alles-ai
Ihr kompetenter, KI-gestützter und lokaler Chatbot-Assistent?
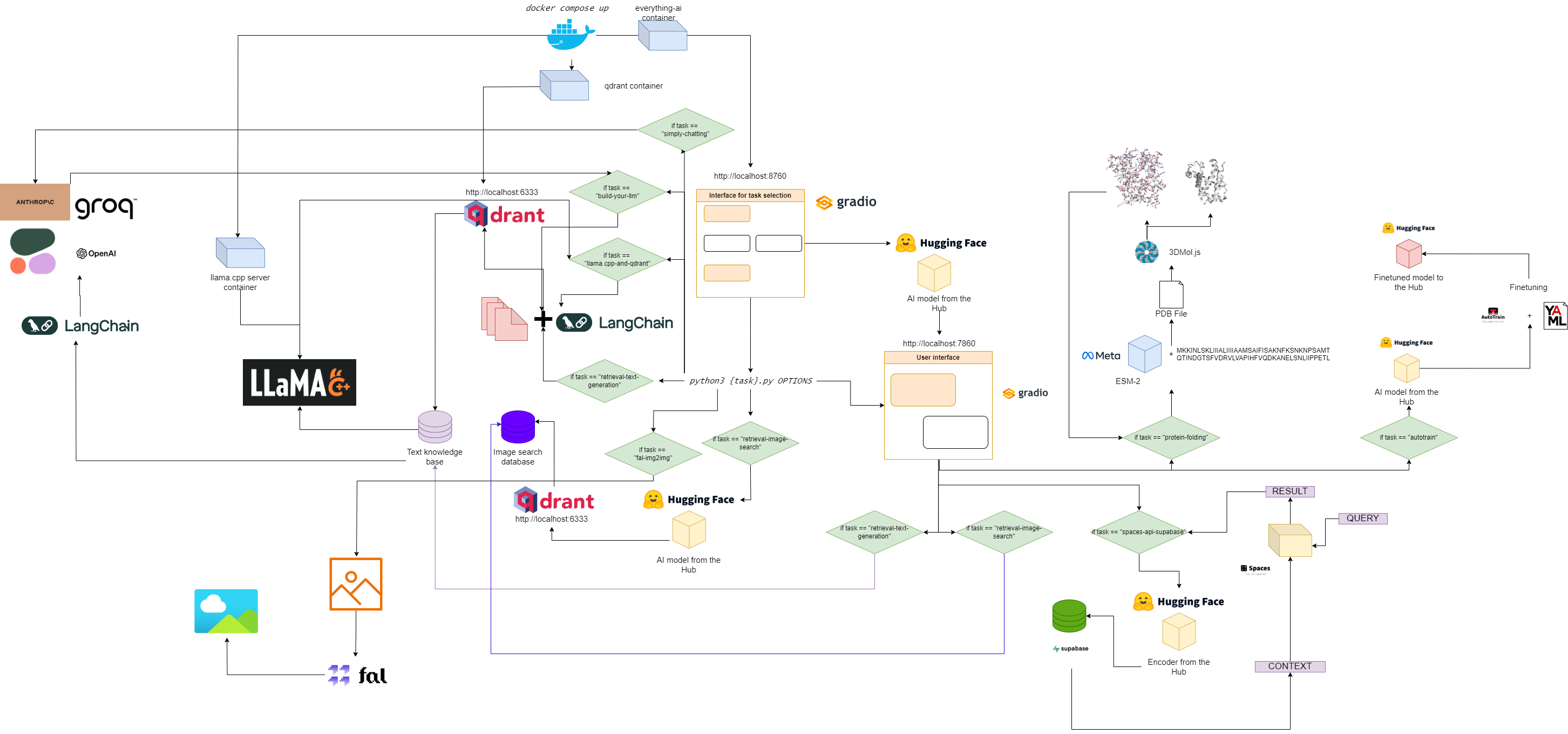
Flussdiagramm für alles – KI
Schnellstart
1. Klonen Sie dieses Repository
git clone https://github.com/AstraBert/everything-ai.git
cd everything-ai
2. Legen Sie Ihre .env Datei fest
Ändern:
-
VOLUME Variable in der .env-Datei, damit Sie Ihr lokales Dateisystem in den Docker-Container einbinden können. - Fügen Sie die Variable
MODELS_PATH in der .env-Datei hinzu, damit Sie llama.cpp mitteilen können, wo Sie die heruntergeladenen GGUF-Modelle gespeichert haben. -
MODEL Variable in der .env-Datei, damit Sie llama.cpp mitteilen können, welches Modell verwendet werden soll (verwenden Sie den tatsächlichen Namen der gguf-Datei und vergessen Sie nicht die Erweiterung .gguf!) - Fügen Sie die Variable
MAX_TOKENS in der .env-Datei hinzu, damit Sie llama.cpp mitteilen können, wie viele neue Token es als Ausgabe generieren kann.
Ein Beispiel für eine .env Datei könnte sein:
VOLUME= " c:/Users/User/:/User/ "
MODELS_PATH= " c:/Users/User/.cache/llama.cpp/ "
MODEL= " stories260K.gguf "
MAX_TOKENS= " 512 "
Das bedeutet, dass jetzt alles, was sich unter „c:/Users/User/“ auf Ihrem lokalen Computer befindet, unter „/User/“ in Ihrem Docker-Container ist, dass llama.cpp weiß, wo und nach welchem Modell nach Modellen gesucht werden muss. zusammen mit der maximalen Anzahl neuer Token für die Ausgabe.
3. Ziehen Sie die erforderlichen Bilder herunter
docker pull astrabert/everything-ai:latest
docker pull qdrant/qdrant:latest
docker pull ghcr.io/ggerganov/llama.cpp:server
4. Führen Sie die Multi-Container-App aus
5. Gehen Sie zu localhost:8670 und wählen Sie Ihren Assistenten aus
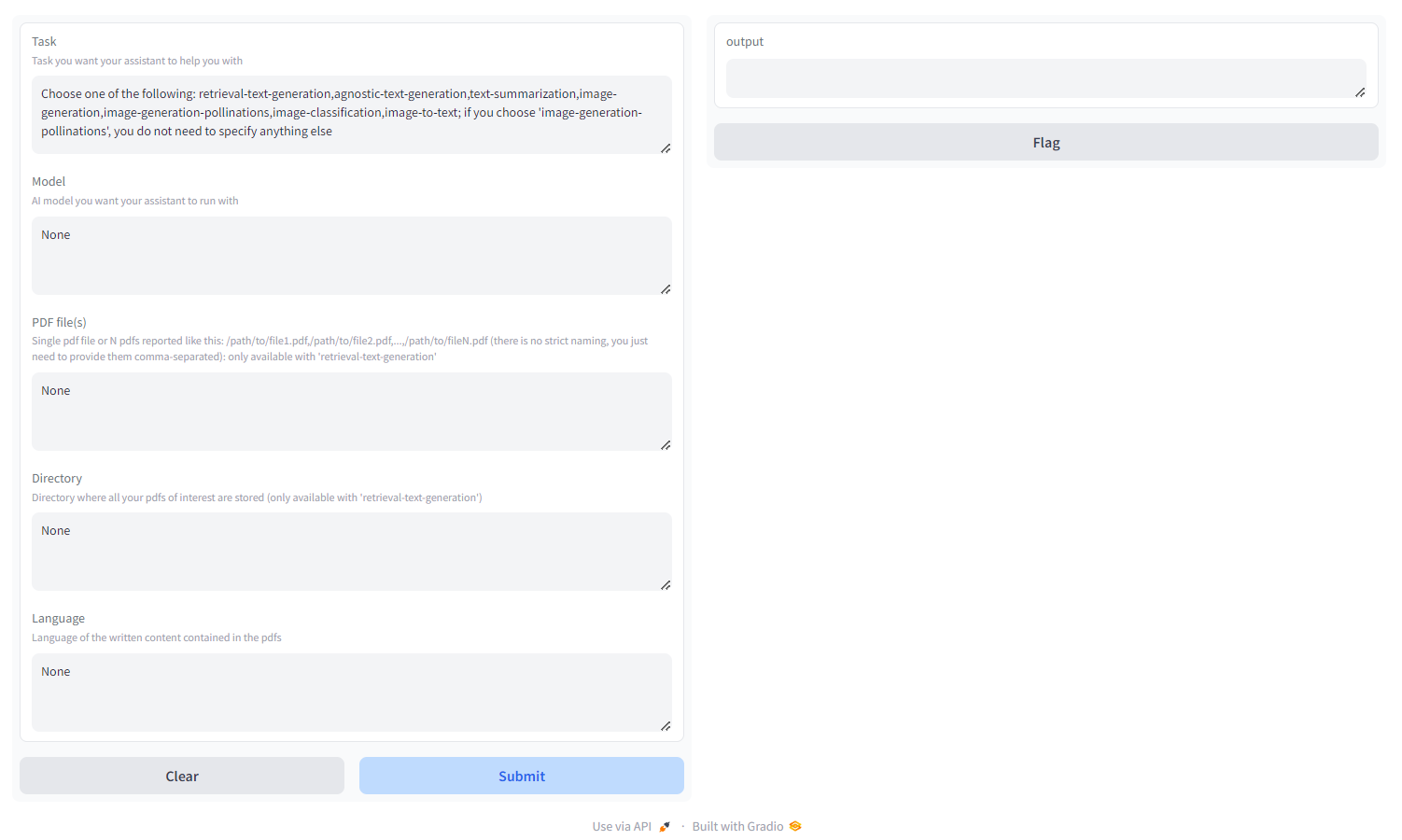
Sie werden etwa Folgendes sehen:
Wählen Sie die Aufgabe aus:
- Retrieval-Text-Generierung : Verwenden Sie
qdrant Backend, um eine abruffreundliche Wissensdatenbank aufzubauen, die Sie abfragen und die Reaktion Ihres Modells optimieren können. Sie müssen entweder ein PDF/eine Reihe von PDFs übergeben, die als durch Kommas getrennte Pfade angegeben sind, oder ein Verzeichnis, in dem alle interessierenden PDFs gespeichert sind (geben Sie NICHT beides an). Sie können auch die Sprache angeben, in der das PDF geschrieben ist, indem Sie die ISO-Nomenklatur verwenden – MEHRSPRACHIG - agnostische Textgenerierung : ChatGPT-ähnliche Textgenerierung (keine Abrufarchitektur), unterstützt jedoch jedes Textgenerierungsmodell auf HF Hub (sofern Ihre Hardware dies unterstützt!) – MEHRSPRACHIG
- Textzusammenfassung : Text und PDFs zusammenfassen, unterstützt jedes Textzusammenfassungsmodell auf HF Hub – NUR ENGLISCH
- Bildgenerierung : stabile Diffusion, unterstützt jedes Text-zu-Bild-Modell auf HF Hub – MEHRSPRACHIG
- Bildgenerierung-Bestäubungen : stabile Diffusion, Bestäubungs-AI-API verwenden; Wenn Sie „Bildgenerierung-Bestäubungen“ wählen, müssen Sie außer der Aufgabe – MEHRSPRACHIG – nichts anderes angeben
- Bildklassifizierung : Ein Bild klassifizieren, unterstützt jedes Bildklassifizierungsmodell auf HF Hub – NUR ENGLISCH
- Bild-zu-Text : Beschreibt ein Bild, unterstützt jedes Bild-zu-Text-Modell auf HF Hub – NUR ENGLISCH
- Audioklassifizierung : Klassifizierung von Audiodateien oder Mikrofonaufnahmen, unterstützt Audioklassifizierungsmodelle auf dem HF-Hub
- Spracherkennung : Transkribiert Audiodateien oder Mikrofonaufnahmen, unterstützt automatische Spracherkennungsmodelle auf dem HF-Hub.
- Videogenerierung : Video nach Textaufforderung generieren, unterstützt Text-zu-Video-Modelle auf dem HF-Hub – NUR ENGLISCH
- Proteinfaltung : Ermitteln Sie die 3D-Struktur eines Proteins aus seiner Aminosäuresequenz mithilfe des ESM-2-Rückgratmodells – NUR GPU
- Autotrain : Optimieren Sie ein Modell für eine bestimmte Downstream-Aufgabe mit Autotrain-Advanced, indem Sie einfach Ihren HF-Benutzernamen, Ihr HF-Schreibtoken und den Pfad zu einer Yaml-Konfigurationsdatei für das Training angeben
- space-api-supabase : Verwenden Sie die HF Spaces API in Kombination mit Supabase PostgreSQL-Datenbanken, um leistungsfähigere LLMs und größere RAG-orientierte Vektordatenbanken freizusetzen – MEHRSPRACHIG
- llama.cpp-and-qdrant : dasselbe wie retrieval-text-generation , verwendet aber llama.cpp als Inferenz-Engine, daher DÜRFEN Sie KEIN Modell angeben – MULTILINGUAL
- build-your-llm : Erstellen Sie ein anpassbares Chat-LLM, das eine Qdrant-Datenbank mit Ihren PDFs und der Leistungsfähigkeit von Anthropic-, OpenAI-, Cohere- oder Groq-Modellen kombiniert: Sie benötigen lediglich einen API-Schlüssel! Um die Qdrant-Datenbank zu erstellen, müssen Sie entweder ein PDF/eine Reihe von PDFs übergeben, die als durch Kommas getrennte Pfade angegeben sind, oder ein Verzeichnis, in dem alle interessierenden PDFs gespeichert sind ( stellen Sie NICHT beides bereit). Sie können auch die Sprache angeben, in der das PDF geschrieben ist, indem Sie die ISO-Nomenklatur verwenden – MULTILINGUAL , LANGFUSE INTEGRATION
- simply-chatting : Erstellen Sie ein anpassbares Chat-LLM mit der Leistung von Anthropic-, OpenAI-, Cohere- oder Groq-Modellen (keine RAG-Pipeline): Sie benötigen lediglich einen API-Schlüssel! - MEHRSPRACHIGE , LANGFUSE-INTEGRATION
- fal-img2img : Verwenden Sie die fal.ai ComfyUI-API, um Bilder ausgehend von Ihren PNG- und JPEG-Bildern zu generieren: Sie benötigen lediglich einen API-Schlüssel! Sie können auch die Generierung mithilfe von Eingabeaufforderungen und Seeds anpassen – NUR AUF ENGLISCH
- image-retrieval-search : Durchsuchen Sie eine Bilddatenbank und laden Sie einen Ordner als Datenbankeingabe hoch. Der Ordner sollte folgende Struktur haben:
./
├── test/
| ├── label1/
| └── label2/
└── train/
├── label1/
└── label2/
Sie können die Datenbank ausgehend von Ihren eigenen Bildern abfragen.
6. Gehen Sie zu localhost:7860 und beginnen Sie mit der Verwendung Ihres Assistenten
Sobald alles fertig ist, können Sie zu localhost:7860 gehen und Ihren Assistenten verwenden: