VideoX
1.0.0
Dies ist eine Sammlung unserer Videoverständnisarbeit
SeqTrack (
@CVPR'23): SeqTrack: Sequenz-zu-Sequenz-Lernen für die visuelle Objektverfolgung
X-CLIP (
@ECCV'22 Oral): Erweiterung der vorab trainierten Sprach-Bild-Modelle für die allgemeine Videoerkennung
MS-2D-TAN (
@TPAMI'21): Mehrskalige 2D-zeitlich benachbarte Netzwerke für Momentlokalisierung mit natürlicher Sprache
2D-TAN (
@AAAI'20): Erlernen zeitlich benachbarter 2D-Netzwerke zur Momentlokalisierung mit natürlicher Sprache
Einstellung von Forschungspraktikanten mit ausgeprägten Programmierkenntnissen: [email protected] | [email protected]
April 2023: Code für SeqTrack ist jetzt veröffentlicht.
Februar 2023: SeqTrack wurde in CVPR'23 aufgenommen
September 2022: X-CLIP ist jetzt integriert in
August 2022: Der Code für X-CLIP ist jetzt veröffentlicht.
Juli 2022: X-CLIP wurde als Oral in ECCV'22 aufgenommen
Okt. 2021: Der Code für MS-2D-TAN ist jetzt veröffentlicht.
September 2021: MS-2D-TAN wurde in TPAMI'21 aufgenommen
Dez. 2019: Der Code für 2D-TAN ist jetzt veröffentlicht.
Nov. 2019: 2D-TAN wurde in AAAI'20 aufgenommen
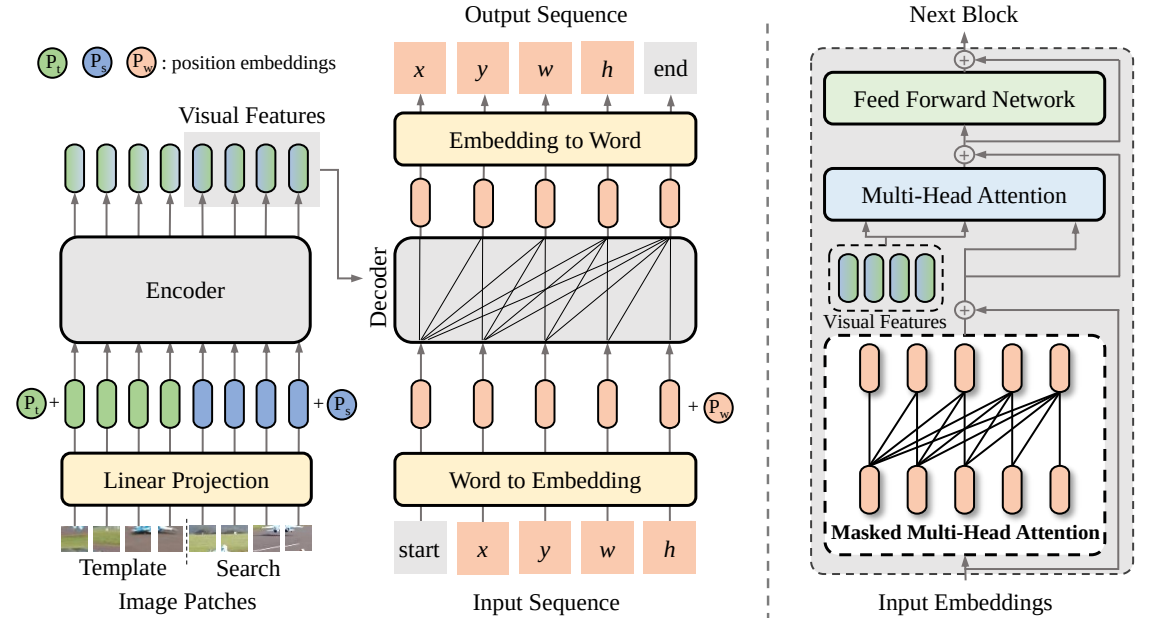
In diesem Artikel schlagen wir ein neues Sequenz-zu-Sequenz-Lernframework für die visuelle Verfolgung vor, genannt SeqTrack. Es betrachtet die visuelle Verfolgung als ein Problem der Sequenzgenerierung, das Objektbegrenzungsrahmen auf autoregressive Weise vorhersagt. SeqTrack verwendet nur eine einfache Encoder-Decoder-Transformator-Architektur. Der Encoder extrahiert visuelle Merkmale mit einem bidirektionalen Transformator, während der Decoder mit einem Kausaldecoder autoregressiv eine Folge von Begrenzungsrahmenwerten generiert. Die Verlustfunktion ist eine einfache Kreuzentropie. Ein solches Sequenzlernparadigma vereinfacht nicht nur das Tracking-Framework, sondern erzielt auch eine wettbewerbsfähige Leistung bei vielen Benchmarks.
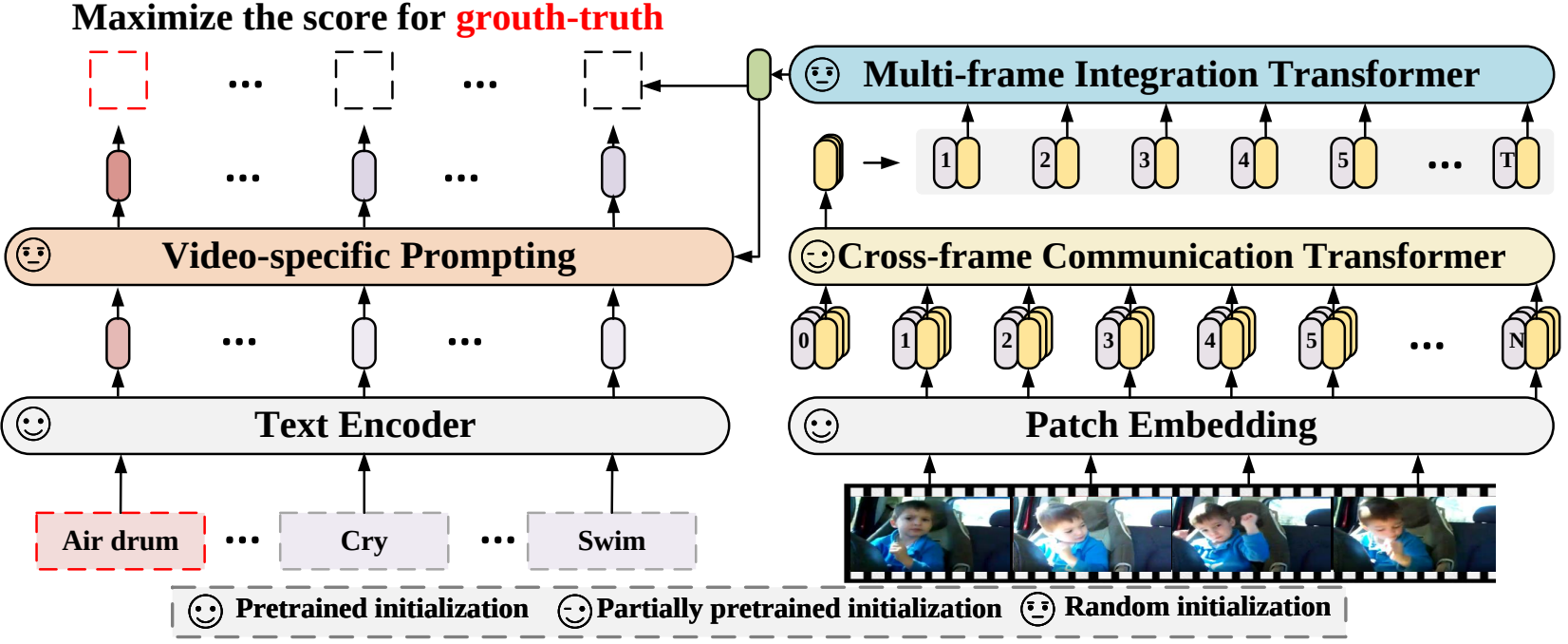
In diesem Artikel schlagen wir ein neues Videoerkennungs-Framework vor, das die vorab trainierten Sprach-Bild-Modelle an die Videoerkennung anpasst. Um die zeitlichen Informationen zu erfassen, schlagen wir insbesondere einen Frame-übergreifenden Aufmerksamkeitsmechanismus vor, der explizit Informationen über Frames hinweg austauscht. Um die Textinformationen in Videokategorien zu nutzen, entwerfen wir eine videospezifische Aufforderungstechnik, die eine diskriminierende Textdarstellung auf Instanzebene ermöglichen kann. Umfangreiche Experimente zeigen, dass unser Ansatz effektiv ist und auf verschiedene Videoerkennungsszenarien übertragen werden kann, darunter vollständig überwacht, wenige Aufnahmen und keine Aufnahmen.
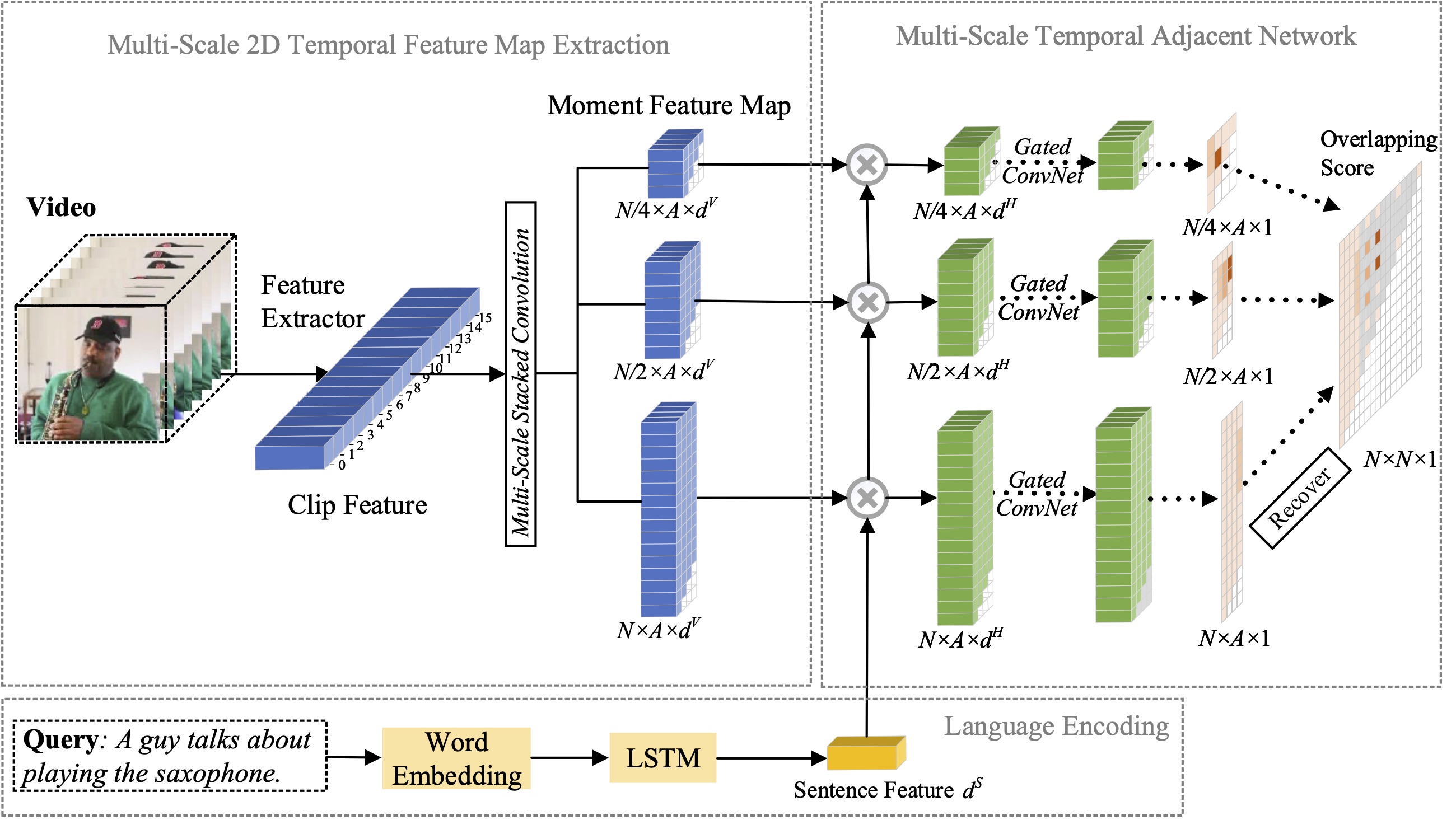
In diesem Artikel untersuchen wir das Problem der Momentlokalisierung mit natürlicher Sprache und schlagen eine Erweiterung unserer zuvor vorgeschlagenen 2D-TAN-Methode auf eine Multiskalenversion vor. Die Kernidee besteht darin, einen Moment aus zweidimensionalen Zeitkarten auf verschiedenen Zeitskalen abzurufen, wobei benachbarte Momentkandidaten als zeitlicher Kontext berücksichtigt werden. Die erweiterte Version ist in der Lage, benachbarte zeitliche Beziehungen in verschiedenen Maßstäben zu kodieren und gleichzeitig Unterscheidungsmerkmale zu erlernen, um Videomomente mit verweisenden Ausdrücken abzugleichen. Unser Modell ist einfach aufgebaut und erzielt im Vergleich zu den modernsten Methoden anhand von drei Benchmark-Datensätzen eine wettbewerbsfähige Leistung.
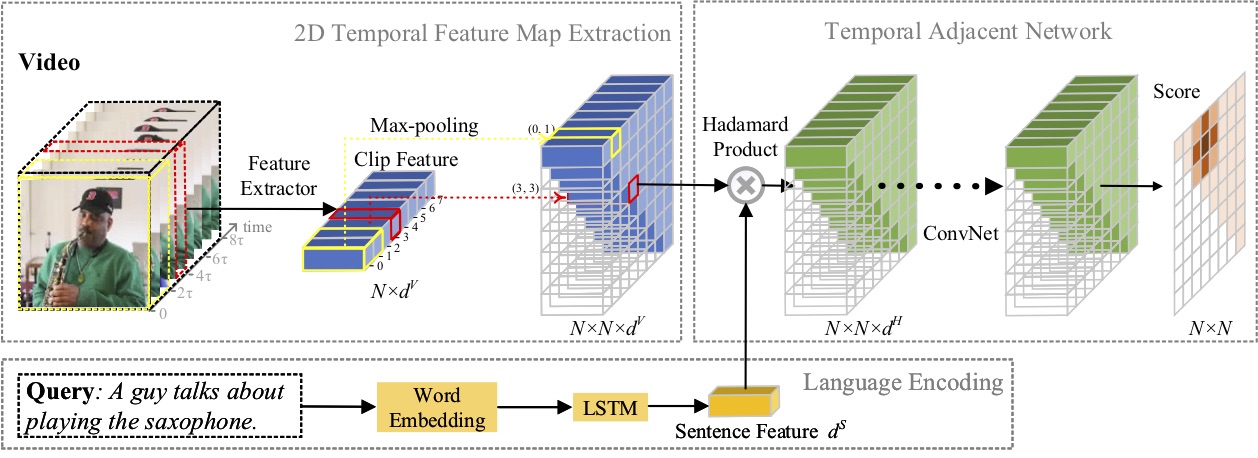
In diesem Artikel untersuchen wir das Problem der Momentlokalisierung mit natürlicher Sprache und schlagen eine neuartige Methode für 2D Temporal Adjacent Networks (2D-TAN) vor. Die Kernidee besteht darin, einen Moment auf einer zweidimensionalen Zeitkarte abzurufen, die benachbarte Momentkandidaten als zeitlichen Kontext berücksichtigt. 2D-TAN ist in der Lage, benachbarte zeitliche Beziehungen zu kodieren und gleichzeitig Unterscheidungsmerkmale zu erlernen, um Videomomente mit entsprechenden Ausdrücken abzugleichen. Unser Modell ist einfach aufgebaut und erzielt im Vergleich zu den modernsten Methoden anhand von drei Benchmark-Datensätzen eine wettbewerbsfähige Leistung.
@InProceedings{SeqTrack, title={SeqTrack: Sequence to Sequence Learning for Visual Object Tracking}, Autor={Chen, Xin und Peng, Houwen und Wang, Dong und Lu, Huchuan und Hu, Han}, Buchtitel={CVPR}, Jahr={2023}}@InProceedings{XCLIP, title={Erweitern vorab trainierter Sprachbildmodelle für allgemeine Videos Anerkennung}, Autor={Ni, Bolin und Peng, Houwen und Chen, Minghao und Zhang, Songyang und Meng, Gaofeng und Fu, Jianlong und Xiang, Shiming und Ling, Haibin}, Buchtitel={European Conference on Computer Vision (ECCV) }, Jahr={2022}}@InProceedings{Zhang2021MS2DTAN,
Autor = {Zhang, Songyang und Peng, Houwen und Fu, Jianlong und Lu, Yijuan und Luo, Jiebo},
title = {Mehrskalige 2D-Temporal-Adjacent-Netzwerke für Momentlokalisierung mit natürlicher Sprache},
Buchtitel = {TPAMI},
Jahr = {2021}}@InProceedings{2DTAN_2020_AAAI,
Autor = {Zhang, Songyang und Peng, Houwen und Fu, Jianlong und Luo, Jiebo},
title = {Lernen von 2D-Temporal Adjacent Networks für Moment-Lokalisierung mit natürlicher Sprache},
Buchtitel = {AAAI},
Jahr = {2020}}Lizenz unter einer MIT-Lizenz.


