ContraCLM
1.0.0
Dieses Repository enthält Code für das ACL 2023-Papier, ContraCLM: Contrastive Learning for Causal Language Model.
Arbeit geleistet von: Nihal Jain*, Dejiao Zhang*, Wasi Uddin Ahmad*, Zijian Wang, Feng Nan, Xiaopeng Li, Ming Tan, Ramesh Nallapati, Baishakhi Ray, Parminder Bhatia, Xiaofei Ma, Bing Xiang. (* zeigt gleichen Beitrag an ).
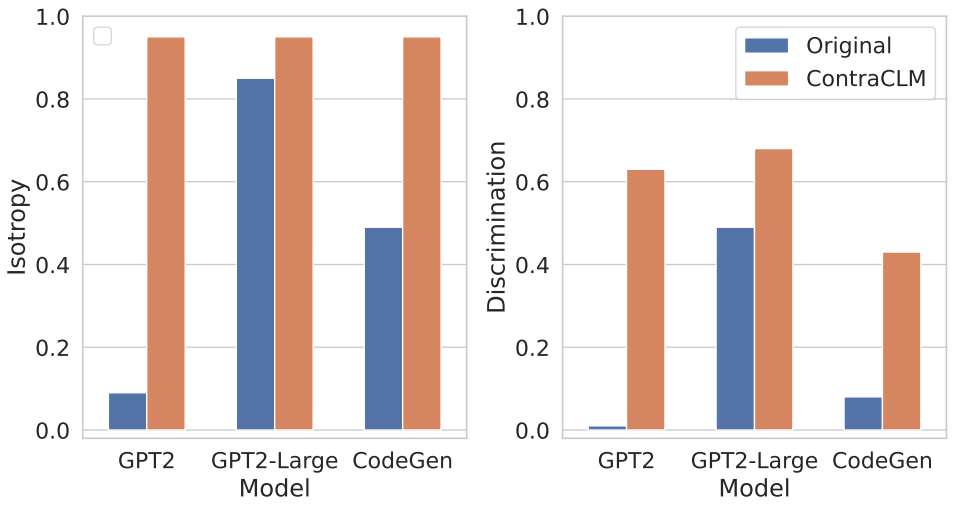
Wir präsentieren ContraCLM, ein neuartiges kontrastives Lernframework, das sowohl auf Token- als auch auf Sequenzebene funktioniert. ContraCLM verbessert die Unterscheidung von Darstellungen aus einem reinen Decoder-Sprachmodell und schließt die Lücke mit reinen Encoder-Modellen, wodurch kausale Sprachmodelle besser für Aufgaben geeignet sind, die über die Sprachgenerierung hinausgehen. Wir empfehlen Ihnen, sich für weitere Einzelheiten unser Papier anzusehen.
Das Setup umfasst die Installation der erforderlichen Abhängigkeiten in einer Umgebung und die Platzierung der Datensätze im erforderlichen Verzeichnis.
Führen Sie diese Befehle aus, um eine neue Conda-Umgebung zu erstellen und die erforderlichen Pakete für dieses Repository zu installieren.
# create a new conda environment with python >= 3.8
conda create -n contraclm python=3.8.12
# install dependencies within the environment
conda activate contraclm
pip install -r requirements.txtSiehe hier.
In diesem Abschnitt zeigen wir, wie Sie dieses Repository verwenden, um (i) GPT2 für Daten in natürlicher Sprache (NL) und (ii) CodeGen-350M-Mono für Daten in Programmiersprache (PL) vorab zu trainieren.
In diesem Abschnitt wird davon ausgegangen, dass Sie die Trainings- und Validierungsdaten unter TRAIN_DIR bzw. VALID_DIR gespeichert haben und sich in einer Umgebung befinden, in der alle oben genannten Abhängigkeiten installiert sind (siehe Setup).
Sie können einen Überblick über alle mit dem Vortraining verbundenen Flags erhalten, indem Sie Folgendes ausführen:
python pl_trainer.py --helpGPT2 auf NL-Daten beibehalten bash runscripts/run_wikitext.sh
CL_Config=$(eval echo ${options[1]}) im Skript festlegen.CodeGen-350M-Mono auf PL-Daten vor Konfigurieren Sie die Variablen oben in runscripts/run_code.sh . Es gibt viele Optionen, aber hier werden nur die Dropout-Optionen erklärt (andere sind selbsterklärend):
dropout_p : Der in torch.nn.Dropout verwendete Dropout-Wahrscheinlichkeitswert
dropout_layers : Wenn > 0, werden die letzten dropout_layers mit der Wahrscheinlichkeit dropout_p aktiviert
functional_dropout : Wenn angegeben, wird eine funktionale Dropout-Ebene über den vom CodeGen-Modell ausgegebenen Token-Darstellungen verwendet
Stellen Sie die Variable CL entsprechend der gewünschten Modellkonfiguration ein. Stellen Sie sicher, dass die Pfade zu TRAIN_DIR, VALID_DIR wie gewünscht festgelegt sind.
Führen Sie den Befehl aus: bash runscripts/run_code.sh
Die relevanten aufgabenspezifischen Verzeichnisse finden Sie hier.
Wenn Sie unseren Code in Ihrer Forschung verwenden, zitieren Sie unsere Arbeit bitte wie folgt:
@inproceedings{jain-etal-2023-contraclm,
title = "{C}ontra{CLM}: Contrastive Learning For Causal Language Model",
author = "Jain, Nihal and
Zhang, Dejiao and
Ahmad, Wasi Uddin and
Wang, Zijian and
Nan, Feng and
Li, Xiaopeng and
Tan, Ming and
Nallapati, Ramesh and
Ray, Baishakhi and
Bhatia, Parminder and
Ma, Xiaofei and
Xiang, Bing",
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.acl-long.355",
pages = "6436--6459"
}
Weitere Informationen finden Sie unter BEITRAGEN.
Dieses Projekt ist unter der Apache-2.0-Lizenz lizenziert.


