serverless rag ynetnews bedrock demo
1.0.0
Die Beantwortung von Fragen (QA) ist eine wichtige Aufgabe, bei der es darum geht, Antworten auf sachliche Fragen zu extrahieren, die in natürlicher Sprache gestellt werden. Typischerweise verarbeitet ein QA-System eine Anfrage anhand einer Wissensdatenbank, die strukturierte oder unstrukturierte Daten enthält, und generiert eine Antwort mit genauen Informationen. Die Gewährleistung einer hohen Genauigkeit ist der Schlüssel zur Entwicklung eines nützlichen, zuverlässigen und vertrauenswürdigen Frage-Antwort-Systems, insbesondere für Anwendungsfälle in Unternehmen.
Generative KI-Modelle wie Amazon Titan, Anthropic Claude und AI21 Jurassic 2 nutzen Wahrscheinlichkeitsverteilungen, um Antworten auf Fragen zu generieren. Diese Modelle werden auf riesigen Mengen an Textdaten trainiert, wodurch sie vorhersagen können, was als nächstes in einer Sequenz kommt oder welches Wort auf ein bestimmtes Wort folgen könnte. Allerdings sind diese Modelle nicht in der Lage, genaue oder deterministische Antworten auf jede Frage zu liefern, da die Daten immer ein gewisses Maß an Unsicherheit aufweisen.
Unternehmen müssen domänenspezifische und proprietäre Daten abfragen und die Informationen zur Beantwortung von Fragen und allgemeiner von Daten verwenden, für die das Modell nicht trainiert wurde.
In diesem Repo werden wir das folgende QS-Muster untersuchen:
Wir verwenden Retrieval Augmented Generation, eine Verbesserung gegenüber der ersten, bei der wir unsere Fragen mit möglichst viel relevantem Kontext verknüpfen, der wahrscheinlich die Antworten oder Informationen enthält, nach denen wir suchen. Die Herausforderung hierbei: Es gibt eine Grenze dafür, wie viele Kontextinformationen verwendet werden können, die durch die Token-Grenze des Modells bestimmt wird. 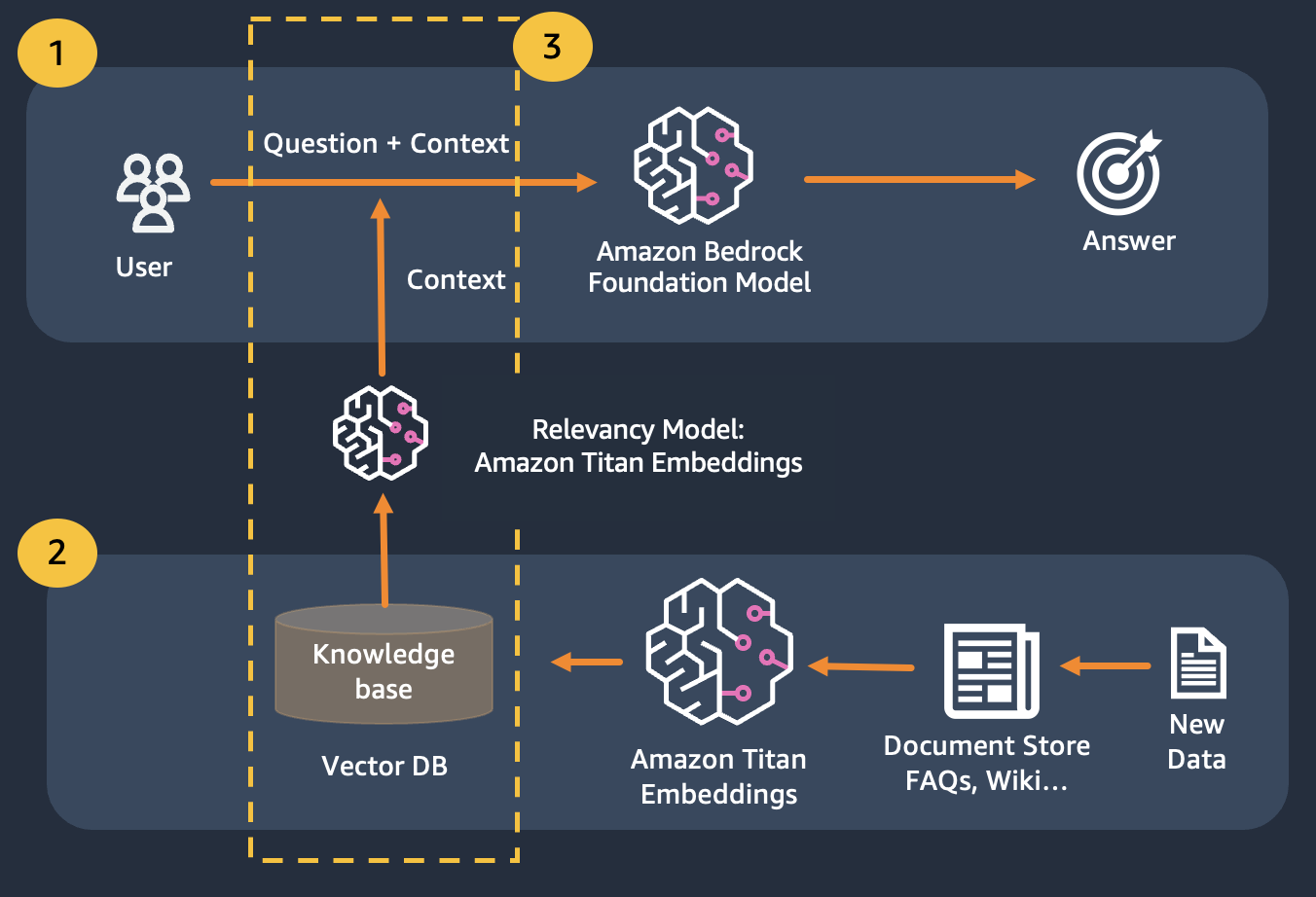
Dies kann durch den Einsatz von Retrival Augmented Generation (RAG) überwunden werden.
RAG kombiniert die Verwendung von Einbettungen zur Indexierung des Dokumentenkorpus zum Aufbau einer Wissensdatenbank und die Verwendung eines LLM zum Extrahieren der Informationen aus einer Teilmenge der Dokumente in der Wissensdatenbank.
Als Vorbereitungsschritt für RAG werden die Dokumente, die die Wissensdatenbank aufbauen, in Blöcke fester Größe (entsprechend der maximalen Eingabegröße des ausgewählten Einbettungsmodells) aufgeteilt und dann an das Modell übergeben, um den Einbettungsvektor zu erhalten. Die Einbettung wird zusammen mit dem Originalteil des Dokuments und zusätzlichen Metadaten in einer Vektordatenbank gespeichert. Die Vektordatenbank ist für die effiziente Durchführung einer Ähnlichkeitssuche zwischen Vektoren optimiert.
Kunden mit Datenspeichern, die möglicherweise privat sind oder sich häufig ändern. Der RAG-Ansatz löst zwei Probleme. Kunden mit den folgenden Herausforderungen können von diesem Labor profitieren.
Nach diesem Modul sollten Sie über folgende Kenntnisse verfügen:
In diesem Modul führen wir Sie durch die Implementierung des QA-Musters mit Bedrock. Zusätzlich haben wir die Einbettungen zum Laden in die Vektordatenbank für Sie vorbereitet.
Beachten Sie, dass Sie Titan Embeddings verwenden können, um die Einbettungen der Benutzerfrage zu erhalten, diese Einbettungen dann verwenden können, um die relevantesten Dokumente aus der Vektordatenbank abzurufen, eine Eingabeaufforderung zu erstellen, die die drei wichtigsten Dokumente verkettet, und das LLM-Modell über Bedrock aufzurufen.


