?️Bild-zu-Sprache-GenAI-Tool mit LLM ?♨️
KI-Tool, das eine Audio-Kurzgeschichte basierend auf dem Kontext eines hochgeladenen Bildes generiert, indem es ein GenAI-LLM-Modell, Hugging-Face-KI-Modelle zusammen mit OpenAI und LangChain anregt. Wird separat auf Streamlit und Hugging Space Cloud bereitgestellt.
?App mit Streamlit Cloud ausführen
Starten Sie die App auf Streamlit
?App mit HuggingFace Space Cloud ausführen
Starten Sie die App im HuggingFace Space
Demo:
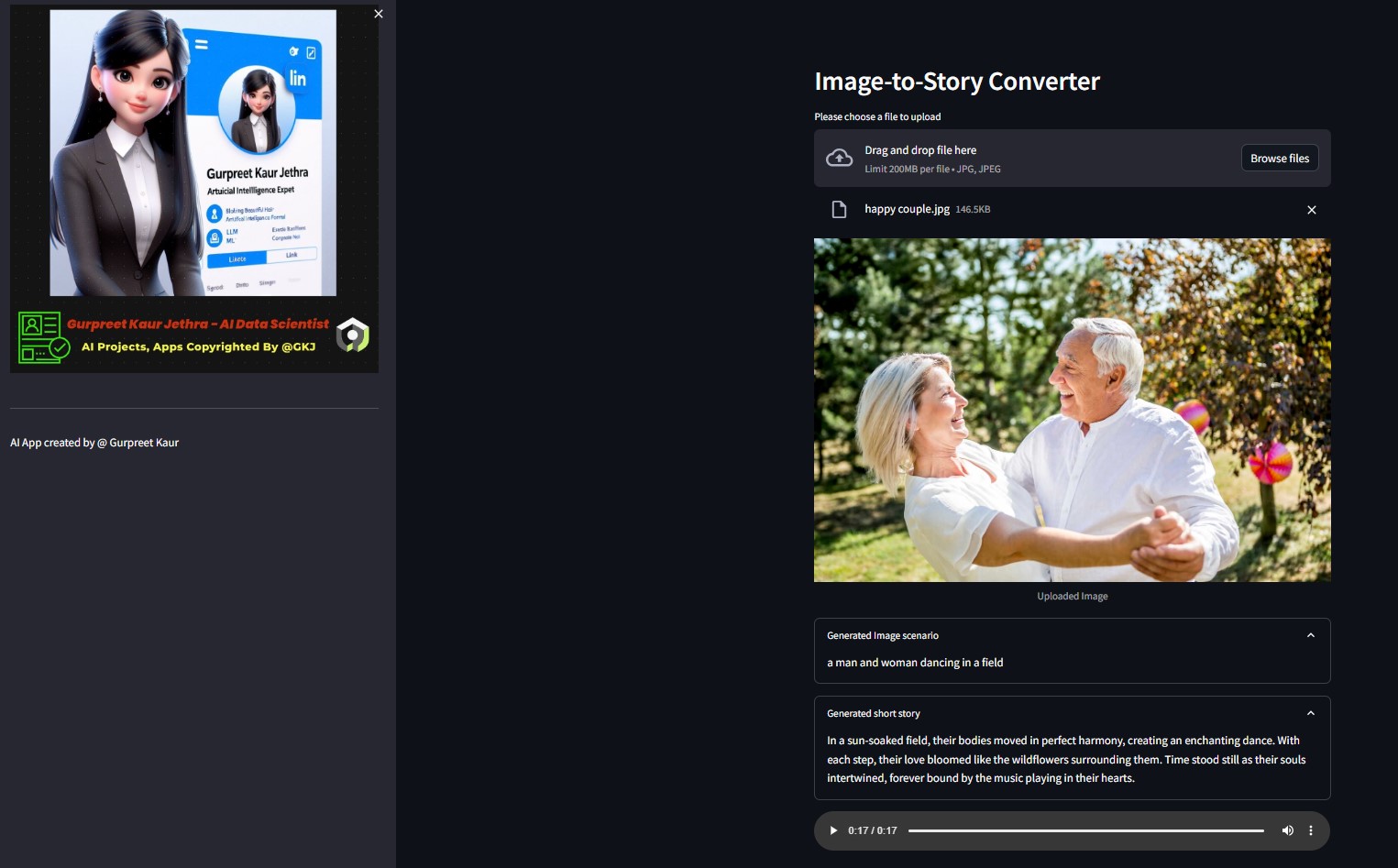
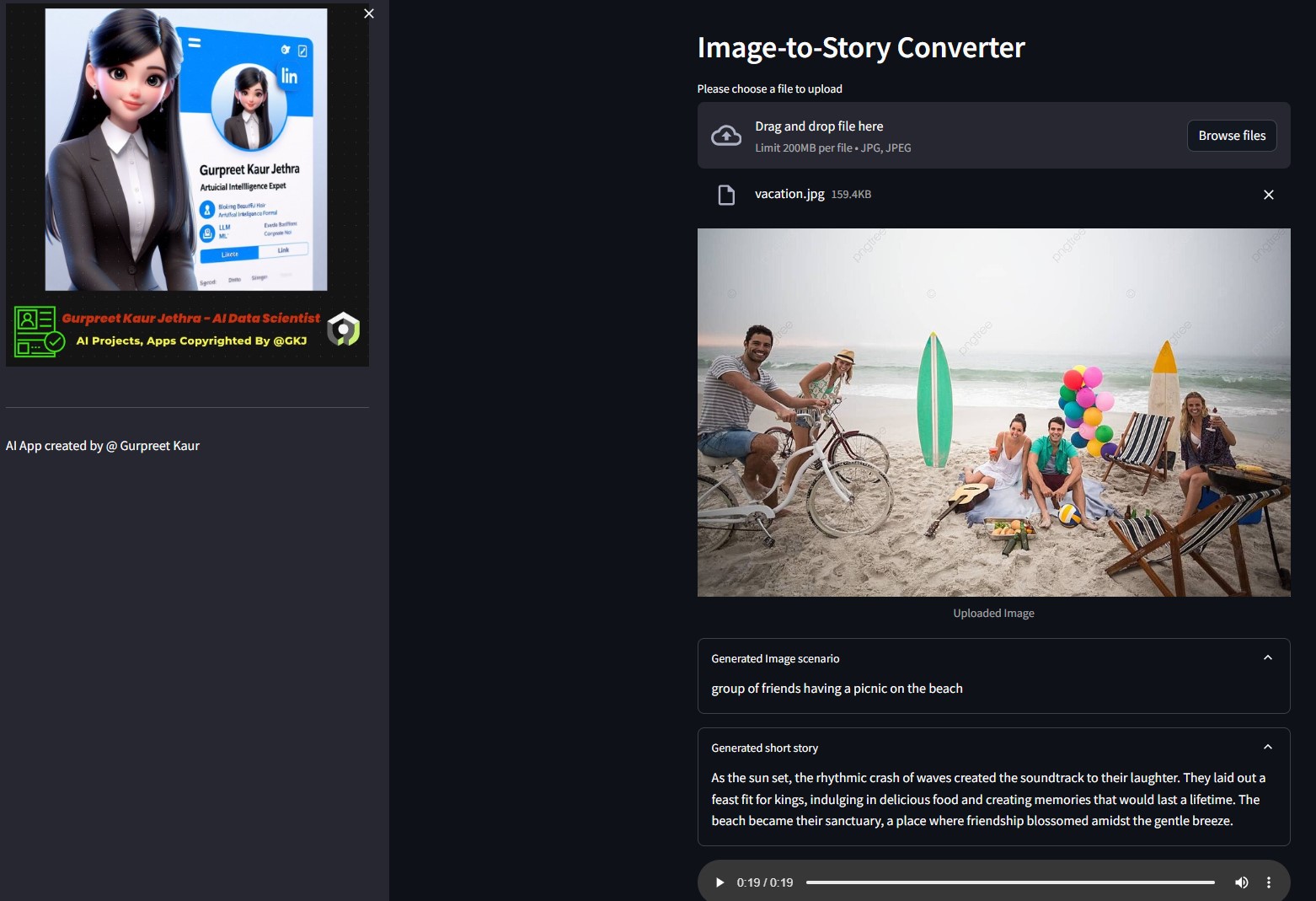
Sie können die jeweilige Audiodatei dieser Testdemobilder im jeweiligen img-audio Ordner anhören
?Systemdesign
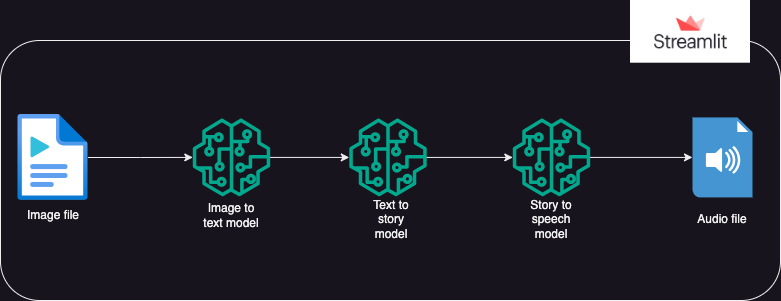
?Ansatz
Eine App, die Hugging Face-KI-Modelle verwendet, um Text aus einem Bild zu generieren, das dann Audio aus dem Text generiert.
Die Ausführung gliedert sich in 3 Teile:
- Bild zu Text: Ein Bild-zu-Text-Transformationsmodell (Salesforce/blip-image-captioning-base) wird verwendet, um ein Textszenario zu generieren, das auf dem KI-Verständnis des Bildkontexts basiert
- Text zur Geschichte: Das OpenAI LLM-Modell wird aufgefordert, eine Kurzgeschichte (50 Wörter: kann nach Bedarf angepasst werden) basierend auf dem generierten Szenario zu erstellen. gpt-3.5-turbo
- Story to Speech: Ein Text-to-Speech-Transformer-Modell (espnet/kan-bayashi_ljspeech_vits) wird verwendet, um die generierte Kurzgeschichte in eine spracherzählte Audiodatei umzuwandeln
- Mit Streamlit wird eine Benutzeroberfläche erstellt, die das Hochladen des Bildes und das Abspielen der Audiodatei ermöglicht
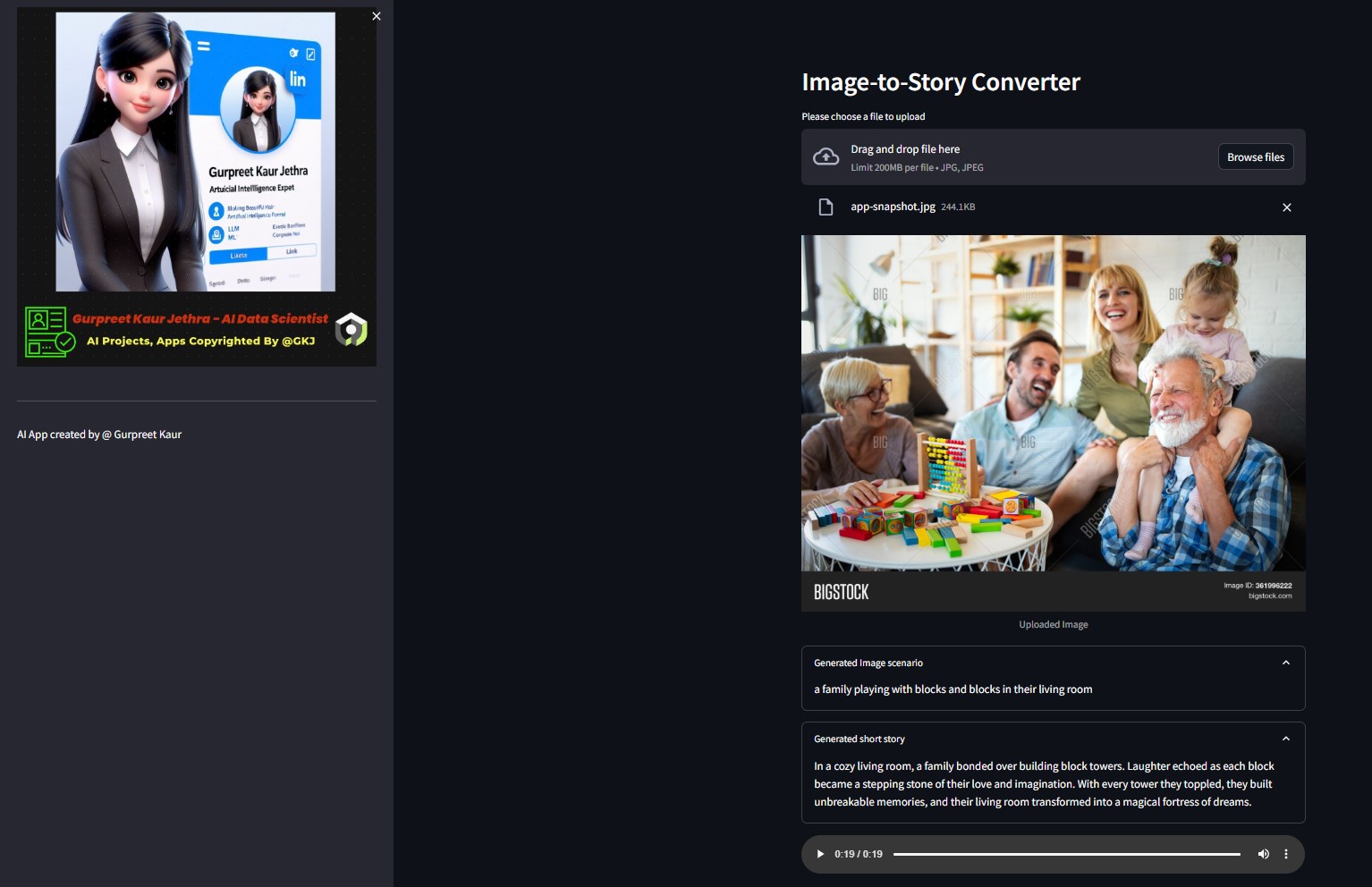 Sie können die entsprechende Audiodatei dieses Testbilds im entsprechenden
Sie können die entsprechende Audiodatei dieses Testbilds im entsprechenden img-audio Ordner anhören
?Anforderungen
- os
- python-dotenv
- Transformatoren
- Fackel
- langchain
- openai
- Anfragen
- streamlit
Verwendung
- Vor der Nutzung der App sollte der Nutzer über persönliche Token für Hugging Face und Open AI verfügen
- Der Benutzer sollte die Venv-Umgebung festlegen und die ipykernel-Bibliothek installieren, um die App auf der lokalen Systemidee auszuführen.
- Der Benutzer sollte die persönlichen Token in einer „.env“-Datei innerhalb des Pakets als String-Objekte unter den Objektnamen HUGGINGFACE_TOKEN und OPENAI_TOKEN speichern
- Der Benutzer kann die App dann mit dem folgenden Befehl ausführen: streamlit run app.py
- Sobald die App auf Streamlit läuft, kann der Benutzer das Zielbild hochladen
- Die Ausführung startet automatisch und kann einige Minuten dauern
- Sobald der Vorgang abgeschlossen ist, zeigt die App Folgendes an:
- Der vom Bild-zu-Text-Transformator HuggingFace-Modell generierte Szenariotext
- Die durch Aufforderung des OpenAI LLM generierte Kurzgeschichte
- Die Audiodatei, die die Kurzgeschichte erzählt, die vom Text-to-Speech-Transformer-Modell generiert wurde
- Bereitstellung der Gen AI App in der Streamlit Cloud und im Hugging Space
▶️ Installation
Klonen Sie das Repository:
git clone https://github.com/GURPREETKAURJETHRA/Image-to-Speech-GenAI-Tool-Using-LLM.git
Installieren Sie die erforderlichen Python-Pakete:
pip install -r requirements.txt
Richten Sie Ihren OpenAI-API-Schlüssel und Hugging Face Token ein, indem Sie im Stammverzeichnis des Projekts eine .env-Datei mit folgendem Inhalt erstellen:
OPENAI_API_KEY=<your-api-key-here> HUGGINGFACE_API_TOKEN=<<your-access-token-here>
Führen Sie die Streamlit-App aus:
streamlit run app.py
©️ Lizenz
Verteilt unter der MIT-Lizenz. Weitere Informationen finden Sie unter LICENSE .
Wenn Ihnen dieses LLM-Projekt gefällt, schauen Sie doch mal in diesem Repo vorbei und Beiträge sind willkommen! Wenn Sie Vorschläge zur Verbesserung dieses AI Img-Speech Converters haben, senden Sie bitte eine Pull-Anfrage.
Folge mir weiter


