LLM PuzzleTest
1.0.0
PuzzleVQA, unser neuer Datensatz, zeigt ernsthafte Herausforderungen multimodaler LLMs beim Verständnis einfacher abstrakter Muster. Papier | Webseite
Wir veröffentlichen AlgoPuzzleVQA, einen neuartigen und herausfordernden Datensatz für multimodales Denken! In Kürze werden wir weitere multimodale Puzzle-Datensätze veröffentlichen. Bleiben Sie dran! Papier | Webseite
Wir freuen uns, die Veröffentlichung von zwei neuartigen VQA-Datensätzen rund um Rätsel anzukündigen:
Die Leistung von MLLMs bei beiden Datensätzen ist deutlich mangelhaft, was den dringenden Bedarf an erheblichen Verbesserungen ihrer multimodalen Argumentationsfähigkeiten unterstreicht.
Große multimodale Modelle erweitern die beeindruckenden Fähigkeiten großer Sprachmodelle durch die Integration multimodaler Verständnisfähigkeiten. Es ist jedoch nicht klar, wie sie die allgemeine Intelligenz und Denkfähigkeit des Menschen nachahmen können. Da das Erkennen von Mustern und das Abstrahieren von Konzepten der Schlüssel zur allgemeinen Intelligenz sind, stellen wir PuzzleVQA vor, eine Sammlung von Rätseln, die auf abstrakten Mustern basieren. Mit diesem Datensatz bewerten wir große multimodale Modelle mit abstrakten Mustern, die auf grundlegenden Konzepten wie Farben, Zahlen, Größen und Formen basieren. Durch unsere Experimente mit hochmodernen großen multimodalen Modellen stellen wir fest, dass sie sich nicht gut auf einfache abstrakte Muster verallgemeinern lassen. Bemerkenswert ist, dass selbst GPT-4V nicht mehr als die Hälfte der Rätsel lösen kann. Um die Denkherausforderungen in großen multimodalen Modellen zu diagnostizieren, leiten wir die Modelle schrittweise mit unseren Ground-Truth-Argumentationserklärungen für visuelle Wahrnehmung, induktives Denken und deduktives Denken. Unsere systematische Analyse zeigt, dass die Hauptengpässe von GPT-4V in einer schwächeren visuellen Wahrnehmung und induktiven Denkfähigkeiten liegen. Wir hoffen, durch diese Arbeit Licht auf die Grenzen großer multimodaler Modelle zu werfen und zu zeigen, wie sie menschliche kognitive Prozesse in Zukunft besser nachahmen können.
PuzzleVQA ist hier und auch auf Huggingface verfügbar.
Die folgende Abbildung zeigt eine Beispielfrage, die das Farbkonzept in PuzzleVQA betrifft, und eine falsche Antwort von GPT-4V. Im Lösungsprozess können im Allgemeinen drei Phasen beobachtet werden: visuelle Wahrnehmung (blau), induktives Denken (grün) und deduktives Denken (rot). Hier war die visuelle Wahrnehmung unvollständig, was zu einem Fehler beim deduktiven Denken führte.

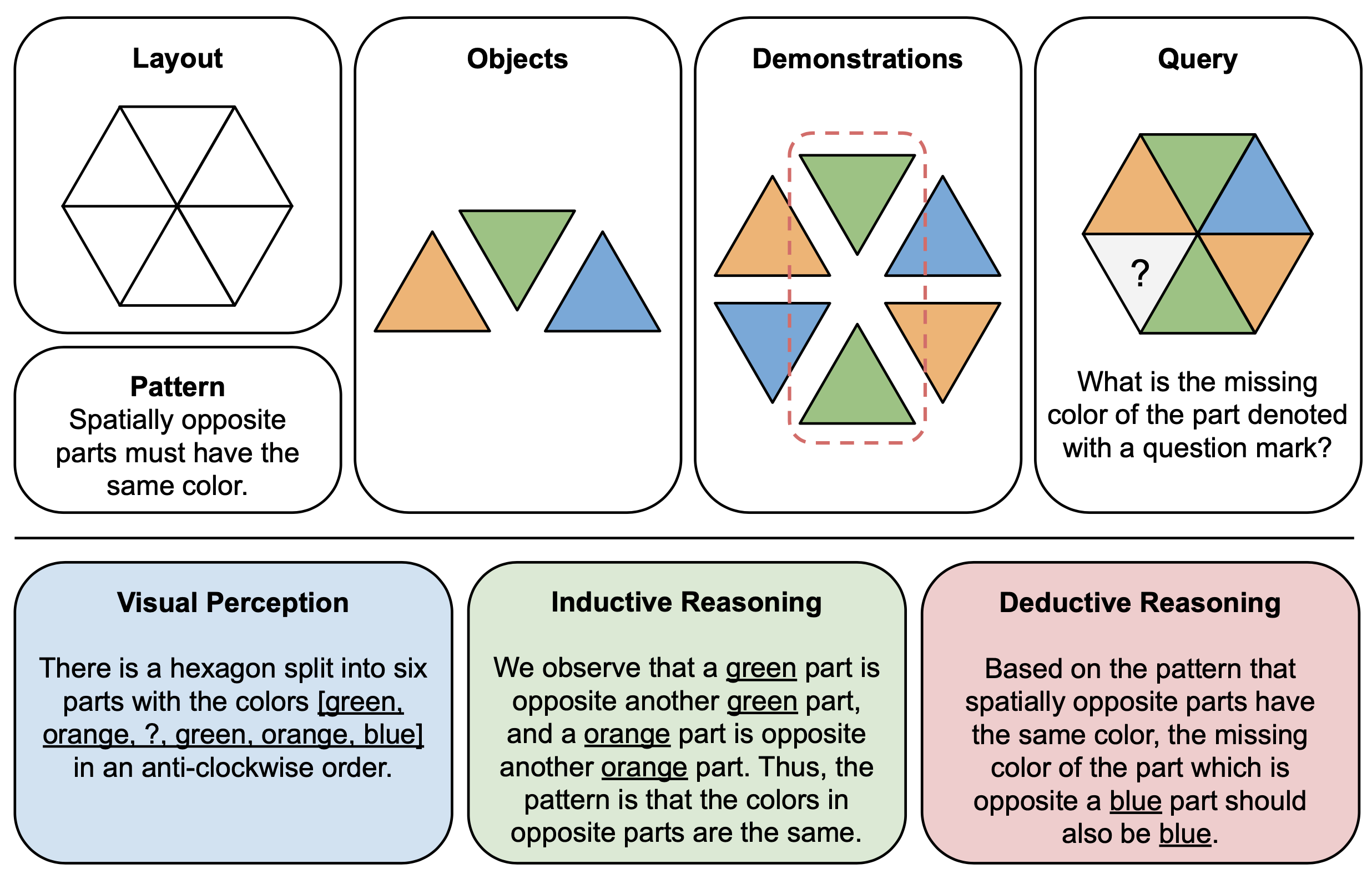
Die folgende Abbildung zeigt ein Illustrationsbeispiel für Komponenten (oben) und Begründungserklärungen (unten) für abstrakte Rätsel in PuzzleVQA. Um jede Puzzle-Instanz zu konstruieren, definieren wir zunächst das Layout und Muster einer multimodalen Vorlage und füllen die Vorlage mit geeigneten Objekten, die das zugrunde liegende Muster demonstrieren. Aus Gründen der Interpretierbarkeit erstellen wir auch Erklärungen zur Grundwahrheitsbegründung, um das Rätsel zu interpretieren und die allgemeinen Lösungsphasen zu erläutern.
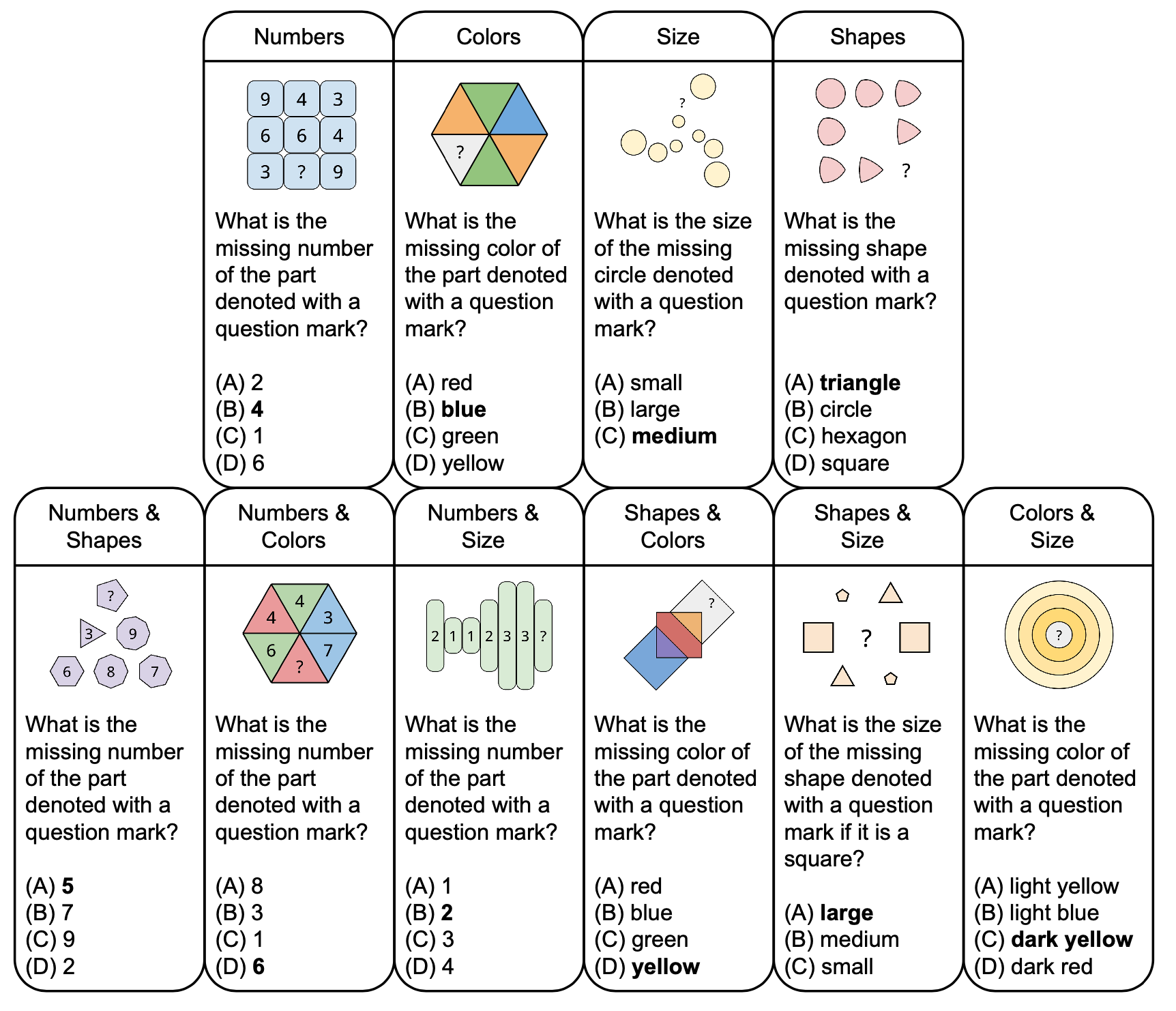
Die folgende Abbildung zeigt die Taxonomie abstrakter Rätsel in PuzzleVQA mit Beispielfragen, basierend auf grundlegenden Konzepten wie Farben und Größe. Um die Vielfalt zu erhöhen, entwerfen wir sowohl Einzelkonzept- als auch Doppelkonzept-Rätsel.
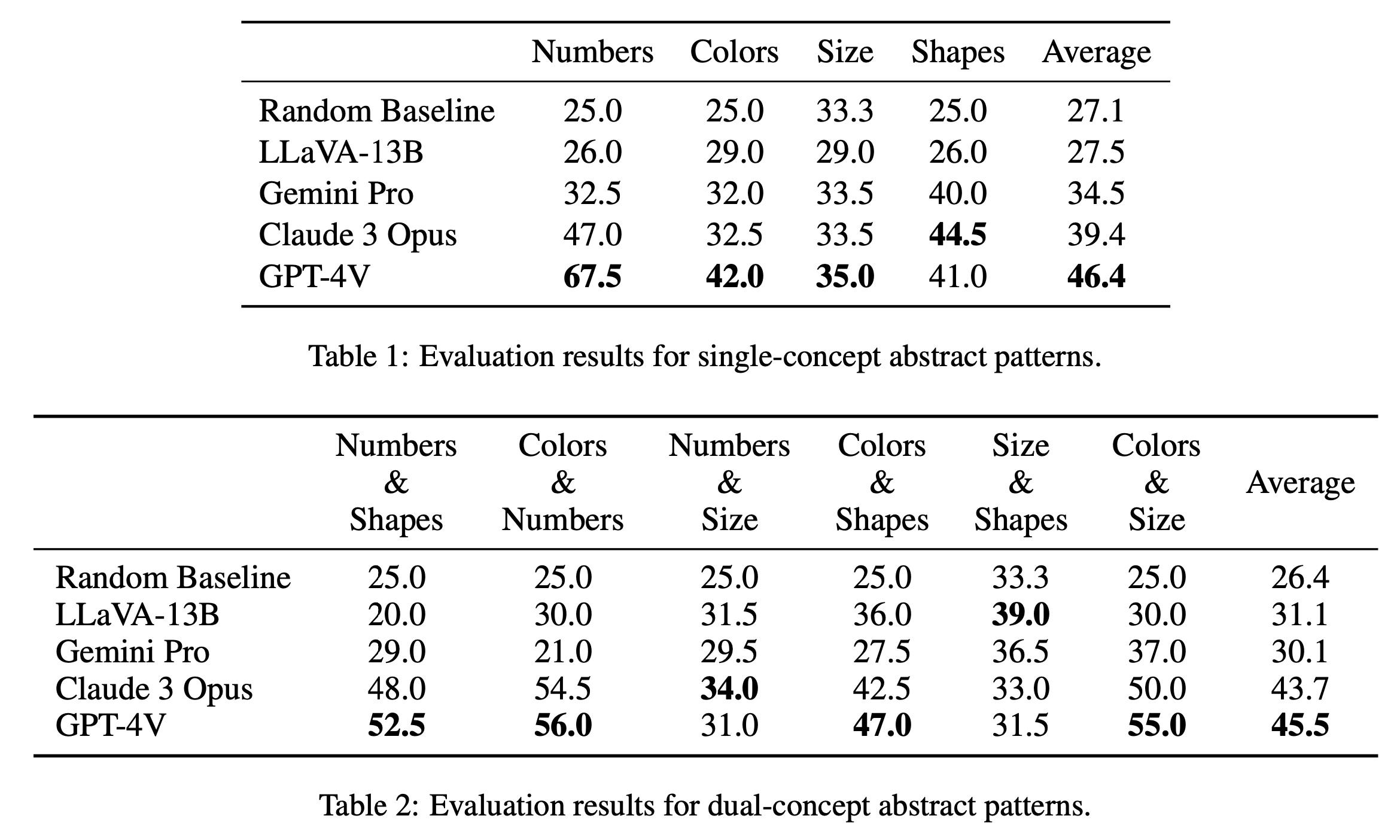
Wir berichten über die wichtigsten Bewertungsergebnisse zu Einzelkonzept- und Doppelkonzept-Rätseln in Tabelle 1 bzw. Tabelle 2. Die in Tabelle 1 gezeigten Bewertungsergebnisse für Einzelkonzept-Rätsel zeigen bemerkenswerte Leistungsunterschiede zwischen den Open-Source- und Closed-Source-Modellen. GPT-4V sticht mit der höchsten durchschnittlichen Punktzahl von 46,4 hervor und demonstriert überlegenes abstraktes Musterschlussfolgern bei Einzelkonzept-Rätseln wie Zahlen, Farben und Größe. Besonders in der Kategorie „Zahlen“ schneidet es mit einer Punktzahl von 67,5 hervor und übertrifft damit andere Modelle bei weitem, was möglicherweise auf seinen Vorteil bei mathematischen Denkaufgaben zurückzuführen ist (Yang et al., 2023). Claude 3 Opus folgt mit einem Gesamtdurchschnitt von 39,4 und zeigt seine Stärke in der Kategorie „Formen“ mit einem Spitzenwert von 44,5. Die anderen Modelle, darunter Gemini Pro und LLaVA-13B, liegen mit Durchschnittswerten von 34,5 bzw. 27,5 zurück und schneiden in mehreren Kategorien ähnlich wie die zufällige Basislinie ab.
In der Auswertung zu Dual-Concept-Rätseln, wie in Tabelle 2 dargestellt, sticht GPT-4V erneut mit der höchsten Durchschnittsnote von 45,5 hervor. Besonders gut schnitt es in Kategorien wie „Farben & Zahlen“ und „Farben & Größe“ mit einer Punktzahl von 56,0 bzw. 55,0 ab. Claude 3 Opus folgt mit einem Durchschnitt von 43,7 dicht dahinter und zeigt eine starke Leistung in „Anzahl & Größe“ mit der höchsten Punktzahl von 34,0. Interessanterweise erzielt LLaVA-13B trotz seines niedrigeren Gesamtdurchschnitts von 31,1 mit 39,0 die höchste Punktzahl in der Kategorie „Größe und Formen“. Gemini Pro hingegen weist in allen Kategorien eine ausgewogenere Leistung auf, weist jedoch einen etwas niedrigeren Gesamtdurchschnitt von 30,1 auf. Insgesamt stellen wir fest, dass Modelle bei Einzelkonzept- und Doppelkonzeptmustern im Durchschnitt eine ähnliche Leistung erbringen, was darauf hindeutet, dass sie in der Lage sind, mehrere Konzepte wie Farben und Zahlen miteinander in Beziehung zu setzen.
@misc{chia2024puzzlevqa,
title={PuzzleVQA: Diagnosing Multimodal Reasoning Challenges of Language Models with Abstract Visual Patterns},
author={Yew Ken Chia and Vernon Toh Yan Han and Deepanway Ghosal and Lidong Bing and Soujanya Poria},
year={2024},
eprint={2403.13315},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Wir stellen die neuartige Aufgabe des multimodalen Rätsellösens vor, eingebettet in den Kontext der visuellen Fragebeantwortung. Wir präsentieren einen neuen Datensatz, AlgoPuzzleVQA, der darauf ausgelegt ist, die Fähigkeiten multimodaler Sprachmodelle bei der Lösung algorithmischer Rätsel, die sowohl visuelles Verständnis, Sprachverständnis als auch komplexes algorithmisches Denken erfordern, herauszufordern und zu bewerten. Wir erstellen die Rätsel, um eine Vielzahl mathematischer und algorithmischer Themen wie boolesche Logik, Kombinatorik, Graphentheorie, Optimierung, Suche usw. abzudecken, mit dem Ziel, die Lücke zwischen visueller Dateninterpretation und algorithmischen Fähigkeiten zur Problemlösung zu ermitteln. Der Datensatz wird automatisch aus von Menschen erstelltem Code generiert. Alle unsere Rätsel verfügen über exakte Lösungen, die ohne langwierige menschliche Berechnungen mithilfe des Algorithmus gefunden werden können. Dadurch wird sichergestellt, dass unser Datensatz hinsichtlich der Argumentationskomplexität und der Datensatzgröße beliebig skaliert werden kann. Unsere Untersuchung zeigt, dass große Sprachmodelle (LLMs) wie GPT4V und Gemini bei Rätsellösungsaufgaben eine begrenzte Leistung aufweisen. Wir stellen fest, dass ihre Leistung in einem Multi-Choice-Frage-Antwort-Setup bei einer beträchtlichen Anzahl von Rätseln nahezu zufällig ist. Die Ergebnisse betonen die Herausforderungen der Integration von visuellem, sprachlichem und algorithmischem Wissen zur Lösung komplexer Denkprobleme.
PuzzleVQA ist hier und auch auf Huggingface verfügbar.
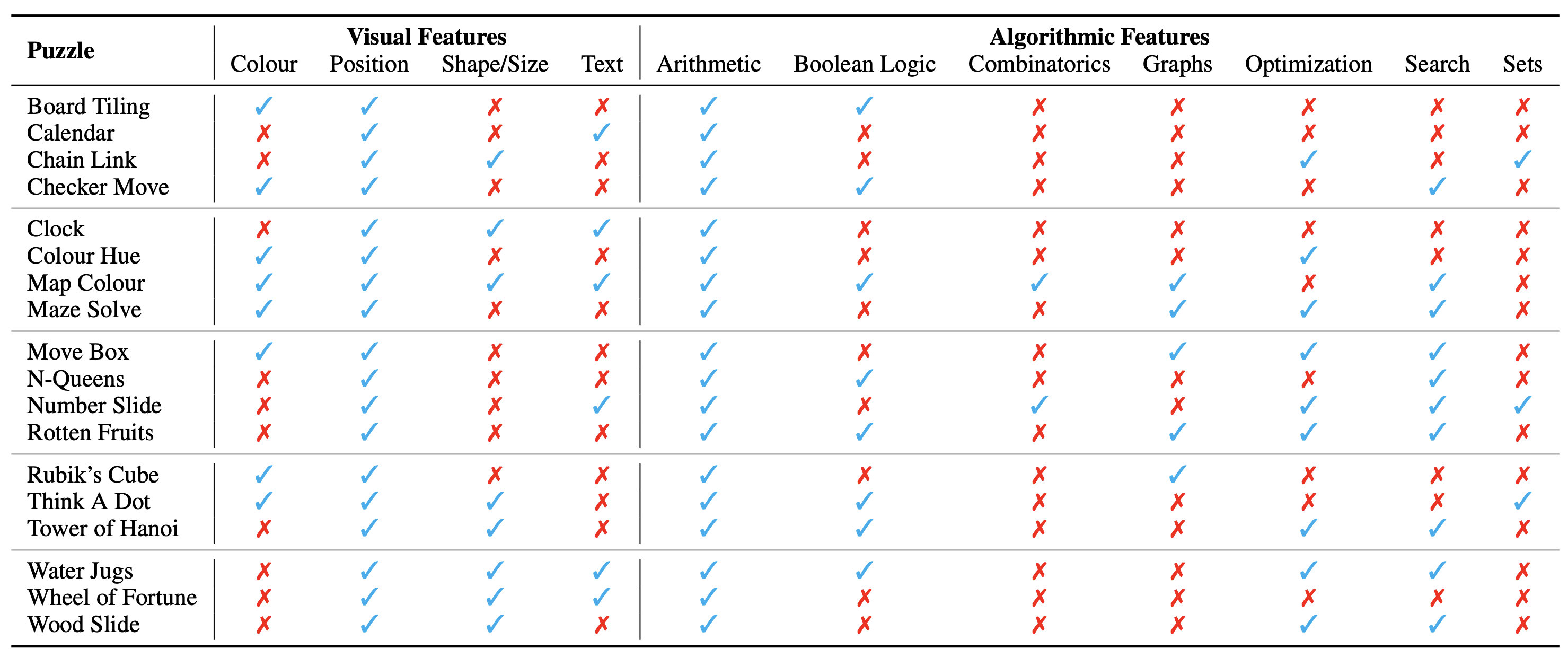
Die Konfiguration des Rätsels/Problems wird als Bild dargestellt, das seinen visuellen Kontext darstellt. Wir identifizieren die folgenden grundlegenden Aspekte des visuellen Kontexts, die die Art der Rätsel beeinflussen:

Wir identifizieren auch die algorithmischen Konzepte, die zur Lösung der Rätsel, also zur Beantwortung der Fragen für die Rätselinstanzen, erforderlich sind. Sie lauten wie folgt:

Die algorithmischen Kategorien schließen sich nicht gegenseitig aus, da wir für die meisten Rätsel zwei oder mehr Kategorien verwenden müssen, um die Antwort abzuleiten.
Der Datensatz ist hier in diesem Format verfügbar. Wir haben insgesamt 18 verschiedene Rätsel erstellt, die verschiedene algorithmische und mathematische Themen abdecken. Viele dieser Rätsel sind in verschiedenen Freizeit- oder akademischen Umgebungen beliebt.
Insgesamt haben wir 1800 Instanzen der 18 verschiedenen Rätsel. Diese Instanzen sind analog zu verschiedenen Testfällen des Puzzles, dh sie haben unterschiedliche Eingabekombinationen, Anfangs- und Zielzustände usw. Um alle Instanzen zuverlässig zu lösen, müsste der genaue zu verwendende Algorithmus gefunden und dann genau angewendet werden. Dies ähnelt der Art und Weise, wie wir die Genauigkeit eines Computerprogramms überprüfen, das eine bestimmte Aufgabe durch eine breite Palette von Testfällen lösen soll.
Wir betrachten den gesamten Datensatz derzeit nur als Bewertungsmaßstab. Die detaillierten Beispiele aller Rätsel finden Sie hier.
Eine Anleitung zur Generierung des Datensatzes finden Sie hier. Die Anzahl der Instanzen und der Schwierigkeitsgrad der Rätsel können beliebig auf jede gewünschte Größe und jedes gewünschte Level skaliert werden.
Die ontologische Kategorisierung der Rätsel ist wie folgt:
Der Versuchsaufbau und die Skripte finden Sie im AlgoPuzzleVQA-Verzeichnis.
Bitte zitieren Sie den folgenden Artikel, wenn Sie unsere Arbeit nützlich fanden:
@article { ghosal2024algopuzzlevqa ,
title = { Are Language Models Puzzle Prodigies? Algorithmic Puzzles Unveil Serious Challenges in Multimodal Reasoning } ,
author = { Ghosal, Deepanway and Han, Vernon Toh Yan and Chia, Yew Ken and and Poria, Soujanya } ,
journal = { arXiv preprint arXiv:2403.03864 } ,
year = { 2024 }
}

