LLM Alignment Project
1.0.0
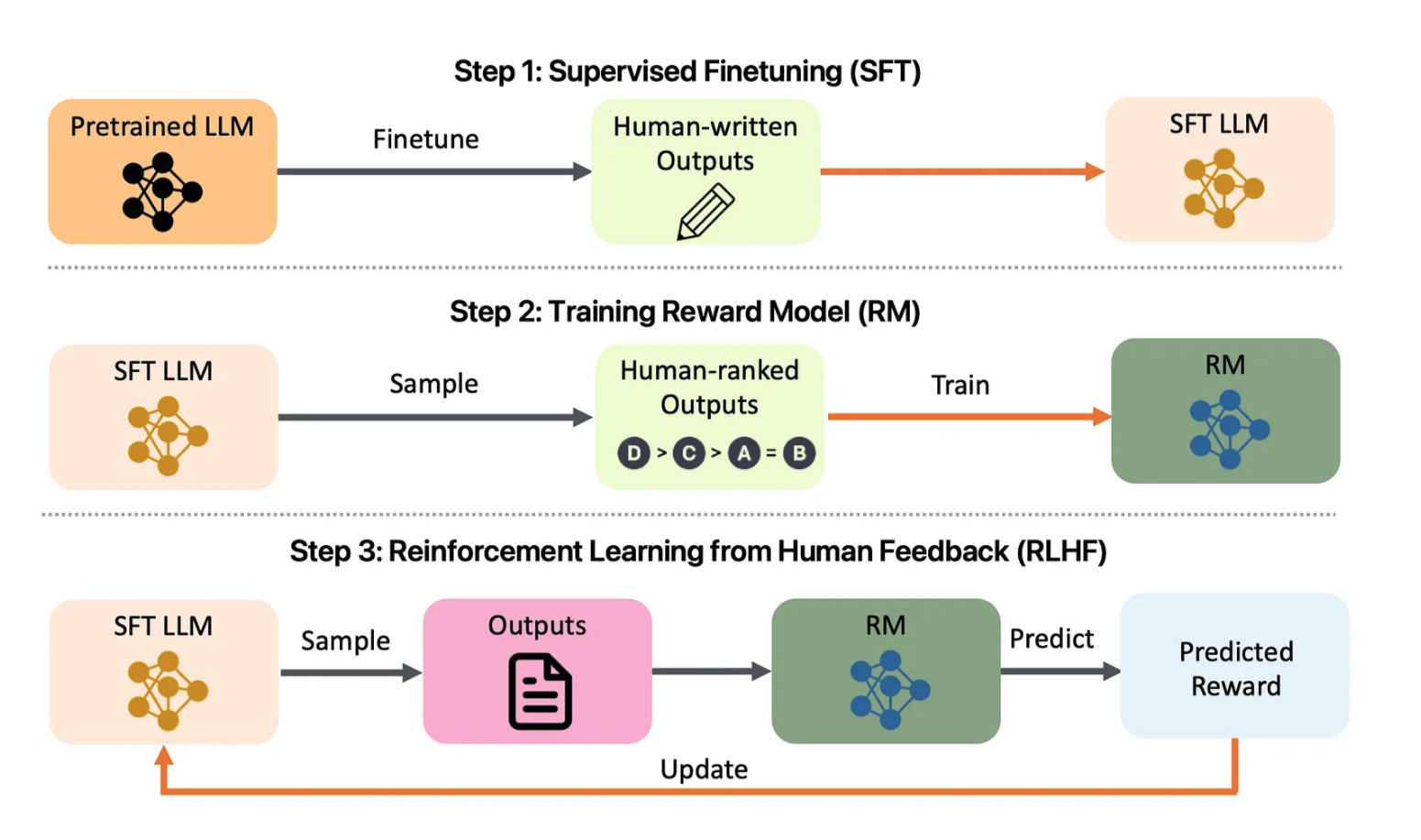
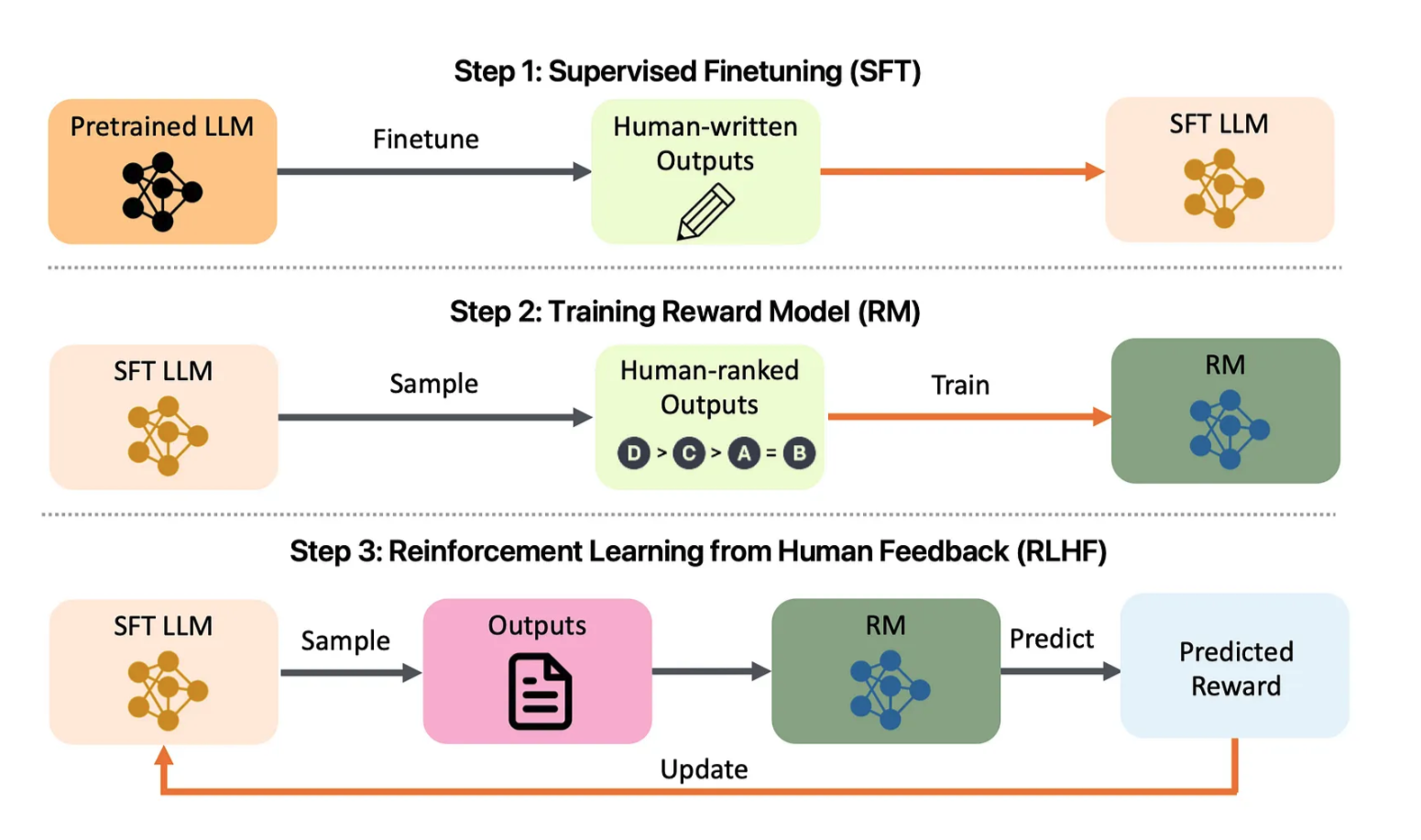
Abbildung 1: Übersicht über das LLM-Alignment-Projekt. Schauen Sie sich Folgendes an: arXiv:2308.05374
Die LLM-Ausrichtungsvorlage ist nicht nur ein umfassendes Tool zum Ausrichten großer Sprachmodelle (LLMs), sondern dient auch als leistungsstarke Vorlage zum Erstellen Ihrer eigenen LLM-Ausrichtungsanwendung. Inspiriert von Projektvorlagen wie der PyTorch-Projektvorlage ist dieses Repository so konzipiert, dass es einen vollständigen Funktionsumfang bietet und als Ausgangspunkt für die Anpassung und Erweiterung an Ihre eigenen LLM-Ausrichtungsanforderungen dient. Unabhängig davon, ob Sie Forscher, Entwickler oder Datenwissenschaftler sind, bietet diese Vorlage eine solide Grundlage für die effiziente Erstellung und Bereitstellung von LLMs, die auf menschliche Werte und Ziele zugeschnitten sind.
Die LLM-Ausrichtungsvorlage bietet einen vollständigen Funktionsumfang, einschließlich Schulung, Feinabstimmung, Bereitstellung und Überwachung von LLMs mithilfe von Reinforcement Learning from Human Feedback (RLHF). Dieses Projekt integriert auch Bewertungsmetriken, um einen ethischen und effektiven Einsatz von Sprachmodellen sicherzustellen. Die Schnittstelle bietet eine benutzerfreundliche Erfahrung für die Verwaltung der Ausrichtung, die Visualisierung von Trainingsmetriken und die Bereitstellung in großem Maßstab.
app/ : Enthält API- und UI-Code.
auth.py , feedback.py , ui.py : API-Endpunkte für Benutzerinteraktion, Feedback-Sammlung und allgemeine Schnittstellenverwaltung.app.js , chart.js ), CSS ( styles.css ) und Swagger-API-Dokumentation ( swagger.json ).chat.html , feedback.html , index.html ) für das UI-Rendering. src/ : Kernlogik und Dienstprogramme für Vorverarbeitung und Training.
preprocessing/ ):preprocess_data.py : Kombiniert Original- und erweiterte Datensätze und wendet Textbereinigung an.tokenization.py : Verwaltet die Tokenisierung.training/ ):fine_tuning.py , transfer_learning.py , retrain_model.py : Skripte zum Trainieren und Umschulen von Modellen.rlhf.py , reward_model.py : Skripte für das Belohnungsmodelltraining mit RLHF.utils/ ): Allgemeine Dienstprogramme ( config.py , logging.py , validation.py ). dashboards/ : Leistungs- und Erklärbarkeits-Dashboards für Überwachung und Modelleinblicke.
performance_dashboard.py : Zeigt Trainingsmetriken, Validierungsverlust und Genauigkeit an.explainability_dashboard.py : Visualisiert SHAP-Werte, um Einblick in Modellentscheidungen zu geben. tests/ : Unit-, Integrations- und End-to-End-Tests.
test_api.py , test_preprocessing.py , test_training.py : Verschiedene Unit- und Integrationstests.e2e/ ): Cypress-basierte UI-Tests ( ui_tests.spec.js ).load_testing/ ): Verwendet Locust ( locustfile.py ) für Auslastungstests. deployment/ : Konfigurationsdateien für die Bereitstellung und Überwachung.
kubernetes/ ): Bereitstellungs- und Ingress-Konfigurationen für Skalierung und Canary-Releases.monitoring/ ): Prometheus ( prometheus.yml ) und Grafana ( grafana_dashboard.json ) zur Überwachung der Leistung und des Systemzustands. Klonen Sie das Repository :
git clone https://github.com/yourusername/LLM-Alignment-Template.git
cd LLM-Alignment-TemplateAbhängigkeiten installieren :
pip install -r requirements.txt cd app/static
npm installErstellen Sie Docker-Images :
docker-compose up --buildGreifen Sie auf die Anwendung zu :
http://localhost:5000 . kubectl apply -f deployment/kubernetes/deployment.yml
kubectl apply -f deployment/kubernetes/service.ymlkubectl apply -f deployment/kubernetes/hpa.ymldeployment/kubernetes/canary_deployment.yml konfiguriert, um neue Versionen sicher bereitzustellen.deployment/monitoring/ an, um Überwachungs-Dashboards zu aktivieren.docker-compose.logging.yml für zentralisierte Protokolle konfiguriert. Das Trainingsmodul ( src/training/transfer_learning.py ) nutzt vorab trainierte Modelle wie BERT , um sich an benutzerdefinierte Aufgaben anzupassen und so eine deutliche Leistungssteigerung zu erzielen.
Das data_augmentation.py -Skript ( src/data/ ) wendet Erweiterungstechniken wie Rückübersetzung und Paraphrasierung an, um die Datenqualität zu verbessern.
rlhf.py und reward_model.py um Modelle basierend auf menschlichem Feedback zu verfeinern.feedback.html ), und das Modell führt ein erneutes Training mit retrain_model.py durch. Das Skript explainability_dashboard.py verwendet SHAP -Werte, um Benutzern zu helfen, zu verstehen, warum ein Modell bestimmte Vorhersagen getroffen hat.
tests/ und deckt API-, Vorverarbeitungs- und Trainingsfunktionen ab.tests/load_testing/locustfile.py ), um Stabilität unter Last sicherzustellen. Beiträge sind willkommen! Bitte reichen Sie Pull-Anfragen oder Probleme für Verbesserungen oder neue Funktionen ein.
Dieses Projekt ist unter der MIT-Lizenz lizenziert. Weitere Informationen finden Sie in der LICENSE-Datei.
Entwickelt mit ❤️ von Amirsina Torfi