PointLLM
1.0.0
 PointLLM: Befähigung großer Sprachmodelle zum Verständnis von Punktwolken
PointLLM: Befähigung großer Sprachmodelle zum Verständnis von Punktwolken Runsen Xu Xiaolong Wang Tai Wang Yilun Chen Jiangmiao Pang* Dahua Lin
Das KI-Labor der Chinesischen Universität Hongkong, Shanghai, Zhejiang-Universität

PointLLM ist online! Probieren Sie es unter http://101.230.144.196 oder unter OpenXLab/PointLLM aus.
Sie können mit PointLLM über die Modelle des Objaverse-Datensatzes oder über Ihre eigenen Punktwolken chatten!
Bitte zögern Sie nicht, uns Ihr Feedback mitzuteilen! ?
| Dialog 1 | Dialog 2 | Dialog 3 | Dialog 4 |
|---|---|---|---|
 |  |  |  |
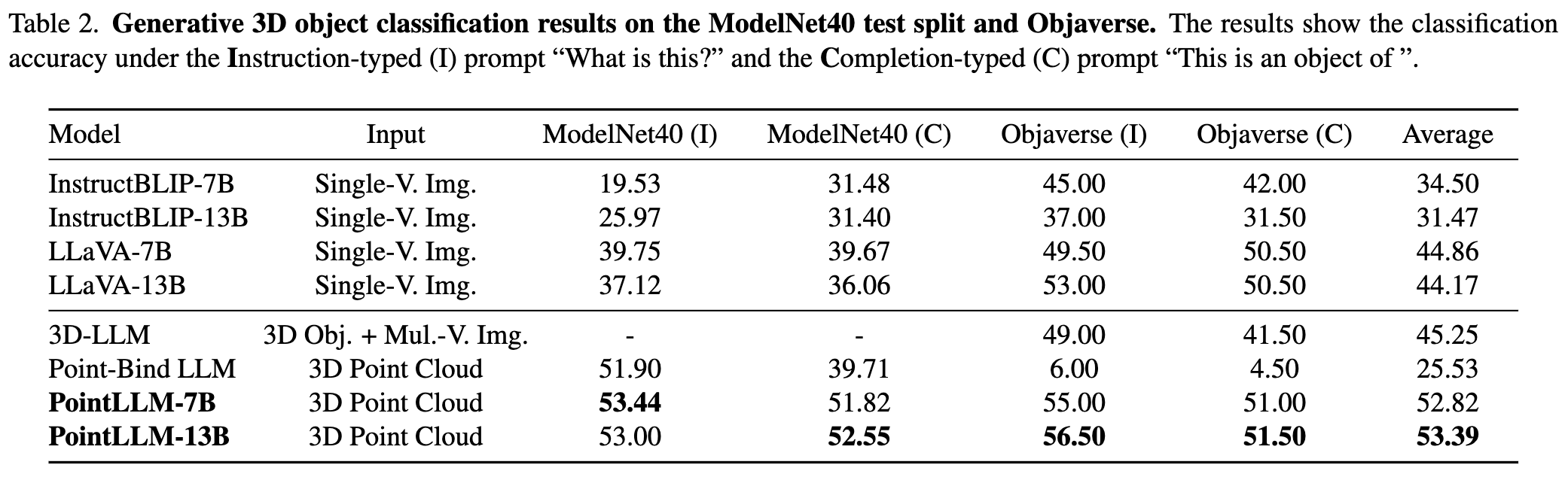
Weitere Ergebnisse finden Sie in unserem Artikel.
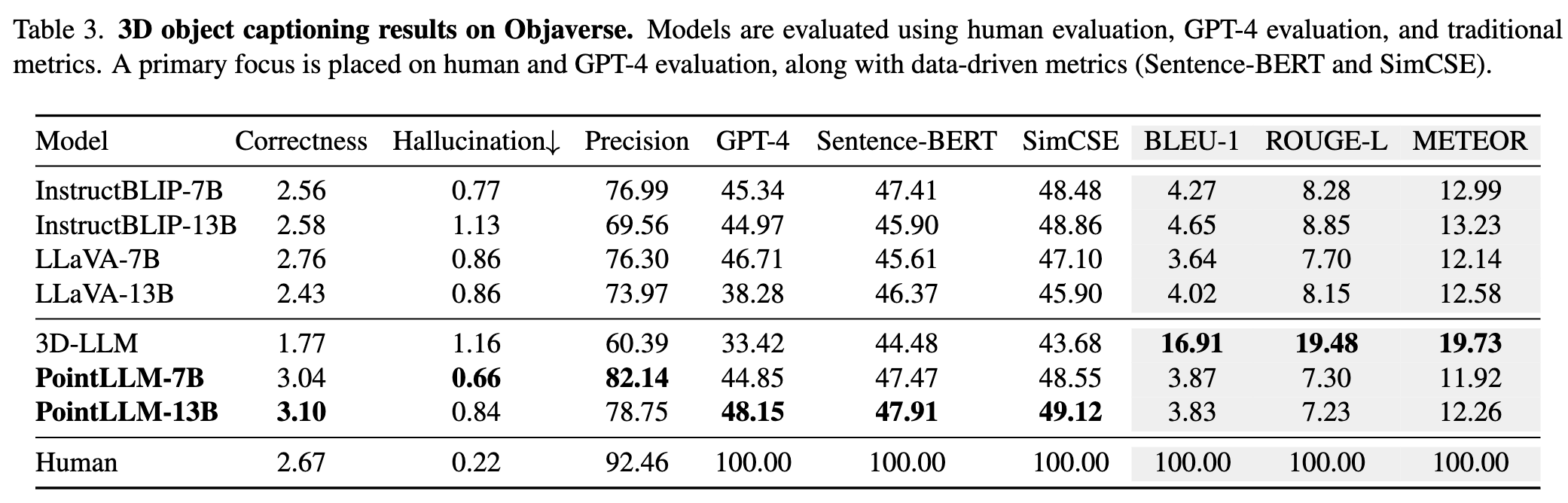
Weitere Ergebnisse finden Sie in unserem Artikel.

Wir testen unsere Codes in der folgenden Umgebung:
Zu Beginn:
git clone [email protected]:OpenRobotLab/PointLLM.git
cd PointLLMconda create -n pointllm python=3.10 -y
conda activate pointllm
pip install --upgrade pip # enable PEP 660 support
pip install -e .
# * for training
pip install ninja
pip install flash-attn8192_npy erstellt, der 660.000 Punktwolkendateien mit dem Namen {Objaverse_ID}_8192.npy enthält. Jede Datei ist ein Numpy-Array mit den Dimensionen (8192, 6), wobei die ersten drei Dimensionen xyz und die letzten drei Dimensionen rgb im Bereich [0, 1] sind. cat Objaverse_660K_8192_npy_split_a * > Objaverse_660K_8192_npy.tar.gz
tar -xvf Objaverse_660K_8192_npy.tar.gzPointLLM Ordner einen Ordner data und erstellen Sie einen Softlink zur unkomprimierten Datei im Verzeichnis. cd PointLLM
mkdir data
ln -s /path/to/8192_npy data/objaverse_dataPointLLM/data ein Verzeichnis mit dem Namen anno_data .anno_data ab. Das Verzeichnis sollte so aussehen: PointLLM/data/anno_data
├── PointLLM_brief_description_660K_filtered.json
├── PointLLM_brief_description_660K.json
└── PointLLM_complex_instruction_70K.jsonPointLLM_brief_description_660K_filtered.json aus PointLLM_brief_description_660K.json gefiltert wird, indem die 3000 Objekte entfernt werden, die wir als Validierungssatz reserviert haben. Wenn Sie die Ergebnisse in unserem Artikel reproduzieren möchten, sollten Sie für das Training die PointLLM_brief_description_660K_filtered.json verwenden. Die PointLLM_complex_instruction_70K.json enthält Objekte aus dem Trainingssatz.pointllm/data/data_generation/system_prompt_gpt4_0613.txt . PointLLM_brief_description_val_200_GT.json herunter, den wir für die Benchmarks zum Objaverse-Datensatz verwenden, und fügen Sie ihn in PointLLM/data/anno_data ein. Wir stellen hier auch die 3000 Objekt-IDs bereit, die wir während des Trainings filtern, und die entsprechenden referenzierenden GTs, die zur Auswertung aller 3000 Objekte verwendet werden können.PointLLM/data ein Verzeichnis mit dem Namen modelnet40_data . Laden Sie die Testaufteilung der ModelNet40-Punktwolken modelnet40_test_8192pts_fps.dat hier herunter und fügen Sie sie in PointLLM/data/modelnet40_data ein.PointLLM Ordner ein Verzeichnis mit dem Namen checkpoints .checkpoints Verzeichnis ab. cd PointLLM
scripts/PointLLM_train_stage1.shscripts/PointLLM_train_stage2.shNormalerweise müssen Sie sich um die folgenden Inhalte nicht kümmern. Sie dienen nur der Reproduktion der Ergebnisse in unserem v1-Artikel (PointLLM-v1.1). Wenn Sie mit unseren Modellen vergleichen oder unsere Modelle für nachgelagerte Aufgaben verwenden möchten, verwenden Sie bitte PointLLM-v1.2 (siehe unser v2-Papier), das eine bessere Leistung bietet.
PointLLM v1.1 und v1.2 verwenden leicht unterschiedliche vorab trainierte Punktencoder und Projektoren. Wenn Sie PointLLM v1.1 reproduzieren möchten, bearbeiten Sie die Datei config.json im Verzeichnis der anfänglichen LLM- und Punkt-Encoder-Gewichte, zum Beispiel vim checkpoints/PointLLM_7B_v1.1_init/config.json .
Ändern Sie den Schlüssel "point_backbone_config_name" um eine andere Punkt-Encoder-Konfiguration anzugeben:
# change from
" point_backbone_config_name " : " PointTransformer_8192point_2layer " # v1.2
# to
" point_backbone_config_name " : " PointTransformer_base_8192point " , # v1.1 Bearbeiten Sie den Prüfpunktpfad des Punktencoders in scripts/train_stage1.sh :
# change from
point_backbone_ckpt= $model_name_or_path /point_bert_v1.2.pt # v1.2
# to
point_backbone_ckpt= $model_name_or_path /point_bert_v1.1.pt # v1.1torch.float32 zum Chatten über 3D-Modelle von Objaverse zu starten. Die Modellprüfpunkte werden automatisch heruntergeladen. Sie können die Modellprüfpunkte auch manuell herunterladen und ihre Pfade angeben. Hier ist ein Beispiel: cd PointLLM
PYTHONPATH= $PWD python pointllm/eval/PointLLM_chat.py --model_name RunsenXu/PointLLM_7B_v1.2 --data_name data/objaverse_data --torch_dtype float32 Sie können auch die Codes für die Verwendung anderer Punktwolken als die von Objaverse problemlos ändern, solange die in das Modell eingegebenen Punktwolken Dimensionen (N, 6) haben, wobei die ersten drei Dimensionen xyz und die letzten drei Dimensionen rgb sind ( im Bereich [0, 1]). Sie können die Punktwolken mit 8192 Punkten abtasten, da unser Modell auf solchen Punktwolken trainiert wird.
Die folgende Tabelle zeigt GPU-Anforderungen für verschiedene Modelle und Datentypen. Wir empfehlen gegebenenfalls die Verwendung torch.bfloat16 , das in den Experimenten in unserem Artikel verwendet wird.
| Modell | Datentyp | GPU-Speicher |
|---|---|---|
| PunktLLM-7B | Torch.float16 | 14 GB |
| PunktLLM-7B | Torch.float32 | 28 GB |
| PunktLLM-13B | Torch.float16 | 26 GB |
| PunktLLM-13B | Torch.float32 | 52 GB |
cd PointLLM
PYTHONPATH= $PWD python pointllm/eval/chat_gradio.py --model_name RunsenXu/PointLLM_7B_v1.2 --data_name data/objaverse_data cd PointLLM
export PYTHONPATH= $PWD
# Open Vocabulary Classification on Objaverse
python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type classification --prompt_index 0 # or --prompt_index 1
# Object captioning on Objaverse
python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type captioning --prompt_index 2
# Close-set Zero-shot Classification on ModelNet40
python pointllm/eval/eval_modelnet_cls.py --model_name RunsenXu/PointLLM_7B_v1.2 --prompt_index 0 # or --prompt_index 1{model_name}/evaluation als Diktat im folgenden Format gespeichert: {
" prompt " : " " ,
" results " : [
{
" object_id " : " " ,
" ground_truth " : " " ,
" model_output " : " " ,
" label_name " : " " # only for classification on modelnet40
}
]
} cd PointLLM
export PYTHONPATH= $PWD
export OPENAI_API_KEY=sk- ****
# Open Vocabulary Classification on Objaverse
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-4-0613 --eval_type open-free-form-classification --parallel --num_workers 15
# Object captioning on Objaverse
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-4-0613 --eval_type object-captioning --parallel --num_workers 15
# Close-set Zero-shot Classification on ModelNet40
python pointllm/eval/evaluator.py --results_path /path/to/model_output --model_type gpt-3.5-turbo-0613 --eval_type modelnet-close-set-classification --parallel --num_workers 15Ctrl+C unterbrechen. Dadurch werden die temporären Ergebnisse gespeichert. Tritt bei der Auswertung ein Fehler auf, speichert das Skript zusätzlich den aktuellen Stand. Sie können die Auswertung an der Stelle fortsetzen, an der sie aufgehört hat, indem Sie denselben Befehl erneut ausführen.{model_name}/evaluation als weiteres Diktat gespeichert. Einige der Metriken werden wie folgt erklärt: " average_score " : The GPT-evaluated captioning score we report in our paper.
" accuracy " : The classification accuracy we report in our paper, including random choices made by ChatGPT when model outputs are vague or ambiguous and ChatGPT outputs " INVALID " .
" clean_accuracy " : The classification accuracy after removing those " INVALID " outputs.
" total_predictions " : The number of predictions.
" correct_predictions " : The number of correct predictions.
" invalid_responses " : The number of " INVALID " outputs by ChatGPT.
# Some other statistics for calling OpenAI API
" prompt_tokens " : The total number of tokens of the prompts for ChatGPT/GPT-4.
" completion_tokens " : The total number of tokens of the completion results from ChatGPT/GPT-4.
" GPT_cost " : The API cost of the whole evaluation process, in US Dollars ?.--start_eval übergeben und den --gpt_type angeben. Zum Beispiel: python pointllm/eval/eval_objaverse.py --model_name RunsenXu/PointLLM_7B_v1.2 --task_type classification --prompt_index 0 --start_eval --gpt_type gpt-4-0613python pointllm/eval/traditional_evaluator.py --results_path /path/to/model_captioning_outputCommunity-Beiträge sind willkommen!? Wenn Sie Unterstützung benötigen, können Sie gerne ein Problem eröffnen oder uns kontaktieren.
Wenn Sie unsere Arbeit und diese Codebasis hilfreich finden, ziehen Sie bitte in Betracht, dieses Repo mit einem Sternchen zu versehen? und zitieren:
@inproceedings { xu2024pointllm ,
title = { PointLLM: Empowering Large Language Models to Understand Point Clouds } ,
author = { Xu, Runsen and Wang, Xiaolong and Wang, Tai and Chen, Yilun and Pang, Jiangmiao and Lin, Dahua } ,
booktitle = { ECCV } ,
year = { 2024 }
}
Dieses Werk steht unter der Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Lassen Sie uns gemeinsam LLM für 3D großartig machen!


