SWE-Bank
1.0.0

| 日本語 | Englisch | 中文简体 | 中文繁體 |
Code und Daten für unser ICLR 2024-Papier SWE-bench: Können Sprachmodelle reale GitHub-Probleme lösen?
Auf unserer Website finden Sie die öffentliche Bestenliste und das Änderungsprotokoll für Informationen zu den neuesten Aktualisierungen des SWE-Benchmark-Benchmarks.
SWE-Bench ist ein Benchmark zur Bewertung großer Sprachmodelle zu realen Softwareproblemen, der von GitHub gesammelt wurde. Bei einer gegebenen Codebasis und einem Problem wird ein Sprachmodell damit beauftragt, einen Patch zu generieren, der das beschriebene Problem behebt.
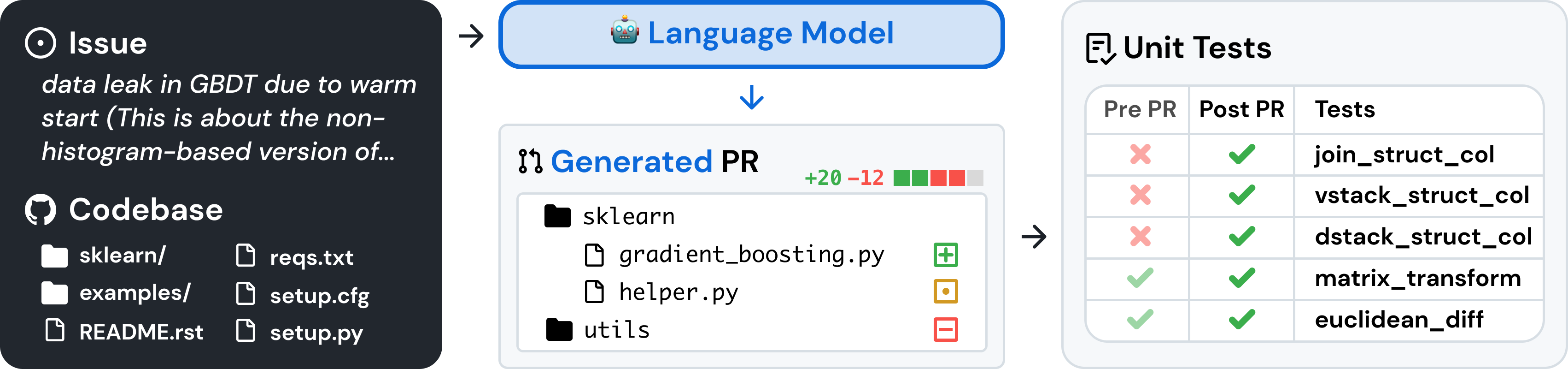
Um auf SWE-bench zuzugreifen, kopieren Sie den folgenden Code und führen Sie ihn aus:
from datasets import load_dataset
swebench = load_dataset ( 'princeton-nlp/SWE-bench' , split = 'test' )SWE-bench nutzt Docker für reproduzierbare Auswertungen. Befolgen Sie die Anweisungen im Docker-Setup-Handbuch, um Docker auf Ihrem Computer zu installieren. Wenn Sie die Einrichtung unter Linux durchführen, empfehlen wir Ihnen, sich auch die Schritte nach der Installation anzusehen.
Um schließlich die SWE-Bench aus dem Quellcode zu erstellen, führen Sie die folgenden Schritte aus:
git clone [email protected]:princeton-nlp/SWE-bench.git
cd SWE-bench
pip install -e .Testen Sie Ihre Installation, indem Sie Folgendes ausführen:
python -m swebench.harness.run_evaluation
--predictions_path gold
--max_workers 1
--instance_ids sympy__sympy-20590
--run_id validate-goldWarnung
Das Ausführen schneller Evaluierungen auf der SWE-Bench kann ressourcenintensiv sein. Wir empfehlen, die Evaluierungsumgebung auf einem x86_64 Computer mit mindestens 120 GB freiem Speicher, 16 GB RAM und 8 CPU-Kernen auszuführen. Möglicherweise müssen Sie mit dem Argument --max_workers experimentieren, um die optimale Anzahl von Workern für Ihren Computer zu finden. Wir empfehlen jedoch, weniger als min(0.75 * os.cpu_count(), 24) zu verwenden.
Wenn Sie mit dem Docker-Desktop arbeiten, stellen Sie sicher, dass Sie den Speicherplatz auf Ihrer virtuellen Festplatte erhöhen, sodass etwa 120 freie GB verfügbar sind, und stellen Sie „max_workers“ so ein, dass es mit den oben genannten Angaben für die für Docker verfügbaren CPUs übereinstimmt.
Die Unterstützung für arm64 -Maschinen ist experimentell.
Bewerten Sie Modellvorhersagen auf SWE-bench Lite mithilfe des Evaluierungskabels mit dem folgenden Befehl:
python -m swebench.harness.run_evaluation
--dataset_name princeton-nlp/SWE-bench_Lite
--predictions_path < path_to_predictions >
--max_workers < num_workers >
--run_id < run_id >
# use --predictions_path 'gold' to verify the gold patches
# use --run_id to name the evaluation run Dieser Befehl generiert Docker-Build-Protokolle ( logs/build_images ) und Evaluierungsprotokolle ( logs/run_evaluation ) im aktuellen Verzeichnis.
Die endgültigen Bewertungsergebnisse werden im Verzeichnis evaluation_results gespeichert.
Führen Sie Folgendes aus, um die vollständige Liste der Argumente für die Bewertungsumgebung anzuzeigen:
python -m swebench.harness.run_evaluation --helpDarüber hinaus kann Ihnen das SWE-Bench-Repo dabei helfen:
| Datensätze | Modelle |
|---|---|
| ? SWE-Bank | ? SWE-Lama 13b |
| ? „Oracle“-Abruf | ? SWE-Lama 13b (PEFT) |
| ? BM25-Abruf 13K | ? SWE-Lama 7b |
| ? BM25-Abruf 27K | ? SWE-Lama 7b (PEFT) |
| ? BM25-Abruf 40.000 | |
| ? BM25-Abruf 50.000 (Lama-Token) |
Wir haben auch die folgenden Blogbeiträge über die Verwendung verschiedener Teile von SWE-bench geschrieben. Wenn Sie einen Beitrag zu einem bestimmten Thema sehen möchten, teilen Sie uns dies bitte über ein Problem mit.
Wir würden gerne von der breiteren NLP-, maschinellen Lern- und Software-Engineering-Forschungsgemeinschaft hören und freuen uns über alle Beiträge, Pull-Requests oder Probleme! Bitte reichen Sie dazu entweder einen neuen Pull-Request oder Issue ein und füllen Sie die entsprechenden Vorlagen entsprechend aus. Wir werden uns in Kürze bei Ihnen melden!
Ansprechpartner: Carlos E. Jimenez und John Yang (E-Mail: [email protected], [email protected]).
Wenn Sie unsere Arbeit hilfreich finden, verwenden Sie bitte die folgenden Zitate.
@inproceedings{
jimenez2024swebench,
title={{SWE}-bench: Can Language Models Resolve Real-world Github Issues?},
author={Carlos E Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R Narasimhan},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=VTF8yNQM66}
}
MIT. Überprüfen Sie LICENSE.md .
