T2M GPT
1.0.0
Pytorch-Implementierung des Papiers „T2M-GPT: Generating Human Motion from Textual Descriptions with Discrete Representations“
[Projektseite] [Papier] [Notebook-Demo] [HuggingFace] [Weltraum-Demo] [T2M-GPT+]

Wenn unser Projekt für Ihre Forschung hilfreich ist, denken Sie bitte darüber nach, Folgendes zu zitieren:
@inproceedings{zhang2023generating,
title={T2M-GPT: Generating Human Motion from Textual Descriptions with Discrete Representations},
author={Zhang, Jianrong and Zhang, Yangsong and Cun, Xiaodong and Huang, Shaoli and Zhang, Yong and Zhao, Hongwei and Lu, Hongtao and Shen, Xi},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2023},
}
| Text: Ein Mann tritt vor und macht einen Handstand. | ||||
|---|---|---|---|---|
| GT | T2M | MDM | MotionDiffuse | Unsere |
 | 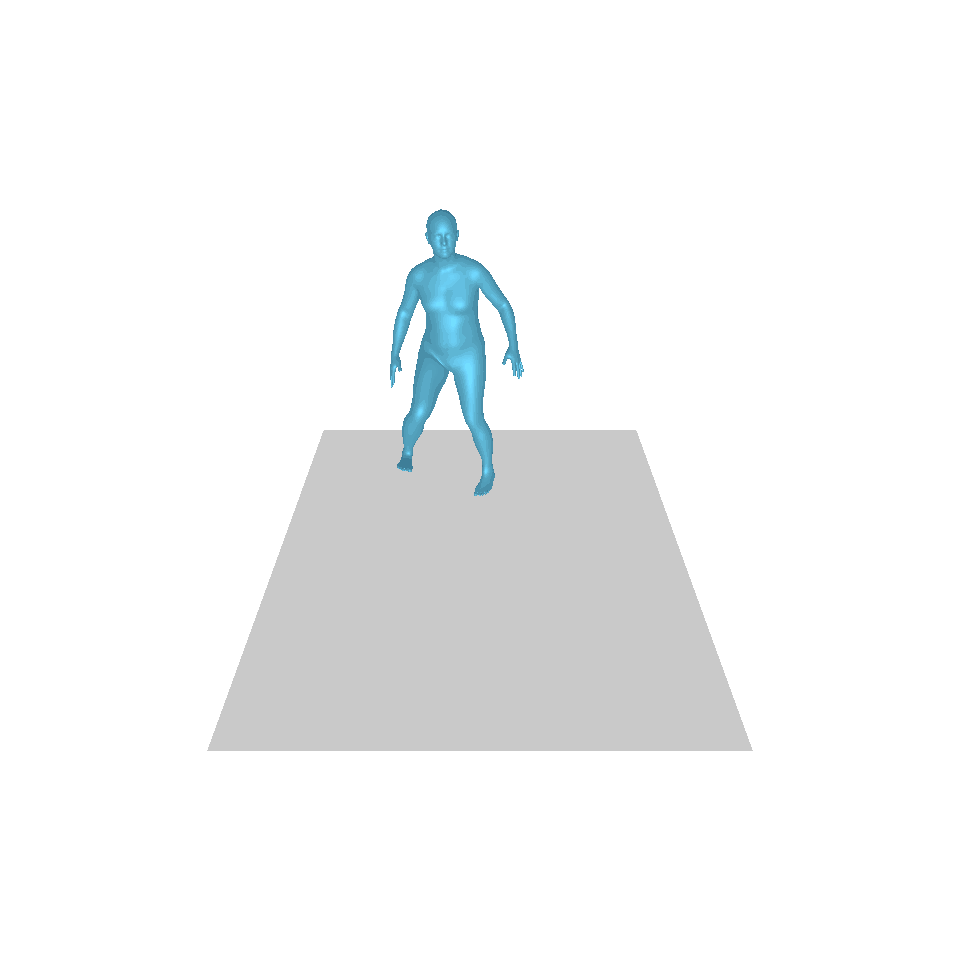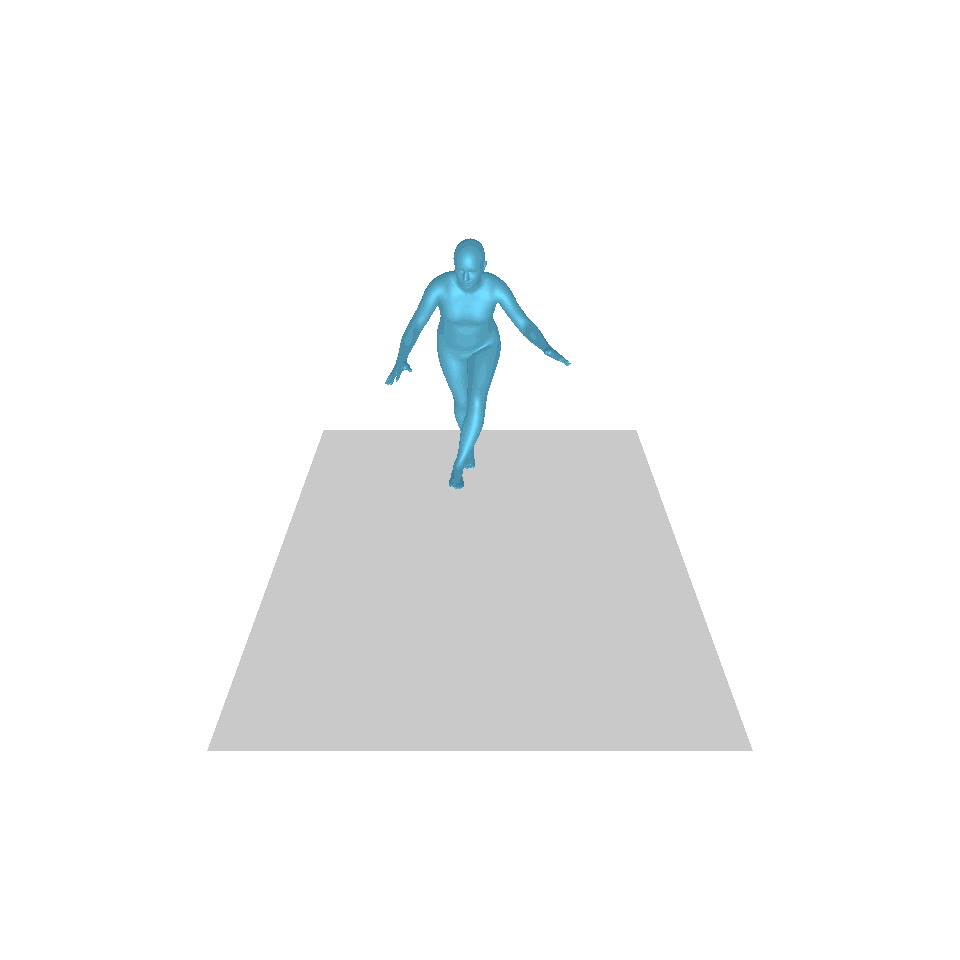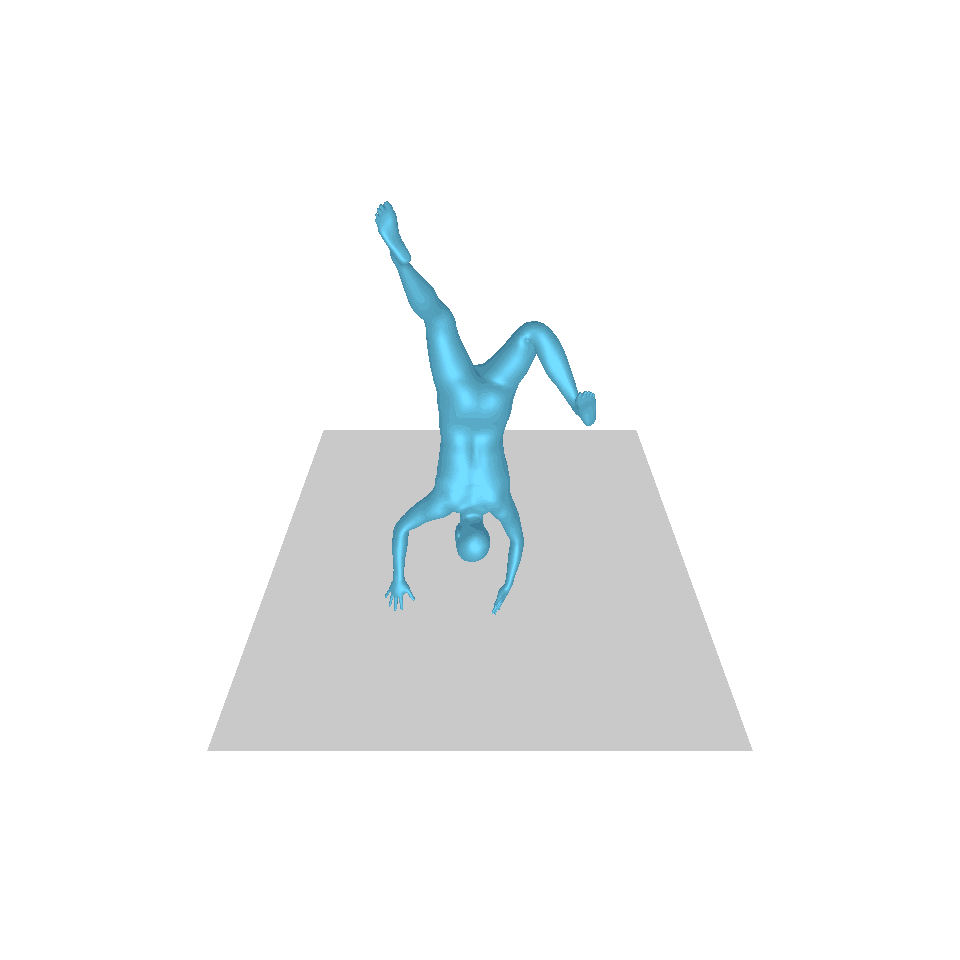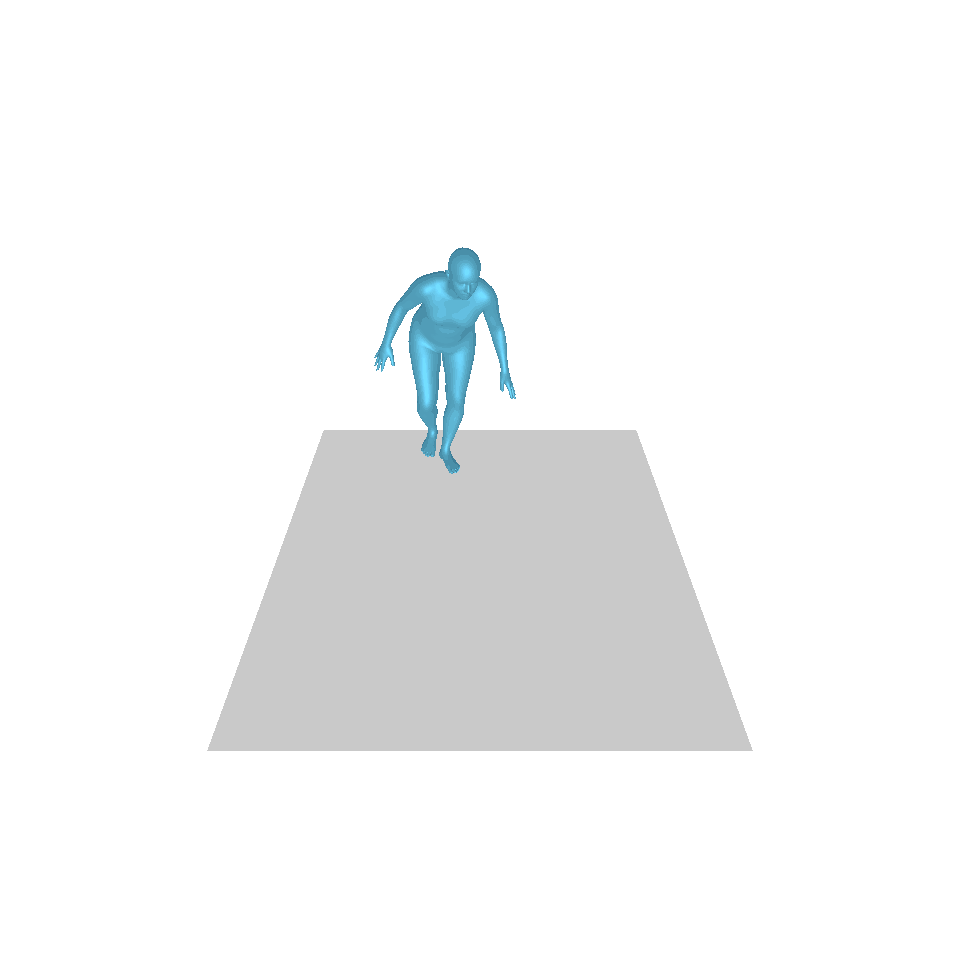 |  | 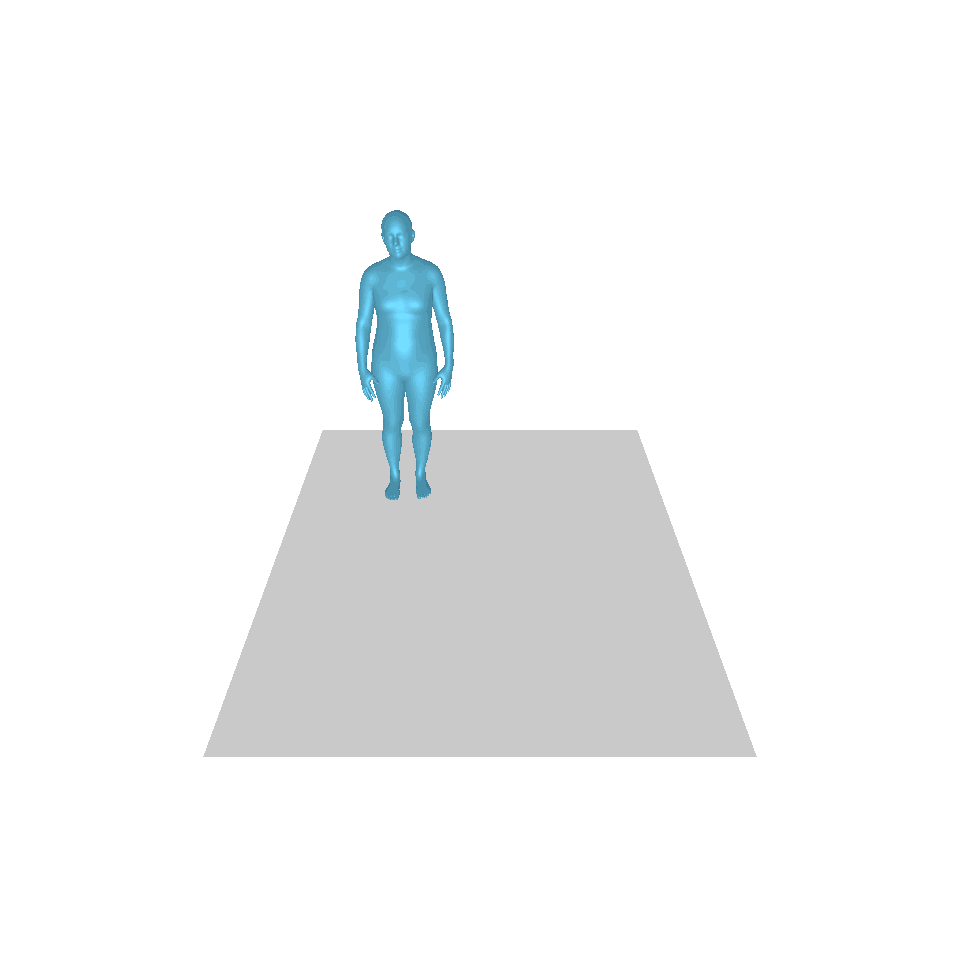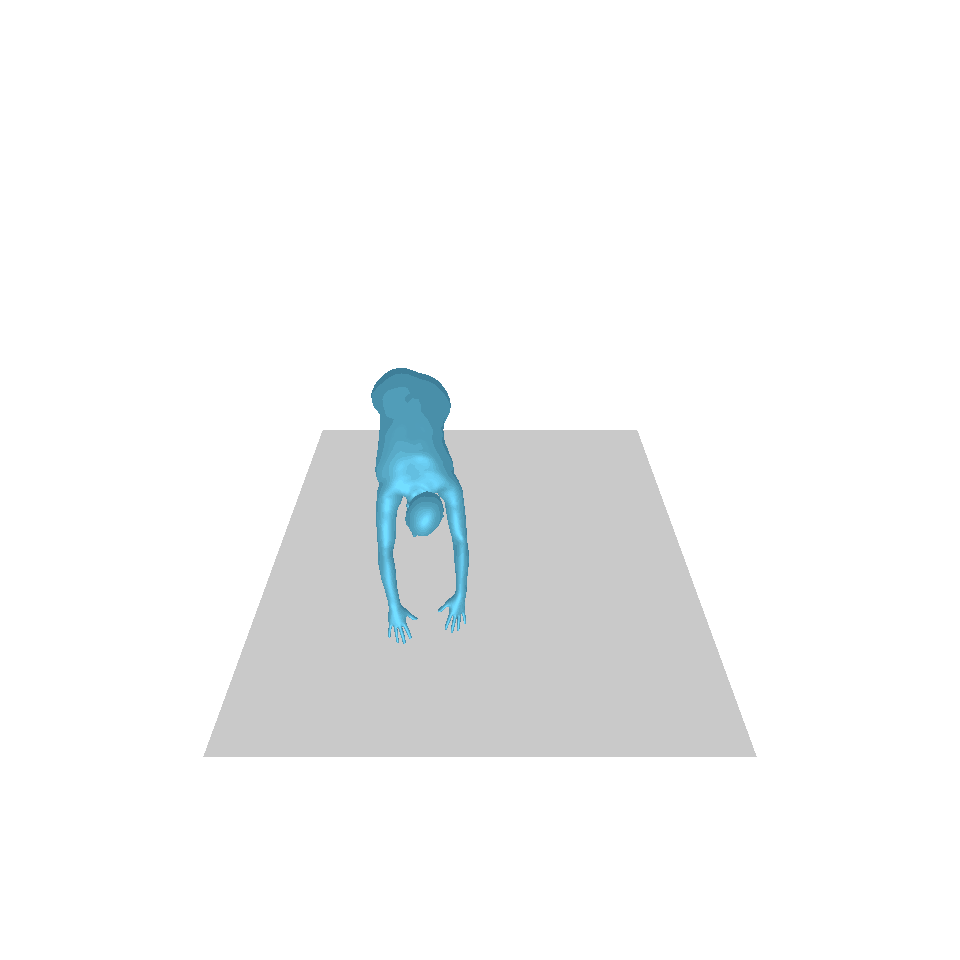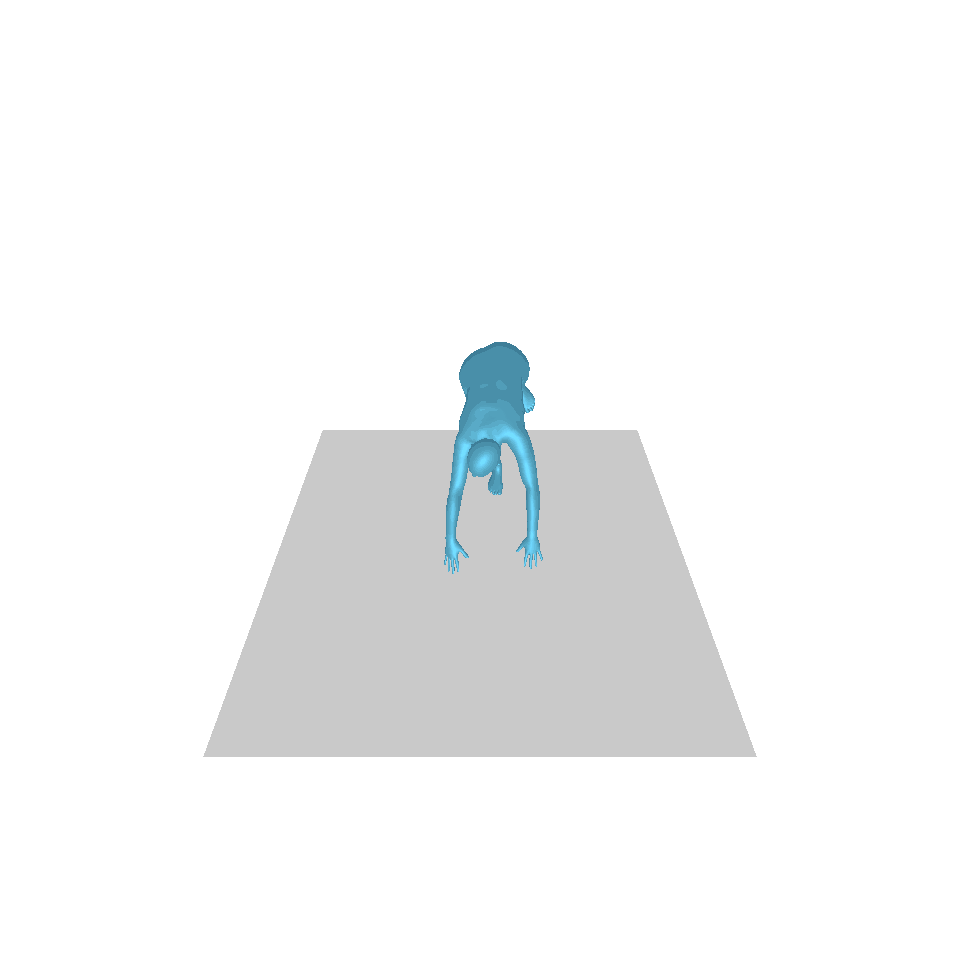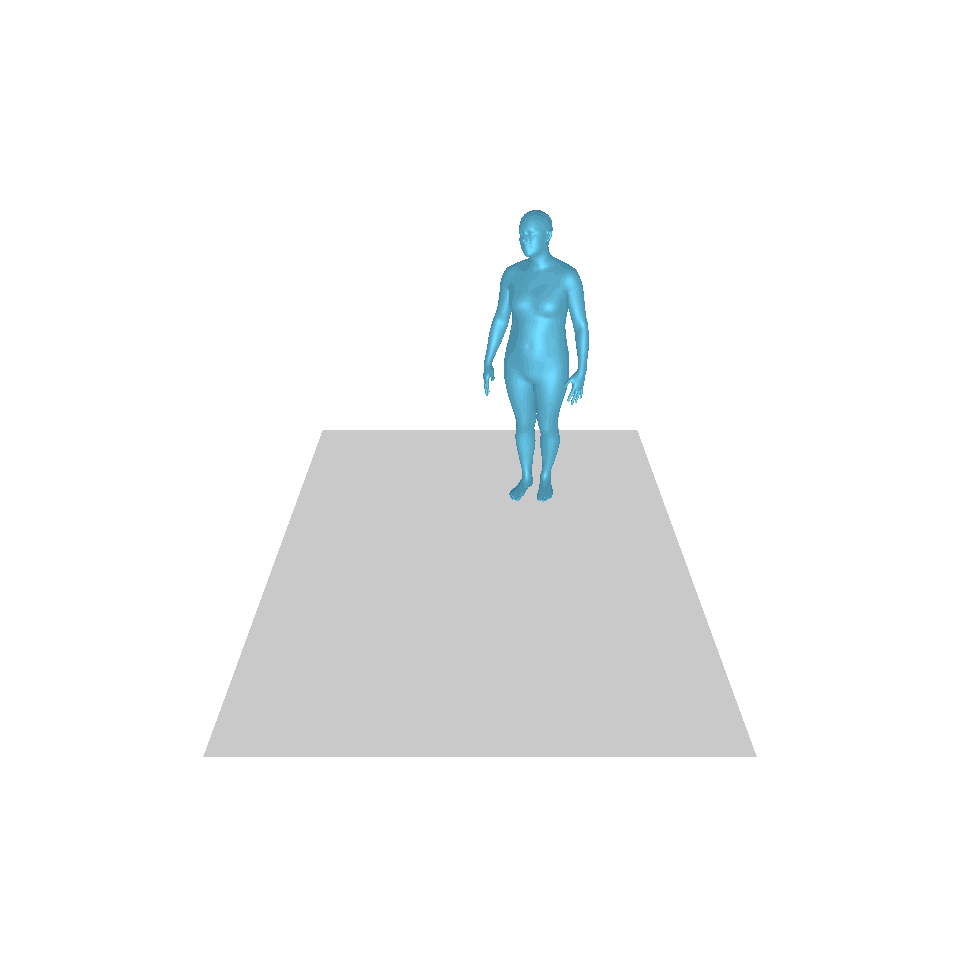 | 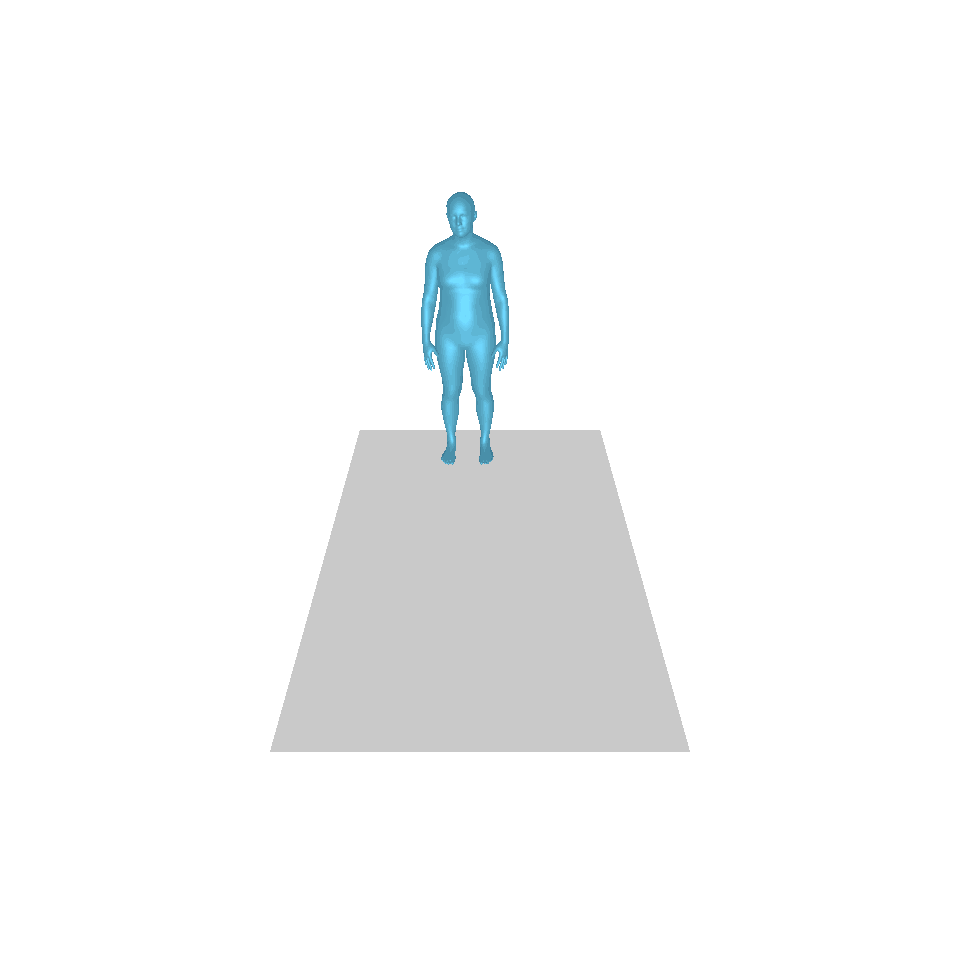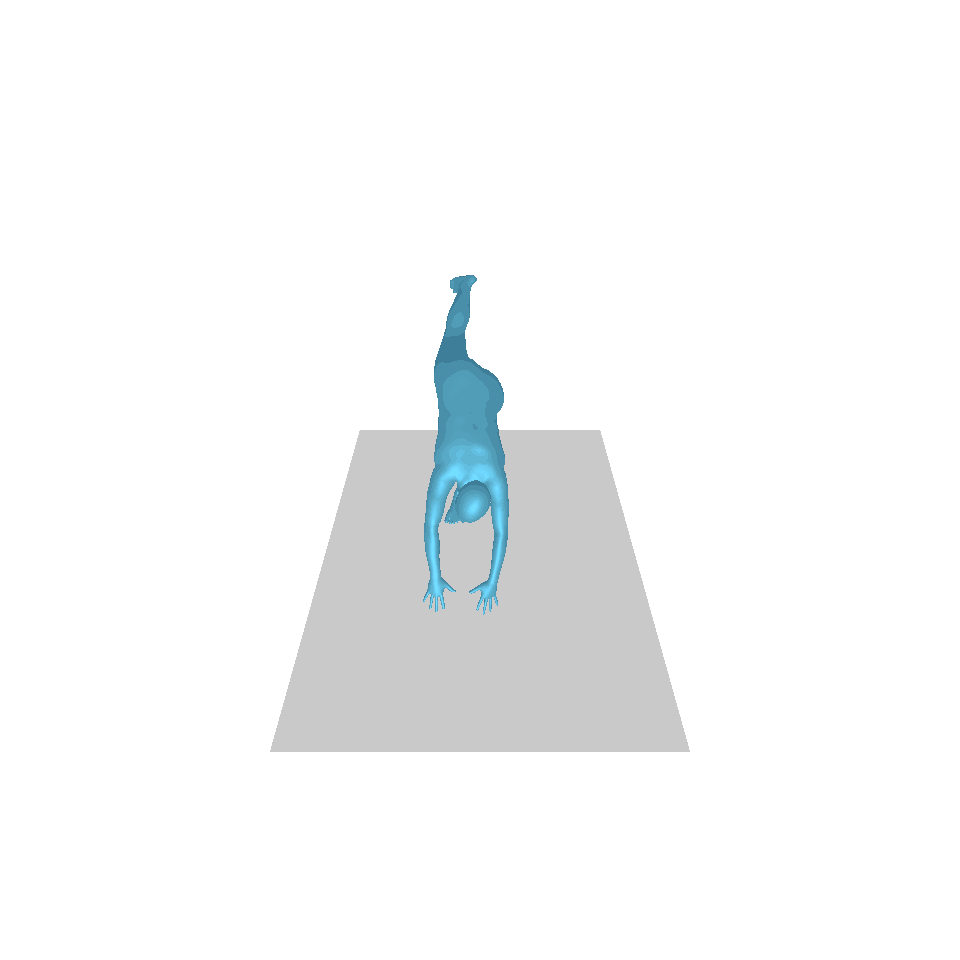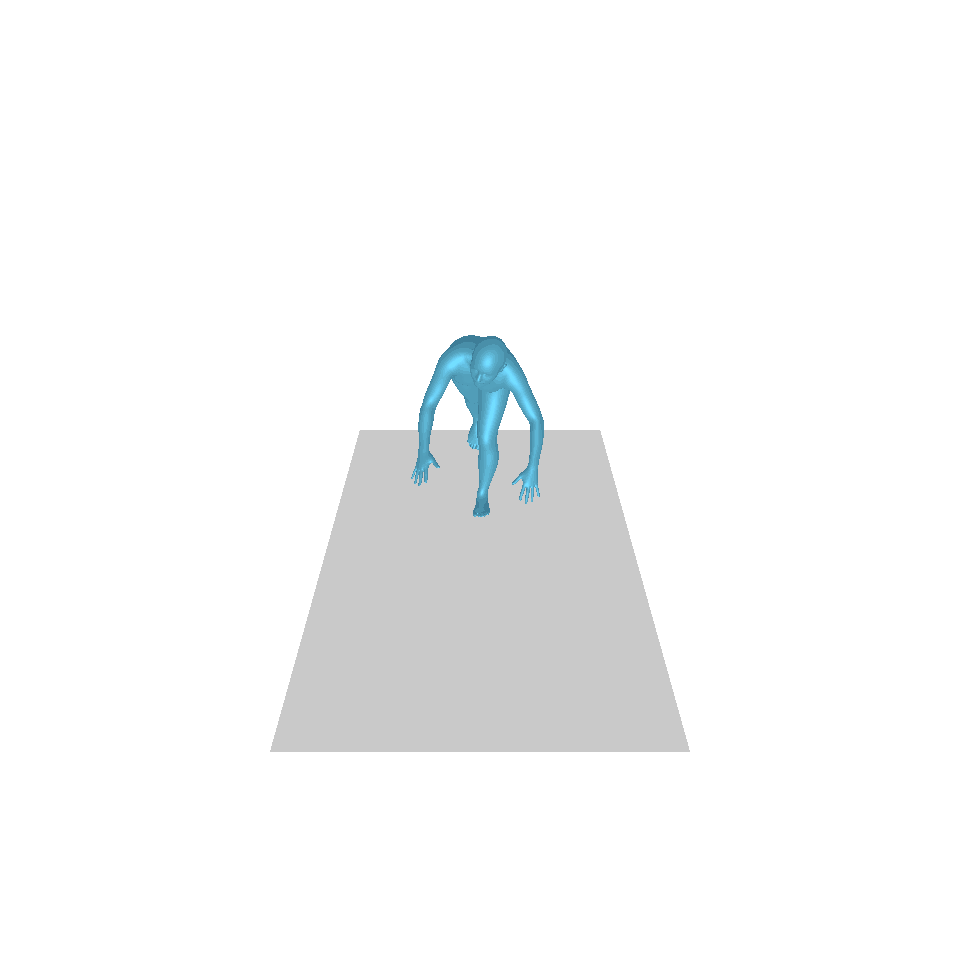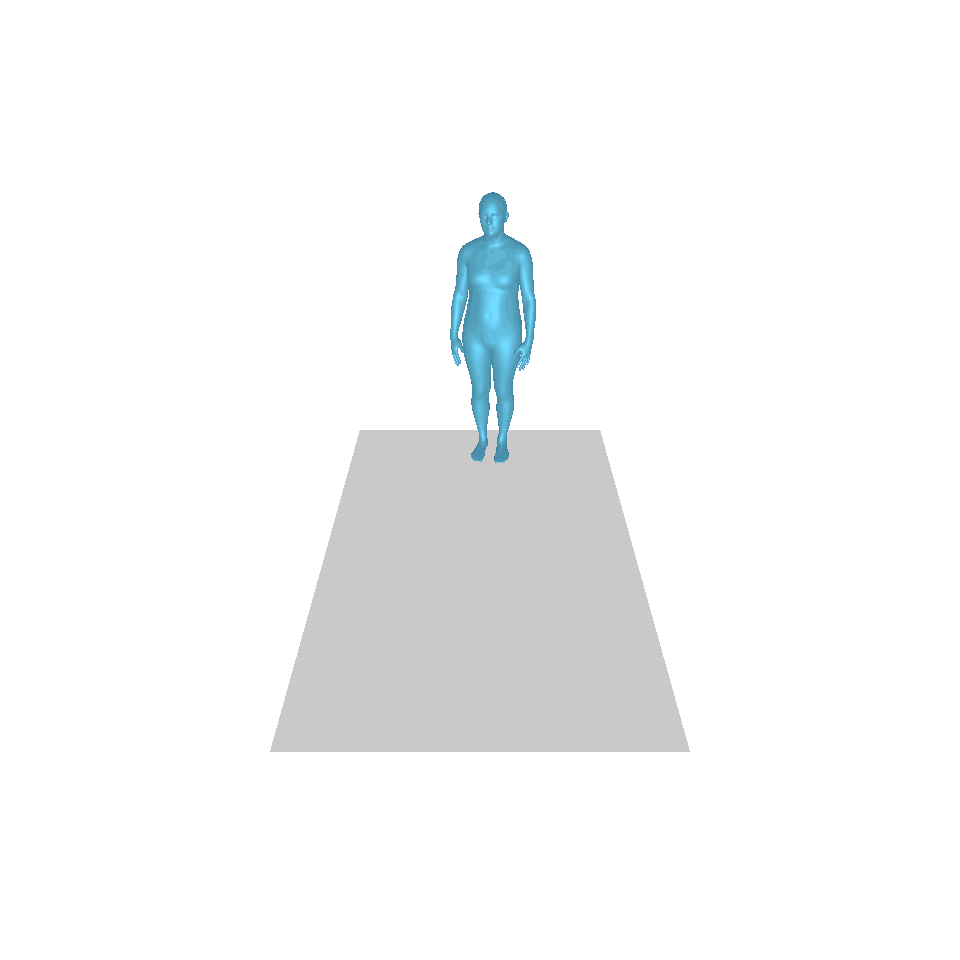 |
| Text: Ein Mann erhebt sich vom Boden, geht im Kreis und setzt sich wieder auf den Boden. | ||||
| GT | T2M | MDM | MotionDiffuse | Unsere |
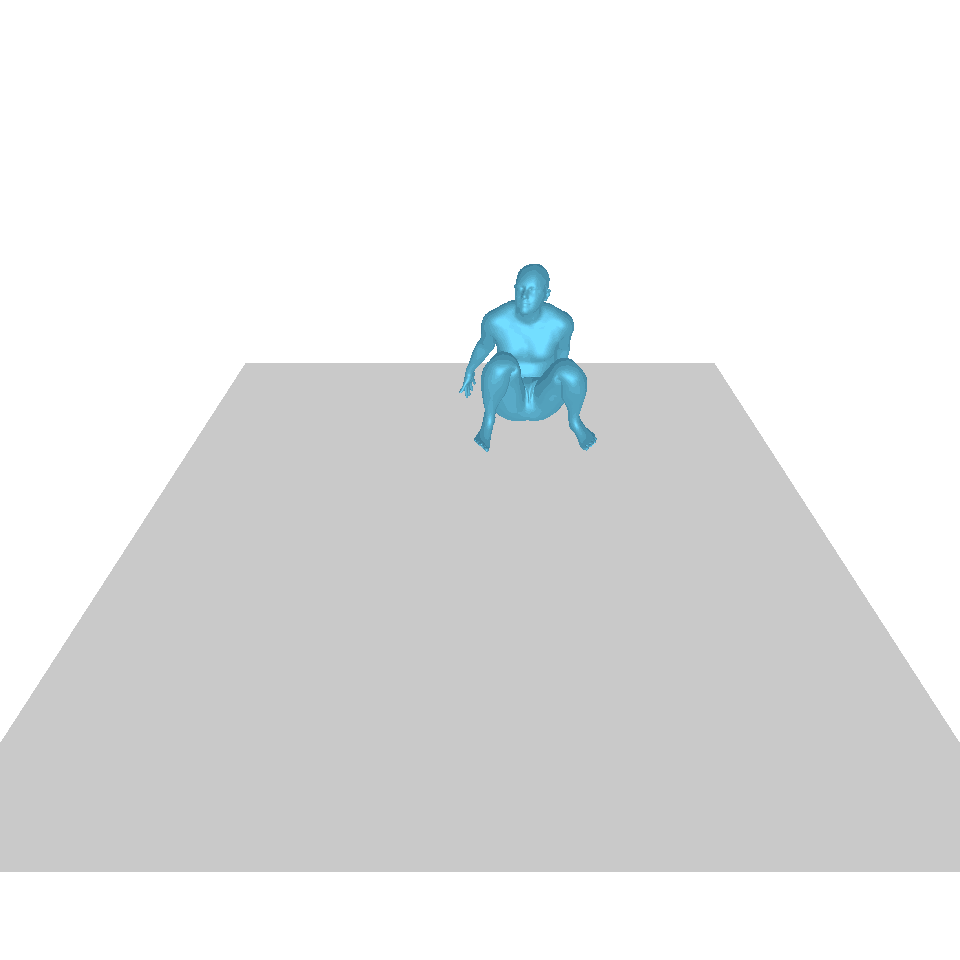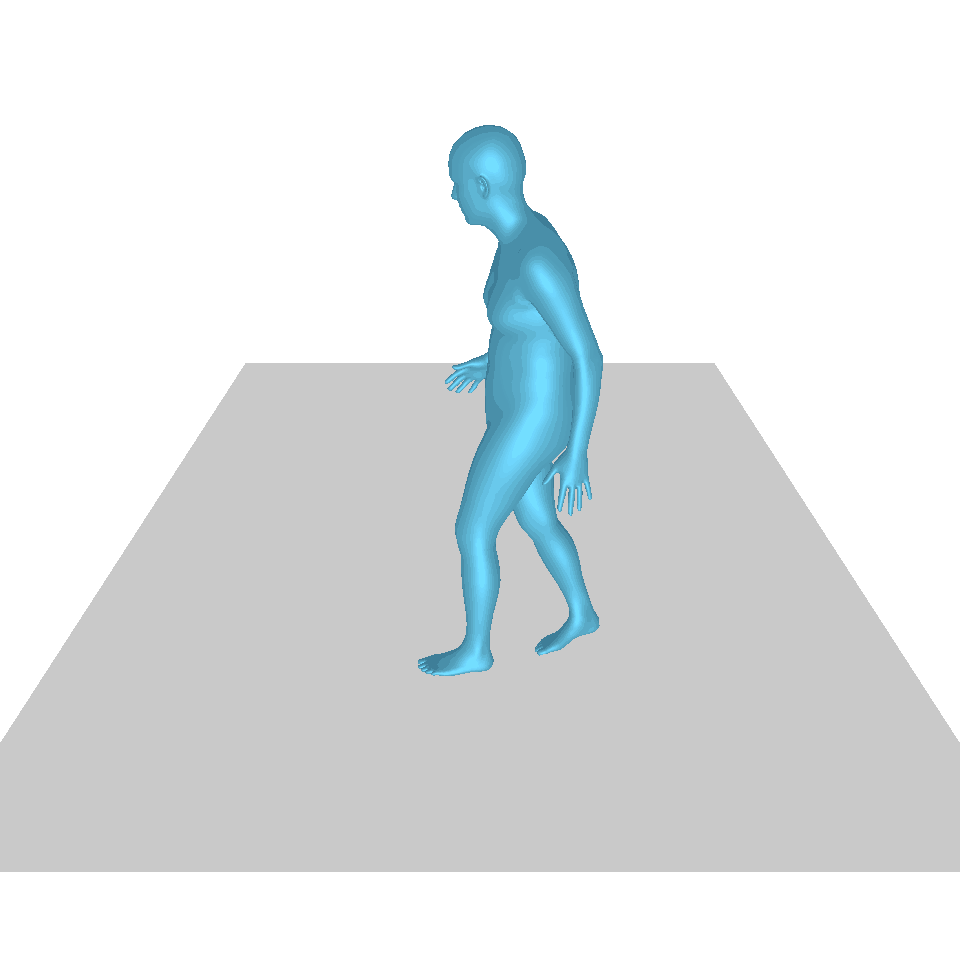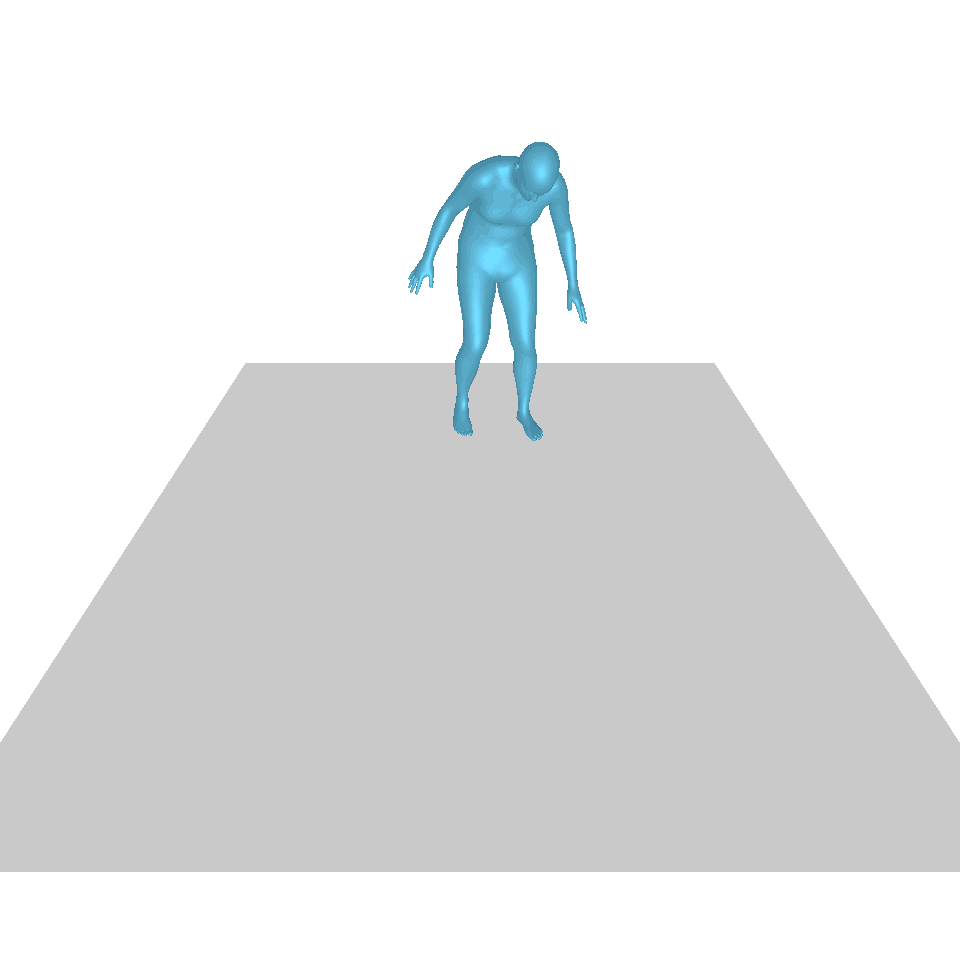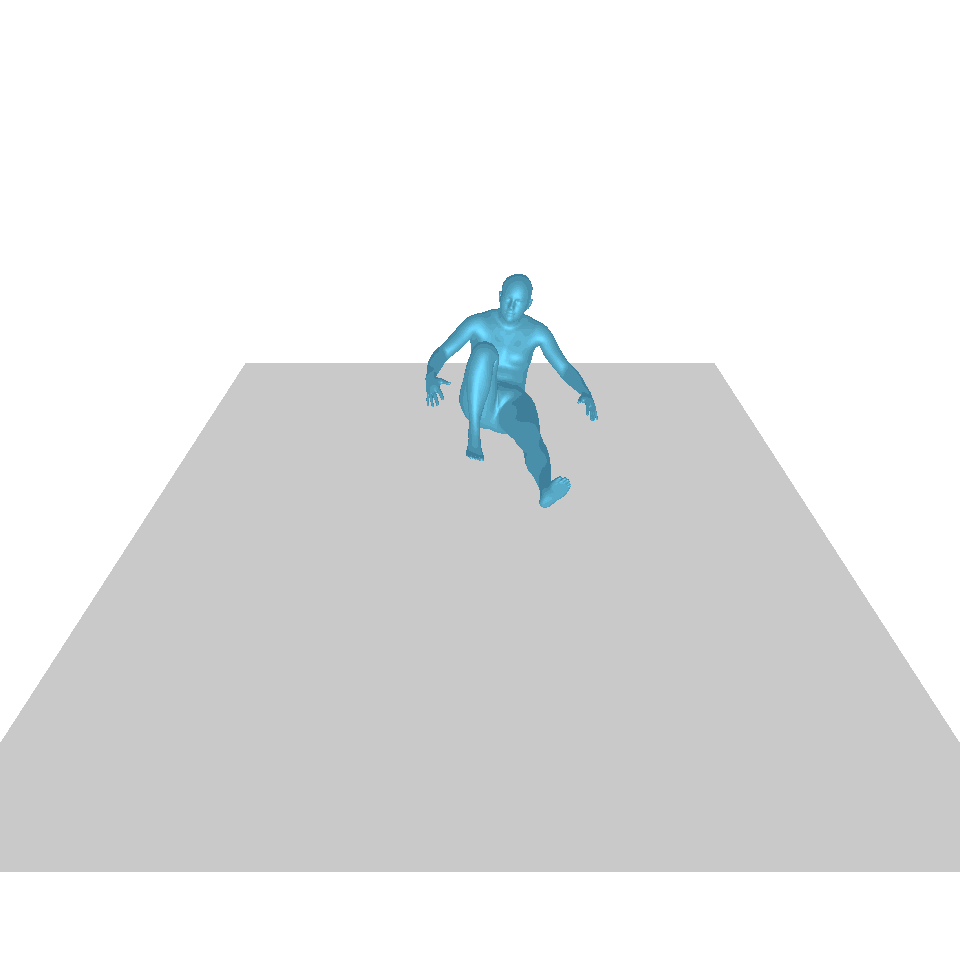 | 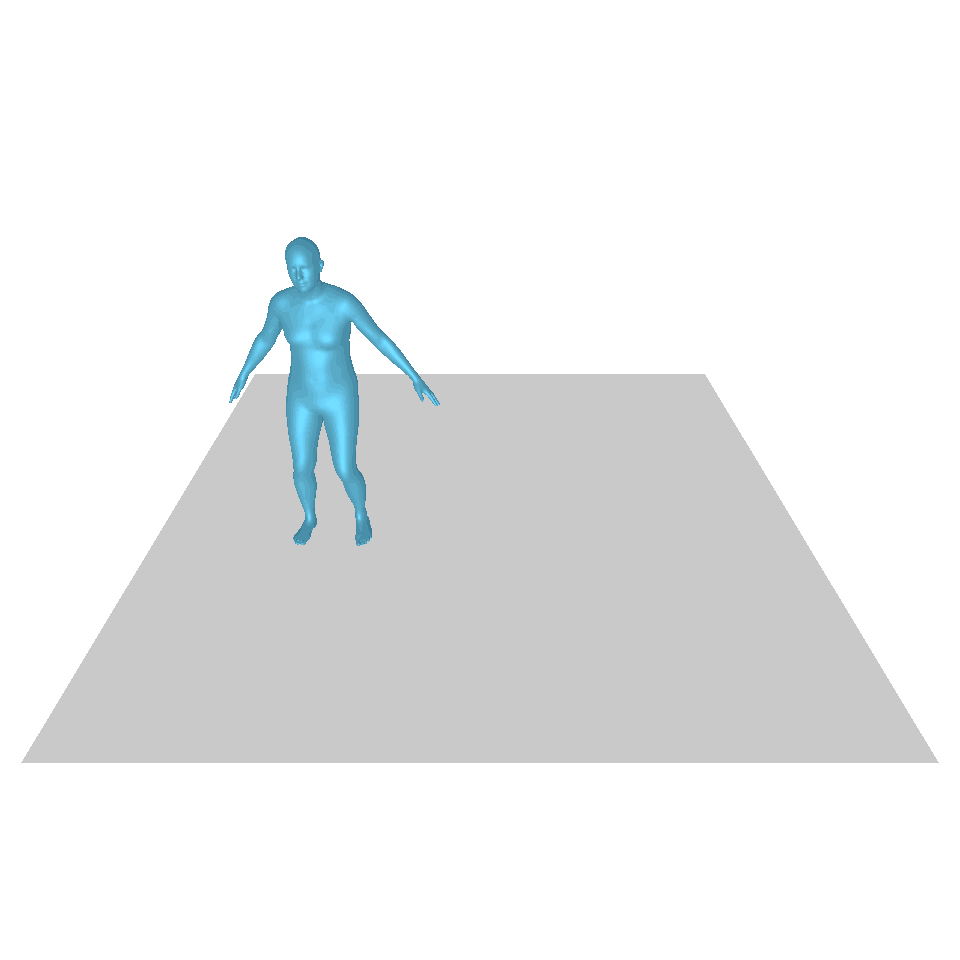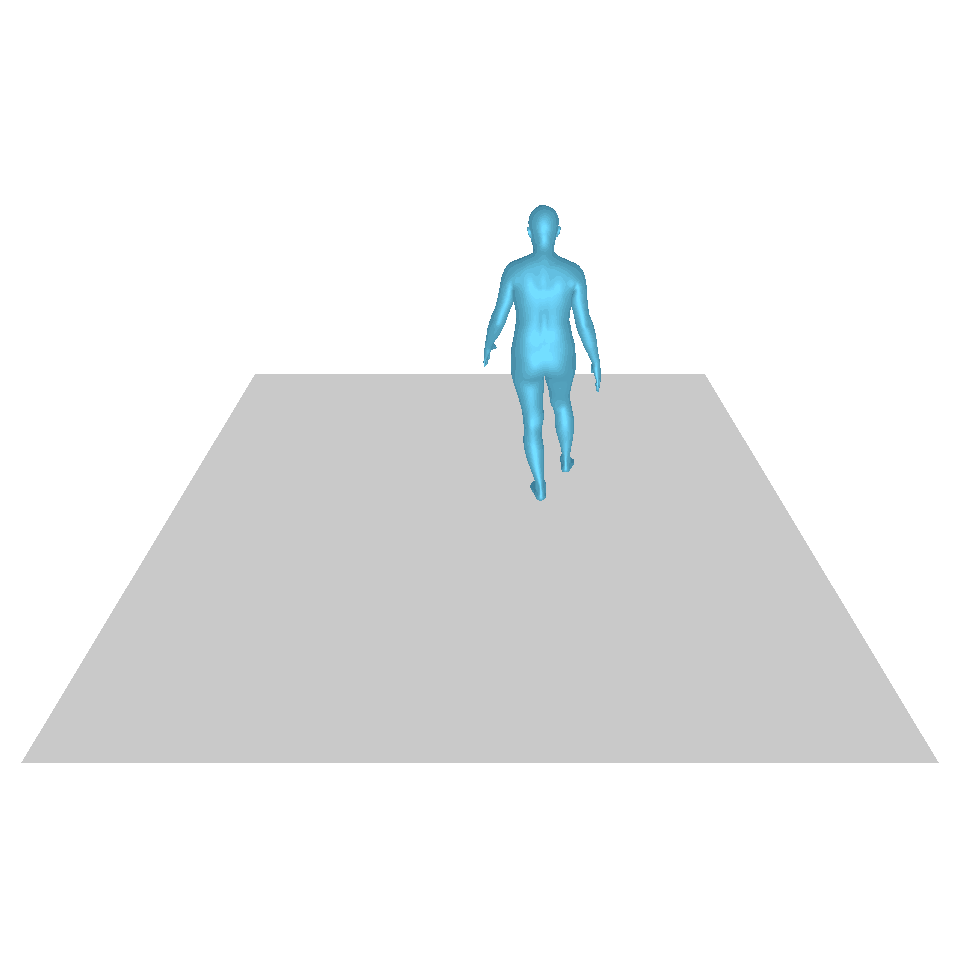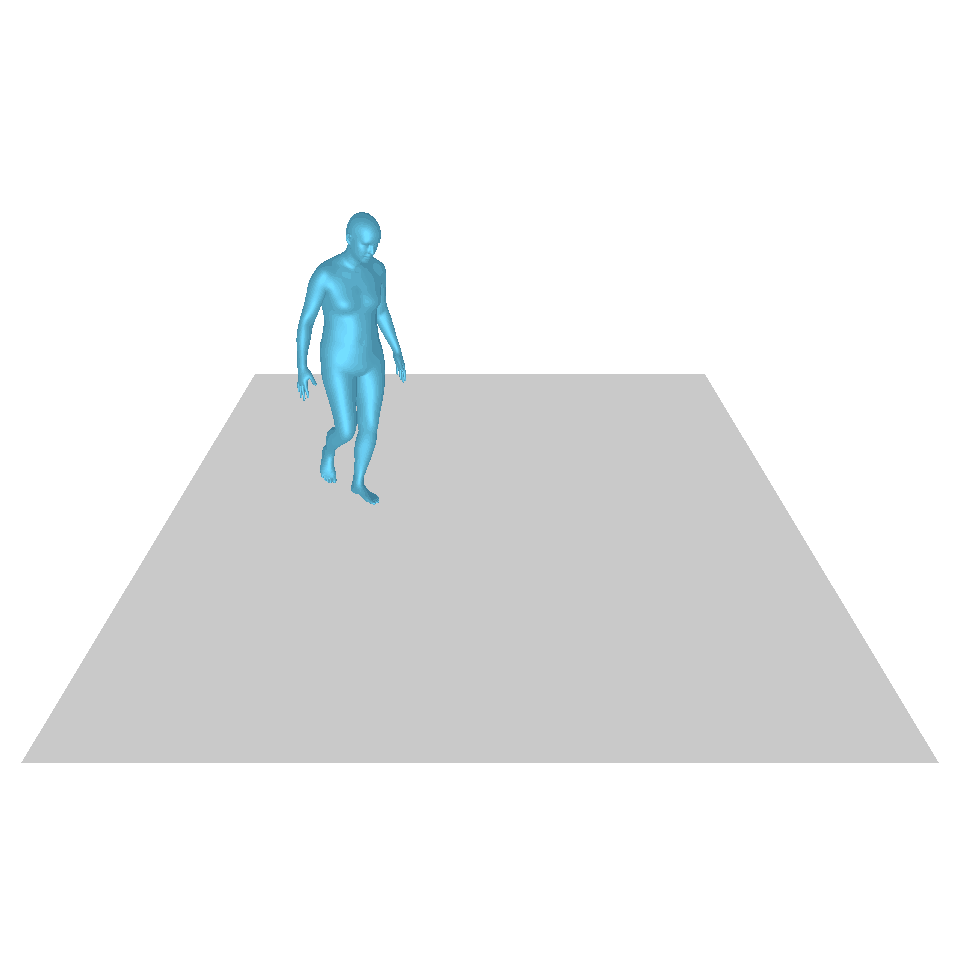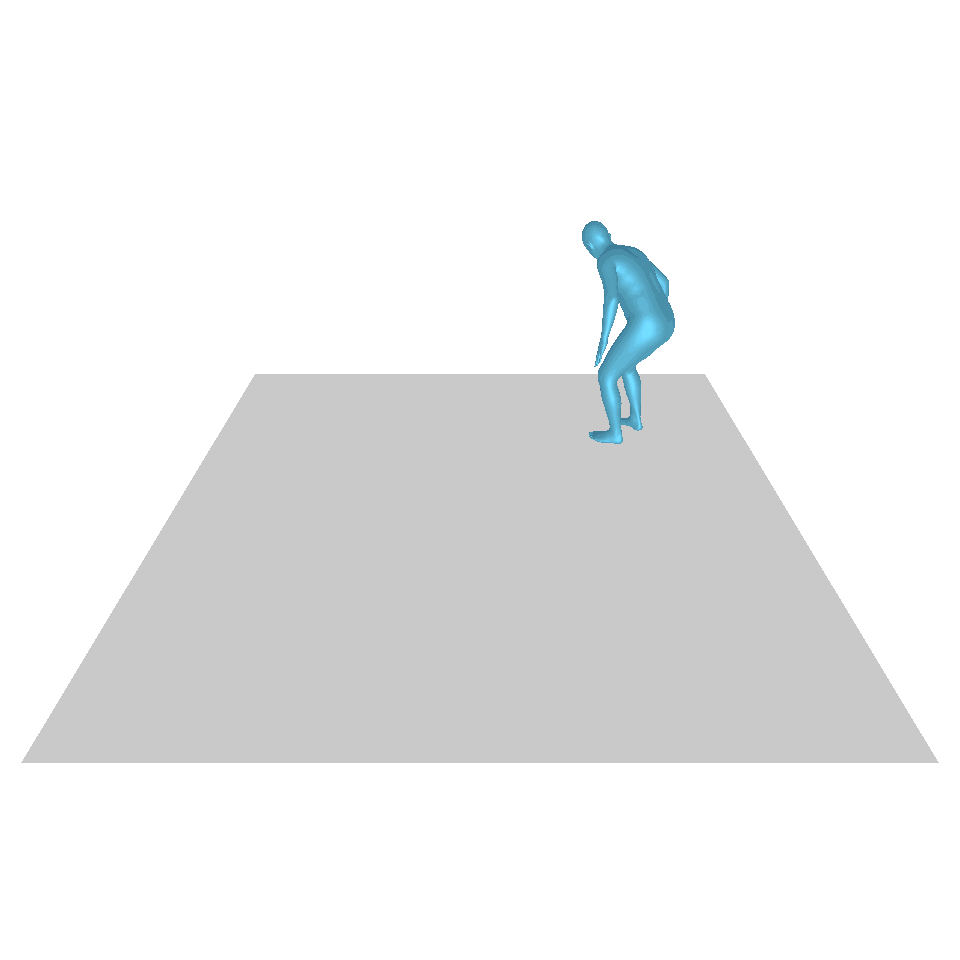 | 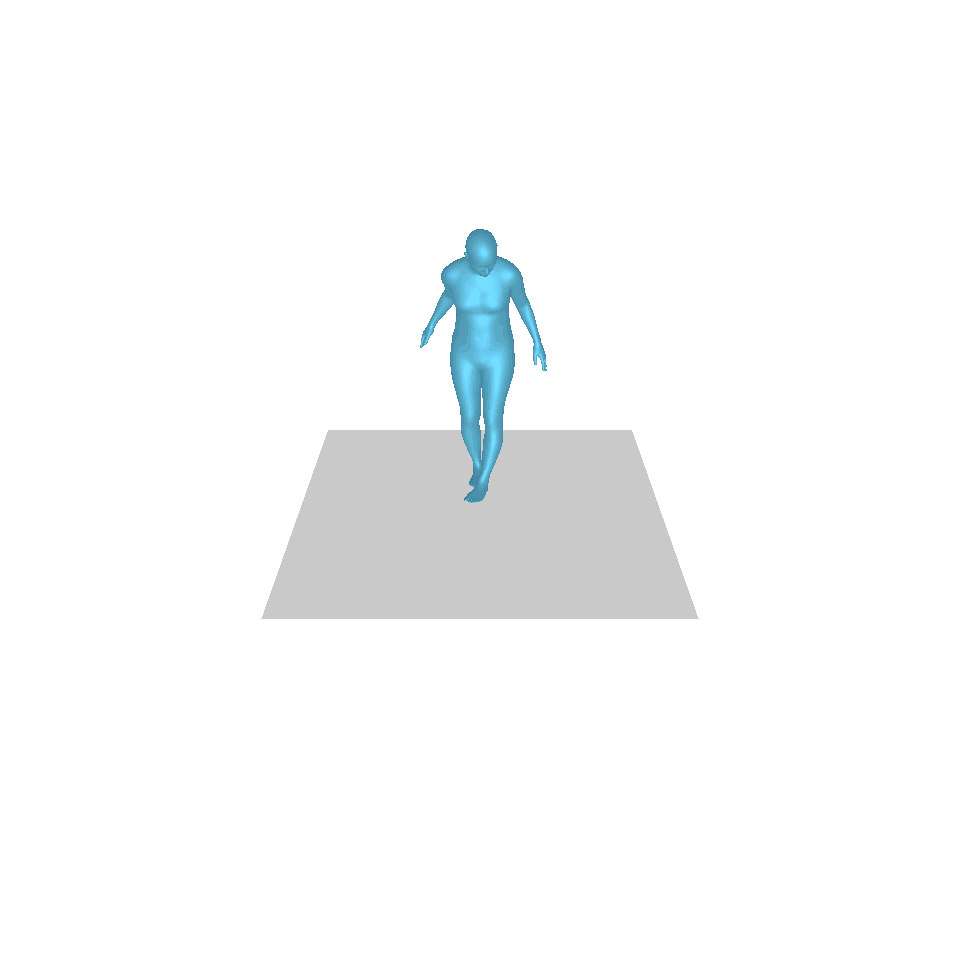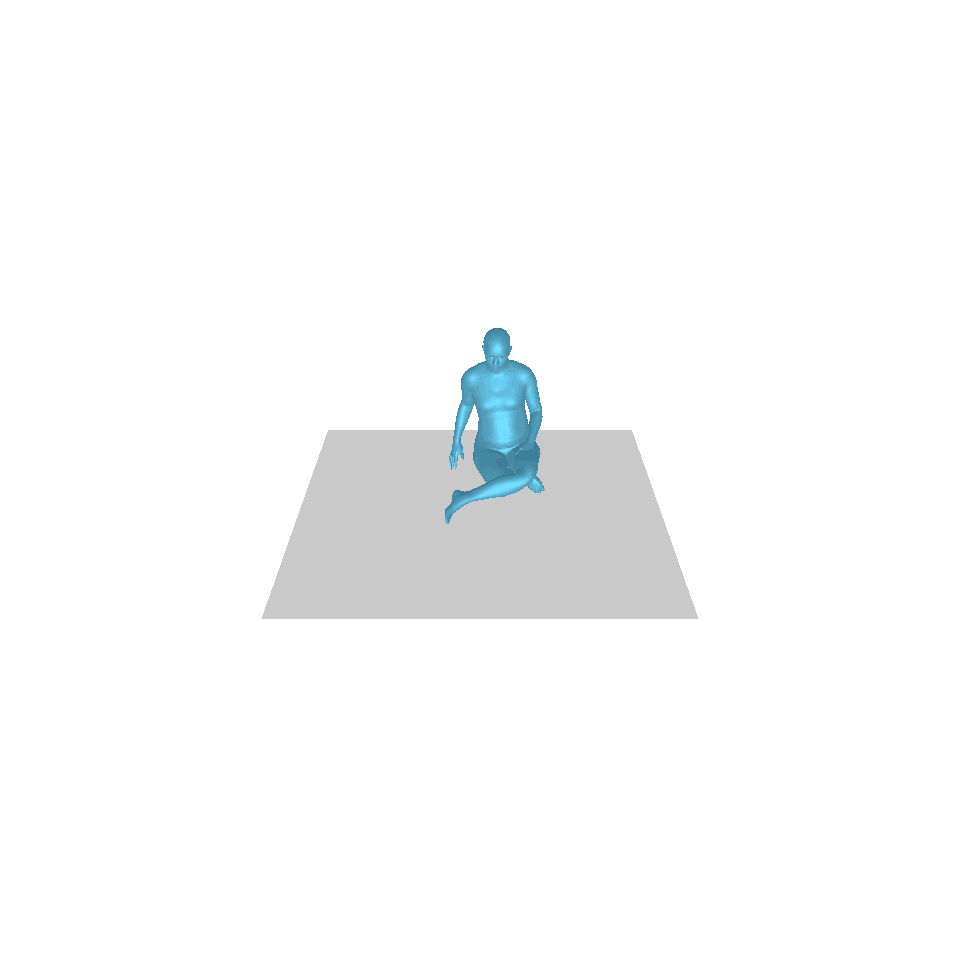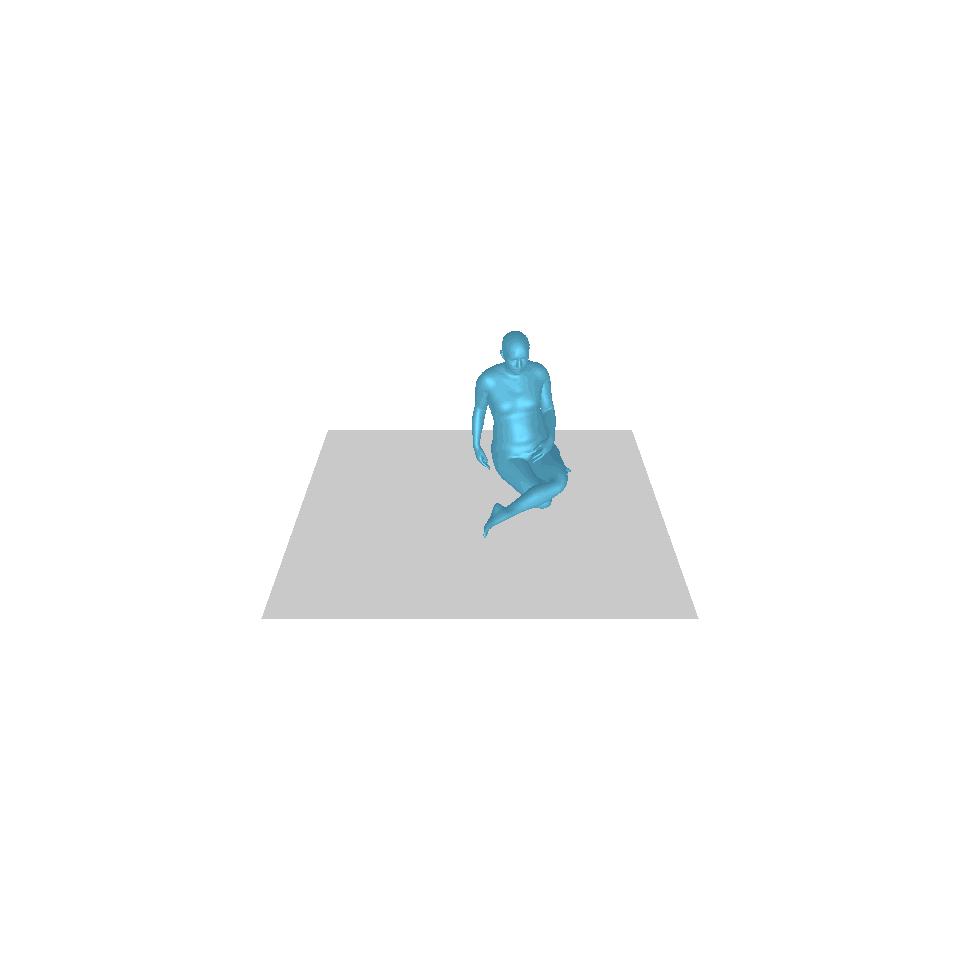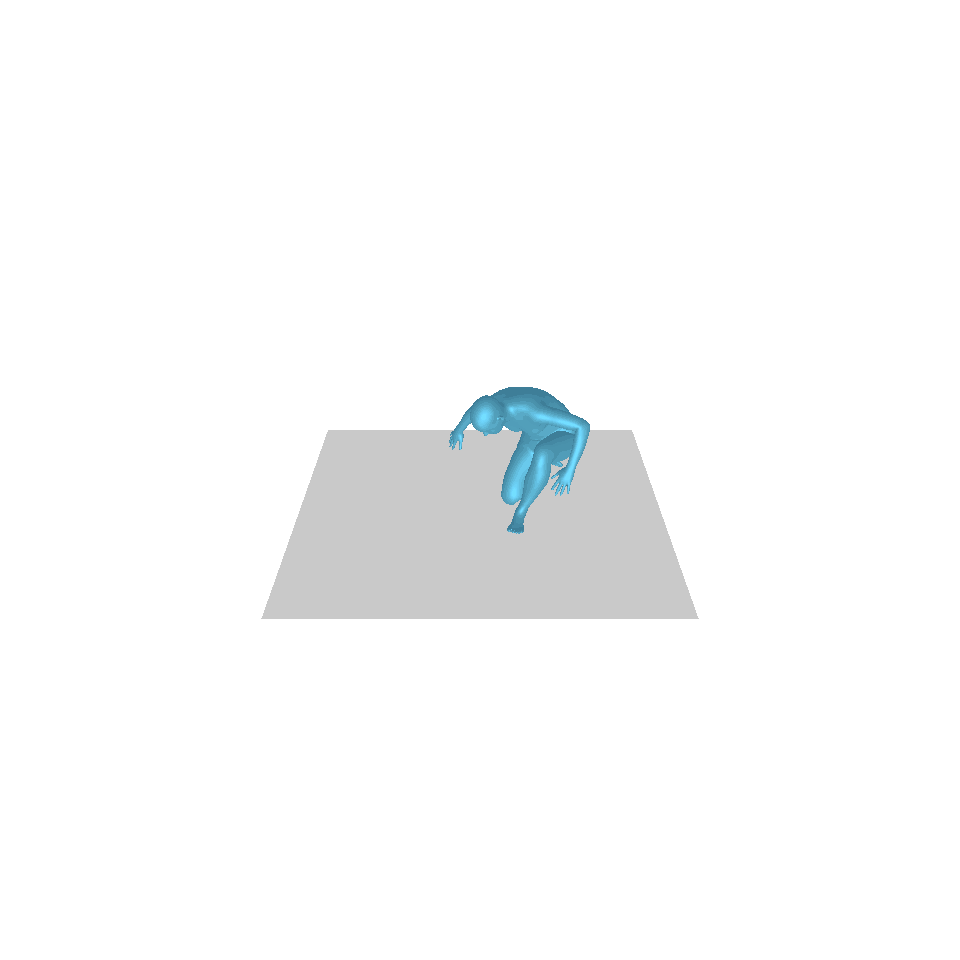 |  |  |
Unser Modell kann in einer einzelnen GPU V100-32G erlernt werden
conda env create -f environment.yml
conda activate T2M-GPTDer Code wurde auf Python 3.8 und PyTorch 1.8.1 getestet.
bash dataset/prepare/download_glove.shWir verwenden zwei 3D-Datensätze mit menschlicher Bewegungssprache: HumanML3D und KIT-ML. Für beide Datensätze finden Sie die Details sowie den Download-Link [hier].
Nehmen Sie HumanML3D als Beispiel. Das Dateiverzeichnis sollte folgendermaßen aussehen:
./dataset/HumanML3D/
├── new_joint_vecs/
├── texts/
├── Mean.npy # same as in [HumanML3D](https://github.com/EricGuo5513/HumanML3D)
├── Std.npy # same as in [HumanML3D](https://github.com/EricGuo5513/HumanML3D)
├── train.txt
├── val.txt
├── test.txt
├── train_val.txt
└── all.txt
Wir verwenden dieselben Extraktoren, die von t2m bereitgestellt werden, um unsere generierten Bewegungen auszuwerten. Bitte laden Sie die Extraktoren herunter.
bash dataset/prepare/download_extractor.shDie vorab trainierten Modelldateien werden im Ordner „pretrained“ gespeichert:
bash dataset/prepare/download_model.shWenn Sie die generierte Bewegung rendern möchten, müssen Sie Folgendes installieren:
sudo sh dataset/prepare/download_smpl.sh
conda install -c menpo osmesa
conda install h5py
conda install -c conda-forge shapely pyrender trimesh mapbox_earcutEine Kurzanleitung zur Verwendung unseres Codes finden Sie in demo.ipynb
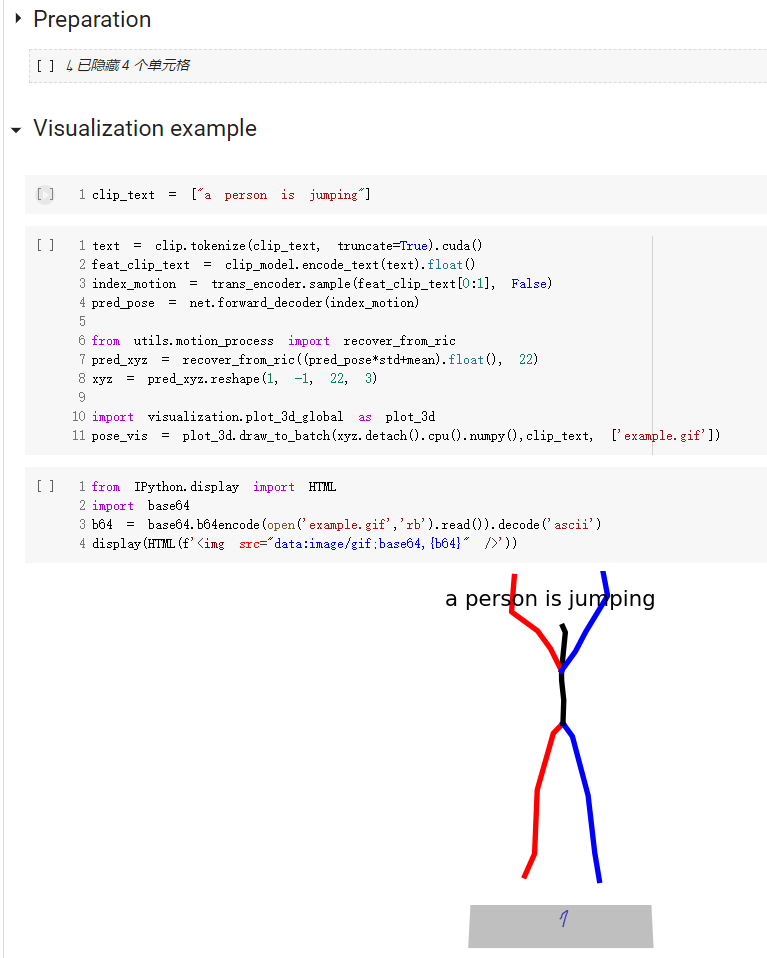
Beachten Sie, dass für den Kit-Datensatz lediglich „--dataname kit“ festgelegt werden muss.
Die Ergebnisse werden im Ordner Ausgabe gespeichert.
python3 train_vq.py
--batch-size 256
--lr 2e-4
--total-iter 300000
--lr-scheduler 200000
--nb-code 512
--down-t 2
--depth 3
--dilation-growth-rate 3
--out-dir output
--dataname t2m
--vq-act relu
--quantizer ema_reset
--loss-vel 0.5
--recons-loss l1_smooth
--exp-name VQVAEDie Ergebnisse werden im Ordner Ausgabe gespeichert.
python3 train_t2m_trans.py
--exp-name GPT
--batch-size 128
--num-layers 9
--embed-dim-gpt 1024
--nb-code 512
--n-head-gpt 16
--block-size 51
--ff-rate 4
--drop-out-rate 0.1
--resume-pth output/VQVAE/net_last.pth
--vq-name VQVAE
--out-dir output
--total-iter 300000
--lr-scheduler 150000
--lr 0.0001
--dataname t2m
--down-t 2
--depth 3
--quantizer ema_reset
--eval-iter 10000
--pkeep 0.5
--dilation-growth-rate 3
--vq-act relupython3 VQ_eval.py
--batch-size 256
--lr 2e-4
--total-iter 300000
--lr-scheduler 200000
--nb-code 512
--down-t 2
--depth 3
--dilation-growth-rate 3
--out-dir output
--dataname t2m
--vq-act relu
--quantizer ema_reset
--loss-vel 0.5
--recons-loss l1_smooth
--exp-name TEST_VQVAE
--resume-pth output/VQVAE/net_last.pthBefolgen Sie die Bewertungseinstellung von Text-to-Motion, wir bewerten unser Modell 20 Mal und berichten über das durchschnittliche Ergebnis. Aufgrund des Multimodalitätsteils, bei dem wir 30 Anträge aus demselben Text generieren sollten, dauert die Auswertung lange.
python3 GPT_eval_multi.py
--exp-name TEST_GPT
--batch-size 128
--num-layers 9
--embed-dim-gpt 1024
--nb-code 512
--n-head-gpt 16
--block-size 51
--ff-rate 4
--drop-out-rate 0.1
--resume-pth output/VQVAE/net_last.pth
--vq-name VQVAE
--out-dir output
--total-iter 300000
--lr-scheduler 150000
--lr 0.0001
--dataname t2m
--down-t 2
--depth 3
--quantizer ema_reset
--eval-iter 10000
--pkeep 0.5
--dilation-growth-rate 3
--vq-act relu
--resume-trans output/GPT/net_best_fid.pthSie sollten die NPY-Ordneradresse und die Bewegungsnamen eingeben. Hier ist ein Beispiel:
python3 render_final.py --filedir output/TEST_GPT/ --motion-list 000019 005485Wir freuen uns über Hilfe von:


