ist die Umsetzung des Papiers:
Lernwissensdatenbanken mit Parametern für aufgabenorientierte Dialogsysteme . Andrea Madotto , Samuel Cahyawijaya, Genta Indra Winata, Yan Xu, Zihan Liu, Zhaojiang Lin, Pascale Fung Ergebnisse von EMNLP 2020 [PDF]
Wenn Sie in Ihrer Arbeit Quellcodes oder Datensätze aus diesem Toolkit verwenden, zitieren Sie bitte das folgende Dokument. Der Bibtex ist unten aufgeführt:
@article{madotto2020learning,
title={Lernende Wissensdatenbanken mit Parametern für aufgabenorientierte Dialogsysteme},
Autor={Madotto, Andrea und Cahyawijaya, Samuel und Winata, Genta Indra und Xu, Yan und Liu, Zihan und Lin, Zhaojiang und Fung, Pascale},
journal={arXiv preprint arXiv:2009.13656},
Jahr={2020}
}
Aufgabenorientierte Dialogsysteme sind entweder modularisiert mit separatem Dialog State Tracking (DST) und Verwaltungsschritten oder durchgängig trainierbar. In jedem Fall spielt die Wissensdatenbank (KB) eine wesentliche Rolle bei der Erfüllung von Benutzeranfragen. Modularisierte Systeme verlassen sich auf DST, um mit der KB zu interagieren, was hinsichtlich Annotation und Inferenzzeit teuer ist. End-to-End-Systeme verwenden die KB direkt als Eingabe, können jedoch nicht skalieren, wenn die KB größer als einige hundert Einträge ist. In diesem Artikel schlagen wir eine Methode vor, um KB beliebiger Größe direkt in die Modellparameter einzubetten. Das resultierende Modell erfordert weder DST- oder Vorlagenantworten noch die KB als Eingabe und kann seine KB durch Feinabstimmung dynamisch aktualisieren. Wir bewerten unsere Lösung in fünf aufgabenorientierten Dialogdatensätzen mit kleiner, mittlerer und großer KB-Größe. Unsere Experimente zeigen, dass End-to-End-Modelle Wissensbasen effektiv in ihre Parameter einbetten und in allen ausgewerteten Datensätzen eine Wettbewerbsleistung erzielen können.
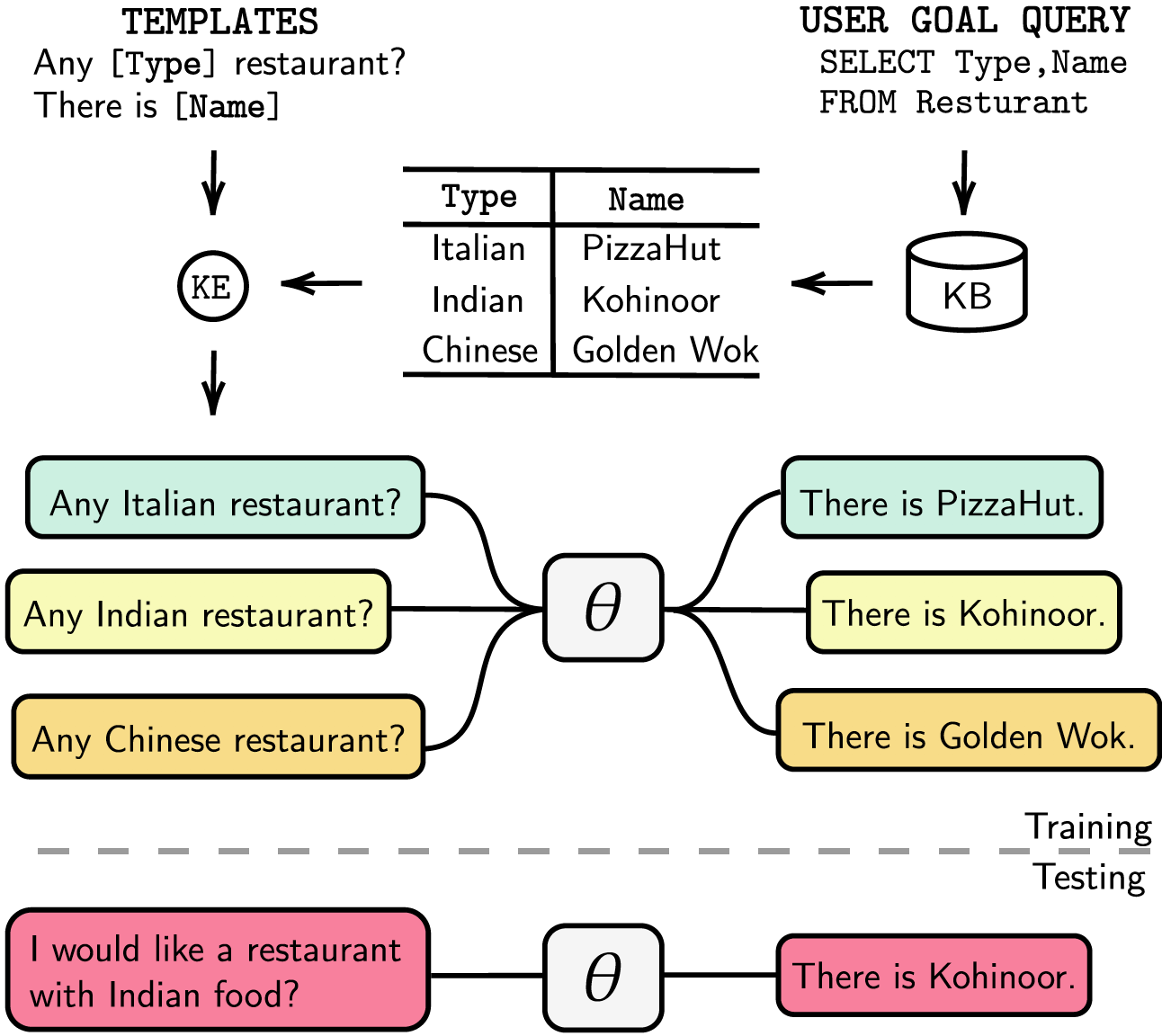
Wir haben unsere Abhängigkeiten in der requirements.txt aufgelistet. Sie können die Abhängigkeiten durch Ausführen installieren
❱❱❱ pip install -r requirements.txt Darüber hinaus enthält unser Code auch fp16 Unterstützung mit apex . Sie finden das Paket unter https://github.com/NVIDIA/apex.
Datensatz Laden Sie den vorverarbeiteten Datensatz herunter und legen Sie die ZIP-Datei im Ordner ./knowledge_embed/babi5 ab. Extrahieren Sie die ZIP-Datei, indem Sie sie ausführen
❱❱❱ cd ./knowledge_embed/babi5
❱❱❱ unzip dialog-bAbI-tasks.zipGenerieren Sie die delexikalisierten Dialoge aus dem bAbI-5-Datensatz über
❱❱❱ python3 generate_delexicalization_babi.pyGenerieren Sie die lexikalisierten Daten aus dem bAbI-5-Datensatz über
❱❱❱ python generate_dialogues_babi5.py --dialogue_path ./dialog-bAbI-tasks/dialog-babi-task5trn_record-delex.txt --knowledge_path ./dialog-bAbI-tasks/dialog-babi-kb-all.txt --output_folder ./dialog-bAbI-tasks --num_augmented_knowledge <num_augmented_knowledge> --num_augmented_dialogue <num_augmented_dialogues> --random_seed 0 Dabei beträgt der Höchstwert <num_augmented_knowledge> 558 (empfohlen) und <num_augmented_dialogues> 264, da dies der Anzahl des Wissens und der Dialoge im bAbI-5-Datensatz entspricht.
Feinabstimmung von GPT-2
Wir stellen den Prüfpunkt des GPT-2-Modells bereit, der auf das bAbI-Trainingsset abgestimmt ist. Sie können das Modell auch selbst trainieren, indem Sie den folgenden Befehl verwenden.
❱❱❱ cd ./modeling/babi5
❱❱❱ python main.py --model_checkpoint gpt2 --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks --n_epochs <num_epoch> --kbpercentage <num_augmented_dialogues> Beachten Sie, dass der Wert von --kbpercentage dem Wert <num_augmented_dialogues> entspricht, der aus der Lexikalisierung stammt. Dieser Parameter wird zur Auswahl der Erweiterungsdatei verwendet, die in den Zugdatensatz eingebettet werden soll.
Sie können das Modell auswerten, indem Sie das folgende Skript ausführen
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks Bewertung von bAbI-5 Um den Scorer für das bAbI-5-Aufgabenmodell auszuführen, können Sie den folgenden Befehl ausführen. Der Scorer liest die gesamte Datei result.json im Ordner runs der aus evaluate.py generiert wurde
python scorer_BABI5.py --model_checkpoint <model_checkpoint> --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks --kbpercentage 0Datensatz
Laden Sie den vorverarbeiteten Datensatz herunter und legen Sie die ZIP-Datei im Ordner ./knowledge_embed/camrest ab. Entpacken Sie die ZIP-Datei durch Ausführen
❱❱❱ cd ./knowledge_embed/camrest
❱❱❱ unzip CamRest.zipGenerieren Sie die delexikalisierten Dialoge aus dem CamRest-Datensatz über
❱❱❱ python3 generate_delexicalization_CAMREST.pyGenerieren Sie die lexikalisierten Daten aus dem CamRest-Datensatz über
❱❱❱ python generate_dialogues_CAMREST.py --dialogue_path ./CamRest/train_record-delex.txt --knowledge_path ./CamRest/KB.json --output_folder ./CamRest --num_augmented_knowledge <num_augmented_knowledge> --num_augmented_dialogue <num_augmented_dialogues> --random_seed 0 Wobei der Höchstwert <num_augmented_knowledge> 201 (empfohlen) und <num_augmented_dialogues> 156 beträgt, was ziemlich groß ist, da er der Anzahl des Wissens und der Dialoge im CamRest-Datensatz entspricht.
Feinabstimmung von GPT-2
Wir stellen den Prüfpunkt des GPT-2-Modells bereit, der auf dem CamRest-Trainingsset fein abgestimmt ist. Sie können das Modell auch selbst trainieren, indem Sie den folgenden Befehl verwenden.
❱❱❱ cd ./modeling/camrest/
❱❱❱ python main.py --model_checkpoint gpt2 --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest --n_epochs <num_epoch> --kbpercentage <num_augmented_dialogues> Beachten Sie, dass der Wert von --kbpercentage dem Wert <num_augmented_dialogues> entspricht, der aus der Lexikalisierung stammt. Dieser Parameter wird zur Auswahl der Erweiterungsdatei verwendet, die in den Zugdatensatz eingebettet werden soll.
Sie können das Modell auswerten, indem Sie das folgende Skript ausführen
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest Scoring CamRest Um den Scorer für das bAbI 5-Aufgabenmodell auszuführen, können Sie den folgenden Befehl ausführen. Der Scorer liest die gesamte Datei result.json im Ordner runs der aus evaluate.py generiert wurde
python scorer_CAMREST.py --model_checkpoint <model_checkpoint> --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest --kbpercentage 0Datensatz
Laden Sie den vorverarbeiteten Datensatz herunter und legen Sie ihn im Ordner ./knowledge_embed/smd ab.
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ unzip SMD.zipFeinabstimmung von GPT-2
Wir stellen den Prüfpunkt des GPT-2-Modells bereit, der auf das SMD-Trainingsset abgestimmt ist. Laden Sie den Prüfpunkt herunter und legen Sie ihn im Ordner ./modeling ab.
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ mkdir ./runs
❱❱❱ unzip ./knowledge_embed/smd/SMD_gpt2_graph_False_adj_False_edge_False_unilm_False_flattenKB_False_historyL_1000000000_lr_6.25e-05_epoch_10_weighttie_False_kbpercentage_0_layer_12.zip -d ./runsSie können das Modell auch selbst trainieren, indem Sie den folgenden Befehl verwenden.
❱❱❱ cd ./modeling/smd
❱❱❱ python main.py --dataset SMD --lr 6.25e-05 --n_epochs 10 --kbpercentage 0 --layers 12Bereiten Sie wissensbasierte Dialoge vor
Zunächst müssen wir Datenbanken für SQL-Abfragen erstellen.
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ python generate_dialogues_SMD.py --build_db --split test Anschließend generieren wir Dialoge basierend auf vorgefertigten Vorlagen nach Domänen. Mit dem folgenden Befehl können Sie Dialoge im weather generieren. Bitte ersetzen Sie weather durch navigate oder schedule in den Argumenten dialogue_path und domain , wenn Sie Dialoge in den anderen beiden Domänen generieren möchten. Sie können auch die Anzahl der im Relexikalisierungsprozess verwendeten Vorlagen ändern, indem Sie das Argument num_augmented_dialogue ändern.
❱❱❱ python generate_dialogues_SMD.py --split test --dialogue_path ./templates/weather_template.txt --domain weather --num_augmented_dialogue 100 --output_folder ./SMD/testPassen Sie das fein abgestimmte GPT-2-Modell an den Testsatz an
❱❱❱ python evaluate_finetune.py --dataset SMD --model_checkpoint runs/SMD_gpt2_graph_False_adj_False_edge_False_unilm_False_flattenKB_False_historyL_1000000000_lr_6.25e-05_epoch_10_weighttie_False_kbpercentage_0_layer_12 --top_k 1 --eval_indices 0,303 --filter_domain ""Sie können den Feinabstimmungsprozess auch beschleunigen, indem Sie Experimente parallel ausführen. Bitte ändern Sie die GPU-Einstellung in #L14 des Codes.
❱❱❱ python runner_expe_SMD.py Datensatz
Laden Sie den vorverarbeiteten Datensatz herunter und legen Sie ihn im Ordner ./knowledge_embed/mwoz ab.
❱❱❱ cd ./knowledge_embed/mwoz
❱❱❱ unzip mwoz.zipBereiten Sie in Wissen eingebettete Dialoge vor (Sie können diesen Schritt überspringen, wenn Sie die ZIP-Datei oben heruntergeladen haben)
Sie können die Datensätze durch Ausführen vorbereiten
❱❱❱ bash generate_MWOZ_all_data.shDas Shell-Skript generiert durch Aufruf die delexikalisierten Dialoge aus dem MWOZ-Datensatz
❱❱❱ python generate_delex_MWOZ_ATTRACTION.py
❱❱❱ python generate_delex_MWOZ_HOTEL.py
❱❱❱ python generate_delex_MWOZ_RESTAURANT.py
❱❱❱ python generate_delex_MWOZ_TRAIN.py
❱❱❱ python generate_redelex_augmented_MWOZ.py
❱❱❱ python generate_MWOZ_dataset.pyFeinabstimmung von GPT-2
Wir stellen den Prüfpunkt des GPT-2-Modells bereit, der auf das MWOZ-Trainingsset abgestimmt ist. Laden Sie den Prüfpunkt herunter und legen Sie ihn im Ordner ./modeling ab.
❱❱❱ cd ./knowledge_embed/mwoz
❱❱❱ mkdir ./runs
❱❱❱ unzip ./mwoz.zip -d ./runsSie können das Modell auch selbst trainieren, indem Sie den folgenden Befehl verwenden.
❱❱❱ cd ./modeling/mwoz
❱❱❱ python main.py --model_checkpoint gpt2 --dataset MWOZ_SINGLE --max_history 50 --train_batch_size 6 --kbpercentage 100 --fp16 O2 --gradient_accumulation_steps 3 --balance_sampler --n_epochs 10 Erste Schritte: Wir verwenden neo4j Community Server Edition und apoc -Bibliothek zur Verarbeitung von Diagrammdaten. apoc wird verwendet, um die Abfrage in neo4j zu parallelisieren, damit wir große Diagramme schneller verarbeiten können
Bevor Sie mit dem Datensatzabschnitt fortfahren, müssen Sie sicherstellen, dass neo4j (https://neo4j.com/download-center/#community) und apoc (https://neo4j.com/developer/neo4j-apoc/) installiert sind auf Ihrem System.
Wenn Sie mit CYPHER und apoc -Syntax nicht vertraut sind, können Sie dem Tutorial unter https://neo4j.com/developer/cypher/ und https://neo4j.com/blog/intro-user-defined-procedures-apoc/ folgen.
Datensatz Laden Sie den Originaldatensatz herunter und legen Sie die ZIP-Datei im Ordner ./knowledge_embed/opendialkg ab. Extrahieren Sie die ZIP-Datei, indem Sie sie ausführen
❱❱❱ cd ./knowledge_embed/opendialkg
❱❱❱ unzip https://drive.google.com/file/d/1llH4-4-h39sALnkXmGR8R6090xotE0PE/view?usp=sharing.zipGenerieren Sie die delexikalisierten Dialoge aus dem opendialkg-Datensatz über ( WARNUNG : Die Ausführung dauert etwa 12 Stunden.)
❱❱❱ python3 generate_delexicalization_DIALKG.py Dieses Skript erzeugt ./opendialkg/dialogkg_train_meta.pt , das zum Generieren des lexikalisierten Dialogs verwendet wird. Anschließend können Sie den lexikalisierten Dialog aus dem opendialkg-Datensatz über generieren
❱❱❱ python generate_dialogues_DIALKG.py --random_seed <random_seed> --batch_size 100 --max_iteration <max_iter> --stop_count <stop_count> --connection_string bolt://localhost:7687 Dieses Skript erzeugt höchstens batch_size * max_iter Samples von Dialogen, aber in jedem Batch besteht die Möglichkeit, dass es keinen gültigen Kandidaten gibt und dies zu weniger Samples führt. Die Anzahl der Generierungen wird durch einen anderen Faktor namens stop_count begrenzt, der die Generierung stoppt, wenn die Anzahl der generierten Stichproben mehr als dem angegebenen stop_count entspricht. Die Datei erzeugt 4 Dateien: ./opendialkg/db_count_records_{random_seed}.csv , ./opendialkg/used_count_records_{random_seed}.csv und ./opendialkg/generation_iteration_{random_seed}.csv , die zur Überprüfung der Verteilungsverschiebung des verwendet werden in der DB zählen; und ./opendialkg/generated_dialogue_bs100_rs{random_seed}.json , das die generierten Beispiele enthält.
Hinweise :
neo4j -Passwort in generate_delexicalization_DIALKG.py und generate_dialogues_DIALKG.py manuell ändern.Feinabstimmung von GPT-2
Wir stellen den Prüfpunkt des GPT-2-Modells bereit, der auf dem opendialkg-Trainingsset optimiert ist. Sie können das Modell auch selbst trainieren, indem Sie den folgenden Befehl verwenden.
❱❱❱ cd ./modeling/opendialkg
❱❱❱ python main.py --dataset_path ../../knowledge_embed/opendialkg/opendialkg --model_checkpoint gpt2 --dataset DIALKG --n_epochs 50 --kbpercentage <random_seed> --train_batch_size 8 --valid_batch_size 8 Beachten Sie, dass der Wert von --kbpercentage dem Wert <random_seed> entspricht, der aus der Lexikalisierung stammt. Dieser Parameter wird zur Auswahl der Erweiterungsdatei verwendet, die in den Zugdatensatz eingebettet werden soll.
Sie können das Modell auswerten, indem Sie das folgende Skript ausführen
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset DIALKG --dataset_path ../../knowledge_embed/opendialkg/opendialkg Scoring OpenDialKG Um den Scorer für das bAbI-5-Aufgabenmodell auszuführen, können Sie den folgenden Befehl ausführen. Der Scorer liest die gesamte Datei result.json im Ordner runs der aus evaluate.py generiert wurde
python scorer_DIALKG5.py --model_checkpoint <model_checkpoint> --dataset DIALKG ../../knowledge_embed/opendialkg/opendialkg --kbpercentage 0 Einzelheiten zu den Experimenten, Hyperparametern und Auswertungsergebnissen finden Sie im Hauptpapier und in den ergänzenden Materialien unserer Arbeit.


