Q Bench
1.0.0
Wie funktionieren LLMs mit mehreren Modalitäten bei Computer Vision auf niedriger Ebene?
Haoning Wu 1 * , Zicheng Zhang 2 * , Erli Zhang 1 * , Chaofeng Chen 1 , Liang Liao 1 ,
Annan Wang 1 , Chunyi Li 2 , Wenxiu Sun 3 , Qiong Yan 3 , Guangtao Zhai 2 , Weisi Lin 1 #
1 Nanyang Technological University, 2 Shanghai Jiaotong University, 3 Sensetime Research
* Gleicher Beitrag. # Korrespondierender Autor.
ICLR2024-Spotlight
Papier | Projektseite | Github | Daten (LLVisionQA) | Daten (LLDescribe) |质衡 (Chinese-Q-Bench)


Der vorgeschlagene Q-Bench umfasst drei Bereiche für das Sehen auf niedriger Ebene: Wahrnehmung (A1), Beschreibung (A2) und Bewertung (A3).
Für Wahrnehmung (A1)/Beschreibung (A2) sammeln wir zwei Benchmark-Datensätze LLVisionQA/LLDescribe.
Wir sind offen für eine einreichungsbasierte Bewertung der beiden Aufgaben. Die Einzelheiten zur Einreichung lauten wie folgt.
Für die Bewertung (A3) stellen wir, da wir öffentliche Datensätze verwenden, einen abstrakten Bewertungscode für beliebige MLLMs zur Verfügung, den jeder testen kann.
datasets -API Für den Q-Bench-A1 (mit Multiple-Choice-Fragen) haben wir sie in Datensätze im HF-Format konvertiert, die automatisch heruntergeladen und mit datasets API verwendet werden können. Bitte beachten Sie die folgende Anleitung:
Pip-Installationsdatensätze
aus Datensätzen importieren Load_datasetds = Load_Dataset("q-future/Q-Bench-HF")print(ds["dev"][0])### {'id': 0,### 'image': <PIL .JpegImagePlugin.JpegImageFile image mode=RGB size=4160x3120>,### 'question': 'Wie ist die Beleuchtung dieses Gebäudes?',### 'option0': 'Hoch',### 'option1': 'Niedrig',### 'option2': 'Mittel',### 'option3': 'N/A',### 'question_type': 2,### 'question_concern': 3,### 'correct_choice': 'B'} aus Datensätzen importieren Load_datasetds = Load_Dataset("q-future/Q-Bench2-HF")print(ds["dev"][0])### {'id': 0,### 'image1': <PIL .Image.Image image mode=RGB size=4032x3024>,### 'image2': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=864x1152>,### 'question': 'Wie ist die Klarheit des zweiten Bildes im Vergleich zum ersten Bild?',### 'option0': 'Mehr Unschärfe',### 'option1': ' Klarer',### 'option2': 'Ungefähr gleich',### 'option3': 'N/A',### 'question_type': 2,### 'question_concern': 0,### 'correct_choice': 'B'}[8.8.2024] Der Low-Level-Vision-Vergleichsaufgabenteil von Q-bench+ (auch als Q-Bench2 bezeichnet) wurde gerade von TPAMI akzeptiert! Kommen Sie und testen Sie Ihr MLLM mit Q-bench+_Dataset.
[01.08.2024] Die Q-Bench ist auf VLMEvalKit veröffentlicht. Kommen Sie und testen Sie Ihr LMM mit einem Befehl wie „python run.py --data Q-Bench1_VAL Q-Bench1_TEST --model InternVL2-1B --verbose“.
[17.06.2024] Q-Bench , Q-Bench2 (Q-bench+) und A-Bench sind jetzt lmms-eval beigetreten, was das Testen von LMM erleichtert!!
[03.06.2024] Github-Repo für A-Bench ist online. Möchten Sie herausfinden, ob Ihr LMM ein Meister darin ist, KI-generierte Bilder auszuwerten? Kommen Sie und testen Sie auf A-Bench !!
[3/1] Wir veröffentlichen hier Co-instruct , Towards Open-End Visual Quality Compare . Weitere Details folgen in Kürze.
[27.02.] Unsere Arbeit Q-Insturct wurde vom CVPR 2024 angenommen. Versuchen Sie, die Einzelheiten darüber zu erfahren, wie man MLLMs in der Sehschwäche unterweist!
[23.02.] Der Low-Level-Vision-Vergleichsaufgabenteil von Q-bench+ ist jetzt bei Q-bench+(Dataset) veröffentlicht!
[2/10] Wir veröffentlichen den erweiterten Q-Bench+, der MLLMs sowohl mit Einzelbildern als auch mit Bildpaaren auf niedriger Sehebene herausfordert. Das LeaderBoard ist vor Ort. Schauen Sie sich die Low-Level-Vision-Fähigkeit Ihrer Lieblings-MLLMs an!! Weitere Details folgen in Kürze.
[1/16] Unsere Arbeit „Q-Bench: A Benchmark for General-Purpose Foundation Models on Low-level Vision“ wird von ICLR2024 als Spotlight-Präsentation akzeptiert.

Wir testen auf drei Close-Source-API-Modellen: GPT-4V-Turbo ( gpt-4-vision-preview , ersetzt die nicht mehr verfügbaren alten GPT-4V-Ergebnisse), Gemini Pro ( gemini-pro-vision ) und Qwen -VL-Plus ( qwen-vl-plus ). GPT-4V ist im Vergleich zur älteren Version leicht verbessert, liegt immer noch an der Spitze aller MLLMs und erreicht fast die Leistung eines Junior-Menschen. Gemini Pro und Qwen-VL-Plus folgen dahinter, immer noch besser als die besten Open-Source-MLLMs (insgesamt 0,65).
Update am 18.07.2024: Wir freuen uns, die neue SOTA-Leistung von BlueImage-GPT (Close-Source) veröffentlichen zu können.
Wahrnehmung, A1-Single
| Name des Teilnehmers | ja oder nein | Was | Wie | Verzerrung | andere | Verzerrung im Kontext | im Kontext andere | gesamt |
|---|---|---|---|---|---|---|---|---|
Qwen-VL-Plus ( qwen-vl-plus ) | 0,7574 | 0,7325 | 0,5733 | 0,6488 | 0,7324 | 0,6867 | 0,7056 | 0,6893 |
BlueImage-GPT ( from VIVO New Champion ) | 0,8467 | 0,8351 | 0,7469 | 0,7819 | 0,8594 | 0,7995 | 0,8240 | 0,8107 |
Gemini-Pro ( gemini-pro-vision ) | 0,7221 | 0,7300 | 0,6645 | 0,6530 | 0,7291 | 0,7082 | 0,7665 | 0,7058 |
GPT-4V-Turbo ( gpt-4-vision-preview ) | 0,7722 | 0,7839 | 0,6645 | 0,7101 | 0,7107 | 0,7936 | 0,7891 | 0,7410 |
| GPT-4V ( alte Version ) | 0,7792 | 0,7918 | 0,6268 | 0,7058 | 0,7303 | 0,7466 | 0,7795 | 0,7336 |
| Mensch-1-Junior | 0,8248 | 0,7939 | 0,6029 | 0,7562 | 0,7208 | 0,7637 | 0,7300 | 0,7431 |
| Mensch-2-Senior | 0,8431 | 0,8894 | 0,7202 | 0,7965 | 0,7947 | 0,8390 | 0,8707 | 0,8174 |
Wahrnehmung, A1-Paar
| Name des Teilnehmers | ja oder nein | Was | Wie | Verzerrung | andere | vergleichen | gemeinsam | gesamt |
|---|---|---|---|---|---|---|---|---|
Qwen-VL-Plus ( qwen-vl-plus ) | 0,6685 | 0,5579 | 0,5991 | 0,6246 | 0,5877 | 0,6217 | 0,5920 | 0,6148 |
Qwen-VL-Max ( qwen-vl-max ) | 0,6765 | 0,6756 | 0,6535 | 0,6909 | 0,6118 | 0,6865 | 0,6129 | 0,6699 |
BlueImage-GPT ( from VIVO New Champion ) | 0,8843 | 0,8033 | 0,7958 | 0,8464 | 0,8062 | 0,8462 | 0,7955 | 0,8348 |
Gemini-Pro ( gemini-pro-vision ) | 0,6578 | 0,5661 | 0,5674 | 0,6042 | 0,6055 | 0,6046 | 0,6044 | 0,6046 |
GPT-4V ( gpt-4-vision ) | 0,7975 | 0,6949 | 0,8442 | 0,7732 | 0,7993 | 0,8100 | 0,6800 | 0,7807 |
| Mensch auf Junior-Niveau | 0,7811 | 0,7704 | 0,8233 | 0,7817 | 0,7722 | 0,8026 | 0,7639 | 0,8012 |
| Mensch auf höchster Ebene | 0,8300 | 0,8481 | 0,8985 | 0,8313 | 0,9078 | 0,8655 | 0,8225 | 0,8548 |
Wir haben kürzlich auch mehrere neue Open-Source-Modelle evaluiert und werden ihre Ergebnisse bald veröffentlichen.
Wir bieten jetzt zwei Möglichkeiten zum Herunterladen der Datensätze an (LLVisionQA und LLDescribe).
über GitHub-Veröffentlichung: Weitere Informationen finden Sie in unserer Veröffentlichung.
über Huggingface-Datensätze: Informationen zum Herunterladen der Bilder finden Sie in den Datenfreigabehinweisen.
Es wird dringend empfohlen, Ihr Modell in das Huggingface-Format zu konvertieren, um diese Daten reibungslos testen zu können. Sehen Sie sich die Beispielskripte für IDEFICS-9B-Instruct von Huggingface als Beispiel an und ändern Sie sie für Ihr benutzerdefiniertes Modell, um sie auf Ihrem Modell zu testen.
Bitte senden Sie eine E-Mail an [email protected] um Ihr Ergebnis im JSON-Format einzureichen.
Sie können uns auch Ihr Modell (z. B. Huggingface AutoModel oder ModelScope AutoModel) zusammen mit Ihren benutzerdefinierten Bewertungsskripten übermitteln. Ihre benutzerdefinierten Skripte können anhand der Vorlagenskripte geändert werden, die für LLaVA-v1.5 (für A1/A2) und hier (zur Bildqualitätsbewertung) funktionieren.
Bitte senden Sie eine E-Mail an [email protected] um Ihr Modell einzureichen, wenn Sie sich außerhalb des chinesischen Festlandes befinden. Bitte senden Sie eine E-Mail an [email protected] um Ihr Modell einzureichen, wenn Sie sich auf dem chinesischen Festland befinden.
Eine Momentaufnahme des LLVisionQA-Benchmark-Datensatzes für die MLLM-Wahrnehmungsfähigkeit auf niedriger Ebene sieht wie folgt aus. Die Bestenliste finden Sie hier.
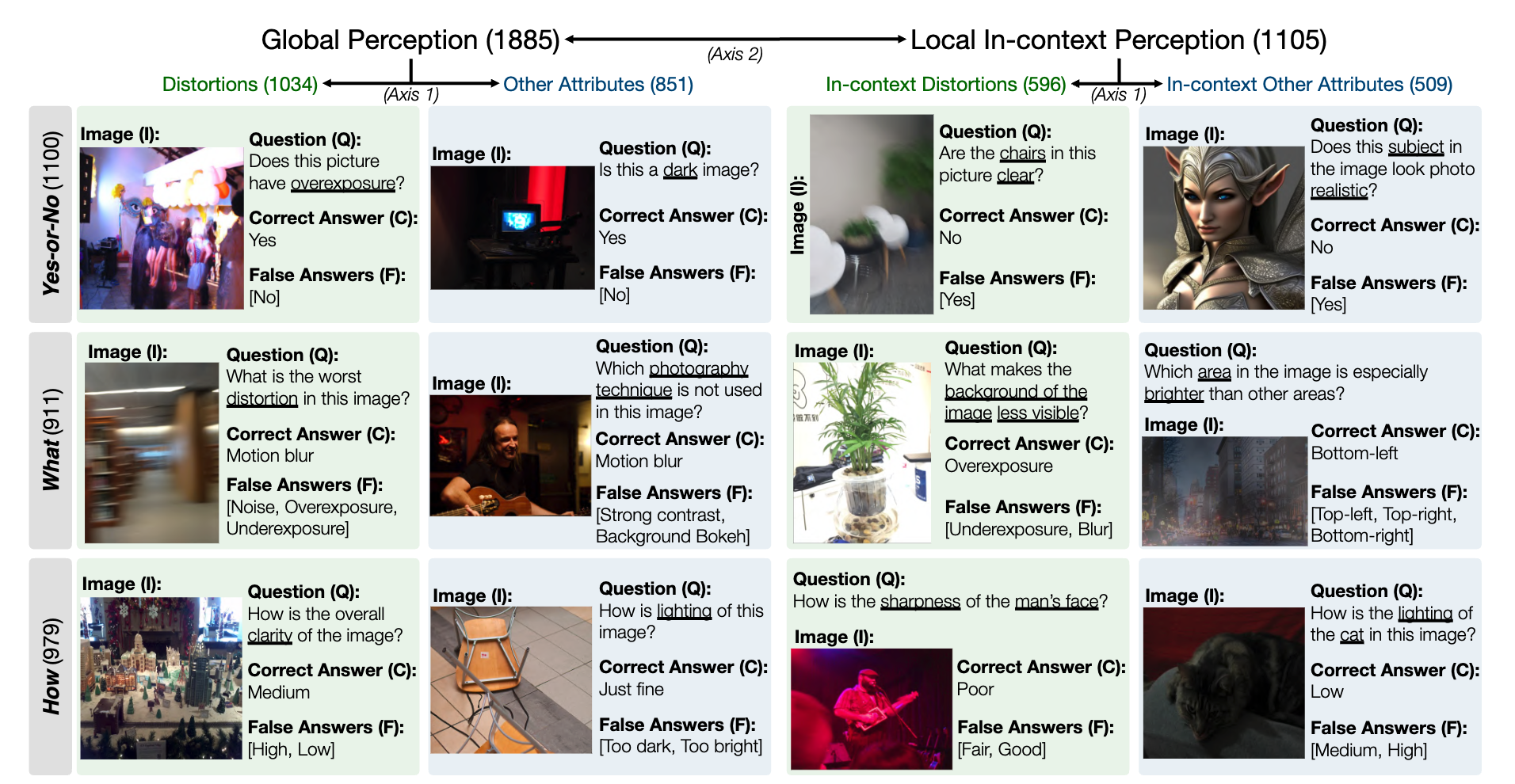
Als Messgröße messen wir hier die Antwortgenauigkeit von MLLMs (bereitgestellt mit der Frage und allen Auswahlmöglichkeiten).
Eine Momentaufnahme des LLDescribe-Benchmark-Datensatzes für die MLLM-Beschreibungsfähigkeit auf niedriger Ebene sieht wie folgt aus. Die Bestenliste finden Sie hier.

Als Metrik messen wir hier die Vollständigkeit , Präzision und Relevanz von MLLM-Beschreibungen.
Eine aufregende Fähigkeit, mit der MLLMs quantitative Ergebnisse für IQA vorhersagen können!
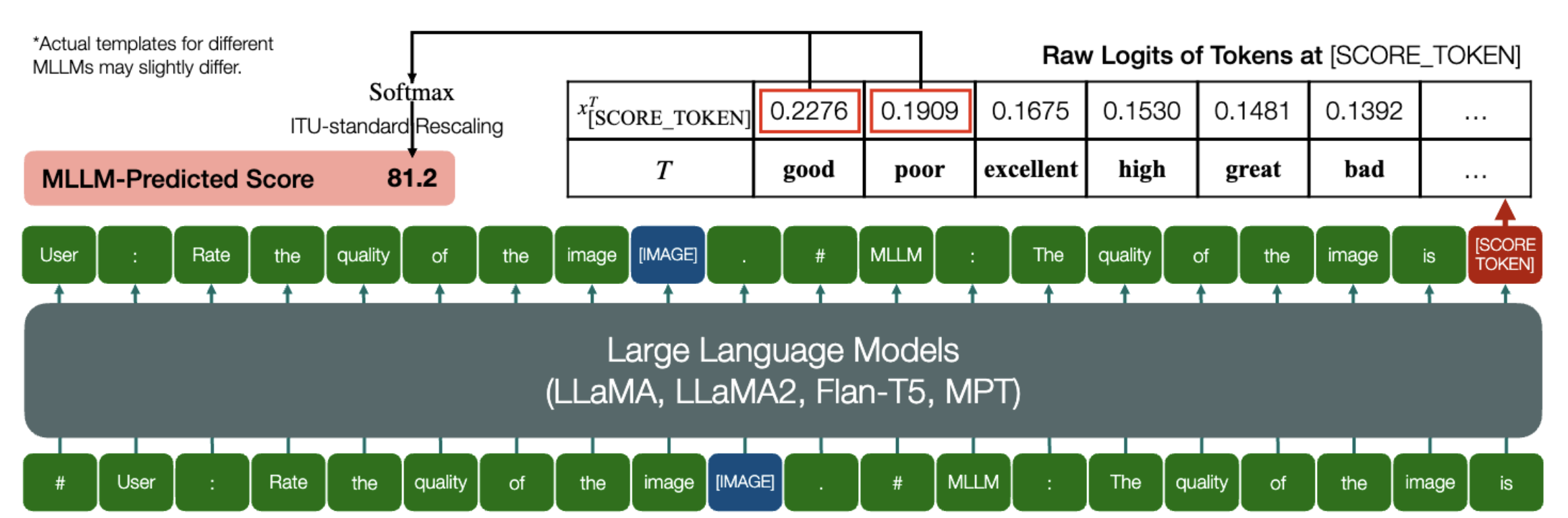
Ähnlich wie oben, solange ein Modell (basierend auf kausalen Sprachmodellen) über die folgenden zwei Methoden verfügt: embed_image_and_text (um Eingaben mit mehreren Modalitäten zu ermöglichen) und forward “ (zur Berechnung von Logits), erfolgt die Bildqualitätsbewertung (IQA) mit dem Modell kann wie folgt erreicht werden:
from PIL import Imagefrom my_mllm_model import Model, Tokenizer, embed_image_and_textmodel, tokenizer = Model(), Tokenizer()prompt = "##User: Bewerten Sie die Qualität des Bildes.n"
„##Assistant: Die Qualität des Bildes ist“ ### Diese Zeile kann basierend auf dem Standardverhalten von MLLM geändert werden.good_idx,poor_idx = tokenizer(["good","poor"]).tolist()image = Image. open("image_for_iqa.jpg")input_embeds = embed_image_and_text(image, prompt)output_logits = model(input_embeds=input_embeds).logits[0,-1]q_pred = (output_logits[[good_idx, arm_idx]] / 100).softmax(0)[0]*Beachten Sie, dass Sie die zweite Zeile basierend auf dem Standardformat Ihres Modells ändern können, z. B. wird für Shikra der „##Assistant: Die Qualität des Bildes ist“ in „##Assistant: Die Antwort ist“ geändert. Es ist in Ordnung, wenn Ihr MLLM zuerst antwortet: „Ok, ich würde gerne helfen! Die Bildqualität ist gut“, ersetzen Sie dies einfach in Zeile 2 der Eingabeaufforderung.
Darüber hinaus bieten wir eine vollständige Implementierung von IDEFICS auf IQA an. Sehen Sie sich ein Beispiel zur Durchführung von IQA mit diesem MLLM an. Auch andere MLLMs können auf die gleiche Weise für die Verwendung in IQA modifiziert werden.
Wir haben Human Opinion Scores (MOS) im JSON-Format für die sieben IQA-Datenbanken erstellt, die in unserem Benchmark bewertet wurden.
Weitere Informationen finden Sie unter IQA_databases.
In die Bestenlisten verschoben. Bitte klicken Sie, um Details anzuzeigen.
Bei Fragen wenden Sie sich bitte an einen der Erstautoren dieses Artikels.
Haoning Wu, [email protected] , @teowu
Zicheng Zhang, [email protected] , @zzc-1998
Erli Zhang, [email protected] , @ZhangErliCarl
Wenn Sie unsere Arbeit interessant finden, zitieren Sie gerne unseren Artikel:
@inproceedings{wu2024qbench,author = {Wu, Haoning und Zhang, Zicheng und Zhang, Erli und Chen, Chaofeng und Liao, Liang und Wang, Annan und Li, Chunyi und Sun, Wenxiu und Yan, Qiong und Zhai, Guangtao und Lin, Weisi},title = {Q-Bench: A Benchmark for General-Purpose Foundation Models on Low-level Vision},booktitle = {ICLR},Jahr = {2024}} 

