LLM4Decompile
1.0.0
![]()
Ergebnisse | ? Modelle | Schnellstart | HumanEval-Decompile | ? Zitat | Papier | Colab |
Reverse Engineering: Dekompilieren von Binärcode mit großen Sprachmodellen
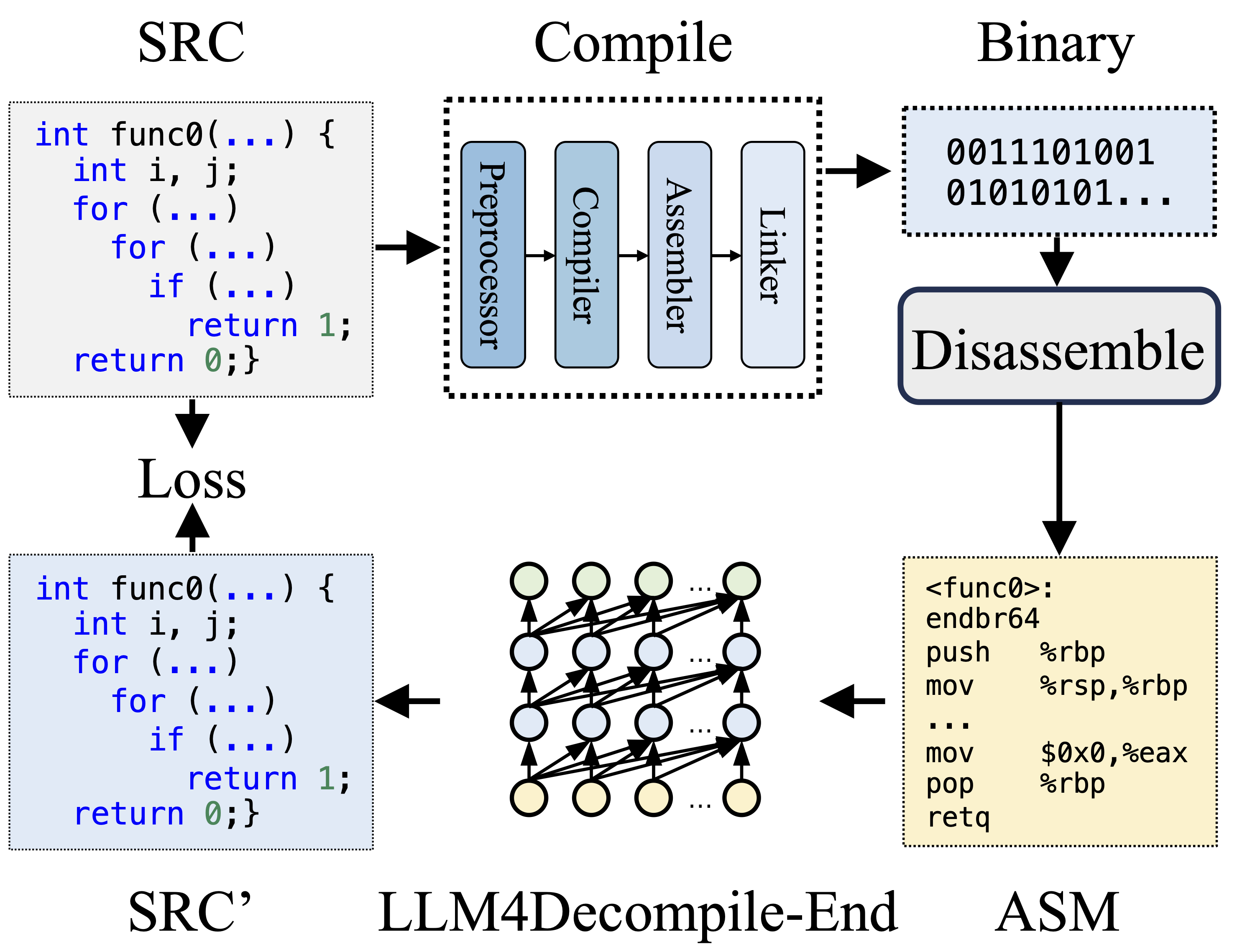
Während der Kompilierung verarbeitet der Präprozessor den Quellcode (SRC), um Kommentare zu entfernen und Makros oder Includes zu erweitern. Der bereinigte Code wird dann an den Compiler weitergeleitet, der ihn in Assembler-Code (ASM) umwandelt. Dieses ASM wird vom Assembler in Binärcode (0en und 1en) umgewandelt. Der Linker schließt den Prozess ab, indem er Funktionsaufrufe verknüpft, um eine ausführbare Datei zu erstellen. Bei der Dekompilierung hingegen geht es um die Rückkonvertierung von Binärcode in eine Quelldatei. LLMs, die auf Text trainiert werden, sind nicht in der Lage, Binärdaten direkt zu verarbeiten. Daher müssen Binärdateien zuerst von Objdump in Assemblersprache (ASM) zerlegt werden. Es ist zu beachten, dass binäre und disassemblierte ASM gleichwertig sind, ineinander konvertiert werden können und wir sie daher austauschbar bezeichnen. Schließlich wird der Verlust zwischen dem dekompilierten Code und dem Quellcode berechnet, um das Training zu steuern. Um die Qualität des dekompilierten Codes (SRC') zu beurteilen, wird dieser durch Testassertions auf seine Funktionalität getestet (Re-Ausführbarkeit).
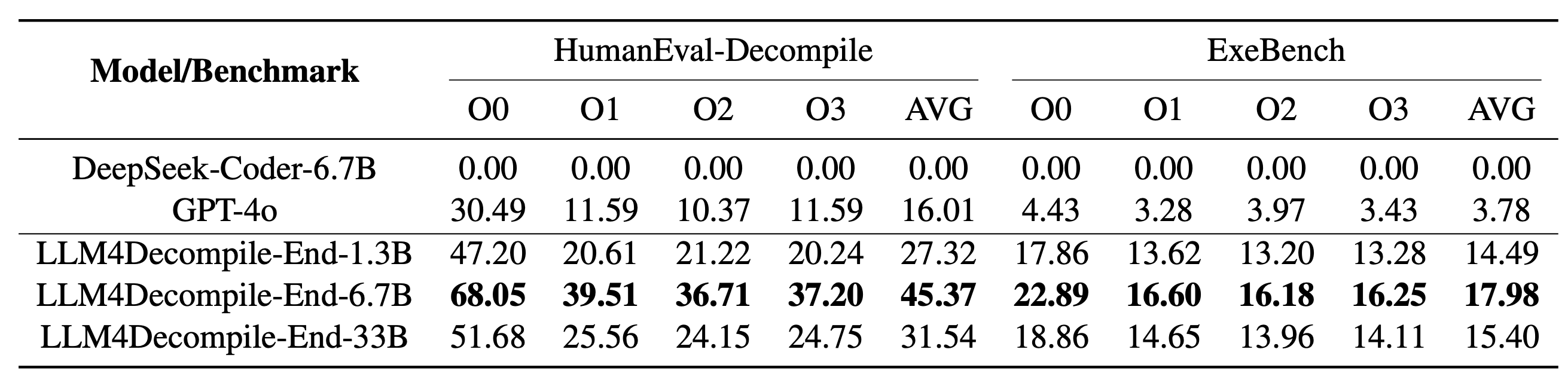
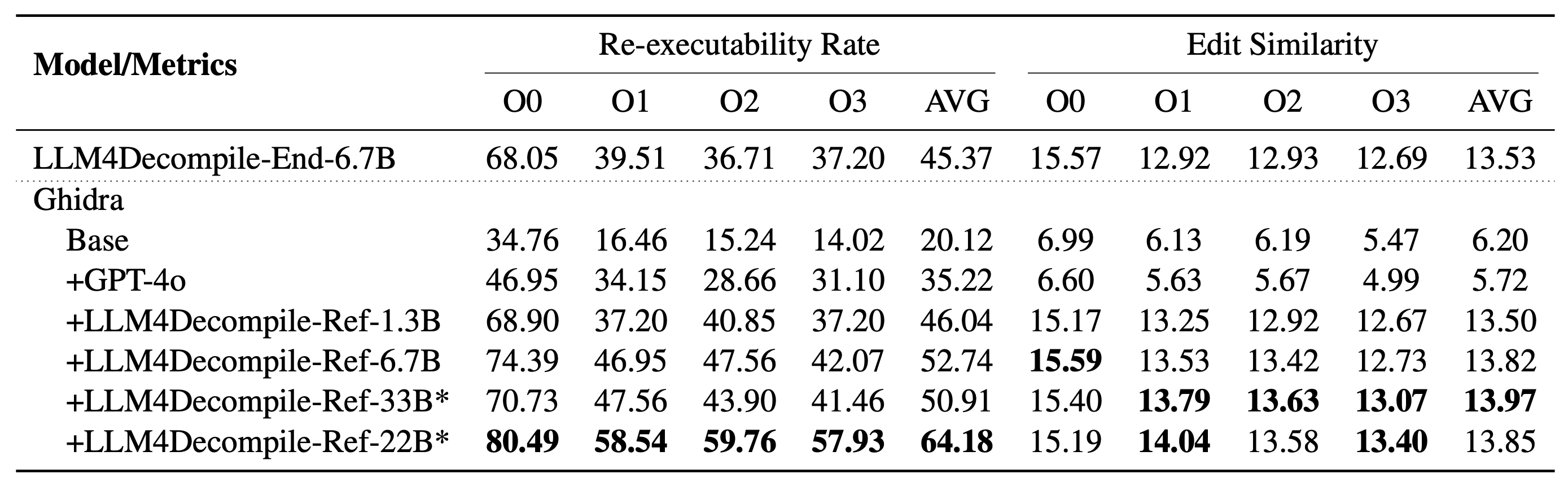
Unser LLM4Decompile umfasst Modelle mit Größen zwischen 1,3 Milliarden und 33 Milliarden Parametern, und wir haben diese Modelle auf Hugging Face verfügbar gemacht.
| Modell | Kontrollpunkt | Größe | Wiederausführbarkeit | Notiz |
|---|---|---|---|---|
| llm4decompile-1.3b-v1.5 | ? HF-Link | 1,3B | 27,3 % | Hinweis 3 |
| llm4decompile-6.7b-v1.5 | ? HF-Link | 6,7B | 45,4 % | Hinweis 3 |
| llm4decompile-1.3b-v2 | ? HF-Link | 1,3B | 46,0 % | Hinweis 4 |
| llm4decompile-6.7b-v2 | ? HF-Link | 6,7B | 52,7 % | Hinweis 4 |
| llm4decompile-9b-v2 | ? HF-Link | 9B | 64,9 % | Hinweis 4 |
| llm4decompile-22b-v2 | ? HF-Link | 22B | 63,6 % | Hinweis 4 |
Hinweis 3: V1.5-Serien werden mit einem größeren Datensatz (15B Token) und einer maximalen Tokengröße von 4.096 trainiert, mit bemerkenswerter Leistung (über 100 % Verbesserung) im Vergleich zum Vorgängermodell.
Anmerkung 4: V2-Serien basieren auf Ghidra und werden auf 2 Milliarden Token trainiert, um den dekompilierten Pseudocode von Ghidra zu verfeinern . Weitere Informationen finden Sie im Ghidra-Ordner.
Setup: Bitte verwenden Sie das folgende Skript, um die erforderliche Umgebung zu installieren.
git clone https://github.com/albertan017/LLM4Decompile.git
cd LLM4Decompile
conda create -n 'llm4decompile' python=3.9 -y
conda activate llm4decompile
pip install -r requirements.txt
Hier ist ein Beispiel für die Verwendung unseres Modells (Überarbeitet für V1.5. Für frühere Modelle schauen Sie bitte auf der entsprechenden Modellseite bei HF nach). Hinweis: Ersetzen Sie „func0“ durch den Funktionsnamen, den Sie dekompilieren möchten .
Vorverarbeitung: Kompilieren Sie den C-Code in eine Binärdatei und zerlegen Sie die Binärdatei in Assembleranweisungen.
import subprocess
import os
func_name = 'func0'
OPT = [ "O0" , "O1" , "O2" , "O3" ]
fileName = 'samples/sample' #'path/to/file'
for opt_state in OPT :
output_file = fileName + '_' + opt_state
input_file = fileName + '.c'
compile_command = f'gcc -o { output_file } .o { input_file } - { opt_state } -lm' #compile the code with GCC on Linux
subprocess . run ( compile_command , shell = True , check = True )
compile_command = f'objdump -d { output_file } .o > { output_file } .s' #disassemble the binary file into assembly instructions
subprocess . run ( compile_command , shell = True , check = True )
input_asm = ''
with open ( output_file + '.s' ) as f : #asm file
asm = f . read ()
if '<' + func_name + '>:' not in asm : #IMPORTANT replace func0 with the function name
raise ValueError ( "compile fails" )
asm = '<' + func_name + '>:' + asm . split ( '<' + func_name + '>:' )[ - 1 ]. split ( ' n n ' )[ 0 ] #IMPORTANT replace func0 with the function name
asm_clean = ""
asm_sp = asm . split ( " n " )
for tmp in asm_sp :
if len ( tmp . split ( " t " )) < 3 and '00' in tmp :
continue
idx = min (
len ( tmp . split ( " t " )) - 1 , 2
)
tmp_asm = " t " . join ( tmp . split ( " t " )[ idx :]) # remove the binary code
tmp_asm = tmp_asm . split ( "#" )[ 0 ]. strip () # remove the comments
asm_clean += tmp_asm + " n "
input_asm = asm_clean . strip ()
before = f"# This is the assembly code: n " #prompt
after = " n # What is the source code? n " #prompt
input_asm_prompt = before + input_asm . strip () + after
with open ( fileName + '_' + opt_state + '.asm' , 'w' , encoding = 'utf-8' ) as f :
f . write ( input_asm_prompt )Die Montageanleitung sollte folgendes Format haben:
<FUNCTION_NAME>:nOPERATIONSnOPERATIONSn
Eine typische Montageanleitung könnte so aussehen:
<func0>:
endbr64
lea (%rdi,%rsi,1),%eax
retq
Dekompilierung: Verwenden Sie LLM4Decompile, um die Assembleranweisungen in C zu übersetzen:
from transformers import AutoTokenizer , AutoModelForCausalLM
import torch
model_path = 'LLM4Binary/llm4decompile-6.7b-v1.5' # V1.5 Model
tokenizer = AutoTokenizer . from_pretrained ( model_path )
model = AutoModelForCausalLM . from_pretrained ( model_path , torch_dtype = torch . bfloat16 ). cuda ()
with open ( fileName + '_' + OPT [ 0 ] + '.asm' , 'r' ) as f : #optimization level O0
asm_func = f . read ()
inputs = tokenizer ( asm_func , return_tensors = "pt" ). to ( model . device )
with torch . no_grad ():
outputs = model . generate ( ** inputs , max_new_tokens = 2048 ) ### max length to 4096, max new tokens should be below the range
c_func_decompile = tokenizer . decode ( outputs [ 0 ][ len ( inputs [ 0 ]): - 1 ])
with open ( fileName + '.c' , 'r' ) as f : #original file
func = f . read ()
print ( f'original function: n { func } ' ) # Note we only decompile one function, where the original file may contain multiple functions
print ( f'decompiled function: n { c_func_decompile } ' ) Die Daten werden in llm4decompile/decompile-eval/decompile-eval-executable-gcc-obj.json im JSON-Listenformat gespeichert. Es gibt 164*4 (O0, O1, O2, O3) Samples mit jeweils fünf Schlüsseln:
task_id : gibt die ID des Problems an.type : Die Optimierungsstufe ist einer von [O0, O1, O2, O3].c_func : C-Lösung für das HumanEval-Problem.c_test : C-Testaussagen.input_asm_prompt : Montageanweisungen mit Eingabeaufforderungen, können wie in unserem Vorverarbeitungsbeispiel abgeleitet werden.Bitte überprüfen Sie die Evaluierungsskripte.
Dieses Code-Repository ist unter der MIT- und DeepSeek-Lizenz lizenziert.
@misc{tan2024llm4decompile,
title={LLM4Decompile: Decompiling Binary Code with Large Language Models},
author={Hanzhuo Tan and Qi Luo and Jing Li and Yuqun Zhang},
year={2024},
eprint={2403.05286},
archivePrefix={arXiv},
primaryClass={cs.PL}
}


