BinaryVectorDB
1.0.0
Dieses Repository enthält eine binäre Vektordatenbank für die effiziente Suche in großen Datensätzen für Bildungszwecke.
Die meisten Einbettungsmodelle stellen ihre Vektoren als float32 dar: Diese verbrauchen viel Speicher und die Suche nach diesen ist sehr langsam. Bei Cohere haben wir das erste Einbettungsmodell mit nativer int8- und Binärunterstützung eingeführt, das Ihnen eine hervorragende Suchqualität zu einem Bruchteil der Kosten bietet:
| Modell | Suche Qualität MIRACL | Zeit, 1 Mio. Dokumente zu durchsuchen | Benötigter Speicher: 250 Mio. Wikipedia-Einbettungen | Preis auf AWS (x2gb-Instanz) |
|---|---|---|---|---|
| OpenAI text-embedding-3-small | 44.9 | 680 ms | 1431 GB | 65.231 $/Jahr |
| OpenAI text-embedding-3-large | 54.9 | 1240 ms | 2861 GB | 130.463 $/Jahr |
| Cohere Embed v3 (mehrsprachig) | ||||
| Einbetten von v3 – float32 | 66,3 | 460 ms | 954 GB | 43.488 $/Jahr |
| Einbetten von v3 – binär | 62,8 | 24 ms | 30 GB | 1.359 $/Jahr |
| Embed v3 – Binary + Int8 Rescore | 66,3 | 28 ms | 30 GB Speicher + 240 GB Festplatte | 1.589 $/Jahr |
Wir haben eine Demo erstellt, mit der Sie in 100 Millionen Wikipedia-Einbettungen nach einer VM suchen können, die nur 15 $/Monat kostet: Demo – Suchen Sie in 100 Millionen Wikipedia-Einbettungen für nur 15 $/Monat
Sie können BinaryVectorDB problemlos für Ihre eigenen Daten verwenden.
Die Einrichtung ist einfach:
pip install BinaryVectorDB
Um einige der folgenden Beispiele verwenden zu können, benötigen Sie einen Cohere-API-Schlüssel (kostenlos oder kostenpflichtig) von cohere.com. Sie müssen diesen API-Schlüssel als Umgebungsvariable festlegen: export COHERE_API_KEY=your_api_key
Wir zeigen später, wie Sie eine Vektor-DB auf Ihren eigenen Daten erstellen. Lassen Sie uns zunächst eine vorgefertigte binäre Vektordatenbank verwenden. Wir hosten verschiedene vorgefertigte Datenbanken auf https://huggingface.co/datasets/Cohere/BinaryVectorDB. Sie können diese herunterladen und vor Ort verwenden.
Lassen Sie uns zum Einstieg die einfache englische Version von Wikipedia verwenden:
wget https://huggingface.co/datasets/Cohere/BinaryVectorDB/resolve/main/wikipedia-2023-11-simple.zip
Und entpacken Sie dann diese Datei:
unzip wikipedia-2023-11-simple.zip
Sie können die Datenbank einfach laden, indem Sie sie auf den entpackten Ordner aus dem vorherigen Schritt verweisen:
from BinaryVectorDB import BinaryVectorDB
# Point it to the unzipped folder from the previous step
# Ensure that you have set your Cohere API key via: export COHERE_API_KEY=<<YOUR_KEY>>
db = BinaryVectorDB ( "wikipedia-2023-11-simple/" )
query = "Who is the founder of Facebook"
print ( "Query:" , query )
hits = db . search ( query )
for hit in hits [ 0 : 3 ]:
print ( hit )Die Datenbank hat 646.424 Einbettungen und eine Gesamtgröße von 962 MB. Allerdings werden nur 80 MB für die binären Einbettungen in den Speicher geladen. Die Dokumente und ihre int8-Einbettungen werden auf der Festplatte gespeichert und nur bei Bedarf geladen.
Diese Aufteilung in binäre Einbettungen im Speicher und int8-Einbettungen und Dokumente auf der Festplatte ermöglicht uns die Skalierung auf sehr große Datensätze, ohne dass wir viel Speicher benötigen.
Es ist ganz einfach, eine eigene Binärvektordatenbank zu erstellen.
from BinaryVectorDB import BinaryVectorDB
import os
import gzip
import json
simplewiki_file = "simple-wikipedia-example.jsonl.gz"
#If file not exist, download
if not os . path . exists ( simplewiki_file ):
cmd = f"wget https://huggingface.co/datasets/Cohere/BinaryVectorDB/resolve/main/simple-wikipedia-example.jsonl.gz"
os . system ( cmd )
# Create the vector DB with an empty folder
# Ensure that you have set your Cohere API key via: export COHERE_API_KEY=<<YOUR_KEY>>
db_folder = "path_to_an_empty_folder/"
db = BinaryVectorDB ( db_folder )
if len ( db ) > 0 :
exit ( f"The database { db_folder } is not empty. Please provide an empty folder to create a new database." )
# Read all docs from the jsonl.gz file
docs = []
with gzip . open ( simplewiki_file ) as fIn :
for line in fIn :
docs . append ( json . loads ( line ))
#Limit it to 10k docs to make the next step a bit faster
docs = docs [ 0 : 10_000 ]
# Add all documents to the DB
# docs2text defines a function that maps our documents to a string
# This string is then embedded with the state-of-the-art Cohere embedding model
db . add_documents ( doc_ids = list ( range ( len ( docs ))), docs = docs , docs2text = lambda doc : doc [ 'title' ] + " " + doc [ 'text' ]) Das Dokument kann ein beliebiges serialisierbares Python-Objekt sein. Sie müssen eine Funktion für docs2text bereitstellen, die Ihr Dokument einer Zeichenfolge zuordnet. Im obigen Beispiel verketten wir das Titel- und das Textfeld. Diese Zeichenfolge wird an das Einbettungsmodell gesendet, um die erforderlichen Texteinbettungen zu erzeugen.
Das Hinzufügen/Löschen/Aktualisieren von Dokumenten ist einfach. Unter „examples/add_update_delete.py“ finden Sie ein Beispielskript zum Hinzufügen/Aktualisieren/Löschen von Dokumenten in der Datenbank.
Wir haben unsere Cohere int8- und Binary Embeddings-Einbettungen angekündigt, die eine 4-fache und 32-fache Reduzierung des benötigten Speichers bieten. Darüber hinaus ermöglicht es eine bis zu 40-fache Beschleunigung der Vektorsuche.
Beide Techniken sind in der BinaryVectorDB vereint. Nehmen wir als Beispiel die englische Wikipedia mit 42 Millionen Einbettungen. Normale Float32-Einbettungen würden 42*10^6*1024*4 = 160 GB Speicher benötigen, um nur die Einbettungen zu hosten. Da die Suche auf float32 ziemlich langsam ist (etwa 45 Sekunden bei 42-Millionen-Einbettungen), müssen wir einen Index wie HNSW hinzufügen, der weitere 20 GB Speicher hinzufügt, sodass Sie insgesamt 180 GB benötigen.
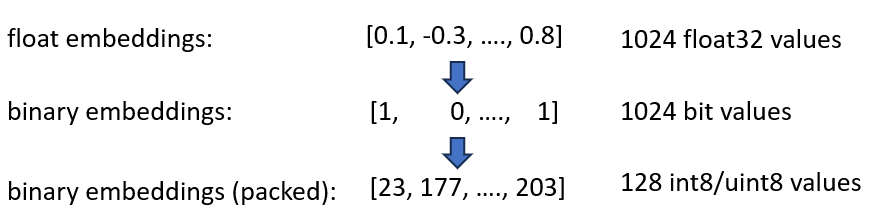
Binäre Einbettungen stellen jede Dimension als 1 Bit dar. Dadurch reduziert sich der Speicherbedarf auf 160 GB / 32 = 5GB . Da die Suche im Binärraum außerdem 40-mal schneller ist, benötigen Sie in vielen Fällen den HNSW-Index nicht mehr. Sie haben Ihren Speicherbedarf von 180 GB auf 5 GB reduziert, eine schöne 36-fache Ersparnis.
Wenn wir diesen Index abfragen, kodieren wir die Abfrage auch binär und verwenden die Hamming-Distanz. Die Hamming-Distanz misst die 1-Bit-Differenzen zwischen zwei Vektoren. Dies ist eine extrem schnelle Operation: Um zwei binäre Vektoren zu vergleichen, benötigen Sie lediglich 2 CPU-Zyklen: popcount(xor(vector1, vector2)) . XOR ist die grundlegendste Operation auf CPUs und läuft daher extrem schnell. popcount zählt die Zahl 1 im Register, was ebenfalls nur 1 CPU-Zyklus benötigt.
Insgesamt erhalten wir so eine Lösung, die etwa 90 % der Suchqualität beibehält.
Wir können die Suchqualität gegenüber dem vorherigen Schritt von 90 % auf 95 % erhöhen, indem wir <float, binary> neu bewerten.
Wir nehmen beispielsweise die Top-100-Ergebnisse aus Schritt 1 und berechnen dot_product(query_float_embedding, 2*binary_doc_embedding-1) .
Angenommen, unsere Abfrageeinbettung ist [0.1, -0.3, 0.4] und unsere Binärdokumenteinbettung ist [1, 0, 1] . Dieser Schritt berechnet dann:
(0.1)*(1) + (-0.3)*(-1) + 0.4*(1) = 0.1 + 0.3 + 0.4 = 0.8

Wir verwenden diese Ergebnisse und bewerten unsere Ergebnisse neu. Dadurch steigt die Suchqualität von 90 % auf 95 %. Diese Operation kann extrem schnell durchgeführt werden: Wir erhalten die Abfrage-Float-Einbettung aus dem Einbettungsmodell, die binären Einbettungen liegen im Speicher, wir müssen also nur 100 Summenoperationen durchführen.
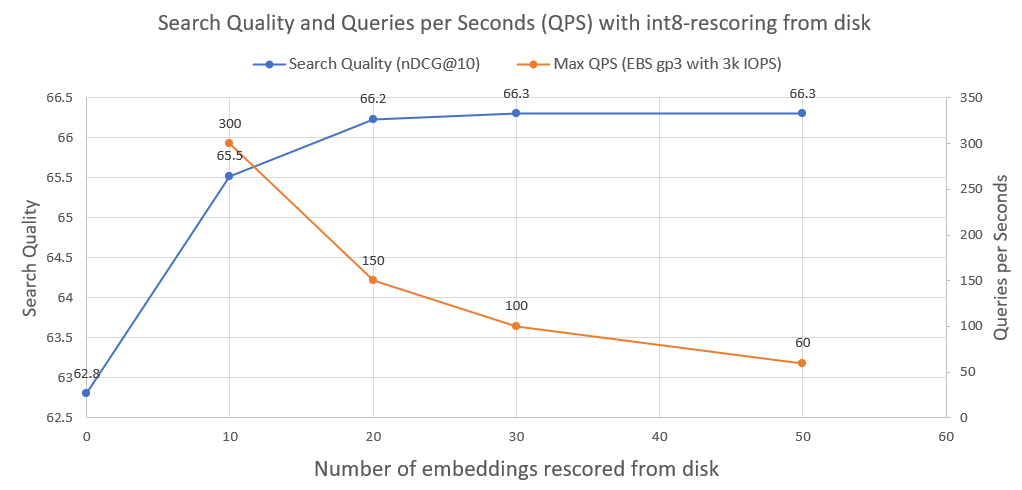
Um die Suchqualität weiter zu verbessern, von 95 % auf 99,99 %, verwenden wir int8-Rescoring von der Festplatte.
Wir speichern alle int8-Dokumenteinbettungen auf der Festplatte. Wir nehmen dann die Top-30 aus dem obigen Schritt, laden die int8-embeddings von der Festplatte und berechnen cossim(query_float_embedding, int8_doc_embedding_from_disk)
Im folgenden Bild können Sie sehen, wie viel Int8-Rescoring und die Suchleistung verbessert werden:
Wir haben auch die Abfragen pro Sekunde aufgezeichnet, die ein solches System erreichen kann, wenn es auf einem normalen AWS EBS-Netzwerklaufwerk mit 3000 IOPS ausgeführt wird. Wie wir sehen, gilt: Je mehr int8-Einbettungen wir von der Festplatte laden müssen, desto weniger QPS.
Um die binäre Suche durchzuführen, verwenden wir den IndexBinaryFlat-Index von faiss. Es speichert lediglich die binären Einbettungen und ermöglicht eine superschnelle Indizierung und eine superschnelle Suche.
Zum Speichern der Dokumente und der int8-Einbettungen verwenden wir RocksDict, einen On-Disk-Schlüsselwertspeicher für Python basierend auf RocksDB.
Die vollständige Implementierung der Klasse finden Sie unter BinaryVectorDB.
Nicht wirklich. Das Repository ist hauptsächlich für Bildungszwecke gedacht, um Techniken zur Skalierung auf große Datensätze zu zeigen. Der Fokus lag mehr auf der Benutzerfreundlichkeit und einige kritische Aspekte fehlen in der Implementierung, wie Multiprozesssicherheit, Rollbacks usw.
Wenn Sie tatsächlich in die Produktion gehen möchten, verwenden Sie eine geeignete Vektordatenbank wie Vespa.ai, mit der Sie ähnliche Ergebnisse erzielen können.
Bei Cohere haben wir Kunden dabei geholfen, die semantische Suche für zig Milliarden Einbettungen zu einem Bruchteil der Kosten durchzuführen. Wenden Sie sich gerne an Nils Reimers, wenn Sie eine skalierbare Lösung benötigen.


