EcoAssistant
1.0.0
EcoAssistant: LLM-Assistent kostengünstiger und präziser nutzen
Schauen Sie sich unseren Blog auf der AutoGen-Website an!
Eine vereinfachte Version mit dem neuesten AutoGen finden Sie in simplified_demo.py
EcoAssistant ist ein Framework, das den LLM-Assistenten kostengünstiger und genauer für die codegesteuerte Beantwortung von Fragen machen kann. Es basiert auf der Idee der Assistentenhierarchie und Lösungsdemonstration . Es basiert auf AutoGen.
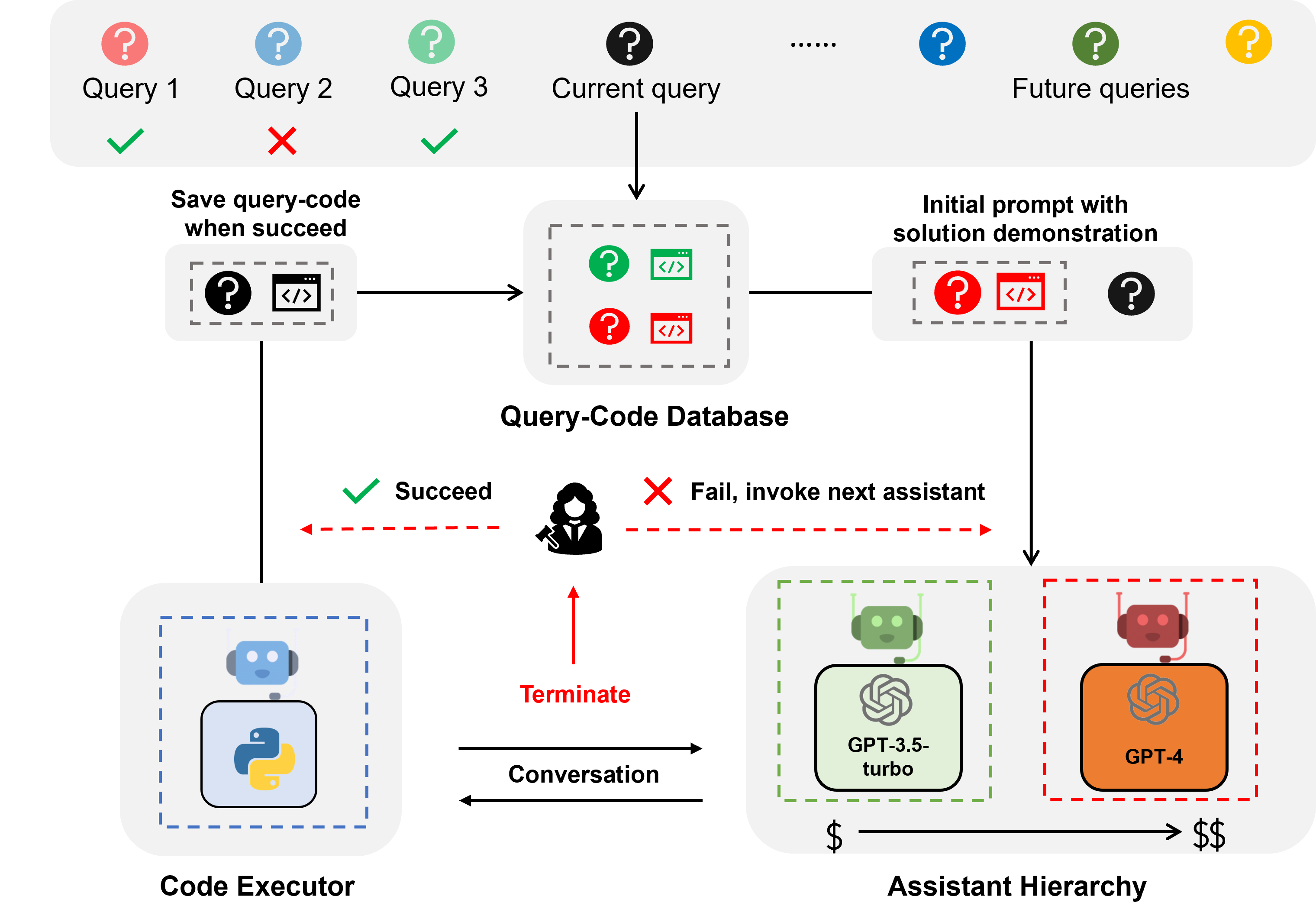
Der LLM-Assistent ist ein Assistenzagent, der durch Konversations-LLM wie ChatGPT und GPT-4 unterstützt wird und in der Lage ist, Benutzeranfragen in einer Konversation zu beantworten.
Die codegesteuerte Beantwortung von Fragen ist eine Aufgabe, bei der der LLM-Assistent Code schreiben muss, um externe APIs aufzurufen, um die Frage zu beantworten. Bei der Frage „Wie hoch ist die durchschnittliche Temperatur der Stadt X in den nächsten 5 Tagen?“ muss der Assistent beispielsweise Code schreiben, um die Wetterinformationen über bestimmte APIS abzurufen und die durchschnittliche Temperatur der Stadt 5 Tage.
Die codegesteuerte Beantwortung von Fragen erfordert iteratives Codieren, da LLM, genau wie der Mensch, beim ersten Versuch kaum den richtigen Code schreiben kann. Daher muss der Assistent mit dem Benutzer interagieren, um Feedback zu erhalten und den Code iterativ zu überarbeiten, bis der Code korrekt ist. Wir haben unser System auf einem Konversationsframework mit zwei Agenten aufgebaut, bei dem der LLM-Assistent mit einem Code-Executor-Agenten gekoppelt ist, der den Code automatisch ausführen und die Ausgabe an den LLM-Assistenten zurückgeben kann.
Bei der Assistentenhierarchie handelt es sich um eine Hierarchie von Assistenten, bei der die LLM-Assistenten nach ihren Kosten geordnet sind (z. B. GPT-3.5-turbo -> GPT-4). Bei der Beantwortung einer Benutzeranfrage bittet der EcoAssistant zunächst den günstigsten Assistenten, die Anfrage zu beantworten. Erst wenn es fehlschlägt, greifen wir auf den teureren Assistenten zurück. Es soll Kosten sparen, indem der Einsatz teurer Assistenten reduziert wird.
Bei der Lösungsdemonstration handelt es sich um eine Technik, die das in der Vergangenheit erfolgreiche Abfrage-Code-Paar nutzt, um zukünftige Abfragen zu unterstützen. Jedes Mal, wenn eine Anfrage erfolgreich bearbeitet wird, speichern wir das Abfrage-Code-Paar in einer Datenbank. Wenn eine neue Abfrage eingeht, rufen wir die ähnlichste Abfrage aus der Datenbank ab und verwenden die Abfrage und den zugehörigen Code dann zur kontextbezogenen Demonstration. Es soll die Genauigkeit verbessern, indem es die in der Vergangenheit erfolgreichen Abfrage-Code-Paare nutzt.
Die Kombination aus Assistentenhierarchie und Lösungsdemonstration verstärkt die individuellen Vorteile, da die Lösung eines leistungsstarken Modells auf natürliche Weise genutzt wird, um ein schwächeres Modell ohne spezifische Designs anzuleiten.
Bei Abfragen zu Wetter, Lagerbestand und Orten übertrifft EcoAssistant die Erfolgsquote einzelner GPT-4-Assistenten um 10 Punkte und kostet weniger als 50 % der GPT-4-Kosten. Weitere Einzelheiten finden Sie in unserem Papier.
Alle Daten sind in diesem Repository enthalten.
Sie müssen nur Ihre API-Schlüssel in keys.json festlegen
Installieren Sie die erforderlichen Bibliotheken (wir empfehlen Python3.10):
pip3 install -r requirements.txtAls Beispiel verwenden wir den Mixed-100- Datensatz. Für andere Datensätze ändern Sie einfach den Datensatznamen in den folgenden Befehlen in google_places/stock/weather/mixed_1/mixed_2/mixed_3.
Die Ausgabeergebnisse finden Sie im results .
Die folgenden Befehle gelten für die in Abschnitt 4.5 beschriebenen autonomen Systeme ohne menschliches Feedback.
Führen Sie den GPT-3.5-Turbo-Assistenten aus
python3 run.py --data mixed_100 --seed 0 --api --model gpt-3.5-turbo Führen Sie den GPT-3.5-Turbo-Assistenten + Chain-of-Thought aus
cot einschalten
python3 run.py --data mixed_100 --seed 0 --api --cot --model gpt-3.5-turbo Führen Sie den GPT-3.5-Turbo-Assistenten + Lösungsdemonstration aus
Schalten Sie solution_demonstration ein
python3 run.py --data mixed_100 --seed 0 --api --solution_demonstration --model gpt-3.5-turbo Führen Sie die Assistentenhierarchie aus (GPT-3.5-turbo + GPT-4)
Stellen Sie model auf gpt-3.5-turbo,gpt-4 ein
python3 run.py --data mixed_100 --seed 0 --api --model gpt-3.5-turbo,gpt-4Führen Sie den EcoAssistant aus: Assistentenhierarchie (GPT-3.5-turbo + GPT-4) + Lösungsdemonstration
python3 run.py --data mixed_100 --seed 0 --api --solution_demonstration --model gpt-3.5-turbo,gpt-4Ermöglichen Sie menschliches Feedback
Für Systeme mit menschlichem Urteilsvermögen setzen Sie bitte eval auf human (standardmäßig llm “), wie im folgenden Beispielbefehl.
python3 run.py --data mixed_100 --seed 0 --api --solution_demonstration --model gpt-3.5-turbo,gpt-4 --eval humanFühren Sie den Goldcode für Mixed-100 aus, den wir wie in Abschnitt 4.4 beschrieben sammeln
Dieses Skript würde die Codeausgaben drucken.
python3 run_gold_code_for_mix_100.pyWenn Sie dieses Repository nützlich finden, denken Sie bitte darüber nach, Folgendes zu zitieren:
@article { zhang2023ecoassistant ,
title = { EcoAssistant: Using LLM Assistant More Affordably and Accurately } ,
author = { Zhang, Jieyu and Krishna, Ranjay and Awadallah, Ahmed H and Wang, Chi } ,
journal = { arXiv preprint arXiv:2310.03046 } ,
year = { 2023 }
}

