GenerativeRL
v0.0.1
Englisch | 简体中文 (vereinfachtes Chinesisch)
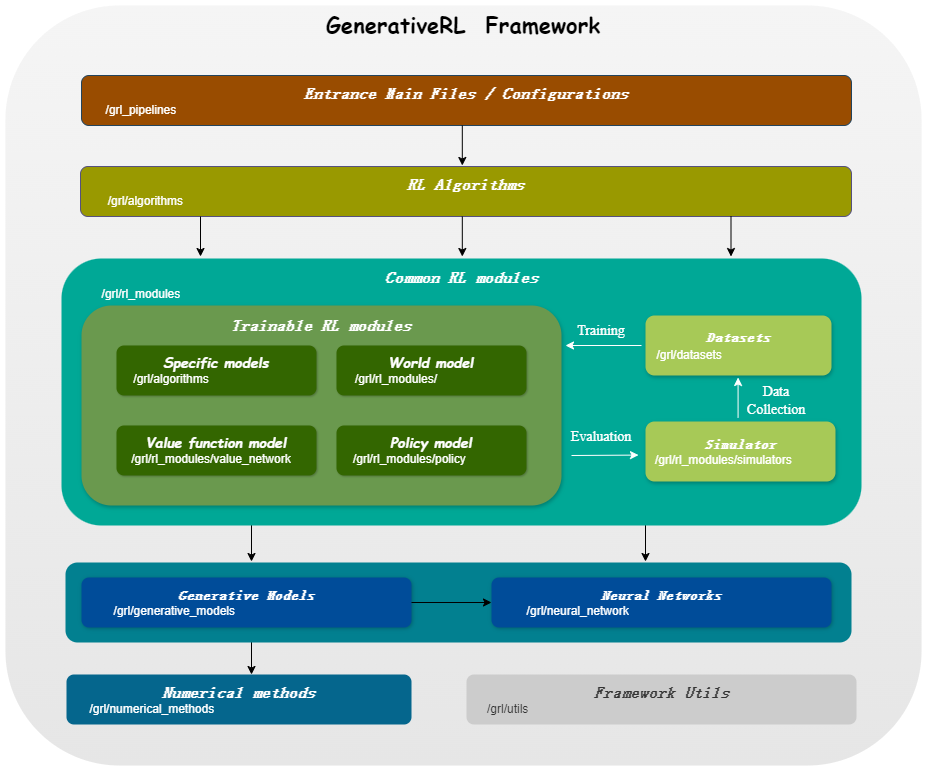
GenerativeRL , kurz für Generative Reinforcement Learning, ist eine Python-Bibliothek zur Lösung von Reinforcement Learning (RL)-Problemen mithilfe generativer Modelle, wie z. B. Diffusionsmodellen und Strömungsmodellen. Ziel dieser Bibliothek ist es, einen Rahmen für die Kombination der Leistungsfähigkeit generativer Modelle mit den Entscheidungsfähigkeiten von Reinforcement-Learning-Algorithmen bereitzustellen.
| Score-Matching | Flow-Matching | |
|---|---|---|
| Diffusionsmodell | ||
| Lineares VP SDE | ✔ | ✔ |
| Generalisierte VP SDE | ✔ | ✔ |
| Lineare SDE | ✔ | ✔ |
| Strömungsmodell | ||
| Unabhängiger bedingter Flussabgleich | ✔ | |
| Optimale transportbedingte Flussanpassung | ✔ |
| Algorithmen/Modelle | Diffusionsmodell | Strömungsmodell |
|---|---|---|
| IDQL | ✔ | |
| QGPO | ✔ | |
| SRPO | ✔ | |
| GMPO | ✔ | ✔ |
| GMPG | ✔ | ✔ |
pip install GenerativeRLOder, wenn Sie von der Quelle installieren möchten:
git clone https://github.com/opendilab/GenerativeRL.git
cd GenerativeRL
pip install -e .Oder Sie können das Docker-Image verwenden:
docker pull opendilab/grl:torch2.3.0-cuda12.1-cudnn8-runtime
docker run -it --rm --gpus all opendilab/grl:torch2.3.0-cuda12.1-cudnn8-runtime /bin/bashHier ist ein Beispiel dafür, wie man mit GenerativeRL ein Diffusionsmodell für Q-guided Policy Optimization (QGPO) in der LunarLanderContinuous-v2-Umgebung trainiert.
Installieren Sie die erforderlichen Abhängigkeiten:
pip install ' gym[box2d]==0.23.1 '(Die Gym-Version kann für Box2D-Umgebungen zwischen 0,23 und 0,25 liegen, aus Kompatibilitätsgründen mit D4RL wird jedoch die Verwendung von 0,23.1 empfohlen.)
Laden Sie den Datensatz hier herunter und speichern Sie ihn als data.npz im aktuellen Verzeichnis.
GenerativeRL verwendet WandB für die Protokollierung. Wenn Sie es verwenden, werden Sie aufgefordert, sich bei Ihrem Konto anzumelden. Sie können es deaktivieren, indem Sie Folgendes ausführen:
wandb offline import gym
from grl . algorithms . qgpo import QGPOAlgorithm
from grl . datasets import QGPOCustomizedTensorDictDataset
from grl . utils . log import log
from grl_pipelines . diffusion_model . configurations . lunarlander_continuous_qgpo import config
def qgpo_pipeline ( config ):
qgpo = QGPOAlgorithm ( config , dataset = QGPOCustomizedTensorDictDataset ( numpy_data_path = "./data.npz" , action_augment_num = config . train . parameter . action_augment_num ))
qgpo . train ()
agent = qgpo . deploy ()
env = gym . make ( config . deploy . env . env_id )
observation = env . reset ()
for _ in range ( config . deploy . num_deploy_steps ):
env . render ()
observation , reward , done , _ = env . step ( agent . act ( observation ))
if __name__ == '__main__' :
log . info ( "config: n {}" . format ( config ))
qgpo_pipeline ( config )Ausführlichere Beispiele und Dokumentation finden Sie in der GenerativeRL-Dokumentation.
Die vollständige Dokumentation für GenerativeRL finden Sie unter GenerativeRL Documentation.
Wir bieten mehrere Fall-Tutorials an, die Ihnen helfen, GenerativeRL besser zu verstehen. Weitere Informationen finden Sie unter Tutorials.
Wir bieten einige Basisexperimente an, um die Leistung generativer Reinforcement-Learning-Algorithmen zu bewerten. Weitere Informationen finden Sie unter Benchmark.
Wir freuen uns über Beiträge zu GenerativeRL! Wenn Sie daran interessiert sind, einen Beitrag zu leisten, lesen Sie bitte den Beitragsleitfaden.
@misc{generative_rl,
title={GenerativeRL: A Python Library for Solving Reinforcement Learning Problems Using Generative Models},
author={Zhang, Jinouwen and Xue, Rongkun and Niu, Yazhe and Chen, Yun and Chen, Xinyan and Wang, Ruiheng and Liu, Yu},
publisher={GitHub},
howpublished={ url {https://github.com/opendilab/GenerativeRL}},
year={2024},
}GenerativeRL ist unter der Apache-Lizenz 2.0 lizenziert. Weitere Einzelheiten finden Sie unter LIZENZ.


