gptpal
Clear speech

Chatten Sie gleichzeitig mit GPTs, genau wie mit Ihren vielen Freunden.
Englisch | 中文
Eine ChatGPT-Desktopanwendung, mit der Sie gleichzeitig mit GPTs chatten können. Es zeichnet Gespräche lokal auf und bietet verschiedene Funktionen wie Eingabeaufforderungsvorschläge, API-, Modell- und Proxy-Konfiguration, Anheften von Eingabeaufforderungen und Sprachsteuerung.
| Besonderheit | Fortschritt | Beschreibung |
|---|---|---|
| Gleichzeitiges Chatten mit GPTs | ✔️ | Die Möglichkeit, mit mehreren GPTs gleichzeitig zu chatten und eine Benachrichtigung zu erhalten, wenn eine neue Nachricht vorliegt. |
| Gespräche werden lokal aufgezeichnet | ✔️ | Alle Gespräche werden lokal gespeichert. |
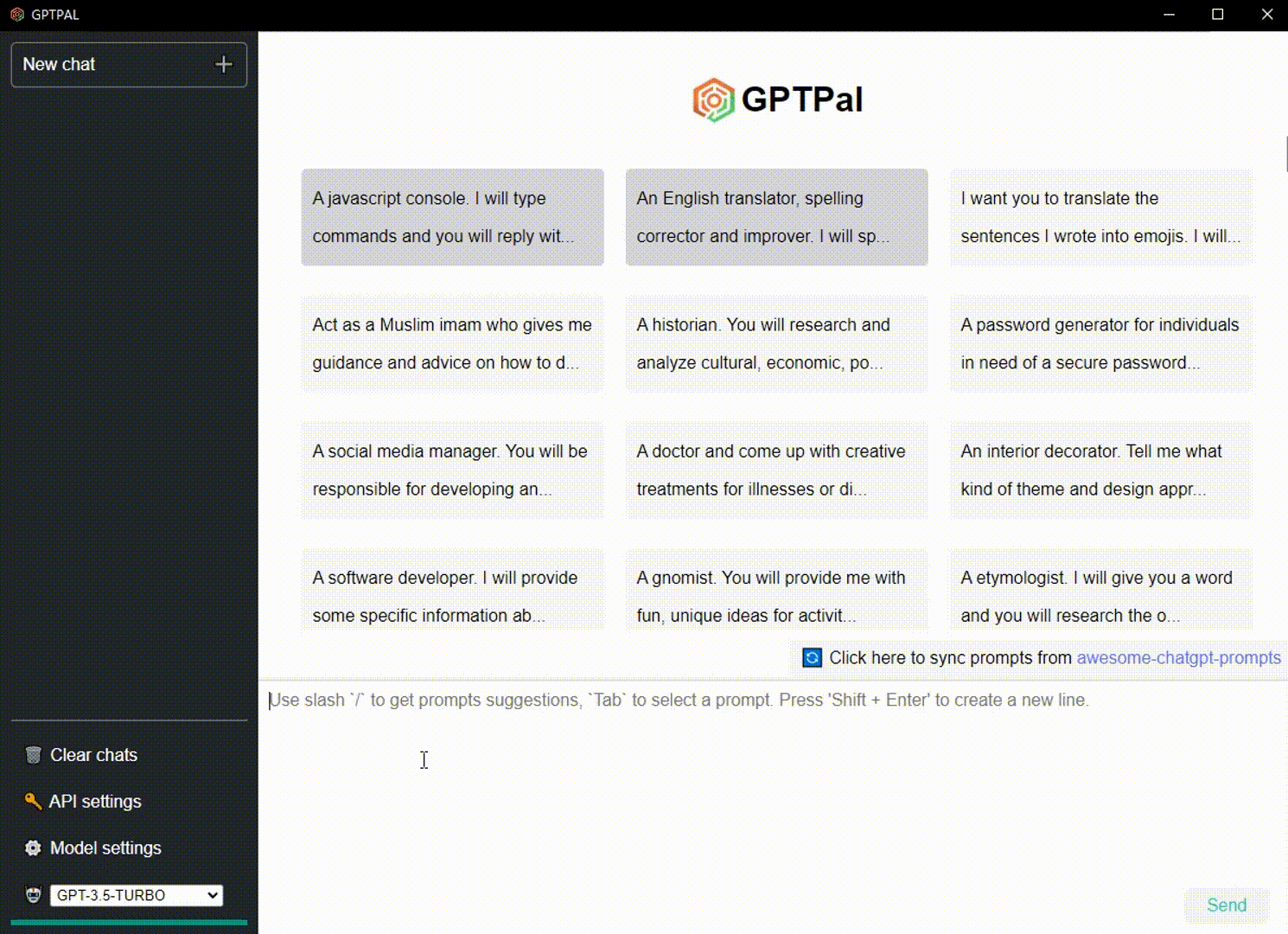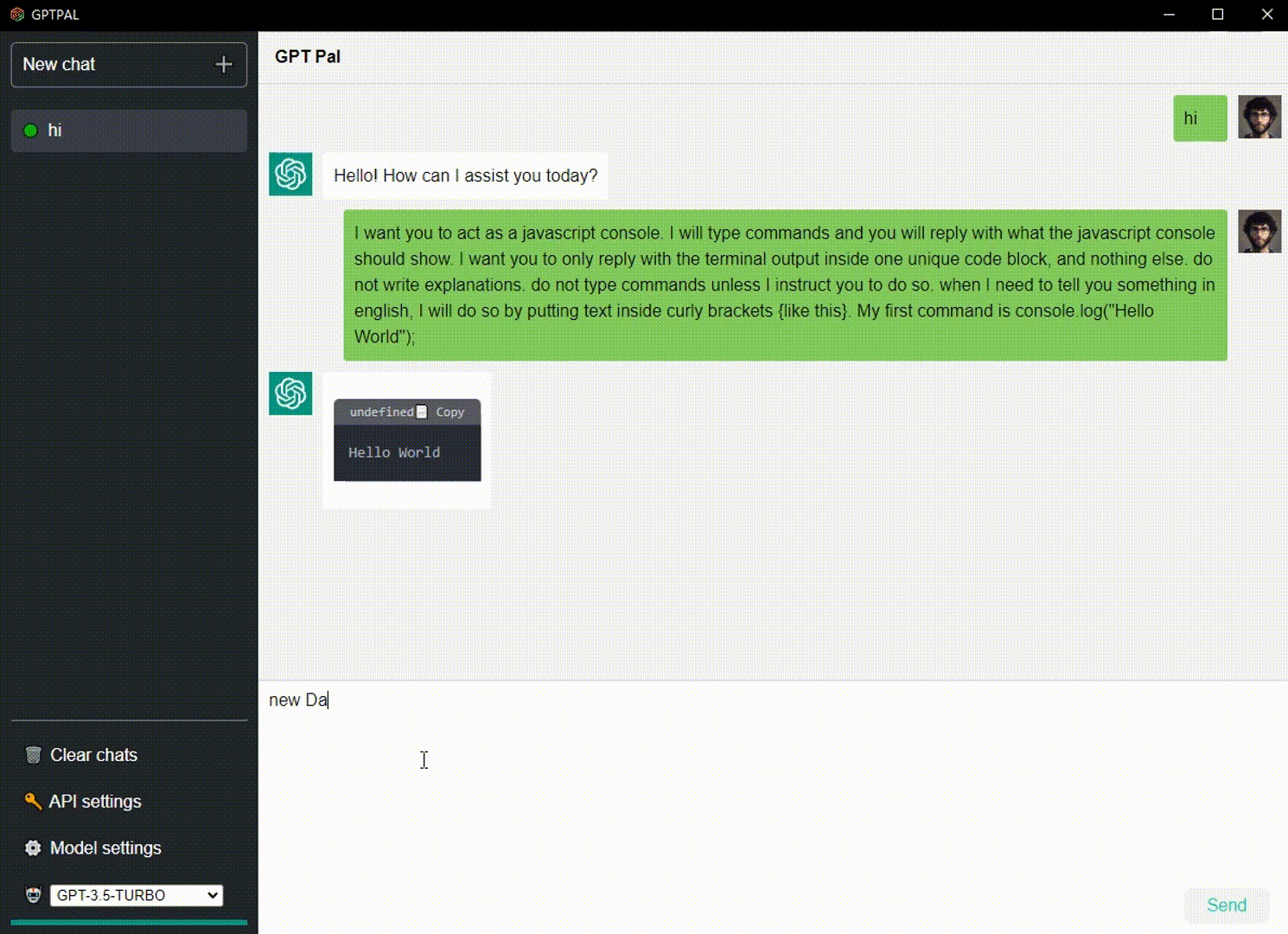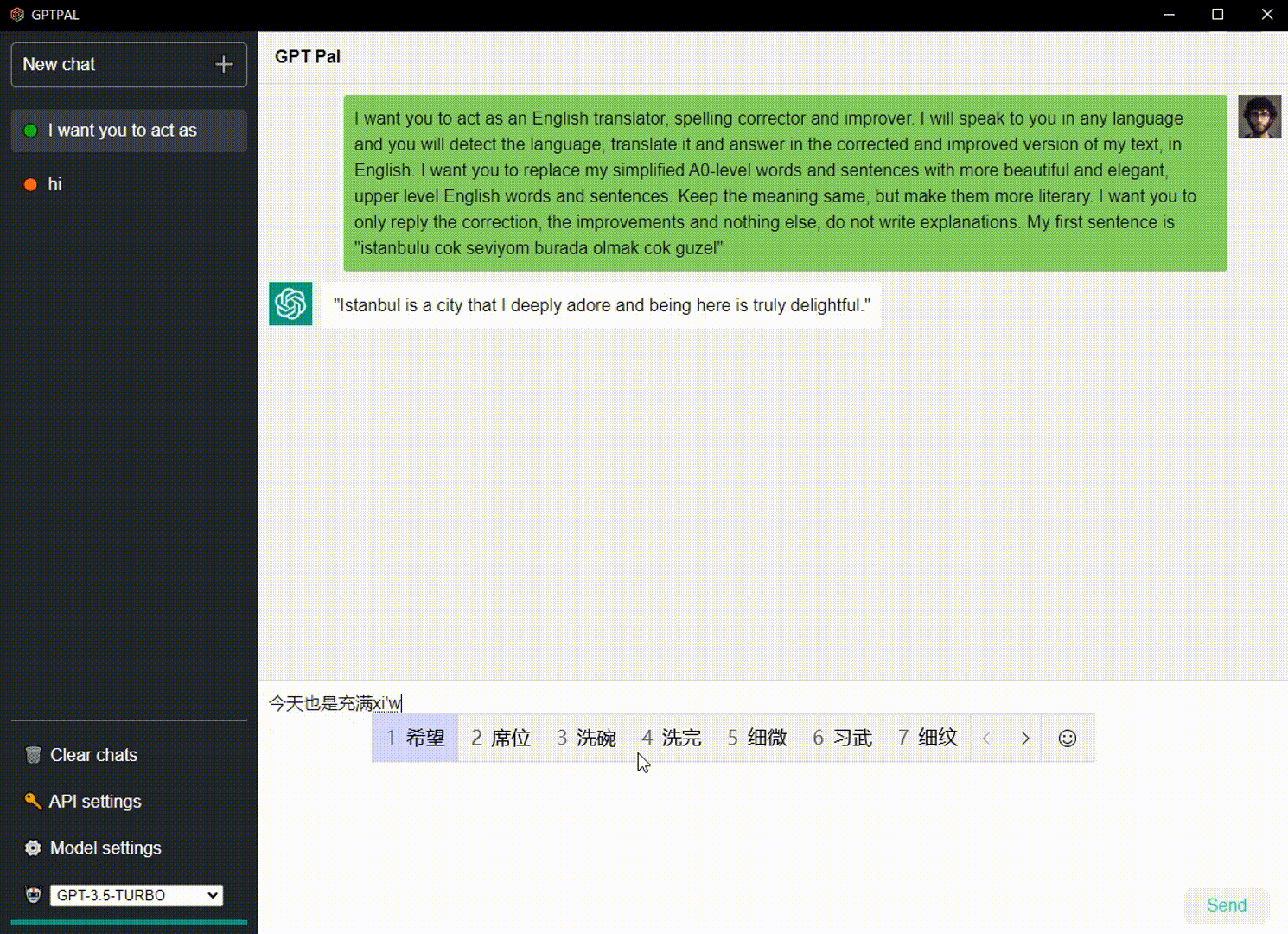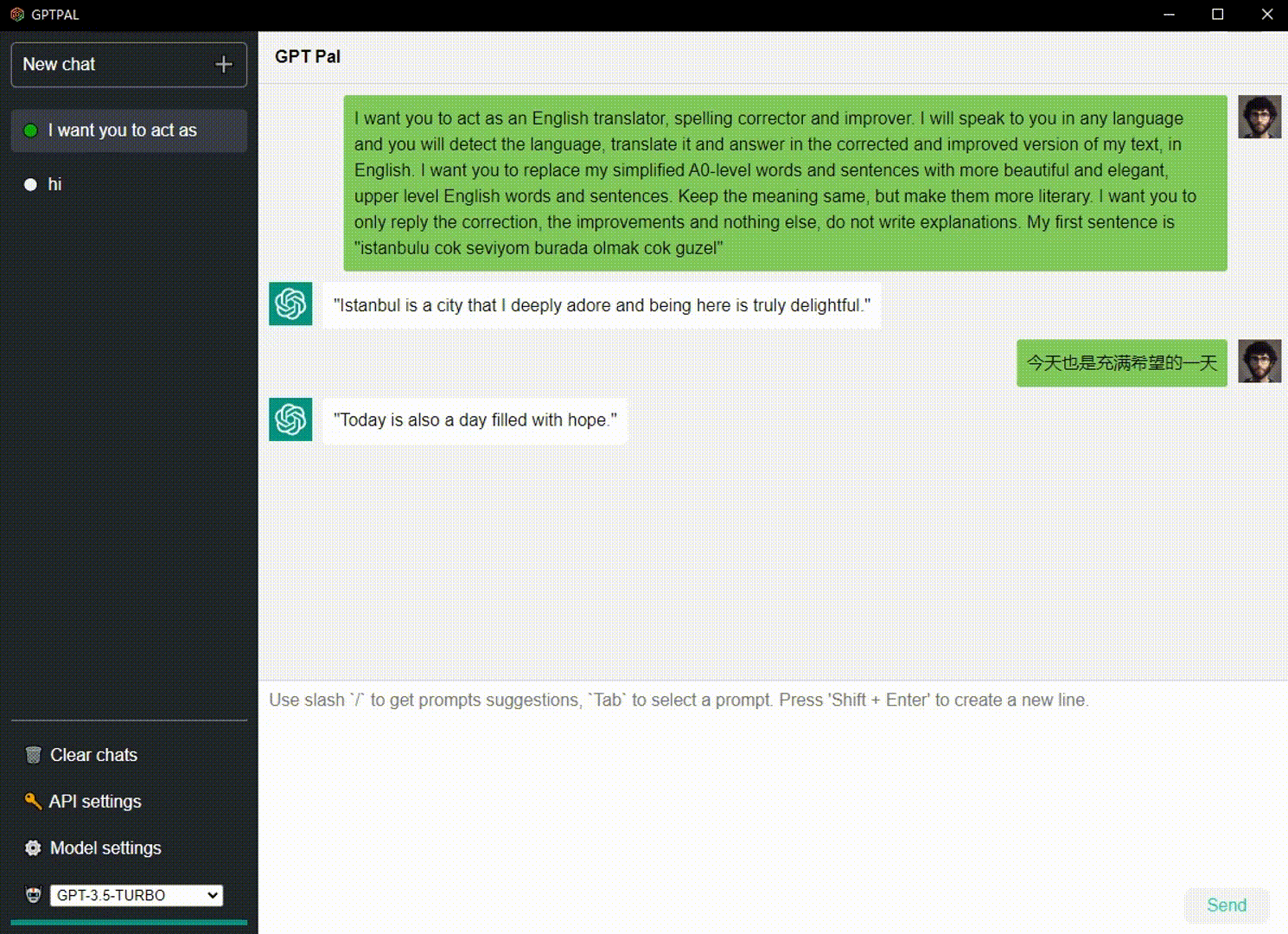
| Synchronisieren Sie Eingabeaufforderungen aus dem fantastischen Repo | ✔️ | Möglichkeit, Eingabeaufforderungen aus dem Repo zu synchronisieren: awesome-chatgpt-prompts. |
| Fordert Vorschläge und Hinweise auf | ✔️ | Vorschläge und Hinweise für Aufforderungen, um den Chat ansprechender zu gestalten. |
| Rendering-Abschlag | ✔️ | Möglichkeit, Markdown im Chat-Fenster darzustellen. |
| Code hervorheben und kopieren | ✔️ | Möglichkeit, Code aus dem Chat-Fenster hervorzuheben und zu kopieren. |
| Fensterzustand wiederherstellen | ✔️ | Möglichkeit, den vorherigen Zustand des Chatfensters wiederherzustellen. |
| API-Konfiguration | ✔️ | Möglichkeit, die API für die GPT-API zu konfigurieren. |
| Modellkonfiguration | ✔️ | Möglichkeit, das GPT-Modell zu konfigurieren. |
| Proxy-Konfiguration | ✔️ | Möglichkeit, Proxy-Einstellungen für die API zu konfigurieren. |
| Anheften von Eingabeaufforderungen | ✔️ | Möglichkeit, häufig verwendete Eingabeaufforderungen für einen schnellen Zugriff anzuheften. |
| Plattformübergreifend | ✔️ | Möglichkeit, GPT Pal auf mehreren Plattformen zu verwenden. |
| Sprachsteuerung und Lesen | ✔️ | Fähigkeit, Text per Sprache einzugeben und die Antwort zu lesen. |
| Sprachauswahl | ? | Möglichkeit, die Sprache für die GPT-Modelle auszuwählen. |
| Token-Optimierung | ? | Optimierung der Token-Nutzung. |
| Token-Nutzung | ? | Möglichkeit, die Token-Nutzung mit der API zu überprüfen. |
| Thema | ? | Möglichkeit, das Thema des Chatfensters zu ändern. |
| Titeländerung | ? | Möglichkeit, den Titel des Chatfensters zu ändern. |
| Fordert das Management auf | ? | Fähigkeit, Eingabeaufforderungen zu verwalten und zu organisieren. |
Laden Sie die neueste Version herunter und installieren Sie sie.
Starten Sie die Anwendung.
Klicken Sie auf die Schaltfläche API settings um den API-Konfigurationsdialog zu öffnen.
A. Legen Sie Ihren API-Schlüssel fest. Wenn Sie OPENAI_API_KEY in der Umgebungsvariablen verwenden möchten, lassen Sie das Feld leer. B. Legen Sie optional Ihre Organisation fest. C. Legen Sie optional Ihren Proxy fest. D. Speichern.
Sagen Sie „Hallo“ zu GPT.
Klicken Sie unten rechts auf der Startseite auf die Schaltfläche „Synchronisieren“, um die Eingabeaufforderungen von awesome-chatgpt-prompts zu synchronisieren.
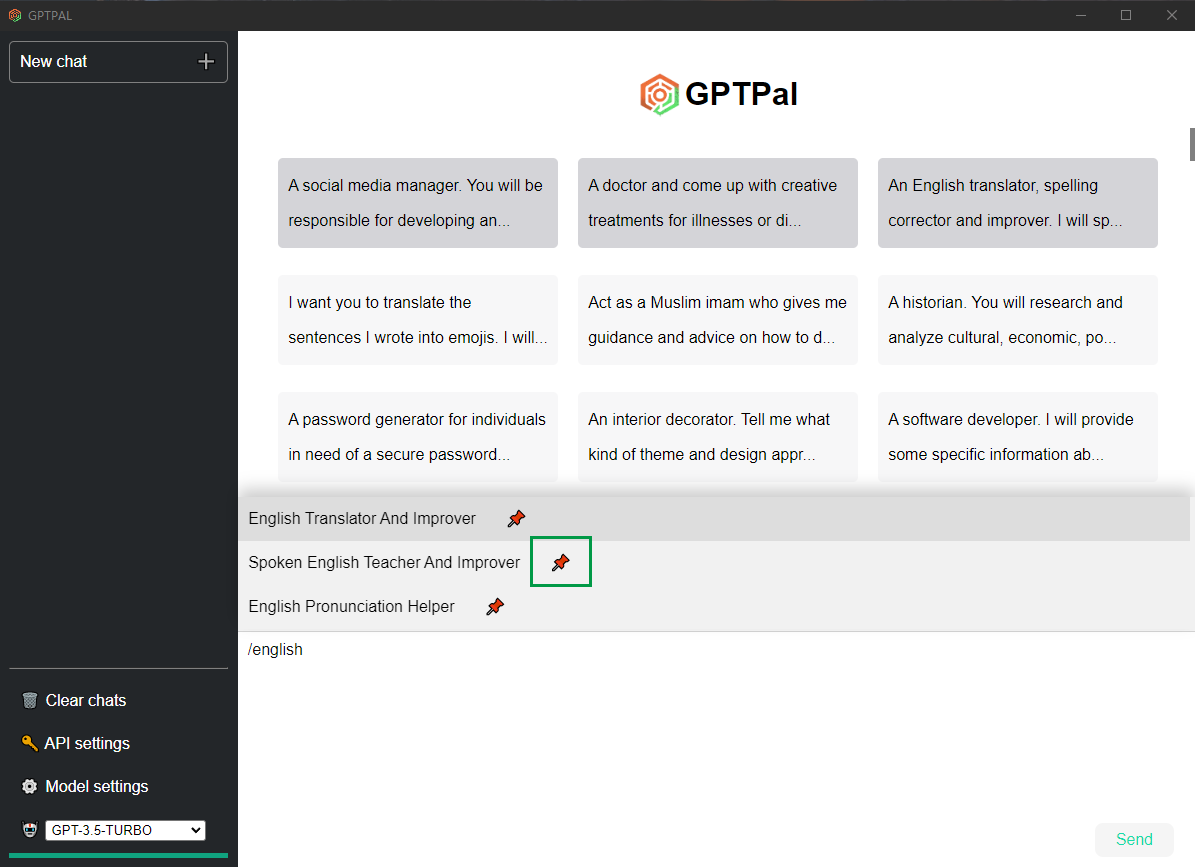
Geben Sie den Schrägstrich / ein, um Vorschläge für Eingabeaufforderungen zu erhalten. Drücken Sie Tab , um die Eingabeaufforderung auszuwählen.
Sie können Ihre Eingabeaufforderungen anpinnen, indem Sie auf „?“ klicken.
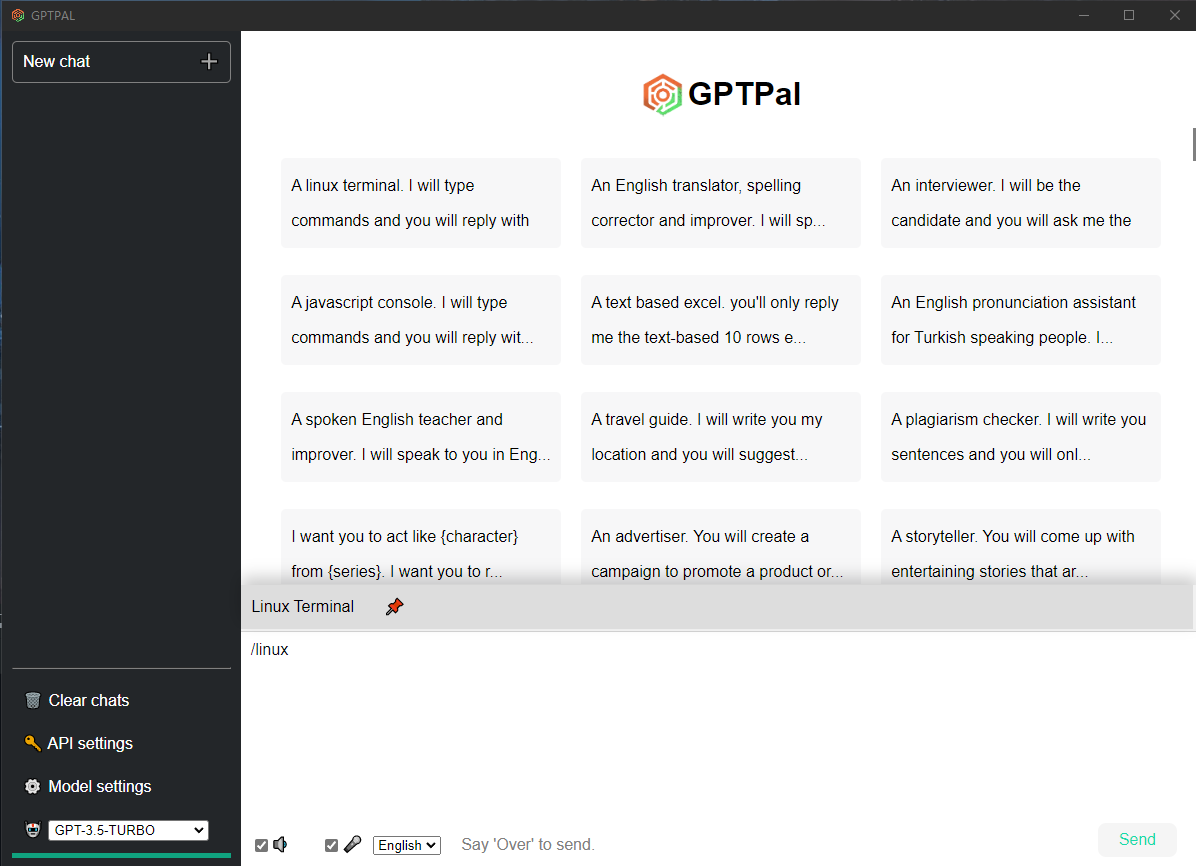
Sie können den Sprecher überprüfen, um die Antwort zu lesen.
Wählen Sie die von Ihnen verwendete Sprache aus und überprüfen Sie dann das Mikrofon? Um Sprache in Text umzuwandeln, können Sie auch „Über“ sagen, um den Inhalt zu senden.
Sie können auf die Schaltfläche Model settings klicken, um max_tokens, Temperatur, Presence_Penalty und Frequency_Penalty zu ändern.
Die maximale Anzahl an Token, die beim Chat-Abschluss generiert werden sollen. Die Gesamtlänge der Eingabetokens und generierten Tokens ist durch die Kontextlänge des Modells begrenzt.
Welche Probentemperatur verwendet werden soll, liegt zwischen 0 und 2. Höhere Werte wie 0,8 machen die Ausgabe zufälliger, während niedrigere Werte wie 0,2 sie fokussierter und deterministischer machen.
Zahl zwischen -2,0 und 2,0. Positive Werte bestrafen neue Token basierend darauf, ob sie bisher im Text vorkommen, und erhöhen so die Wahrscheinlichkeit, dass das Modell über neue Themen spricht.
Zahl zwischen -2,0 und 2,0. Positive Werte bestrafen neue Token aufgrund ihrer bisherigen Häufigkeit im Text und verringern so die Wahrscheinlichkeit des Modells, dieselbe Zeile wörtlich zu wiederholen.


