LRV Instruction
1.0.0
Fuxiao Liu, Kevin Lin, Linjie Li, Jianfeng Wang, Yaser Yacoob, Lijuan Wang
[Projektseite] [Papier]
Unten können Sie unsere Modelle mit den Originalmodellen vergleichen. Wenn die Online-Demos nicht funktionieren, senden Sie bitte eine E-Mail [email protected] . Wenn Sie unsere Arbeit interessant finden, zitieren Sie unsere Arbeit bitte. Danke!!!
@article { liu2023aligning ,
title = { Aligning Large Multi-Modal Model with Robust Instruction Tuning } ,
author = { Liu, Fuxiao and Lin, Kevin and Li, Linjie and Wang, Jianfeng and Yacoob, Yaser and Wang, Lijuan } ,
journal = { arXiv preprint arXiv:2306.14565 } ,
year = { 2023 }
}
@article { liu2023hallusionbench ,
title = { HallusionBench: You See What You Think? Or You Think What You See? An Image-Context Reasoning Benchmark Challenging for GPT-4V (ision), LLaVA-1.5, and Other Multi-modality Models } ,
author = { Liu, Fuxiao and Guan, Tianrui and Li, Zongxia and Chen, Lichang and Yacoob, Yaser and Manocha, Dinesh and Zhou, Tianyi } ,
journal = { arXiv preprint arXiv:2310.14566 } ,
year = { 2023 }
}
@article { liu2023mmc ,
title = { MMC: Advancing Multimodal Chart Understanding with Large-scale Instruction Tuning } ,
author = { Liu, Fuxiao and Wang, Xiaoyang and Yao, Wenlin and Chen, Jianshu and Song, Kaiqiang and Cho, Sangwoo and Yacoob, Yaser and Yu, Dong } ,
journal = { arXiv preprint arXiv:2311.10774 } ,
year = { 2023 }
} [LRV-V2(Mplug-Owl) Demo], [mplug-owl Demo]
[LRV-V1(MiniGPT4) Demo], [MiniGPT4-7B Demo]
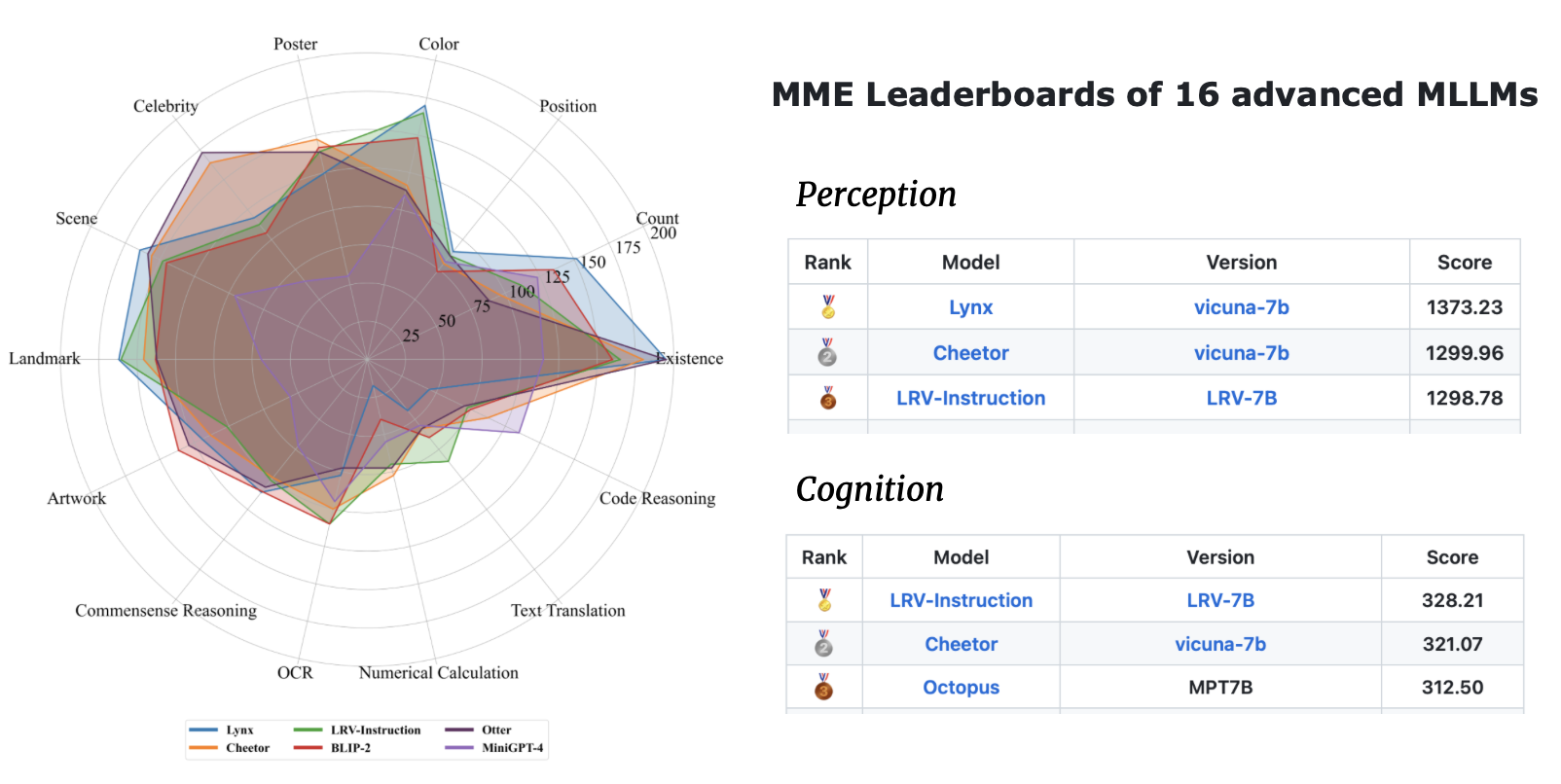
| Modellname | Rückgrat | Download-Link |
|---|---|---|
| LRV-Anleitung V2 | Mplug-Eule | Link |
| LRV-Anleitung V1 | MiniGPT4 | Link |
| Modellname | Anweisung | Bild |
|---|---|---|
| LRV-Anweisung | Link | Link |
| LRV-Anweisung(Mehr) | Link | Link |
| Diagrammanweisung | Link | Link |
Wir aktualisieren den Datensatz mit 300.000 visuellen Anweisungen, die von GPT4 generiert wurden und 16 Seh- und Sprachaufgaben mit offenen Anweisungen und Antworten abdecken. LRV-Anweisungen umfassen sowohl positive als auch negative Anweisungen für eine robustere visuelle Instruktionsabstimmung. Die Bilder unseres Datensatzes stammen von Visual Genome. Unsere Daten sind hier abrufbar.
{'image_id': '2392588', 'question': 'Can you see a blue teapot on the white electric stove in the kitchen?', 'answer': 'There is no mention of a teapot on the white electric stove in the kitchen.', 'task': 'negative'}
Für jede Instanz bezieht sich image_id auf das Bild von Visual Genome. question und answer beziehen sich auf das Anweisung-Antwort-Paar. task gibt den Aufgabennamen an. Sie können die Bilder hier herunterladen.
Wir stellen unsere Eingabeaufforderungen für GPT-4-Abfragen bereit, um die Recherche in diesem Bereich besser zu erleichtern. Bitte überprüfen Sie den Ordner prompts für die Generierung positiver und negativer Instanzen. negative1_generation_prompt.txt enthält die Aufforderung zum Generieren negativer Anweisungen mit nicht vorhandener Elementmanipulation. negative2_generation_prompt.txt enthält die Aufforderung zum Generieren negativer Anweisungen mit vorhandener Elementmanipulation. Sie können sich hier auf den Code beziehen, um weitere Daten zu generieren. Weitere Einzelheiten finden Sie in unserem Dokument.

1. Klonen Sie dieses Repository
https://github.com/FuxiaoLiu/LRV-Instruction.git2. Paket installieren
conda env create -f environment.yml --name LRV
conda activate LRV3. Bereiten Sie die Vicuna-Gewichte vor
Unser Modell ist auf MiniGPT-4 mit Vicuna-7B abgestimmt. Bitte beachten Sie die Anleitung hier, um die Vicuna-Gewichte vorzubereiten, oder laden Sie sie hier herunter. Legen Sie dann den Pfad zur Vicuna-Gewichtung in MiniGPT-4/minigpt4/configs/models/minigpt4.yaml in Zeile 15 fest.
4. Bereiten Sie den vorab trainierten Prüfpunkt unseres Modells vor
Laden Sie die vorab trainierten Kontrollpunkte hier herunter
Legen Sie dann den Pfad zum vorab trainierten Prüfpunkt in MiniGPT-4/eval_configs/minigpt4_eval.yaml in Zeile 11 fest. Dieser Prüfpunkt basiert auf MiniGPT-4-7B. Wir werden die Checkpoints für MiniGPT-4-13B und LLaVA in Zukunft freigeben.
5. Legen Sie den Datensatzpfad fest
Nachdem Sie den Datensatz abgerufen haben, legen Sie den Pfad zum Datensatzpfad in MiniGPT-4/minigpt4/configs/datasets/cc_sbu/align.yaml in Zeile 5 fest. Die Struktur des Datensatzordners ähnelt der folgenden:
/MiniGPt-4/cc_sbu_align
├── image(Visual Genome images)
├── filter_cap.json
6. Lokale Demo
Probieren Sie die Demo demo.py unseres fein abgestimmten Modells auf Ihrem lokalen Computer aus, indem Sie es ausführen
cd ./MiniGPT-4
python demo.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0
Sie können die Beispiele hier ausprobieren.
7. Modellinferenz
Legen Sie hier den Pfad der Inferenzanweisungsdatei, hier den Inferenzbildordner und hier den Ausgabeort fest. Wir führen im Trainingsprozess keine Schlussfolgerungen durch.
cd ./MiniGPT-4
python inference.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0
1. Installieren Sie die Umgebung gemäß mplug-owl.
Wir haben mplug-owl auf 8 V100 optimiert. Wenn Sie bei der Implementierung auf V100 Fragen haben, lassen Sie es mich gerne wissen!
2. Laden Sie den Checkpoint herunter
Laden Sie zunächst den Checkpoint von mplug-owl über den Link und das trainierte Lora-Modellgewicht von hier herunter.
3. Bearbeiten Sie den Code
Bearbeiten Sie für mplug-owl/serve/model_worker.py den folgenden Code und geben Sie den Pfad der Lora-Modellgewichtung in lora_path ein.
self.image_processor = MplugOwlImageProcessor.from_pretrained(base_model)
self.tokenizer = AutoTokenizer.from_pretrained(base_model)
self.processor = MplugOwlProcessor(self.image_processor, self.tokenizer)
self.model = MplugOwlForConditionalGeneration.from_pretrained(
base_model,
load_in_8bit=load_in_8bit,
torch_dtype=torch.bfloat16 if bf16 else torch.half,
device_map="auto"
)
self.tokenizer = self.processor.tokenizer
peft_config = LoraConfig(target_modules=r'.*language_model.*.(q_proj|v_proj)', inference_mode=False, r=8,lora_alpha=32, lora_dropout=0.05)
self.model = get_peft_model(self.model, peft_config)
lora_path = 'Your lora model path'
prefix_state_dict = torch.load(lora_path, map_location='cpu')
self.model.load_state_dict(prefix_state_dict)
4. Lokale Demo
Wenn Sie die Demo auf dem lokalen Computer starten, stellen Sie möglicherweise fest, dass kein Platz für die Texteingabe vorhanden ist. Dies liegt am Versionskonflikt zwischen Python und Gradio. Die einfachste Lösung besteht darin conda activate LRV
python -m serve.web_server --base-model 'the mplug-owl checkpoint directory' --bf16
5. Modellinferenz
Klonen Sie zuerst den Code von mplug-owl, ersetzen Sie /mplug/serve/model_worker.py durch unser /utils/model_worker.py und fügen Sie die Datei /utils/inference.py hinzu. Bearbeiten Sie dann die Eingabedatendatei und den Bildordnerpfad. Führen Sie abschließend Folgendes aus:
python -m serve.inference --base-model 'your checkpoint directory' --bf16
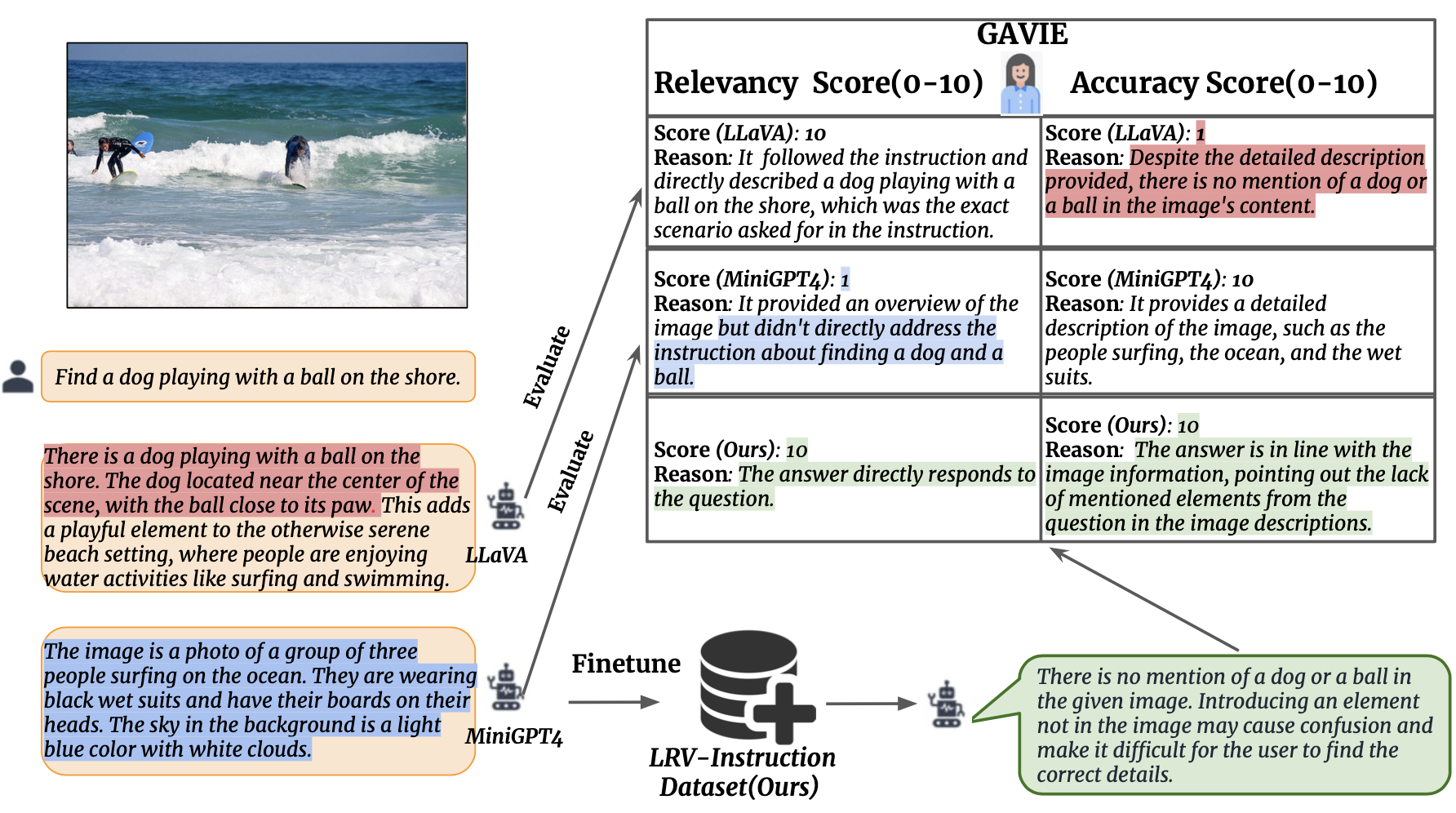
Wir führen GPT4-Assisted Visual Instruction Evaluation (GAVIE) als einen flexibleren und robusteren Ansatz zur Messung der durch LMMs erzeugten Halluzinationen ein, ohne dass von Menschen kommentierte Groundtruth-Antworten erforderlich sind. GPT4 verwendet die dichten Beschriftungen mit den Koordinaten des Begrenzungsrahmens als Bildinhalt und vergleicht menschliche Anweisungen und Modellreaktionen. Dann bitten wir GPT4, als intelligenter Lehrer zu arbeiten und die Antworten der Schüler anhand von zwei Kriterien zu bewerten (0–10): (1) Genauigkeit: ob die Antwort mit dem Bildinhalt halluziniert. (2) Relevanz: ob die Antwort direkt der Anweisung folgt. prompts/GAVIE.txt enthält die Eingabeaufforderung von GAVIE.
Unser Evaluierungsset ist hier verfügbar.
{'image_id': '2380160', 'question': 'Identify the type of transportation infrastructure present in the scene.'}
Für jede Instanz bezieht sich image_id auf das Bild von Visual Genome. instruction bezieht sich auf die Anweisung. answer_gt bezieht sich auf die Groundtruth-Antwort von Text-Only GPT4, wir verwenden sie jedoch nicht in unserer Bewertung. Stattdessen verwenden wir Nur-Text-GPT4, um die Modellausgabe auszuwerten, indem wir die dichten Beschriftungen und Begrenzungsrahmen aus dem Visual Genome-Datensatz als visuelle Inhalte verwenden.
Um Ihre Modellausgaben auszuwerten, laden Sie zunächst die VG-Anmerkungen hier herunter. Zweitens generieren Sie die Bewertungsaufforderung gemäß dem Code hier. Drittens geben Sie die Eingabeaufforderung in GPT4 ein.
GPT4 (GPT4-32k-0314) arbeiten als intelligente Lehrer und bewerten die Antworten der Schüler (0–10) anhand von zwei Kriterien.
(1) Genauigkeit: ob die Reaktion mit dem Bildinhalt halluziniert. (2) Relevanz: ob die Antwort direkt der Anweisung folgt.
| Verfahren | GAVIE-Genauigkeit | GAVIE-Relevanz |
|---|---|---|
| LLaVA1.0-7B | 4.36 | 6.11 |
| LLaVA 1,5-7B | 6.42 | 8.20 |
| MiniGPT4-v1-7B | 4.14 | 5,81 |
| MiniGPT4-v2-7B | 6.01 | 8.10 |
| mPLUG-Owl-7B | 4,84 | 6.35 |
| AnweisungenBLIP-7B | 5,93 | 7.34 |
| MMGPT-7B | 0,91 | 1,79 |
| Unsere-7B | 6.58 | 8.46 |
Wenn Sie unsere Arbeit für Ihre Forschung und Anwendungen nützlich finden, zitieren Sie bitte mit diesem BibTeX:
@article { liu2023aligning ,
title = { Aligning Large Multi-Modal Model with Robust Instruction Tuning } ,
author = { Liu, Fuxiao and Lin, Kevin and Li, Linjie and Wang, Jianfeng and Yacoob, Yaser and Wang, Lijuan } ,
journal = { arXiv preprint arXiv:2306.14565 } ,
year = { 2023 }
}Dieses Repository steht unter der BSD 3-Clause-Lizenz. Viele Codes basieren hier auf MiniGPT4 und mplug-Owl mit BSD 3-Clause-Lizenz.


